

JesterEE
-
Posts
168 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by JesterEE
-
-
Has this plugin been delisted from CA? Fix Common Problems is showing this after upgrade to 6.12.8 from 6.11.

-
On 1/23/2023 at 12:56 PM, Skitals said:
Do you have Above 4G Decoding enabled in your bios?
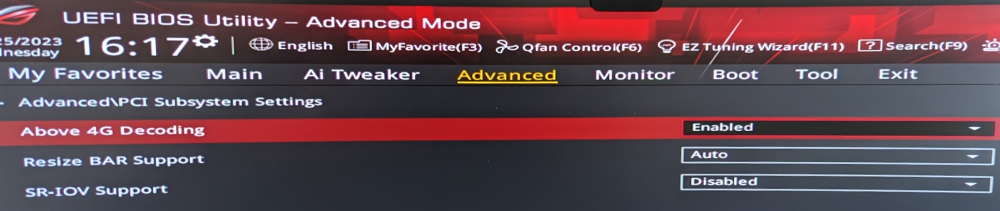
Yes.
Above 4G Decoding: Enabled
Resize BAR Support: Auto (other option is Disabled)
-
Started using a new video card in Unraid this week and noticed the card name and PCIe Gen columns on the first line are overlapping for may card with a long name. Can the card name be truncated depending on the width of the window (and subsequently the column)?

-
On 1/22/2023 at 5:45 AM, Skitals said:
you are trying to set the bar to 16GB when you have 8GB VRAM.
Yup, messed that up in the copypasta while experimenting.
Anyway, not a big deal...it works for me if I want to set the ReBAR to acceptable values lower than the default 256MB (for my card [64MB, 128MB, 256MB]) ... But it will not set them higher (for my card [512MB, 1GB, 2GB, 4GB, 8GB]). If I try and set it to a value lower than 64MB or higher than 256MB I will get the error.
# -bash: echo: write error: Device or resource busy
Here is the is the memory allocation info for my card
# lspci -vvvs 0b:00.0 0b:00.0 VGA compatible controller: NVIDIA Corporation GA104 [GeForce RTX 3070 Lite Hash Rate] (rev a1) (prog-if 00 [VGA controller]) ... Region 0: Memory at fb000000 (32-bit, non-prefetchable) [size=16M] Region 1: Memory at d0000000 (64-bit, prefetchable) [size=256M] Region 3: Memory at c8000000 (64-bit, prefetchable) [size=32M] ... Physical Resizable BAR BAR 0: current size: 16MB, supported: 16MB BAR 1: current size: 256MB, supported: 64MB 128MB 256MB 512MB 1GB 2GB 4GB 8GB BAR 3: current size: 32MB, supported: 32MBThanks for publishing the patch and modified kernel even though it didn't work for me completely. Hope others give it a shot too to report their mileage.
-
54 minutes ago, Skitals said:
Is the pci address of your GPU really the same as mine?
No, I changed the addressed on my side, but I posted the command so it could easily be referenced from your post. Here is my version:
#!/bin/bash echo -n "0000:0b:00.0" > /sys/bus/pci/drivers/vfio-pci/unbind echo 14 > /sys/bus/pci/devices/0000\:0b\:00.0/resource1_resize # <<<< Gets stuck here echo -n "10de 2488" > /sys/bus/pci/drivers/vfio-pci/new_id || echo -n "0000:0b:00.0" > /sys/bus/pci/drivers/vfio-pci/bind
-
@Skitals So I tried the script commands you specified in your previous post, but got stuck when actually sizing the ReBar with:
# echo 14 > /sys/bus/pci/devices/0000\:0d\:00.0/resource1_resize # -bash: echo: write error: Device or resource busy
Did some searching and I couldn't find a way to correct this. Not looking for tech support necessarily, just reporting my experience.
On my system, the video card is bound to VFIO and the system is booting with a syslinux config including
... video=efifb:off ...
-
On 1/6/2023 at 11:30 PM, Skitals said:
I did a little more testing. It looks like the patch isn't needed with the RTX 40 Series.
Tried your patch today with my ASUS KO RTX 3070 and a Windows 10 VM. GPU-Z is still reporting Resizeable Bar as Disabled.
Was there any additional setup needed to set the initial state of the Bar or should it be on by default with the patched kernel?
-
Cross linking to an Unraid support thread where libtorrent (used by deluge) is causing a kernel error on the 6.11 release series. If you are on 6.11.* and see your syslog contain the error shown in this thread accompanied by your deluge/Unraid webUI being unresponsive, you may also be experiencing the same issue. This is not unique to Unraid, but seemingly all distros utilizing newer versions of the Linux v5 kernel.
-
 1
1
-
-
19 hours ago, limetech said:
This release is focused on bug fixes and minor improvements.
Some of us over in this thread would appreciate some of this 6.11 series bug squashing love:
-JesterEE
-
 2
2
-
-
3 minutes ago, ds1414 said:
So since all suggests where pointing towards motherboard power, I swapped the system power supply. It has been two days now and it is running smoothly.
Glad you got something working but I'd hardly consider this a solution given that just 1 OS version before didn't show a hardware issue. So unless the update somehow messed up the physical power supply electronics (extremely unlikely) I'm skeptical this is it.
There are a lot more of us with this issue and I doubt that everyone has faulty hardware. You can track the problem thread here:
-
@JorgeB Thanks for raising this issue up. I will mark this tread as solved while it is tracked on the bug report you created.
As an aside, @trurl pointed a couple of us to his Unraid 6 FAQ in another thread with concern to the Ryzen processor family and stability issues. I have been running a Ryzen 7 3800x for 3 years without issue before my upgrade to a Ryzen 9 5950x. Though to be complete and check the boxes, I under clocked my memory (2133 MHz which is the Auto setting my board sets) and modified the default Auto C-State setting which worked on my 3800x, to the "typical current idle". The same bug showed up so I believe this is unrelated.
I am currently letting my server do a 4th parity check due to all the dirty shutdowns in Safe Mode with the RAM set to 2133MHz and the C-State setting back in Auto. I'll let it sit like that for a couple more days (I'm thinking 60-72hrs uptime) to see if it shows in Safe Mode. If not, I will start working with the plugins @JorgeB itemized in the bug report.
-
1
-
-
I just started getting this error too; very frustrating.
To be transparent, I upgraded my hardware 2 weeks before my upgrade to 6.11.1. So while I thought the hardware is stable after running without issue on 6.10.3 for that time before upgrading, it is possible (though unlikely) that it is not an Unraid issue.
What's interesting is that all 3 of us (so far) use an ASUS motherboard. Maybe it's a coincidence. Maybe it's not.
I am cross posting for traction on my other thread I started here:
-JesterEE
-
Cross post for similar issue reports here:
-
-
Recently after installing Unraid 6.11.0 (and subsequently 6.11.1 in hopes of fixing this issue) my server started reporting kernel NULL pointer dereferencing after about 1-2 days of uptime. This causes:
- The WebUI to become unresponsive (loading indefinitely after "successful login")
-
Some (but not all) on my dockers to become unresponsive
- Dockers like plex and the *arrs seem to stay alive
- Others become unresponsive via their web interfaces but are reported as up via a 'docker container ls' check.
- Non-functional powerdown and poweroff commands (in attempt to reboot without parity check)
It does not seem to impact:- Operation of a VM I have running before, during, and after the error is reported (I'm typing on that VM right now and I had this issue pop up earlier this AM).
- Connection to the server via SSH
For full transparency, I did upgrade my server's hardware (CPU and added RAM) 2 weeks before the 6.11.0 upgrade when operating on 6.10.3. I ran memtest86 on all the RAM for 3 passes after installation so I'm pretty sure that's OK. And 2 weeks of stable Unraid 6.10.3 operation leads me to believe this is unrelated to my hardware upgrade, but I cannot be 100% sure.
Here is the relevant section of the syslog. Diagnostics attached. I have other diagnostics showing the same issue on both 6.11.0 and 6.11.1.
Any help from the gurus appreciated! 🙏
QuoteOct 11 05:02:02 Cogsworth kernel: BUG: kernel NULL pointer dereference, address: 0000000000000076
Oct 11 05:02:02 Cogsworth kernel: #PF: supervisor read access in kernel mode
Oct 11 05:02:02 Cogsworth kernel: #PF: error_code(0x0000) - not-present page
Oct 11 05:02:02 Cogsworth kernel: PGD 0 P4D 0
Oct 11 05:02:02 Cogsworth kernel: Oops: 0000 [#1] PREEMPT SMP NOPTI
Oct 11 05:02:02 Cogsworth kernel: CPU: 3 PID: 29837 Comm: Disk Tainted: P O 5.19.14-Unraid #1
Oct 11 05:02:02 Cogsworth kernel: Hardware name: System manufacturer System Product Name/ROG STRIX X570-E GAMING, BIOS 4403 04/27/2022
Oct 11 05:02:02 Cogsworth kernel: RIP: 0010:folio_try_get_rcu+0x0/0x21
Oct 11 05:02:02 Cogsworth kernel: Code: e8 8e 61 63 00 48 8b 84 24 80 00 00 00 65 48 2b 04 25 28 00 00 00 74 05 e8 9e 9b 64 00 48 81 c4 88 00 00 00 5b c3 cc cc cc cc <8b> 57 34 85 d2 74 10 8d 4a 01 89 d0 f0 0f b1 4f 34 74 04 89 c2 eb
Oct 11 05:02:02 Cogsworth kernel: RSP: 0000:ffffc90002f97cc0 EFLAGS: 00010246
Oct 11 05:02:02 Cogsworth kernel: RAX: 0000000000000042 RBX: 0000000000000042 RCX: 0000000000000042
Oct 11 05:02:02 Cogsworth kernel: RDX: 0000000000000001 RSI: ffff888292672da0 RDI: 0000000000000042
Oct 11 05:02:02 Cogsworth kernel: RBP: 0000000000000000 R08: 0000000000000014 R09: ffffc90002f97cd0
Oct 11 05:02:02 Cogsworth kernel: R10: ffffc90002f97cd0 R11: ffffc90002f97d48 R12: 0000000000000000
Oct 11 05:02:02 Cogsworth kernel: R13: ffff888041111178 R14: 000000000011dd97 R15: ffff888041111180
Oct 11 05:02:02 Cogsworth kernel: FS: 0000149ac3e84b38(0000) GS:ffff88900e8c0000(0000) knlGS:0000000000000000
Oct 11 05:02:02 Cogsworth kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
Oct 11 05:02:02 Cogsworth kernel: CR2: 0000000000000076 CR3: 0000000bc4606000 CR4: 0000000000750ee0cogsworth-diagnostics-20221011-0736.zip
Oct 11 05:02:02 Cogsworth kernel: PKRU: 55555554
Oct 11 05:02:02 Cogsworth kernel: Call Trace:
Oct 11 05:02:02 Cogsworth kernel: <TASK>
Oct 11 05:02:02 Cogsworth kernel: __filemap_get_folio+0x98/0x1ff
Oct 11 05:02:02 Cogsworth kernel: filemap_fault+0x6e/0x524
Oct 11 05:02:02 Cogsworth kernel: __do_fault+0x2d/0x6e
Oct 11 05:02:02 Cogsworth kernel: __handle_mm_fault+0x9a5/0xc7d
Oct 11 05:02:02 Cogsworth kernel: handle_mm_fault+0x113/0x1d7
Oct 11 05:02:02 Cogsworth kernel: do_user_addr_fault+0x36a/0x514
Oct 11 05:02:02 Cogsworth kernel: exc_page_fault+0xfc/0x11e
Oct 11 05:02:02 Cogsworth kernel: asm_exc_page_fault+0x22/0x30
Oct 11 05:02:02 Cogsworth kernel: RIP: 0033:0x149ac6f427b5
Oct 11 05:02:02 Cogsworth kernel: Code: 8b 48 08 48 8b 32 48 8b 00 48 39 f0 73 09 48 8d 14 08 48 39 d6 eb 0c 48 39 c6 73 0b 48 8d 14 0e 48 39 d0 73 02 0f 0b 48 89 c7 <f3> a4 66 48 8d 3d 59 b7 22 00 66 66 48 e8 d9 d8 f6 ff 48 89 28 48
Oct 11 05:02:02 Cogsworth kernel: RSP: 002b:0000149ac3e83960 EFLAGS: 00010216
Oct 11 05:02:02 Cogsworth kernel: RAX: 00001474db777770 RBX: 0000149ac3e83ad0 RCX: 0000000000004000
Oct 11 05:02:02 Cogsworth kernel: RDX: 000014730499b866 RSI: 0000147304997866 RDI: 00001474db777770
Oct 11 05:02:02 Cogsworth kernel: RBP: 0000000000000000 R08: 0000000000000000 R09: 0000149ac3e83778
Oct 11 05:02:02 Cogsworth kernel: R10: 0000000000000008 R11: 0000000000000246 R12: 0000000000000000
Oct 11 05:02:02 Cogsworth kernel: R13: 0000149ac3e83b40 R14: 0000149ac40dc3d0 R15: 0000149ac3e83ac0
Oct 11 05:02:02 Cogsworth kernel: </TASK>
Oct 11 05:02:02 Cogsworth kernel: Modules linked in: xt_CHECKSUM ipt_REJECT nf_reject_ipv4 ip6table_mangle ip6table_nat iptable_mangle vhost_net vhost vhost_iotlb tap tun nvidia_uvm(PO) veth xt_nat xt_tcpudp xt_conntrack nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo xt_addrtype br_netfilter xfs dm_crypt dm_mod dax md_mod nct6775 nct6775_core hwmon_vid iptable_nat xt_MASQUERADE nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 wireguard curve25519_x86_64 libcurve25519_generic libchacha20poly1305 chacha_x86_64 poly1305_x86_64 ip6_udp_tunnel udp_tunnel libchacha ip6table_filter ip6_tables iptable_filter ip_tables x_tables bridge stp llc bonding tls ipv6 igb i2c_algo_bit r8169 realtek nvidia_drm(PO) nvidia_modeset(PO) mxm_wmi wmi_bmof asus_ec_sensors nvidia(PO) edac_mce_amd edac_core kvm_amd kvm crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel aesni_intel crypto_simd cryptd rapl k10temp i2c_piix4 drm_kms_helper ccp drm mpt3sas backlight syscopyarea sysfillrect ahci sysimgblt fb_sys_fops
Oct 11 05:02:02 Cogsworth kernel: libahci corsair_cpro i2c_core raid_class scsi_transport_sas tpm_crb tpm_tis tpm_tis_core tpm wmi button acpi_cpufreq unix [last unloaded: i2c_algo_bit]
Oct 11 05:02:02 Cogsworth kernel: CR2: 0000000000000076
Oct 11 05:02:02 Cogsworth kernel: ---[ end trace 0000000000000000 ]---
Oct 11 05:02:02 Cogsworth kernel: RIP: 0010:folio_try_get_rcu+0x0/0x21
Oct 11 05:02:02 Cogsworth kernel: Code: e8 8e 61 63 00 48 8b 84 24 80 00 00 00 65 48 2b 04 25 28 00 00 00 74 05 e8 9e 9b 64 00 48 81 c4 88 00 00 00 5b c3 cc cc cc cc <8b> 57 34 85 d2 74 10 8d 4a 01 89 d0 f0 0f b1 4f 34 74 04 89 c2 eb
Oct 11 05:02:02 Cogsworth kernel: RSP: 0000:ffffc90002f97cc0 EFLAGS: 00010246
Oct 11 05:02:02 Cogsworth kernel: RAX: 0000000000000042 RBX: 0000000000000042 RCX: 0000000000000042
Oct 11 05:02:02 Cogsworth kernel: RDX: 0000000000000001 RSI: ffff888292672da0 RDI: 0000000000000042
Oct 11 05:02:02 Cogsworth kernel: RBP: 0000000000000000 R08: 0000000000000014 R09: ffffc90002f97cd0
Oct 11 05:02:02 Cogsworth kernel: R10: ffffc90002f97cd0 R11: ffffc90002f97d48 R12: 0000000000000000
Oct 11 05:02:02 Cogsworth kernel: R13: ffff888041111178 R14: 000000000011dd97 R15: ffff888041111180
Oct 11 05:02:02 Cogsworth kernel: FS: 0000149ac3e84b38(0000) GS:ffff88900e8c0000(0000) knlGS:0000000000000000
Oct 11 05:02:02 Cogsworth kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
Oct 11 05:02:02 Cogsworth kernel: CR2: 0000000000000076 CR3: 0000000bc4606000 CR4: 0000000000750ee0
Oct 11 05:02:02 Cogsworth kernel: PKRU: 55555554 -
I have the same issue on my reverse proxied Unraid dashboard, but only on a certain Windows 10 device. The browser loading the content doesn't seem to matter (tried Google Chrome and Microsoft Edge) so I'm thinking its some group policy or something; maybe even an IT security safeguard (i.e. blocker). I looked at the network traffic in the Chrome Debugger and see all the WebSocket traffic coming in; none of which is blocked outright by the browser. But, I am getting errors in the console that look like this:
QuoteWebSocket connection to 'wss://unraid.myserver.com/graphql' failed: WebSocket is closed before the connection is established.
e.close @ unraid.min.js:113So, something is not letting the connections through. I'd like to know how to fix this too, but I have no idea what would be causing this issue outside the browser. My best guess ... an IT deployed "safeguard".
@FlyingTexan, have you tried on a different device?
-
For anyone looking for a currently available FL1100 based USB Controller that works with Unraid, Linux and Windows 10 VMs (haven't tested a macOS VM) check out this one from YEELIYA.
I haven't tested throughput to see what I can get out of it in a real-world test to really push the PCI-E 1x bus, but I have no issues with a keyboard, mouse, webcam and 2 USB sticks working simultaneously.
-
@JorgeB certainly did a lot of the heavy lifting on this one. I have referenced that post multiple times when making my own HBA considerations a few years ago, and it's probably one of the best data driven studies on the subject.
While making your decision, just remember what you're controlling; likely spinning rust (HDDs). Most of these drives you're likely going to use for your data are moderate speeds (5400 RPM) and have an I/O limit of ~100 MB/s in real world application. So, while it may be great that your fancy PCIe 3.0 card doubles performance against the PCIe 2.0 counterpart ... do you really need it given the significantly higher price tag? SDD array, likely yes ... HDD array, probably not.
Also be cognizant of the PCI Express lanes your CPU and motherboard combination offer for the application. Read the fine print on the motherboard specification to make sure you'll be able to use all the lanes that your card offers. It's not uncommon for the lower priority 16x slots to only be able to source 8x/4x speeds given a consumer grade configuration.
-
On 11/22/2019 at 2:38 PM, Skitals said:
USB Passthrough:
Leaving PCIe ACS override disabled, you should have ~34 IOMMU groups (give or take depending on how many PCIe devices you have connected) if you look in Tools > System Devices. There should be 3 USB controllers with the same vendor/device ID (1022:149c). Two of them will be lumped together with a PCI bridge and "Non-Essential Instrumentation." Those are the two we want to pass! The more logical option would be the controller isolated in its own group, but I could NOT get that one to pass. The trick is run your Unraid USB off that third controller, and we can pass the other two controllers together. Run your Unraid USB out of the rear white USB port labeled BIOS. That white USB 3.0 port plus the neighboring 3 blue USB 3.0 ports share a controller. Use these other ports for your keyboard and mouse (to be passed through as devices) and your UPS or whatever else you want Unraid to access.
This USB pass-through write-up is still relevant and I performed it today on my ASUS ROG Strix X570-E on the latest BIOS build (Version 4021) which appears to have an identical architecture as the GIGABYTE X570 AORUS.
One thing to note ... the internal USB headers are also attached to the same controller we are able to pass through. So, if you need to run an internal peripheral and want to keep it attached to the Unraid host (e.g. a fan controller, LED controller, etc.) you're SOL! 😡
There are 2 internal USB2 headers on the board(s), but they are both attached to the same controller. I wish they split them between the controllers, but from a board design and layout standpoint, I understand why they didn't.
-JesterEE
-
22 minutes ago, D0N2k said:
Hey. Thanks for the great project.
Is it normal that the container is using between 7-9GB of Ram?
Something changed in the last update. Not sure what, but this wasn't happening before. I just checked my docker and after a few days or running, and streetmerchant was eating all my RAM. I started limiting the RAM consumption of the docker now. We'll see how this works out.
-
@kiowa2005 This project is updated very regularly. Updating links, adding features, fixing bugs, etc. Is there a way to structure the dockerfile such that users can force an update so the image can pull from the github repo and run the latest code?
-
On 1/7/2021 at 5:45 PM, kiowa2005 said:
This container assumes you are running another proxy service container. I use delugeVPN proxy with PIA VPN. You ensure this container is on the same network as your proxy container, include the IP and port to that proxy container. Many other proxy container options out there.
Using the built in proxy support also works: https://jef.codes/streetmerchant/reference/proxy/
You just have to map the files corectly to the docker:
For example: -v '/mnt/user/appdata/streetmerchant/global.proxies':'/app/global.proxies':'ro'
I use this for amazon so I don't hit the servers too hard and start forcing CAPTCHA requests.
-JesterEE
-
2 minutes ago, kiowa2005 said:
I have not seen that behavior. I usually only monitor newegg, amazon, bestbuy, sony, walmart.
Here are the cards the ASUS store supports. If you have additional product URL's those can be added, just let me know.
3080
https://store.asus.com/us/item/202009AM160000001
https://store.asus.com/us/item/202009AM150000004
https://store.asus.com/us/item/202009AM290000002
3090
Oh there are definitely other cards...I'll get back to you in a while with a list of links.
Are you in the dev team? Do you want me to track this elsewhere (github)?
-
@kiowa2005 Is this container pulling from master or the latest stable release?





VM GPU passthrough resizable BAR support in 6.1 kernel
in Feature Requests
Posted
With the Unraid 6.12 series on Linux kernel 6.1 natively, I decided to finally revisit this topic with my update to 6.12.8.
After the OS update, I checked the lspci output to see if the OS was correctly assigning the correct memory size allocation for my ASUS KO GeForce RTX 3070 V2 OC Edition 8GB. I was pleasantly surprised that without doing anything, it was assigning the resource space to the maximum video memory allotment my card is able to provide (i.e. 8GB) (see full lspci output at bottom of this post).
# lspci -vvvs 0c:00.0 0c:00.0 VGA compatible controller: NVIDIA Corporation GA104 [GeForce RTX 3070 Lite Hash Rate] (rev a1) (prog-if 00 [VGA controller]) Subsystem: ASUSTeK Computer Inc. GA104 [GeForce RTX 3070 Lite Hash Rate] Capabilities: [bb0 v1] Physical Resizable BAR BAR 0: current size: 16MB, supported: 16MB BAR 1: current size: 8GB, supported: 64MB 128MB 256MB 512MB 1GB 2GB 4GB 8GB BAR 3: current size: 32MB, supported: 32MBNote the BAR 1 size is set to 8GB. Before the kernel update (and with the kernel patch referenced in the earlier pages of this thread), it was set to a default of 256MB. All is looking good so far!
I followed the these baseline steps
✅ Host BIOS UEFI w/o CSM
✅ Host BIOS Enable ReBAR support
✅ Host BIOS Enable 4G Decoding
⬛Enable & Boot Custom Kernel syslinux configuration (near beginning of this thread)not needed anymoreBefore modifying my Windows 10 Pro VM configuration, I booted up the VM to see if anything was needed for the Guest OS to recognize ReBAR. I did make sure my guest bios was set to OVMF TPM (regular OVMF provided the same result as shown below though). Windows booted without issue and I ran both GPU-Z 2.57.0 and the NVIDIA Control Panel to check ReBAR support:
This is what I saw:
GPU-Z reported ReBAR as Enabled, but when I went into the Advanced settings, 4G Decode was shown as Disabled in BIOS. NVIDIA Control Panel shows ReBAR an Enabled and shows it's correctly allocating 8GB of dedicated video memory with an additional 16GB of shared memory for 24GB total. If I close the apps and relaunch them, GPU-Z reports differently, showing ReBAR as Disabled with the same advanced details (NVIDIA Control Panel stays reporting ReBAR Enabled with the same details).
I shut down the VM and tried the XML edits noted in this thread and other online spaces talking about VFIO ReBAR:
<domain type='kvm'> ➡️ <domain type='kvm' xmlns:qemu='http://libvirt.org/schemas/domain/qemu/1.0'>
<qemu:commandline>
<qemu:arg value='-fw_cfg'/>
<qemu:arg value='opt/ovmf/X-PciMmio64Mb,string=65536'/>
</qemu:commandline>
After relaunching the VM, I found the results to be the same. So, this is interesting in that the XML may not be required for ReBAR anymore either. However, since I'm getting inconsistent reporting using GPU-Z and the NVIDIA Control Panel, I can't be sure.
I think I trust NVIDIA Control Panel more than GPU-Z on this one even though GPU-Z has never steered me wrong in the past. I figure the hardware vendors driver information software probably knows better and GPU-Z is looking at some inconsistent information and reporting incorrectly. But, I think putting a synthetic benchmark to test Host BIOS setting differences is probably called for in this scenario (ReBar and 4G Decoding On vs Off). I'll report some of that in a follow-up post.
Anyone else see something similar to what I'm seeing and have verified ReBAR functional in their VM?
-JesterEE
# lspci -vvvs 0c:00.0 0c:00.0 VGA compatible controller: NVIDIA Corporation GA104 [GeForce RTX 3070 Lite Hash Rate] (rev a1) (prog-if 00 [VGA controller]) Subsystem: ASUSTeK Computer Inc. GA104 [GeForce RTX 3070 Lite Hash Rate] Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+ Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx- Latency: 0, Cache Line Size: 64 bytes Interrupt: pin A routed to IRQ 141 IOMMU group: 30 Region 0: Memory at fb000000 (32-bit, non-prefetchable) [size=16M] Region 1: Memory at 7c00000000 (64-bit, prefetchable) [size=8G] Region 3: Memory at 7e00000000 (64-bit, prefetchable) [size=32M] Region 5: I/O ports at f000 [size=128] Expansion ROM at fc000000 [disabled] [size=512K] Capabilities: [60] Power Management version 3 Flags: PMEClk- DSI- D1- D2- AuxCurrent=0mA PME(D0+,D1-,D2-,D3hot+,D3cold-) Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME- Capabilities: [68] MSI: Enable+ Count=1/1 Maskable- 64bit+ Address: 00000000fee00000 Data: 0000 Capabilities: [78] Express (v2) Legacy Endpoint, MSI 00 DevCap: MaxPayload 256 bytes, PhantFunc 0, Latency L0s unlimited, L1 <64us ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+ DevCtl: CorrErr+ NonFatalErr+ FatalErr+ UnsupReq+ RlxdOrd+ ExtTag+ PhantFunc- AuxPwr- NoSnoop- FLReset- MaxPayload 256 bytes, MaxReadReq 512 bytes DevSta: CorrErr- NonFatalErr- FatalErr- UnsupReq- AuxPwr- TransPend- LnkCap: Port #0, Speed 16GT/s, Width x16, ASPM L0s L1, Exit Latency L0s <512ns, L1 <16us ClockPM+ Surprise- LLActRep- BwNot- ASPMOptComp+ LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt- LnkSta: Speed 2.5GT/s (downgraded), Width x8 (downgraded) TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt- DevCap2: Completion Timeout: Range AB, TimeoutDis+ NROPrPrP- LTR- 10BitTagComp+ 10BitTagReq+ OBFF Via message, ExtFmt- EETLPPrefix- EmergencyPowerReduction Not Supported, EmergencyPowerReductionInit- FRS- AtomicOpsCap: 32bit- 64bit- 128bitCAS- DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis- LTR- 10BitTagReq- OBFF Disabled, AtomicOpsCtl: ReqEn- LnkCap2: Supported Link Speeds: 2.5-16GT/s, Crosslink- Retimer+ 2Retimers+ DRS- LnkCtl2: Target Link Speed: 16GT/s, EnterCompliance- SpeedDis- Transmit Margin: Normal Operating Range, EnterModifiedCompliance- ComplianceSOS- Compliance Preset/De-emphasis: -6dB de-emphasis, 0dB preshoot LnkSta2: Current De-emphasis Level: -3.5dB, EqualizationComplete+ EqualizationPhase1+ EqualizationPhase2+ EqualizationPhase3+ LinkEqualizationRequest- Retimer- 2Retimers- CrosslinkRes: unsupported Capabilities: [b4] Vendor Specific Information: Len=14 <?> Capabilities: [100 v1] Virtual Channel Caps: LPEVC=0 RefClk=100ns PATEntryBits=1 Arb: Fixed- WRR32- WRR64- WRR128- Ctrl: ArbSelect=Fixed Status: InProgress- VC0: Caps: PATOffset=00 MaxTimeSlots=1 RejSnoopTrans- Arb: Fixed- WRR32- WRR64- WRR128- TWRR128- WRR256- Ctrl: Enable+ ID=0 ArbSelect=Fixed TC/VC=01 Status: NegoPending- InProgress- Capabilities: [258 v1] L1 PM Substates L1SubCap: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ L1_PM_Substates+ PortCommonModeRestoreTime=255us PortTPowerOnTime=10us L1SubCtl1: PCI-PM_L1.2- PCI-PM_L1.1- ASPM_L1.2- ASPM_L1.1- T_CommonMode=0us LTR1.2_Threshold=0ns L1SubCtl2: T_PwrOn=10us Capabilities: [128 v1] Power Budgeting <?> Capabilities: [420 v2] Advanced Error Reporting UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol- UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol- UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO- CmpltAbrt- UnxCmplt- RxOF+ MalfTLP+ ECRC- UnsupReq- ACSViol- CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr- CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr+ AERCap: First Error Pointer: 00, ECRCGenCap- ECRCGenEn- ECRCChkCap- ECRCChkEn- MultHdrRecCap- MultHdrRecEn- TLPPfxPres- HdrLogCap- HeaderLog: 00000000 00000000 00000000 00000000 Capabilities: [600 v1] Vendor Specific Information: ID=0001 Rev=1 Len=024 <?> Capabilities: [900 v1] Secondary PCI Express LnkCtl3: LnkEquIntrruptEn- PerformEqu- LaneErrStat: 0 Capabilities: [bb0 v1] Physical Resizable BAR BAR 0: current size: 16MB, supported: 16MB BAR 1: current size: 8GB, supported: 64MB 128MB 256MB 512MB 1GB 2GB 4GB 8GB BAR 3: current size: 32MB, supported: 32MB Capabilities: [c1c v1] Physical Layer 16.0 GT/s <?> Capabilities: [d00 v1] Lane Margining at the Receiver <?> Capabilities: [e00 v1] Data Link Feature <?> Kernel driver in use: vfio-pci Kernel modules: nvidia_drm, nvidia