




Chunks
Members
-
Joined
-
Last visited
Everything posted by Chunks
-
I am wondering why my VNC shows up in a language that I don't use, and don't have configured (as far as I can find) on my system. My system has the country set to United Kingdom. The language is English. My browser and OS and everything are all english. I live in Sweden, I just don't know how VNC knows I live in Sweden When I load VNC for a VM, the interface looks like this: I recently installed a docker image that also uses VNC, and that uses a different VNC app, but it's still showing in Swedish. Is this configurable? Cheers.
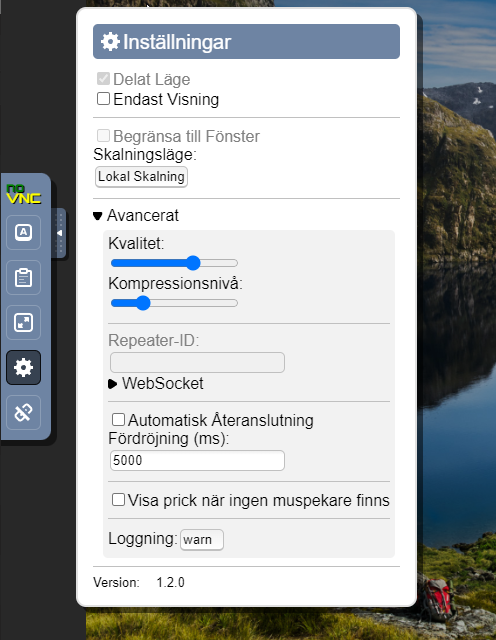
-
Thanks @BigBoyMarky, I did the same. Just renamed ssl.conf --> ssl.cong.bak and nginx.conf --> nginx.conf.bak so that I could compare them after they were downloaded fresh. I had made some changes to make Nextcloud happy that I didn't want to lose. Thankfully, all the changes were simple to un-comment out once the new configs downloaded. So I'm actually pretty glad the new, most updated config files are now in place.
-
I had the same issues, couldn't get in to see anything, unauthorized errors even on my LAN. I also had the black box saying ##################################################### # Login via the webui at http://<ip>:32400/web # # and restart the docker, because there was no # # plex token found in the preference file # ##################################################### What ended up fixing it for me was one of two things: 1. I added the "PLEX_CLAIM" value on the docker settings. Make sure you notice that you only have 4 minutes before the key expires. 2. I went into the Appdata folder and removed the 4 key/value PAIRS that they said to on the troubleshooting page: The first time I tried this, I just emptied the values so they were, for example, PlexOnlineMail="" . That didn't work. What seemed to work, was removing both key AND value. The next time I Started the docker, the logs showed it was claimed successfully, and then logging into the LAN IP worked. Server claimed successfully, navigate to http://serverip:32400/web to complete plex setup. I dunno if it was just dumb luck, or restarting the docker image 12 times, but it finally looks good again.
-
The plugin works ok for me if I disable snapshots. They used to work with snapshots as well until "recently"? I'm not sure what happened. 2022-07-03 02:00:01 information: able to perform snapshot for disk /mnt/user/domains/vmname/vdisk1.img on vmname. use_snapshots is 1. vm_state is running. vdisk_type is raw 2022-07-03 02:00:01 information: qemu agent found. enabling quiesce on snapshot. 2022-07-03 02:00:01 failure: snapshot command failed on vdisk1.snap for vmname. 2022-07-03 02:00:13 failure: snapshot_fallback is 0. skipping backup for vmname to prevent data loss. no cleanup will be performed for this vm. 2022-07-03 02:00:17 information: finished attempt to backup vmname to /mnt/disks/ssd1tb/vm_backups. Not sure what happened. I forgot to add the error from the actual logs. I'll attach them here since they're kinda long. vmerror.txt
-
So I got it to save my value. Line 38 of "/usr/share/webapps/rutorrent/plugins/cookies/cookies.php" looks like this: if(count($tmp>1) && (trim($tmp[1])!='')) if you change it to if( (count($tmp)>1) && (trim($tmp[1])!='')) You just need to move the comparison outside of the "count" function. This is all I could find that MIGHT be relevant? https://www.php.net/manual/en/function.count.php#refsect1-function.count-changelog Edit to add: The source file hasn't been changed in 9 years. So I dunno why this is suddenly a problem for us. I don't know enough PHP to guess. https://github.com/Novik/ruTorrent/blob/master/plugins/cookies/cookies.php
-
Hi there... I've been running the backup (v2) forever, but I hadn't actually needed to use it until this weekend. I broke a config (for home-assistant, not that I think that matters) and wanted to restore. I had 5 days worth of backups but realised the tar.gz was 90gb. No matter what I do with these backup files (I had 5 days worth), there is a CRC error. I've copied them to my windows machine, and 7zip gets mad. I've gunzip'd and untarred on the server itself. Always errors. For todays backup, I removed Plex which halved the size. A mere 45gb compressed now. Still errors. I have "Verify backups" set to "yes", and nothing has been reported. For my next backup, I will not use compression at all and see what happens. I guess my question is... any idea what could be doing this? Perhaps I'm fundamentally misunderstanding how things work? Maybe one docker directory is doing weird things with filenames or something that's not supported by tar?
-
I have the same issue psycho_asylum. I'm trying to move from Linuxservers retired image to this one. I've done a compare of both php files that are referenced in the stack trace, and they're identical. I did notice however that Linuxserver (which works) is running PHP 8.0.3 and this one is running 7.3.27 I'm not an expert, but maybe that has something to do with it? I haven't gone beyond this point in my troubleshooting yet.
-
Regarding the formatting, I wasn't sure how to grab the XML you asked for, (normally the Flash share is disabled) so I used the "Tools --> Config File Editor" to grab it from the flash drive, then pasted it into Notepad++ on windows. That explains the formatting. But you made me wonder about the xml, so I deleted the docker and that, and started over - everything works. Anyway, I have no idea what happened, or why the first time I removed/readded it, it didn't fix it. Sorry for taking your time but I do appreciate the help. /Chunks
-
I'm not sure I'm doing this correctly, but I grabbed the XML. I don't think there's anything sensitive in there, the only change I made was to the path. Here's the command that runs (successfully as far as I can tell): root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker create --name='rmlint' --net='bridge' -e TZ="Europe/Berlin" -e HOST_OS="Unraid" -e 'GUAC_USER'='' -e 'GUAC_PASS'='' -e 'PUID'='99' -e 'PGID'='100' -p '8322:8080/tcp' -v '/mnt/user/Photos/':'/root':'rw' -v '/mnt/user/appdata/rmlint':'/config':'rw' 'bobbintb/docker-rmlint-unraid' d86f95afa658ec3ac59acf94325c058d73b9afe1a140f01a0991049069b4e849 The command finished successfully! --- I really hope none of this data is sensitive. I think it's not Thanks for checking this out, I appreciate it. There's a chance it's a system issue. I dunno. rmlint.xml
-
I've tried getting this to run, and after downloading/installing the image, I am stuck. When I start the container, the log gets filled with a TON of "Exec Format Errors". It looks like they're just looping after that. These are the first few lines of the log, in case that's helpful. I can provide the rest of the log as well if it would help.. 2021-04-11T11:34:39.048094872Z foreground: warning: unable to spawn /docker-mods: Exec format error 2021-04-11T11:34:39.078252944Z [s6-init] making user provided files available at /var/run/s6/etc...exited 0. 2021-04-11T11:34:39.145482632Z [s6-init] ensuring user provided files have correct perms...exited 0. 2021-04-11T11:34:39.148697163Z [fix-attrs.d] applying ownership & permissions fixes... 2021-04-11T11:34:39.150926422Z [fix-attrs.d] done. 2021-04-11T11:34:39.152785844Z [cont-init.d] executing container initialization scripts... 2021-04-11T11:34:39.155464041Z [cont-init.d] 01-envfile: executing... 2021-04-11T11:34:39.157618520Z foreground: warning: unable to spawn /var/run/s6/etc/cont-init.d/01-envfile: Exec format error I googled a little, and maybe this is a problem with the shell command? I dunno.... I know just enough about linux to be a danger to myself
-
This has happened a couple times to me as well. In the last few weeks I've left browsers open and viewing the dashboard page for many days at a time (I'm the guy with 10 windows, 50 tabs in each, and since I've been working on a few things I end up with a bunch of Unraid dashboard / Main windows open). I'm using Chrome. I can confirm that running "/etc/rc.d/rc.nginx restart" via SSH resolved the problem for me (temporarily?) before my system completely locks up. Last time this happened the Web UI was completely hosed and I had to restart by force (I forgot to try SSH).
-
Out of curiosity, are temperature threshold values for drives reset when you do a version update? Ever since I installed the new release, my nvme drive is giving temperature alerts - at first I thought it was being pushed harder, but then I realised that I might have increased the temperature alert values in 6.8.3, ages ago.
-
Dumb question, but I'm a linux newb. I see a fair few comments about it being easier with 6.9.* to add modules. I can tinker and screw around some weekend, so I'm not asking for someone to do the work for me, but my motherboard has a module for reading more sensors. https://github.com/electrified/asus-wmi-sensors Is this feasible for a relative newbie to do? Can I build it as a plugin or even put it on the app store if I figure out that far?
-
I was trying to get Telegram notifications working with the Docker. From what I can see, you just enable the "notification script" option, and then fill out some variables to send to "sabnzbd-notify.py" I'm getting errors and it's not working. I cannot remember if I added the Notify script myself to "appdata\sabnzbd\scripts" or if it was included with the configuration. But it's there now. I made the python files executable (I just 777'd them, because I don't understand security, or linux I guess) and it seems like it's missing other things. Anyone got this working? Or have tips on what I should do? Most of my googling comes back to installing missing Python libraries (setuptools), but I'm not sure I want to go too deep down that rabbit hole without asking here first.
-
I grabbed my diagnostics and was about to send them but then I had a thought - I am using firefox which is having the problem. I switched to Edge (it's what I have) and the page loaded fine. Chrome just finished installing and that works fine too. It may just be Firefox that is choking?
-
I have the same issue, I updated this morning without any errors but now it hangs at "Updating Content" and doesn't do anything or give any errors. I just removed and reinstalled the plugin and that did not fix it - the same issue persists. I am running 6.7.0-rc5 not the latest, if that matters.
-
I completely understand. I was so focused on filling everything out, I kind of forgot the point of the plugin. What you said definitely makes sense. Thanks again though, as I said, everything else works perfectly.
-
I've set this up and I didn't have any problems except that my Samsung NVME cache drive isn't showing up at all. I'm not super linux friendly, but I did dig through the thread looking for anyone else with this problem. I saw someone running the command "lsscsi -u -g" but when I do that, my NVME drive isn't shown at all. I can see 4 HDD's from my onboard controller, and 2 other HDD's from my External controller, and my Flash Drive is also visible (sg0). But not the NVME drive (pardon the silly obfuscation) :~# lsscsi -u -g [0:0:0:0] disk none /dev/sda /dev/sg0 [1:0:0:0] disk 500xxxxxxaf48d06 /dev/sdd /dev/sg3 [2:0:0:0] disk 500xxxxxx2d2cedb /dev/sde /dev/sg4 [3:0:0:0] disk 500xxxxxx2da8bbe /dev/sdf /dev/sg5 [4:0:0:0] disk 500xxxxxx7286f91 /dev/sdg /dev/sg6 [10:0:0:0] disk 500xxxxxx6e9b2d7 /dev/sdb /dev/sg1 [10:0:1:0] disk 500xxxxxx664e6dc /dev/sdc /dev/sg2 However running "fdisk -l" I can see it here: Disk /dev/nvme0n1: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors Disk model: Samsung SSD 970 EVO 1TB Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x00000000 Device Boot Start End Sectors Size Id Type /dev/nvme0n1p1 64 1953525167 1953525104 931.5G 83 Linux Any ideas on how I can get it to show up? Is there any further information that would be useful to share?

