




Chunks
Members
-
Joined
-
Last visited
-
I'm possibly just dumb, but has anyone gotten this working with Open Webui? I can't get it to accept the end point, but I'm really inexperienced with this, so it could be simple. For one thing, when adding the http end point, is there no authentication? I feel like I may be doing it entirely wrong.
-
I got a bit tripped up when installing Pelican, I think it's possible that they've changed the config structure, leading to errors In the UnRaid instructions it says in the config.yml Now it's a slightly different layout (or I just didn't understand the instructions) but there are two blocks to update, I set both to false and that fixed it: You can also set the above from /etc/pelican --> /tmp/pelican And below from /etc/pelican/machine-id --> /tmp/pelican/machine-id I'm not sure if this will have any impact, but at least the server launches now. I haven't actually tried to connect from a client yet, but my network setup is a bit quirky and it tripped me up as well. Once I confirm everythings working I'll try to remember to share.
-
Adminer question - I'm trying to figure out how to get the "permanent login" working. Seems like there's a plugin that's maybe required, but I didn't have any luck getting that going. Also, with no "appdata" folder, I don't really see how the stored db data can be persisted. Any advice on setting up "permanent login"? Specifically the plugin field, if needed. And if there's an "appdata" requirement as well, specifics on what's needed for that would be great. Thanks!
-
Something that only seems to happen on Folders, not individual dockers - the usage summary container seems to be resized dynamically, and part of that function is causing the memory usage to fluctuate between 1 and 2 lines: Normal: Two Lines The result is that the entire page shifts up and down which is visually pretty jarring. It's also phyisically moving the buttons at the bottom of the page up and down which is a bit unexpected as well. Especially as it happens on multiple folders:



-
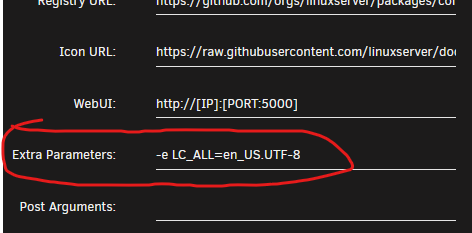
I think I've solved my problem. I went to the Linuxserver's Discord to see if I could find any info, and I actually found a dev that ran into the same problem as me. He reportedly fixed it, but I guess it's back? In any case, everything works except that changedetection.io, using the linuxserver image, has issues with encoding foreign characters. And my website I'm watching is in Swedish. Here's a link to the discord thread. For completeness I'll detail it here too. The symptom (screenshot attached showing Encoding errors): And for me, the fix was to add "-e LC_ALL=en_US.UTF-8" to the "Extra Parameters" field on the Changedetectio.io docker: I'm not sure if this actually breaks stuff or not, but the errors gone at least!

-
I thought I got everything up and running, but I started to have some issues with changedetection. I posted about it on github, and got a reply from the dev (after I explained my configuration) that "browserless is not supposed any more" Now I'm trying to make sense of his reply to me, but I've hit a bit of a wall with regards to my knowledge of things here. Especially since the link he gave me seems to be tweaking the docker-compose.yml file, and I have no idea about that I'm afraid. Should I post this to the changedetection.io app support thread instead?
-
Dumb comment, but I just installed this and I think Unraid has modified how the formatting is handled. When you add/edit the docker image, it shows the "additional requirements" with what I can only guess is a "br" tag with html stripped out: I was really confused what brmeilisearch is, and why I couldn't find and "app" for it. I figured it out eventually, but there you go (maybe this is an Unraid issue, in which case, sorry!)

-
I run MACVLAN and haven't had any problems so far, but I added a new NIC to my PC, so I'm trying to move all my docker images off of eth0. I have a couple simple questions (after reading the docs, I think I'm right, but I would appreciate a sanity check. The "default bridge" on Unraid uses the OS default NIC, or eth0 right? It must, since it shares the IP address of the host which is on eth0. If I'm moving all devices off of eth0, I need to turn on bridging on eth1, and assign all my docker images to br1 - any images using "host" or "bridge" will be stuck on eth0 in the case of moving "default bridge" --> br1, I will need to assign a new individual IP address, they can't share the eth1 IP right? (I've completely rewritten this post a few times based on my progress, sorry if that's confusing, hopefully this is the last re-write as I am more informed than I was at the start.) Cheers, Chunks
-
Thank you so much for this thread. The most challenging part was navigating the Broadcom website to find my firmware. It worked great for my old SAS 9207-8i (even if the newest firmware is 8ish years old at this point, it's newer than what I had )
-
Edit afterwards: the output from "dmesg" is not updated until you reboot. I must have fixed the errors but not seen it. A reboot cleared them from dmesg. --- I was tinkering with an unrelated issue, when I stumbled upon XFS errors. Specifically, I was using dmesg to try to figure out if/where my bluetooth device was As I was scrolling around, I saw a big red block of text: [ 499.522570] XFS (nvme0n1p1): Metadata corruption detected at xfs_dinode_verify+0xa0/0x732 [xfs], inode 0x5d1948 dinode [ 499.526457] XFS (nvme0n1p1): Unmount and run xfs_repair [ 499.530281] XFS (nvme0n1p1): First 128 bytes of corrupted metadata buffer: [ 499.534110] 00000000: 49 4e 81 ed 03 02 00 00 00 00 00 63 00 00 00 64 IN.........c...d [ 499.538029] 00000010: 00 00 00 01 00 00 00 00 00 00 00 00 00 00 00 00 ................ [ 499.541922] 00000020: 66 16 cc 9c 0e c6 a0 a9 66 16 cc 9c 0e e5 25 4b f.......f.....%K [ 499.545811] 00000030: 66 43 1b b8 18 8d a5 60 00 00 00 00 00 03 8e a0 fC.....`........ [ 499.549700] 00000040: 00 00 00 00 00 00 00 39 00 00 00 00 00 00 00 01 .......9........ [ 499.553474] 00000050: 00 00 00 02 00 00 00 00 00 00 00 00 7f 8a 1f c2 ................ [ 499.557119] 00000060: ff ff ff ff fa c0 e6 7b 00 00 00 00 00 00 00 2a .......{.......* [ 499.560735] 00000070: 00 00 16 c2 00 01 46 5a 00 00 00 00 00 00 00 00 ......FZ........ [ 499.752447] XFS (nvme0n1p1): Metadata corruption detected at xfs_dinode_verify+0xa0/0x732 [xfs], inode 0x5d1948 dinode [ 499.756148] XFS (nvme0n1p1): Unmount and run xfs_repair [ 499.759710] XFS (nvme0n1p1): First 128 bytes of corrupted metadata buffer: [ 499.763272] 00000000: 49 4e 81 ed 03 02 00 00 00 00 00 63 00 00 00 64 IN.........c...d [ 499.766895] 00000010: 00 00 00 01 00 00 00 00 00 00 00 00 00 00 00 00 ................ [ 499.770498] 00000020: 66 16 cc 9c 0e c6 a0 a9 66 16 cc 9c 0e e5 25 4b f.......f.....%K [ 499.774107] 00000030: 66 43 1b b8 18 8d a5 60 00 00 00 00 00 03 8e a0 fC.....`........ [ 499.777695] 00000040: 00 00 00 00 00 00 00 39 00 00 00 00 00 00 00 01 .......9........ [ 499.781243] 00000050: 00 00 00 02 00 00 00 00 00 00 00 00 7f 8a 1f c2 ................ [ 499.784709] 00000060: ff ff ff ff fa c0 e6 7b 00 00 00 00 00 00 00 2a .......{.......* [ 499.788173] 00000070: 00 00 16 c2 00 01 46 5a 00 00 00 00 00 00 00 00 ......FZ........ Looked scary, but easy to google, so I found some existing threads and the official docs. I took my array offline, started it again in Maintenance mode, and then ran xfs_repair (in the GUI after removing -n, and on commandline) Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 1 - agno = 2 - agno = 0 - agno = 3 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... done Nothing reportedly found, nor fixed. But every time I run "dmesg" I get the same error. I'm not sure if it's a dmesg thing showing old data? Or if xfs_repair isn't finding my issue? I have not yet tried xfs_repair with the -L flag, as my system seems to be running ok and I'd rather not blow stuff up and that command sounds scary to run on a whim. Any advice on what needs to be done, if anything?
-
I've been having issues getting a successful backup. I tried excluding things and all changing the order of things.... but never had luck. Now, I decided to simply stop ALL dockers before running the backup, and it still failed. A number of files changed somehow? And some other strange errors. 7 total failures. I have quite a lot of images installed, but I figured with NOTHING running, it should complete successfully. Mover isn't running either, not that it should be moving appdata files anyway.. Any protips? Debug log: a5598295-47ea-4c73-b1c7-909c1dc1ea3a
-
I'm trying to figure out why my Unraid machine (NUT 2.8.1, APC ups) stays online during a self test, but my pfSense router (NUT 2.8.2 I think) running as "slave" is shutting itself off. I don't know if the problem is Unraids side, or pfSense's side. The Unraid log (master) shows the following: Dec 19 18:05:56 ChunksUnraid upsmon[11191]: UPS [email protected]: administratively OFF or asleep Dec 19 18:06:05 ChunksUnraid usbhid-ups[11164]: ups_status_set: seems that UPS [chunksups] is in OL+DISCHRG state now. Is it calibrating (perhaps you want to set 'onlinedischarge_calibration' option)? Note that some UPS models (e.g. CyberPower UT series) emit OL+DISCHRG when in fact offline/on-battery (perhaps you want to set 'onlinedischarge' option). Dec 19 18:06:06 ChunksUnraid upsmon[11191]: UPS [email protected]: no longer administratively OFF or asleep Syslog for my pfSense machine (slave) shows: (reverse order, oldest bottom) 2023-12-19 18:06:05 Notification (5) SHUTDOWN power-down by root: 2023-12-19 18:06:02 Error (3) PHP-CGI notify_monitor.php: Message sent to <ME> OK 2023-12-19 18:06:00 Notification (5) UPSMON Auto logout and shutdown proceeding 2023-12-19 18:06:00 Critical (2) UPSMON Executing automatic power-fail shutdown 2023-12-19 18:06:00 Notification (5) UPSMON UPS [email protected].<ME>: administratively OFF or asleep Specifically, I don't know what to do about this line here: How do I set this "onlinedischarge_calibration" option? I looked into the config area of NUT on Unraid, but honestly, I'm a bit uncertain how to set it correctly. Is it in "/etc/nut/upsmon.conf" at the bottom of the NUT page? Any advice?
-
I tested it manually, and I definitely did get an error this time. I still get the "The backup was successful and took 0h, 0m!" message, but this time it was proceeded by an error message. So I really don't know what happened last time. Either the message got eaten somehow, or the conditions were different. Sorry for reporting so quickly.
-
Not a question or a complaint or anything, but I recently added a new "unassigned devices" partition and set it up to be used with Appdata Backup. Tested it out, took almost an hour, worked fine. I had to reboot the server yesterday, and didn't notice I forgot to turn on "auto-mount" for my AppdataBackup partition/drive. So when AppdataBackup ran at it's scheduled time, it didn't do anything. Except that I got a "Success" notification sent to me - Backup done [0h, 0m]! Seemed weird, and then I figured out what happened, but perhaps the tool could confirm the destination path exists?
-
Indeed. device.model: Back-UPS RS 900G Never had issues with "old Nut" but I guess that's because it was using a (much?) older back end.






