




Stubbs
Members
-
Joined
-
Last visited
-
I have an Nvidia RTX 2070 Super in my server. I also have the Dynamic S3 Sleep Plugin (this plugin is not responsible for the issue). When I put my server to sleep though the UI then wake it up, CUDA crashes within milliseconds, containers that leverage AI either stop working or start using the CPU+System ram. I have replicated this with both the open source driver and the latest driver. When I enter dmesg | grep -B20 -A20 "Xid" in the Unraid terminal, this is the output: dmesg | grep -B20 -A20 "Xid" [ 1820.752171] ata6.00: revalidation failed (errno=-5) [ 1820.752190] ata1.00: qc timeout after 5000 msecs (cmd 0xec) [ 1820.752200] ata1.00: failed to IDENTIFY (I/O error, err_mask=0x4) [ 1820.752203] ata1.00: revalidation failed (errno=-5) [ 1824.032060] ata4: SATA link up 6.0 Gbps (SStatus 133 SControl 300) [ 1824.103300] ata4.00: configured for UDMA/133 [ 1824.239854] ata6: SATA link up 6.0 Gbps (SStatus 133 SControl 300) [ 1824.307231] ata6.00: configured for UDMA/133 [ 1824.743864] ata1: SATA link up 6.0 Gbps (SStatus 133 SControl 300) [ 1824.810567] ata1.00: configured for UDMA/133 [ 1825.616118] ata2: SATA link up 6.0 Gbps (SStatus 133 SControl 300) [ 1825.689735] ata2.00: configured for UDMA/133 [ 1844.924052] docker0: port 3(veth791c2cd) entered blocking state [ 1844.924059] docker0: port 3(veth791c2cd) entered disabled state [ 1844.924067] veth791c2cd: entered allmulticast mode [ 1844.924159] veth791c2cd: entered promiscuous mode [ 1844.929874] eth0: renamed from vethf7a46f8 [ 1844.930313] docker0: port 3(veth791c2cd) entered blocking state [ 1844.930319] docker0: port 3(veth791c2cd) entered forwarding state [ 1852.706530] NVRM: GPU at PCI:0000:08:00: GPU-9619125e-6ae1-e026-121a-d310f1334081 [ 1852.706536] NVRM: Xid (PCI:0000:08:00): 31, pid=6298, name=modprobe, channel 0x08000005, intr 00000000. MMU Fault: ENGINE HOST9 HUBCLIENT_HOST faulted @ 0x1_21010000. Fault is of type FAULT_PDE ACCESS_TYPE_VIRT_READ [ 1852.706742] NVRM: nvGpuOpsReportFatalError: uvm encountered global fatal error 0x60, requiring os reboot to recover. [ 1852.708980] NVRM: Xid (PCI:0000:08:00): 154, GPU recovery action changed from 0x0 (None) to 0x2 (Node Reboot Required) [ 1854.008687] NVRM: Xid (PCI:0000:08:00): 31, pid=6298, name=modprobe, channel 0x09000007, intr 00000000. MMU Fault: ENGINE HOST10 HUBCLIENT_HOST faulted @ 0x1_21070000. Fault is of type FAULT_PDE ACCESS_TYPE_VIRT_READ [ 1854.141606] docker0: port 3(veth791c2cd) entered disabled state [ 1854.141693] vethf7a46f8: renamed from eth0 [ 1854.158438] docker0: port 3(veth791c2cd) entered disabled state [ 1854.159249] veth791c2cd (unregistering): left allmulticast mode [ 1854.159254] veth791c2cd (unregistering): left promiscuous mode [ 1854.159260] docker0: port 3(veth791c2cd) entered disabled state [ 1857.029693] docker0: port 3(vethfd4a51e) entered blocking state [ 1857.029700] docker0: port 3(vethfd4a51e) entered disabled state [ 1857.029710] vethfd4a51e: entered allmulticast mode [ 1857.029843] vethfd4a51e: entered promiscuous mode [ 1857.035564] eth0: renamed from vethb56fa0b [ 1857.035994] docker0: port 3(vethfd4a51e) entered blocking state [ 1857.035999] docker0: port 3(vethfd4a51e) entered forwarding state Diagnostics attached. tower-diagnostics-20260729-0455.zip
-
Ok, --accept-dns was enabled so I set it to false. This fixed the issue of containers like Jellyfin not being able to connect to the internet (curl ifconfig.io now resolves), however pinging to and from the remote server to an unraid docker container still routes over DERP. I have more or less done the same thing by going to Services>UPnP, enabling port mapping and Allow PCP/NAT-PMP Port Mapping and creating an allow rule for the Unraid Server with a port range of 53-65535. This is what the Tailscale Documentation recommends: https://tailscale.com/docs/integrations/firewalls/pfsense
-
Using Bridge Network is not an option. For reasons I don't understand, it has a side effect preventing the container from connecting to the internet, and is only able to resolve machines on the same tailnet. For example, if I set Jellyfin to Bridge Mode, curl ifconfig.io won't resolve, and it won't fetch movie banners and posters, but devices can still connect to it. I tried doing what you suggested, enabling host access to custom network in Docker Settings. Unfortunately it didn't fix the issue. tailscale ping still uses the DERP servers and fails to establish a direct connection. In fact, the same thing applies even when I put the container in Bridge Mode. Everything other than Unraid's docker containers can establish direct connections to this remote server. Even Proxmox LXC containers can directly connect to the remote. This leads me to believe there is something related to Unraid's Tailscale implementation that restricts direct connections over Tailscale.
-
I have installed tailscale into a few of my docker containers using the built-in Unraid 7 tailscale integration in the docker template. If I run tailscale ping nextcloud from a machine on my own internal network (like my desktop PC), it can successfully ping the container directly. But if I try to ping the same Unraid docker container from a remote machine on a different network (this remote machine is running ubuntu server), it always resolves through the DERP servers. I can successfully tailscale ping this remote Ubuntu Server just fine from my desktop PC, my Unraid host, and even LXC containers with tailscale installed from my Proxmox machine on the same network. The only hosts that cannot initiate direct connections to the Ubuntu Server remote are the Unraid Docker Containers with Tailscale enabled in the template. To add some data, here is the output from running tailscale netcheck inside my Nextcloud container: tailscale netcheck 2026/07/22 17:03:11 portmap: monitor: gateway and self IP changed: gw=172.20.0.1 self=172.20.0.3 Report: * Time: 2026-07-22T07:03:12.898630468Z * UDP: true * IPv4: yes, my.wan.IP:47342 * IPv6: no, but OS has support * MappingVariesByDestIP: true * PortMapping: * CaptivePortal: false * Nearest DERP: Sydney * DERP latency: - syd: 22.7ms (Sydney) - sin: 134ms (Singapore) - hkg: 145.4ms (Hong Kong) - tok: 173.1ms (Tokyo) - dbi: 185.3ms (Dubai) I would also like to clarify that I have enabled NAT-PMP on my home router (pfSense) and created ACL allow entries for my tailscale machines (desktop PC, unraid host, etc). If I run the same command on my Unraid Host or my Desktop PC, PortMapping has the value PortMapping: UPnP, NAT-PMP, PCP. All of these Unraid containers (nextcloud, jellyfin, etc) have their Network Type set to Custom : DockerNetwork which is just a custom docker network I created.
-
Hello, I have a Windows 11 PC and an Unraid Server. They both have Mellanox ConnectX-3 network cards installed, and they are connected directly with a 10G DAC Cable. When my Unraid Server goes to sleep and wakes up, the connection no longer works, and mounted shares will no longer function. Resetting network adapters windows-side does nothing. On Unraid, clicking "port down" and "port up" in the network settings does not fix it. The only thing that fixes this is restarting the Unraid server. Is there a way to make sure sleep doesn't kill my 10G connection? Or is there at least a script I can run on wake to ensure it works?
-
I recently installed a 10G NIC on both my Client PC and Unraid Server (and actually got it working this time). On Unraid, my network interfaces are: eth0 - connected to my network switch. This is the motherboard's ethernet port. eth2 - directly connected to my client PC (10G) eth2 is configured with a static IP with my PC endpoint on the same subnet. Transferring files between endpoints works fine. My question: How do I get Unraid to route internet traffic from eth0 to eth2? The reason I ask is because I have two ethernet cables running out of both my PC and Server: one each for a connection to my switch one for the direct connection. This seems inefficient, because if the Unraid server is already connected to the WAN bridge on my Switch, it should be able to route WAN traffic to my PC over the direct 10G connection. The problem is this does not work by default, so I'm wondering what steps I need to take. I looked up an older solution on the forums here that suggested adding the 10G interface to the default network bridge. The problem with this is that it bottlenecks my speed to 750Mbps in iperf3.
-
But at the very least it proves both my NICs and cable are capable of near-10GBe output? Like, my PC motherboard's 2.5G NIC can't replicate this.
-
Someone elsewhere directed me to run iperf with 5 parallel threads, and it looks like it actually saturated most of the 10Gb. So I'm assuming the problem lies somewhere in configuration.
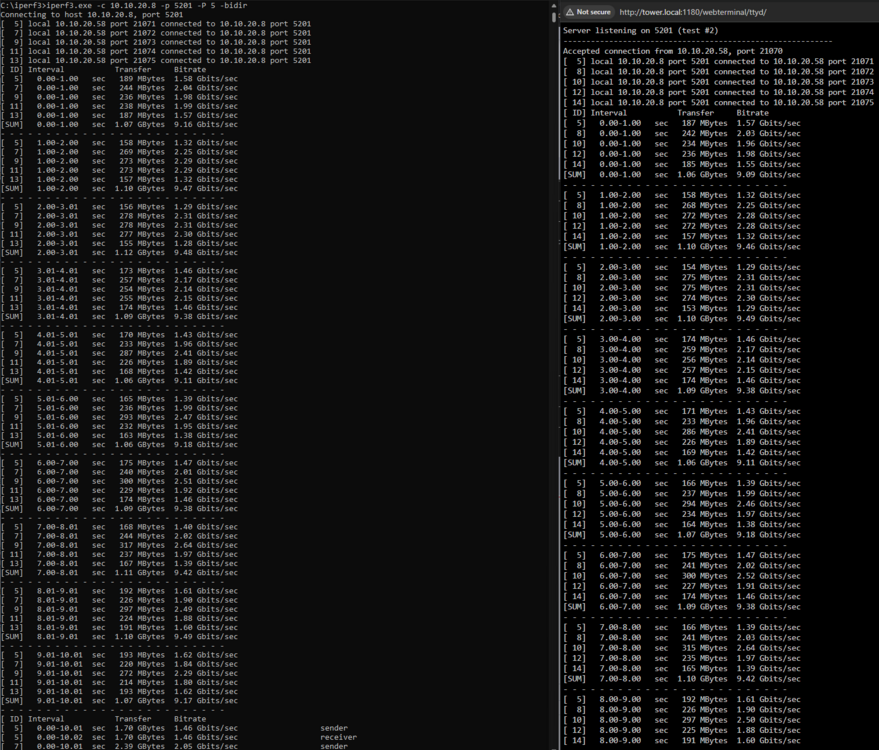
-
-
I've tried on an MX500, a Samsung 870 EVO and even my Intel Optane P1600X. Same speed on all of them. It's mostly a consistent 180MB/s. If anything the slight slowdown is right at the beginning of the transfer. I attached a window screenshot of what a typical transfer looks like.
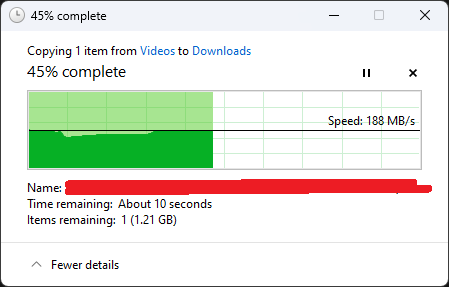
-
Can anyone help identify what is causing the bottleneck here? I installed two 10G NICs in my PC and Unraid Server, made a direct connection between PC and server using the 10G NICs, then configured Unraid to bridge it's two interfaces. I know the link is up and functional, but I'm only getting 188MB/s uploading a video to the server over SMB. I'm uploading to a SATA SSD share so I know disk write isn't the bottleneck. Details of the connection: 10GBase-T Cable: 15m RJ45 CAT7 flat patch PC's 10G Adapter: ASUS XG-C100C (Aquantia AQC107 controller) Server's 10G Adapter: Binardat 10G (also an Aquantia AQC107 controller) Transfer Protocol: SMB - default settings Both NICs have no additional cooling, just their heatsink
-
Having a problem that seems to be persistent across all TorrentVPN containers (delugevpn, qbitorrentvpn, rfloodvpn). If I choose Wireguard as the VPN_Client, the webUI won't load. The IP will resolve in the command line, typing curl ifconfig.io will return a valid IP, but going to it's localdomain:port will return a 'page cannot be found'. This can be resolved by using OpenVPN instead. It's not my VPN provider either, because I can load the conf file in the Windows Wireguard client and it will work fine. It might be something related to Unraid.
-
Does running powertop autotune interrupt with Wake-on-LAN? I've enabled WOL + S3 in my BIOS, have the Unraid S3 Sleep Plugin, and wol is set to g on my eth0's interface(which is my server's network card). Even with all that, I still can't wake it up with a magic packet.
-
Are the Pure Power 11 FM and RM550x still the only known PSUs that are extremely efficient at low loads? I can't buy them anywhere.
-
How do you refresh the admin token? Mine isn't working and I cannot login as an admin. I tried using what was in the .json file in appdata, but it did not work.



