





Mizerka
Members
-
Joined
-
Last visited
-
just went through 7.3.1 update, fyi, looks like tailscale broke something when using bridge on the container and it wont open webgui qbit, disconnecting tailscale on local client and its back, not sure why.... I'll worry about it later I guess. service continues working fine in background ofc.
-
its probably been asked and might not be plugin fault but can we stop the plugin from updating to latest version of driver despite hardware not being compatible with it? does it every unraid update, forcing follow up reboot hassle just to set driver back to what it should be. as always, thanks for your work on the plugin.
-
no still on /mnt/user/appdata, it works so its probably fine, just odd behaviour, not seen it auto change path mid navigation like that. if I wasnt clear enough, if I go into container edit, change any path, start going level by level into appdata (now exclusive share, on a zfs pool), /mnt/user/appdata/ works fine, then when I go a level deeper inside the appdata, say binhex-plex/ it will rewrite the path to /mnt/nvmezfs/appdata/binhex-plex/
-
Hey, hoping for some help, somehow manged to get proton wireguard working, after restart its broken again, it seems to briefly connect, complains about dns resolution, kills wireguard int and goes back to complaining about dns. here's what I'm assuming I need config wise docker run -d --name='binhex-qbittorrentvpn' --net='bridge' --pids-limit 2048 --privileged=true -e TZ="Europe/London" -e HOST_OS="Unraid" -e HOST_HOSTNAME="UnRaid" -e HOST_CONTAINERNAME="binhex-qbittorrentvpn" -e 'VPN_ENABLED'='yes' -e 'VPN_USER'='RjIOxxxxxxxxHTQIz+pmp' -e 'VPN_PASS'='bDKoyxxxxxxxxxxxxxxxxxO4rhOl' -e 'VPN_PROV'='protonvpn' -e 'VPN_CLIENT'='wireguard' -e 'STRICT_PORT_FORWARD'='yes' -e 'ENABLE_PRIVOXY'='no' -e 'ENABLE_SOCKS'='no' -e 'SOCKS_USER'='admin' -e 'SOCKS_PASS'='socks' -e 'LAN_NETWORK'='192.168.0.0/24' -e 'WEBUI_PORT'='9080' -e 'VPN_INPUT_PORTS'='' -e 'VPN_OUTPUT_PORTS'='' -e 'DEBUG'='true' -e 'VPN_OPTIONS'='' -e 'ENABLE_STARTUP_SCRIPTS'='no' -e 'USERSPACE_WIREGUARD'='no' -e 'NAME_SERVERS'='1.1.1.1,1.0.0.1' -e 'PUID'='99' -e 'PGID'='100' -e 'UMASK'='000' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='http://[IP]:[PORT:9080]' -l net.unraid.docker.icon='https://raw.githubusercontent.com/binhex/docker-templates/master/binhex/images/qbittorrent-icon.png' -p '9080:9080/tcp' -p '8118:8118/tcp' -p '9118:9118/tcp' -p '58947:58947/tcp' -p '58947:58947/udp' -v paths obfuscated --sysctl="net.ipv4.conf.all.src_valid_mark=1" 'ghcr.io/binhex/arch-qbittorrentvpn' 51e472b9d747fbdaf094278f24cf33553094a3be293847300f98ed61c3c3968a and container logs just look like this, after 12 failures it tries some backup, doesnt say which in debug, builds wireguard as expected and bring webgui up, but after few minutes goes back to failing dns resolutions; any help would be appreciated, thanks for your work on this. also like another person mentioned above mine also spits out 2025-10-29 16:46:47,660 DEBG 'start-script' stdout output: initnatpmp() returned 0 (SUCCESS) using gateway : 10.2.0.1 sendpublicaddressrequest returned 2 (SUCCESS) readnatpmpresponseorretry returned -100 (TRY AGAIN) readnatpmpresponseorretry returned -100 (TRY AGAIN) readnatpmpresponseorretry returned -100 (TRY AGAIN) readnatpmpresponseorretry returned -100 (TRY AGAIN) readnatpmpresponseorretry returned -100 (TRY AGAIN) readnatpmpresponseorretry returned -100 (TRY AGAIN) readnatpmpresponseorretry returned -100 (TRY AGAIN) readnatpmpresponseorretry returned -100 (TRY AGAIN) readnatpmpresponseorretry returned -7 (FAILED) 2025-10-29 16:46:47,660 DEBG 'start-script' stderr output: readnatpmpresponseorretry() failed : the gateway does not support nat-pmp errno=11 'Resource temporarily unavailable' edit; I'm still confused why... but it works again, I have changed to a different proton vpn server for no real reason pretty sure it did nothing, and added in a ton of public resolvers, why is it always dns... 84.200.69.80,37.235.1.174,1.1.1.1,37.235.1.177,84.200.70.40,1.0.0.1
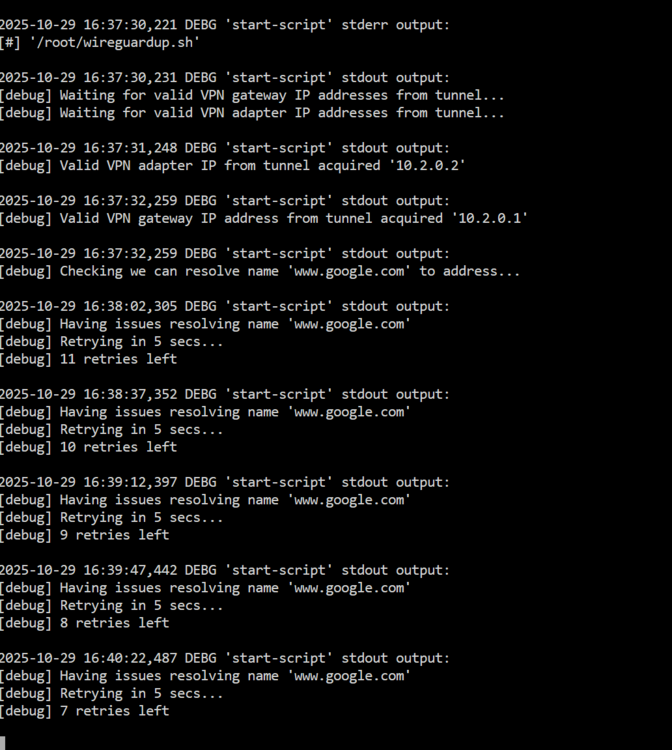
-
seems good so far, shares picked up as exclusive, interestingly, docker template now forces itself to be /mnt/pool/path even when trying to force it via /mnt/user/path. docker view correctly shows /mnt/pool also. cant believe I ran plex without this for years, metadata and scanning is inanely faster now.
-
>all top level folders on any drive will show up as User Shares Ah I get you now, yes makes sense. Thanks both, I will get exclusive shares configured later on today and see how it goes
-
Ahh I see, yes that sounds like what I'm trying to achieve with the /mnt/pool/ paths, I will let plex finish off the library its doing and give that a try, thanks. I should read patch notes more frequently, seems to have been in place back in 6.12. I was mostly testing stuff on plex as thats impact the most atm but I was planning on changing other containers, with this global change should be simpler and easier. Thanks for the info.
-
2nd part I get, and yeah the files only exist on the nvmezfs pool, with no secondary storage. 1st part though, so are you saying that regardless of the path mount I choose, unraid will always display it as a user share path? despite it being told to use a direct disk (pool in this case) in the container build config and seemingly using the direct disk path? I'm happy to accept that as the performance of the plex appdata has increased substantially, going from few mb/s at best to 200mb/s peaks, in app performance is reflecting that also
-
Hey, I'm guessing its a visual bug, on 7.1.4 atm. I'm just doing a lot of plex recahcing and cleaning up metadata, one thing I've noticed my db tends to hang every now and then (put a script in place for now to just reboot container) but also during this I found some reccomendation to change appdata path from /mnt/user/appdata/container to /mnt/cache/appdata/container. I have a zfs pool with all my appdata on it now, stopped container in question, ran the cache writes cmd sync; echo 1 > /proc/sys/vm/drop_caches and adjusted the container path, however in docker view in unraid I can still see the appdata mount path being set to user path, is this expected and just unraid? I'm in middle of more cleanup tasks and it seems to perform better than before.

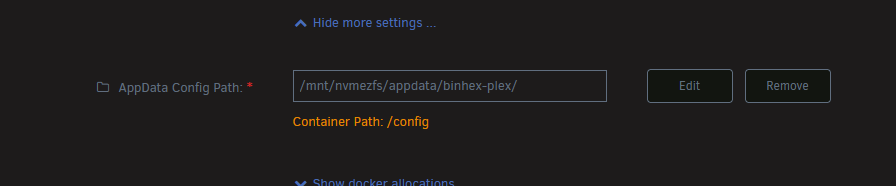
-
got util in line with other 2 disks, this is the behavior of cache>array mover with most free shares and without parity; eventually it will allign with rest of array and bottleneck much closer to cache read rates
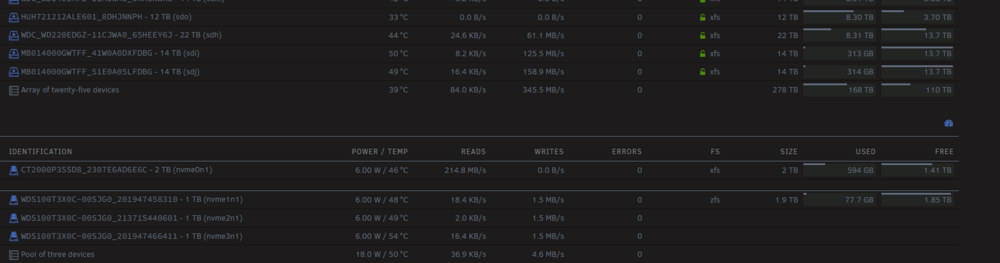
-
actually I think I can think of another hack way of doing this but I dont feel like going down that path... with "preseeding" destination folders, by looking up cache directories, creating empty paths to /mnt/disk../ paths, with correct understanding of my current split levels (its somewhat deep atm), it should achieve read one write many scenario. original problem btw, is that with 2tb cache it just takes a while and cripples new content ingests as cache isn't being used during mover and both cache and new data want to write to the same disk
-
hi both, yeah I understand that having parity is the big bottleneck and impact on array with multiple write could cause with parity having to calc each block etc. and yes writing without parity is reasonably fast, best the single disk can do basically about 180MB for my current most empty disk. with balanced free space across array and with most-free share, its a lot faster, I assume its thanks to split levels rather than writing single files and swapping dest targets, it can write entire subfolders at once. Thanks, I kind of knew what the answer was but wanted to double check
-
Hey, Might be asking for impossible here but just wondering if there's a way I could improve cache offloading/mover to array, atm without parity (yeah ik ik) which should remove the biggest obstacle, and I know for a fact that most filled handles this quite well in a properly balanced least free disk across array as it'll bounce between disks happily saturating cache reads, seen it happen and was happy with it. in a scenario where I've added new disks and balance is off atm and I dont feel like manually fixing it, is it possible to achieve similar to above behavior (read cache to write multiple array disks). Kr Mizerka
-
already tried, and attempted some mariadb recovery. fresh start it is. thanks.
-
upgraded foolishly last night, and mariadb seems to have exploded into bits. Any chance of recovery? or should I just start from scratch? log snips; Unable to connect to DB. ZM Cannot continue. BEGIN failed--compilation aborted at /usr/share/perl5/ZoneMinder/Config.pm line 150. Compilation failed in require at /usr/bin/zmupdate.pl line 74. BEGIN failed--compilation aborted at /usr/bin/zmupdate.pl line 74. DBI connect('database=zm;host=localhost','zmuser',...) failed: Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2) at /usr/share/perl5/ZoneMinder/Database.pm line 110. DBI connect('database=zm;host=localhost','zmuser',...) failed: Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2) at /usr/share/perl5/ZoneMinder/Database.pm line 110. DBI connect('database=zm;host=localhost','zmuser',...) failed: Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2) at /usr/share/perl5/ZoneMinder/Database.pm line 110. Unable to connect to DB. ZM Cannot continue. BEGIN failed--compilation aborted at /usr/share/perl5/ZoneMinder/Config.pm line 150. Compilation failed in require at /usr/share/perl5/ZoneMinder.pm line 33. BEGIN failed--compilation aborted at /usr/share/perl5/ZoneMinder.pm line 33. Compilation failed in require at /usr/bin/zmpkg.pl line 34. BEGIN failed--compilation aborted at /usr/bin/zmpkg.pl line 34. *** /etc/my_init.d/50_firstrun.sh failed with status 255 *** Killing all processes... Starting ZoneMinder: Oct 5 14:57:51 0acc7dd76f45 zmpkg[1608]: ERR [Error reconnecting to db: errstr:Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2) error val:] Oct 5 14:57:51 0acc7dd76f45 zmpkg[1608]: ERR [Error reconnecting to db: errstr:Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2) error val:] ZoneMinder failed to start Starting ZoneMinder: Oct 5 14:57:51 0acc7dd76f45 zmpkg[1608]: ERR [Error reconnecting to db: errstr:Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2) error val:] Oct 5 14:57:51 0acc7dd76f45 zmpkg[1608]: ERR [Error reconnecting to db: errstr:Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2) error val:] ZoneMinder failed to start




