

905jay
-
Posts
55 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by 905jay
-
-
Thank you @JorgeB would it also make sense to have the dives never spin down?
I am on unraid 6.12.8, and this was reported as being an issue on 6.9
-
I woke up this morning to a similar issue.
12TB Ironwolf Parity
5x8TB Ironwolf data
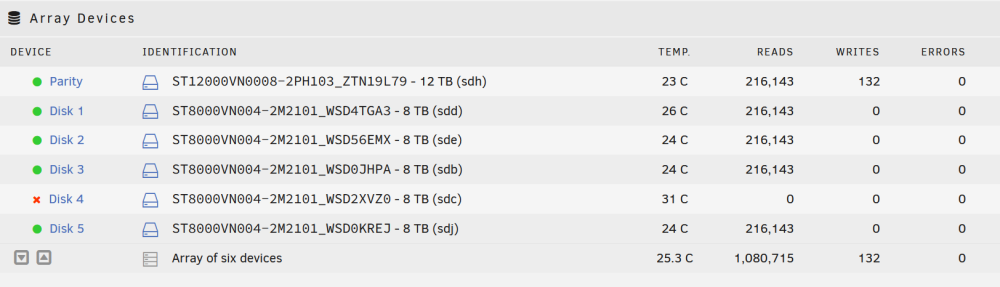
/dev/sdc is disabled contents emulated.
Server is in a 42u cabinet and hasn't moved or otherwise jostled so while I presently have not checked SATA and Power to the disk, I don't suspect that being an issue, but will be happy to. I just don't want to power down the server unless I know it's safe to do so.
The disks aren't 2 years old, and were all pre-cleared prior to adding to the server.
I started in Maintenance and did an fs check and repair, and SMART shows no errors.
Extended SMART has been running for about 6 hours and is currently at 80%, but was hoping I could seek some expert assistance in the meantime.
Diagnostic from yesterday is attached, running another for today also.
This is the Disk Log for /dev/sdc
Mar 17 00:25:44 unraid emhttpd: spinning down /dev/sdc Mar 17 01:36:25 unraid emhttpd: read SMART /dev/sdc Mar 17 02:37:08 unraid emhttpd: spinning down /dev/sdc Mar 17 04:00:01 unraid emhttpd: read SMART /dev/sdc Mar 17 05:41:54 unraid emhttpd: spinning down /dev/sdc Mar 17 09:16:33 unraid emhttpd: read SMART /dev/sdc Mar 17 10:20:19 unraid emhttpd: spinning down /dev/sdc Mar 17 13:36:33 unraid emhttpd: read SMART /dev/sdc Mar 17 14:36:54 unraid emhttpd: spinning down /dev/sdc Mar 17 21:21:35 unraid emhttpd: read SMART /dev/sdc Mar 17 22:23:48 unraid emhttpd: spinning down /dev/sdc Mar 17 23:26:36 unraid emhttpd: read SMART /dev/sdc Mar 18 00:28:39 unraid emhttpd: spinning down /dev/sdc Mar 18 01:36:51 unraid kernel: sd 11:0:1:0: [sdc] tag#737 CDB: opcode=0x85 85 06 20 00 00 00 00 00 00 00 00 00 00 40 e5 00 Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#752 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=7s Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#752 Sense Key : 0x2 [current] Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#752 ASC=0x4 ASCQ=0x0 Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#752 CDB: opcode=0x88 88 00 00 00 00 00 c6 4e 37 48 00 00 00 08 00 00 Mar 18 01:36:55 unraid kernel: I/O error, dev sdc, sector 3327014728 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 2 Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#753 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=18s Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#753 Sense Key : 0x2 [current] Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#753 ASC=0x4 ASCQ=0x0 Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#753 CDB: opcode=0x88 88 00 00 00 00 00 c6 4d 6d 30 00 00 00 08 00 00 Mar 18 01:36:55 unraid kernel: I/O error, dev sdc, sector 3326962992 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 2 Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#754 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#754 Sense Key : 0x2 [current] Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#754 ASC=0x4 ASCQ=0x0 Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#754 CDB: opcode=0x88 88 00 00 00 00 00 c5 97 90 d8 00 00 00 20 00 00 Mar 18 01:36:55 unraid kernel: I/O error, dev sdc, sector 3315044568 op 0x0:(READ) flags 0x0 phys_seg 4 prio class 2 Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#757 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#757 Sense Key : 0x2 [current] Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#757 ASC=0x4 ASCQ=0x0 Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#757 CDB: opcode=0x88 88 00 00 00 00 00 c6 13 63 b8 00 00 00 20 00 00 Mar 18 01:36:55 unraid kernel: I/O error, dev sdc, sector 3323159480 op 0x0:(READ) flags 0x0 phys_seg 4 prio class 2 Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#758 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#758 Sense Key : 0x2 [current] Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#758 ASC=0x4 ASCQ=0x0 Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#758 CDB: opcode=0x88 88 00 00 00 00 02 00 05 a0 60 00 00 00 10 00 00 Mar 18 01:36:55 unraid kernel: I/O error, dev sdc, sector 8590303328 op 0x0:(READ) flags 0x0 phys_seg 2 prio class 2 Mar 18 01:36:55 unraid emhttpd: read SMART /dev/sdc Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#761 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#761 Sense Key : 0x2 [current] Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#761 ASC=0x4 ASCQ=0x0 Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#761 CDB: opcode=0x8a 8a 00 00 00 00 00 c6 4e 37 48 00 00 00 08 00 00 Mar 18 01:36:55 unraid kernel: I/O error, dev sdc, sector 3327014728 op 0x1:(WRITE) flags 0x0 phys_seg 1 prio class 2 Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#763 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#763 Sense Key : 0x2 [current] Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#763 ASC=0x4 ASCQ=0x0 Mar 18 01:36:55 unraid kernel: sd 11:0:1:0: [sdc] tag#763 CDB: opcode=0x8a 8a 00 00 00 00 00 c5 97 90 d8 00 00 00 20 00 00 Mar 18 01:36:55 unraid kernel: I/O error, dev sdc, sector 3315044568 op 0x1:(WRITE) flags 0x0 phys_seg 4 prio class 2 Mar 18 02:36:58 unraid emhttpd: spinning down /dev/sdc Mar 21 21:07:43 unraid emhttpd: spinning up /dev/sdc Mar 21 21:07:58 unraid kernel: sd 11:0:1:0: [sdc] tag#1285 CDB: opcode=0x85 85 06 20 00 00 00 00 00 00 00 00 00 00 40 e3 00 Mar 21 21:08:02 unraid emhttpd: sdspin /dev/sdc up: 22 Mar 21 21:08:02 unraid emhttpd: read SMART /dev/sdc Mar 22 14:20:14 unraid emhttpd: read SMART /dev/sdc Mar 22 14:23:10 unraid emhttpd: ST8000VN004-2M2101_WSD2XVZ0 (sdc) 512 15628053168 Mar 22 14:23:10 unraid kernel: mdcmd (5): import 4 sdc 64 7814026532 0 ST8000VN004-2M2101_WSD2XVZ0 Mar 22 14:23:10 unraid kernel: md: import disk4: (sdc) ST8000VN004-2M2101_WSD2XVZ0 size: 7814026532 Mar 22 14:23:10 unraid emhttpd: read SMART /dev/sdc Mar 22 14:47:04 unraid emhttpd: read SMART /dev/sdc Mar 22 14:47:07 unraid emhttpd: ST8000VN004-2M2101_WSD2XVZ0 (sdc) 512 15628053168 Mar 22 14:47:07 unraid kernel: mdcmd (5): import 4 sdc 64 7814026532 0 ST8000VN004-2M2101_WSD2XVZ0 Mar 22 14:47:07 unraid kernel: md: import disk4: (sdc) ST8000VN004-2M2101_WSD2XVZ0 size: 7814026532 Mar 22 14:47:07 unraid emhttpd: read SMART /dev/sdc -
8 hours ago, MAM59 said:
Nono 🙂
(maybe my bad english was not clear enough once more)
ZFS itself is ok, but when used in the Array and with Parity Drives, it becomes an IO Hog and the system slows down enourmously.
ZFS is always "working in the background", so every few second it tries to optimize the drives. If there are many ZFS drive (single ZFS, not a ZFS-RAID-Array) they work independent of each other, stepping around wildly. This would not harm anything, they only do this on leisure time.
But there is a Parity Drive (which ZFS is not aware of), that needs to follow all these "optimizations" and this really sums up and brings IO to the limit in some situations.
ZFS on a cache drive is ok, but wasted. Cache drives are usually very fast (at least they should be) and SSDs so there is no benefit from the optimizations.
Your English is perfect, I didn't deliver the message correctly @MAM59.
I will add that correction: ZFS is perfectly fine for non parity protected disks, however with a parity disk (or 2 parity disks) it is more if a drawback in the array, than a benefit.
The reason it is a drawback in the array is because ZFS performs optimizations and self-correcting. And every optimization and correction has to be written to parity (or 2 parity disks in my case) which was causing high IO and high CPU use.
-
@Squid reading through this thread, I can see that my IOwait is over 20, sometimes close to 30 (or more)
I made the bone-headed move of evacuating my 4 array disks one at a time, and changing them to ZFS because I figured that was smart.
@MAM59 corrected me due to very painfully slow transfer speeds of 16-20 MB/s on my array, that ZFS was the culprit and I should re-convert all my disks back to XFS.
All my array disks were Seagate Ironwolf 8TB CMR 7200k (2 parity, 4 array) attached via LSI SAS-9211-8i HBA with breakout cables.
I performed an offsite backup or the critically important data, backed up the flash, did a new config process, and unassigned the 2 parity disks.
I will be replacing the 2 8TB parity disks, with a single Ironwolf 12TB (still nervous about 2 parity being overkill but I'll submit)
Now I am evacuating disk 1-4 of the array and reformatting them back to XFS.
Disk 1 is complete and is XFS, and I am moving all the data from Disk 2, over to 1 at approx. 160 MB/s.
All this being said, I followed @SpaceInvaderOne video on converting the cache NVME (Samsung 990 Pro 1TB ) to ZFS, and thought I'd be smart and also do all 4 array disks. Reading about TRIM support, and high IOWait times, Is this a recommended setup having the cache NVME as ZFS? The final outcome will look like this:
Parity: Ironwolf 12TB
Array: 4x Ironwolf 8TB (XFS)
Cache: Samsung 990 Pro (ZFS)
Should I convert that cache NVME back to xfs also? My end goal is to protect against a disk failure with parity but still have a somewhat decent array transfer speeds with relatively low CPU and IOWait. This server doesn't host any VMs at all.
16-20 MB/s was disgusting, and my IOWait is far too high so I'm trying to narrow down where my issue lies.

-
thanks for all the help @MAM59 and @JorgeB
Just to round things off...
The official suggestion from @MAM59 is that the unraid array should NOT be ZFS and should remain as XFS (or BTRFS if you're brave)
I will begin the arduous process or converting all my array disks back to XFS.
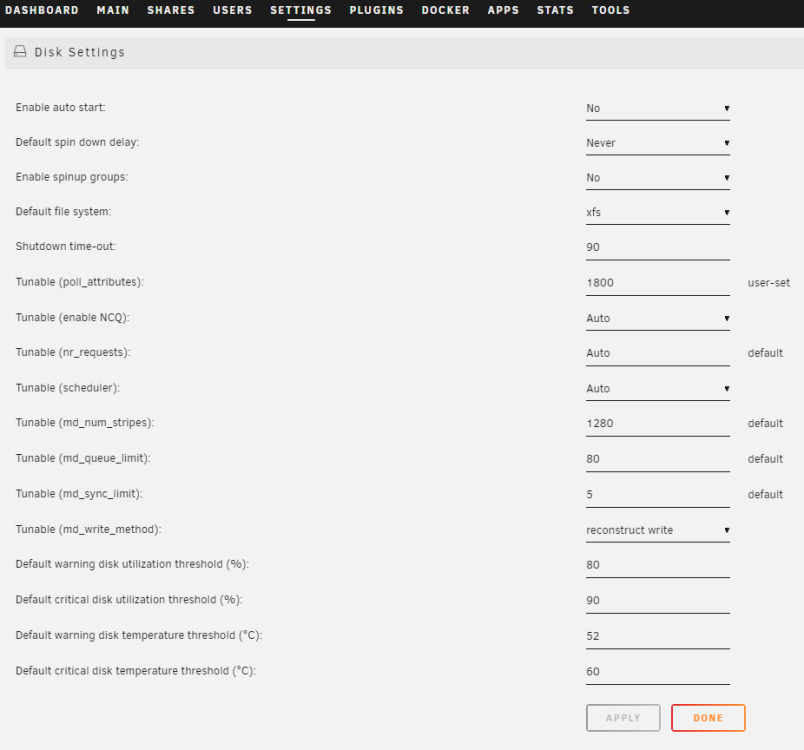
I have turbo write enabled, and in the Disk Settings, I have it set to reconstruct write
I will perform the following actions.
- Remove 1 parity disk
- Allocate the removed parity disk to the array as Disk 5 with XFS
- Let parity sync complete
- Evacuate ZFS Disk1 to XFS Disk5
- Format Disk 1 to XFS
- Continue the disk evacuation and format process until all array disks are back to XFS
Aside from this painfully long process is there anything else I should do or tune?
Am I missing anything?
Would there be a faster way for me to complete the process of moving all that data around and reformatting disks and moving the data back onto them?
Right now my transfer speeds have dropped to 15mb/s. This is going to be an extremely painful process....
Any suggestions?
-
@JorgeB does this correlate to my other post about the painfully slow transfers in any way?
-
6 minutes ago, MAM59 said:
what are those 2 "cache" drives good for?
For "cache" you should use fast (as fast as possible) drives and not slower ones than the one of the main array. (your main disks turn around with 7200 RPM whereas your cache is slow with 5640 RPM, thats just pain and no gain)
So its "slow down" instead of "speed up"
stop the copy, turn off cache, restart the copy (using the same parameters as before, it will skip already moved files and just continue from where it was stopped) and see if there is a speed improvement.
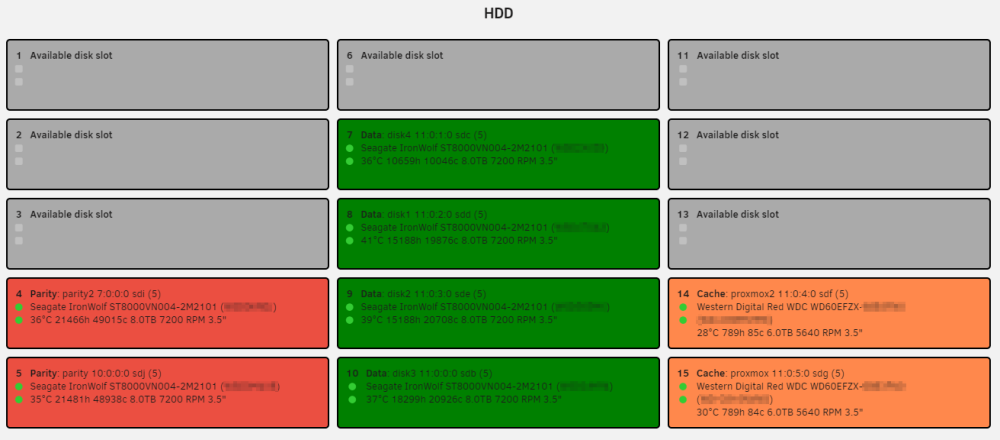
The two WD RED 6TB drives are used for my ProxMox backups that are shipped to unraid over a 10G DAC.
They aren't used in unraid in any cache capacity other than a place to sit until backups kick off at 3am.
my appdata and downloads sit on a Samsung 980 Pro (not pictured)
-
52 minutes ago, MAM59 said:
one reason is speed. write speed is cut down by ~50% per parity disk. So you end up with around 25% of the max with 2 parity disks
The next reason is "parity + zfs dont go well together". Zfs does not know anything about the parity disk, worst case are many data drives with single zfs each (not an zfs array but every disk with its own zfs file system). These ZFS drives have no clue about each other (and the parities too of course). ZFS is allocating new Blocks quite randomly (not sequential), so it happens that D1 steps to sector 3444, D2 to sector 9999, D3 to 123123 and so on. Poor Parities have to follow these steps to keep up with the data. This results in an enourmous amount of stepping (watch the temperature of your parity, you will see a difference to the data drives). Of course this will slow down the data writes greatly too, even down to 0% if io is overrun.
The cleverness of ZFS and the parity of UNRAID give a real bad couple.
Ok, still not knowing why you were down to 30/Mb with xfs. Jorge should take a look at your diagnostics I think, he is the driver/disk/controller specialist here
I just wanted to mention that in terms of the temperatures I don't see much difference, even during this current data move I'm doing

-
13 minutes ago, JorgeB said:
This is incorrect, zfs is faster with pools, with the array it should be the same speed as the other filesystem, due to the existing issue it's slower, but it will never be faster.
Initially with the previous setup (below) my transfer speeds were around 30mb/s when moving data around/between the disks
2 Ironwolf 8TB Parity
4 Ironwolf 8TB Array (XFS)
This was the reason I moved to ZFS to begin with, was because those speeds were utterly unacceptable. Now relizing that this was in-fact a mistake I can begin the long process of reverting all the array disks to XFS.
So now moving all the array disks back to XFS, and dropping down to 1 Parity disk, what else do I need to do in your collective opinions to realize something close to proper transfer speeds?
Does anything here look off to you folks? Or is there something I need to tune, or perhaps I may have changed at some point in the past that's messing with my speeds?
-
1 minute ago, itimpi said:
The speed gains are when it is used in a multi-drive pool outside the main array. If you are interest in this then it is quite likely that you will create an array of HDD using ZFS and not bother with the main Unraid array. Although this will perform faster there are downsides such as having all drives always spinning and less flexibility on expansion.
Have you tried setting Turbo write for the array? That would normally get you far better speeds than the 30MB/s that you quote (albeit at the expense of having all drives spun up).
Yes I have enabled turbo write and set it to reconstruct write
-
1 minute ago, MAM59 said:
Dunno, I have no connection to limetech. I just fell into the same trap as you did now (but my speed was ~80Mb/s down from normal 280MB/s)
The stepping problem cannot be fixed unless they find a way to get the free running zfs disks synced somehow. But this would mean you have to build a RAIDZ array and can forget about UNRAID's parity completely (and lose the freedom to add disks of any size (...up to the size of the parity drive). So this would kill their own business.
My hope for zfs was that it contains a read cache, but it does not help if anything else slows down to a slimy snail...
What works is zfs in a pool device (but again, there is no real benefit as pools are on SSDs/NVMes usually, fast enough without tricks).
BTRFS is an option but some reports here give it a quite bad reputation (data loss). ZFS was introduced to replace BTFRS in UNRAID.
So XFS is the only real and safe harbour currently (my data is valuable too, I don't take risks with them).
Maybe Jorge finds the knot to untie your machine.
@JorgeB would you be able to provide any input on top of the information provided by @MAM59 ?
If the painful move back to XFS is a necessary evil, I'll start the process right away.
Please validate the order of operations be for my own sanity, clarity and consistency:
- Remove 1 parity disk
- Re-run a parity sync (is this step necessary?)
- Allocate the removed parity disk to the array as Disk 5 with XFS
- Evacuate ZFS Disk1 to XFS Disk5
- Format Disk 1 to XFS
- Continue the disk evacuation and format process until all array disks are back to XFS
Am I missing anything?
-
2 minutes ago, MAM59 said:
one reason is speed. write speed is cut down by ~50% per parity disk. So you end up with around 25% of the max with 2 parity disks
The next reason is "parity + zfs dont go well together". Zfs does not know anything about the parity disk, worst case are many data drives with single zfs each (not an zfs array but every disk with its own zfs file system). These ZFS drives have no clue about each other (and the parities too of course). ZFS is allocating new Blocks quite randomly (not sequential), so it happens that D1 steps to sector 3444, D2 to sector 9999, D3 to 123123 and so on. Poor Parities have to follow these steps to keep up with the data. This results in an enourmous amount of stepping (watch the temperature of your parity, you will see a difference to the data drives). Of course this will slow down the data writes greatly too, even down to 0% if io is overrun.
The cleverness of ZFS and the parity of UNRAID give a real bad couple.
Ok, still not knowing why you were down to 30/Mb with xfs. Jorge should take a look at your diagnostics I think, he is the driver/disk/controller specialist here
I unfortunately don't have any diagnostics from before I converted all the array disks to ZFS.
So will these quirks be fixed in a later release in terms in terms of Parity and ZFS playing nicely together?
Or is this just a nature of the beast and I should most certainly move back to XFS?
Would it be better to create BTRFS on the array disks instead of XFS?
-
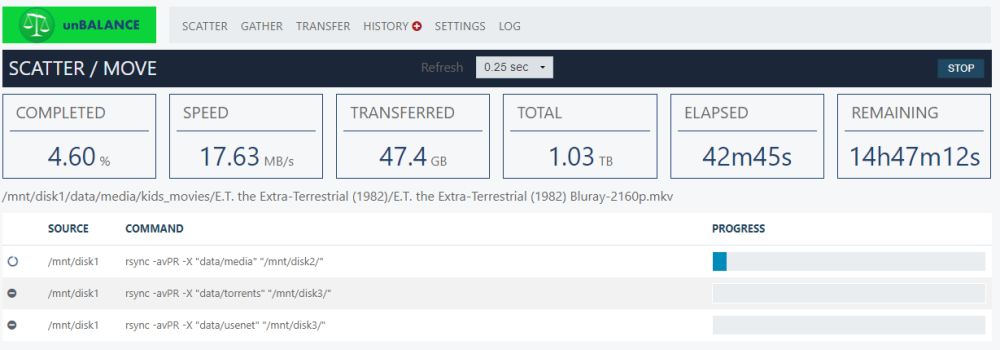
at this rate it will take close to 16 hours to move 1TB of data.
-
6 minutes ago, itimpi said:
Note that having 2 parity drives does not protect you from data loss - it just provides protection against drives failing. There are lots of other ways to lose data. You still need a robust backup strategy for anything important. It may be that the second parity drive is better used as an off-array backup.
I completely understand that and I do have a backup strategy in place.
But unless there is a compelling reason to remove one, I see no reason to do so.
I don't want to mess with the parity or the array in that regard.
I was previously using 2 WD RED 6TB Parity disks, and I had 2 RED 6TB, 2 RED 4TB, 2 RED 3TB disks, and I had 2 of them fail at the exact same time. WD took close to a year to send me the warrantied disks and it caused me HUGE headaches.Long winding story, but I have experience losing 2 disks at the same time, and it was a nightmare for me.
And knowing that it's happened once, I know it can happen again.
Edited the note above as after I read it I realized it sounded snippy on my part without the additional context (wasn't trying to be a dick)")
-
1 minute ago, MAM59 said:
You have done nothing wrong. And these crawl speeds will continue even after the transfer is finished someday.
"isnt a viable option" isnt a viable option 🙂 Only the way back guarantees you normal speeds again someday (it took me 2 weeks to clean up that zfs mess again)
Even with XFS my speeds were only around 30mb/s
This was the reason I moved to ZFS to begin with, was because of the supposed speed gains.
So if XFS was giving me 30mb/s
and ZFS is giving me under 20mb/sWhat is the actual solutions here?
Not saying you're wrong, but I don't feel the advice is entirely accurate
-
9 hours ago, MAM59 said:
Be aware that "zfs in the array" is currently a real killer for UNRAID. There is a bug that slows down everything to snail speed. It does not hit everyone, but if you have it, you are alone.
The only thing that "worked" so far (for me and others) is to revert to xfs and finally "modprobe -r zfs" to get rid completely from this evildoer...
BTW: TWO parity disks for just 4 data drives??? sounds a bit like overkill to me...
2 parity drives isn't overkill. My use case for unRAID is much more than downloaded Linux torrents
I have moved off of OneDrive /Google Drive /Google Photos. This server has my life on it and irreplaceable memories and documents.
-
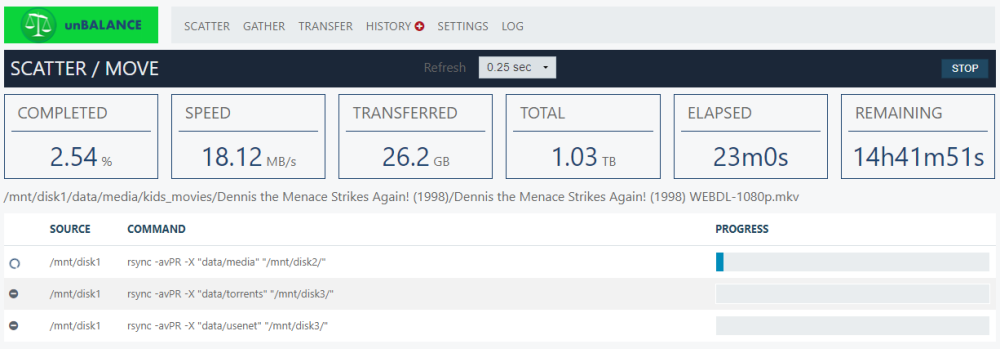
Reverting back to XFS isn't a viable option considering how long these transfers are taking. But these transfer speeds are nowhere near to being acceptable.
Have I misconfigured something that would be causing these speeds?
-
4 hours ago, JorgeB said:
You can try changing everything you can to user disk shares instead, or the new exclusive shares.
Thanks @JorgeB for the info. Would this be something that I may have changed somehow, and your're recommending that I change back to `user disk shares` or exclusive shares?
I'm not familiar with either but let me google and see what I find.
Is there a benefit /drawback to doing either approach?
-
Hello everyone, another post looking for help on another issue.
It may very well be a bad configuration on my part, and if so I will gladly take some advice on where I may be going wrong.
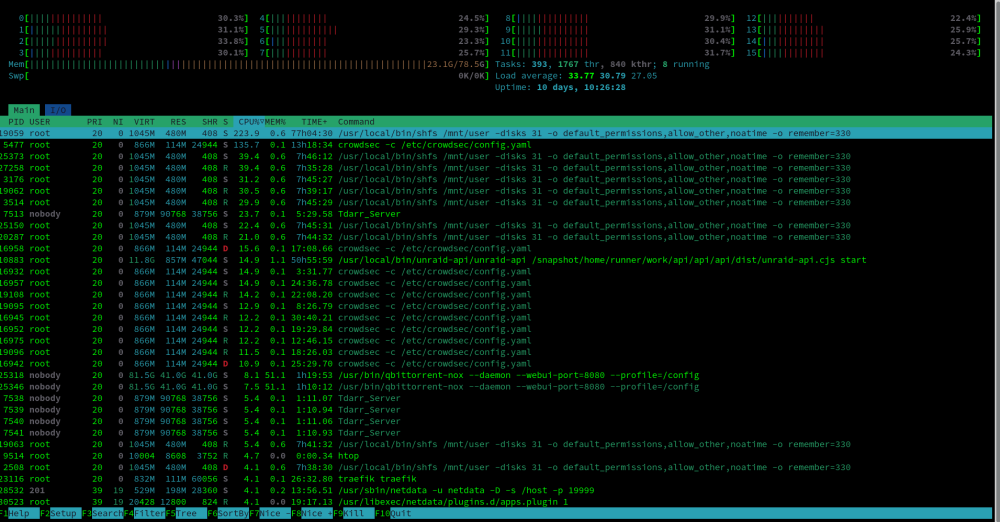
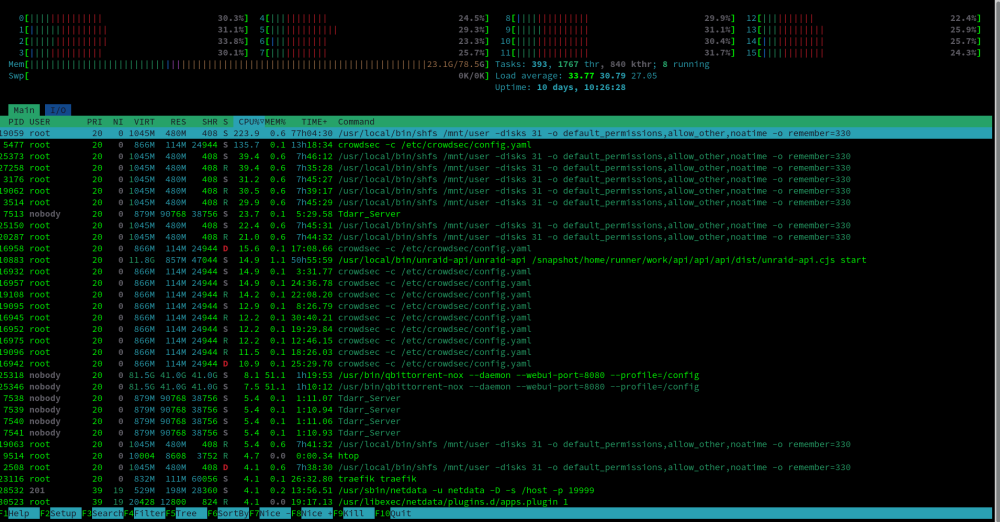
I noticed about a week ago (roughly) that my load average on the server was quite high, and the CPU was constantly in red on the dashboard.
htop shows many processes with the command below:
/usr/local/bin/shfs /mnt/user -disks 31 -o default_permissions,allow_other,noatime -o remember=330I have read that this is normal to have these processes as it's what unraid uses to facilitate shares, however I think the amount of CPU they are using is a little unreasonable.
I can't seem to pin down any particular actions I may have taken that would result in the high CPU I'm experiencing right now, but I have been playing around quite a but replacing NPM with traefik, crowdsec and authelia.
Can someone help me understand why there are so many of these /usr/local/bin/shfs commands running, eating so much CPU cycles?
Did I mis-configure something along the way perhaps?
Server Details:
Ryzen 7 3700x
Asus Prime x570 Pro
80GB DDR4 Memory
LSI HBA (IT Mode) with 6 Seagate Ironwolf 8TB ZFS Disks (2 parity, 4 array)
1 Samsung 980 SSD Cache
Nvidia 1070ti GPU for transcoding
-
Hi Everyone,
Was wondering if someone could help point me in the right direction.
My array disks were all xfs as default, and using unbalance to move data on the disks was moving at about 30mb/s.
I was doing this with the intention of converting the array disks to zfs with unraid 6.12.3
Enabling turbo write didn't seem to solve the problem.
Now I am trying to redistribute the data a little more evenly across the array disks, all of which are zfs.
Moving about 700G of data has taken so far about 9.5 - 10hrs.
I have 2 Parity disks - Seagate IronWolf 8TB
For the array I have 4 disks - Seagate Ironwolf 8TB
They are connected to a dual port LSI HBA SAS-9211-8i flashed in IT mode.
Diagnostics attached. I'd be happy to elaborate more but I didn't want to turn this into a novel
EDIT: added the HBA model ( LSI SAS-9211-8i)

-
15 hours ago, ken-ji said:
Looks good. I'll assume its working for you.
yes sir it is working as expected. Thanks for helping me fix this!
-
-
You're a beautiful man, Charlie Brown!
I will look into doing this after "production hours" lol
Thanks for your help on clarifying this for me @ken-ji
-
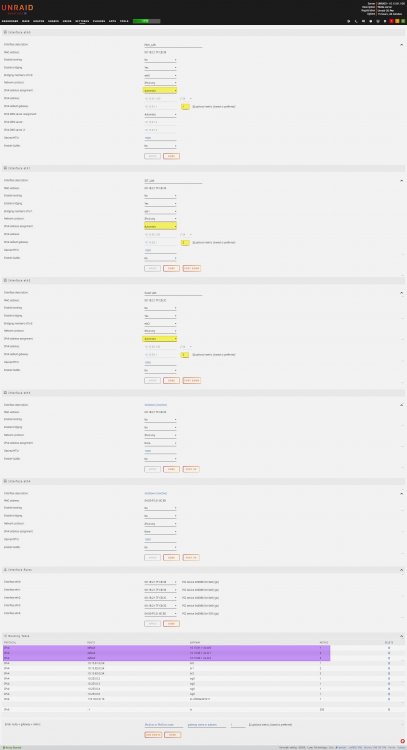
Would assigning the info based on the interface MAC in pfsense make more sense and just set it all to automatic?
That way any gateway issues should be eliminated, right?
I don't have a firm understanding of the networking, it's not one of my strengths.












Device is Disabled Contents Emulated - what to do
in General Support
Posted · Edited by 905jay
added further details on rebuilding disk onto itself
For anyone just coming across this issue, this is what I did to fix it.
Array was started in Maintenance Mode
I ran the following commands outlined below taken from this post linked below relating to Seagate Ironwolf disks and LSI HBA cards due to a drive showing disabled contents emulated
These are my mappings only related to Seagate Ironwolf Drives Only
I pasted the output from sg_map into notepad, and made notes as to what the sg_map output relates to which drive in my array and it's use (Parity and Data) just for my own record keeping
root@unraid:/tmp/SeaChest# sg_map /dev/sg7 /dev/sdh Parity /dev/sg2 /dev/sdc Data Array (drive that was disabled) /dev/sg3 /dev/sdd Data Array /dev/sg4 /dev/sde Data Array /dev/sg1 /dev/sdb Data Array /dev/sg9 /dev/sdj Data ArrayThe SeaChest folder structure is different than noted in the link above, Seagate seems to change this more often that I think they should (IMO)
This is the folder structure as of 2024-03-23
C:\USERS\JAY\DOWNLOADS\ └───SeaChestUtilities ├───doc ├───Linux │ ├───Non-RAID │ │ ├───aarch64 │ │ └───x86_64 │ └───RAID │ ├───aarch64-RAID │ └───x86_64-RAID ├───parallel_testing ├───USB boot maker └───Windows ├───Win64-Non-RAID └───Win64-RAIDThese are files I will be working with. They reference alpine linux in the name, but when made executable they worked perfectly on unraid.
C:\USERS\JAY\DOWNLOADS\SeaChestUtilities\Linux\Non-RAID\x86_64\ Mode LastWriteTime Length Name ---- ------------- ------ ---- -a---l 2024-03-19 3:33 PM 657216 SeaChest_Basics_x86_64-alpine-linux-musl_static -a---l 2024-03-19 3:33 PM 616256 SeaChest_Configure_x86_64-alpine-linux-musl_static -a---l 2024-03-19 3:33 PM 706432 SeaChest_Erase_x86_64-alpine-linux-musl_static -a---l 2024-03-19 3:33 PM 600168 SeaChest_Firmware_x86_64-alpine-linux-musl_static -a---l 2024-03-19 3:33 PM 628544 SeaChest_Format_x86_64-alpine-linux-musl_static -a---l 2024-03-19 3:33 PM 595808 SeaChest_GenericTests_x86_64-alpine-linux-musl_static -a---l 2024-03-19 3:33 PM 712896 SeaChest_Info_x86_64-alpine-linux-musl_static -a---l 2024-03-19 3:33 PM 583488 SeaChest_Lite_x86_64-alpine-linux-musl_static -a---l 2024-03-19 3:33 PM 612160 SeaChest_NVMe_x86_64-alpine-linux-musl_static -a---l 2024-03-19 3:33 PM 608064 SeaChest_PowerControl_x86_64-alpine-linux-musl_static -a---l 2024-03-19 3:33 PM 554816 SeaChest_Reservations_x86_64-alpine-linux-musl_static -a---l 2024-03-19 3:33 PM 653184 SeaChest_Security_x86_64-alpine-linux-musl_static -a---l 2024-03-19 3:33 PM 853856 SeaChest_SMART_x86_64-alpine-linux-musl_staticFrom Windows 11 Terminal I opened 2 terminal tabs (I use ssh keys for access to all my Linux servers)
TAB1: (Keep tab open after running these commands)
ssh into unraid server and create a folder in /tmp called SeaChest
ssh unraid mkdir /tmp/SeaChestTAB2: Copy all the SeaChest utilities over to unraid in /tmp/SeaChest from the download location using scp command
scp C:\Users\jay\OneDrive\Downloads\SeaChestUtilities\Linux\Non-RAID\x86_64\* unraid:/tmp/SeaChestTAB1: mark the files copied to unraid as executable
chmod +x /tmp/SeaChest/*I disabled EPC as well as the lowCurrentSpinup (just to be safe but as noted in the link, not confirmed if necessary)
go to /tmp/SeaChest folder and run the 3 utilities below
./SeaChest_Info_x86_64-alpine-linux-musl_static -d /dev/sg2 -i |grep -i epc ./SeaChest_PowerControl_x86_64-alpine-linux-musl_static -d /dev/sg2 --EPCfeature disable ./SeaChest_Configure_x86_64-alpine-linux-musl_static -d /dev/sg2 --lowCurrentSpinup disableI ran those commands above for all of the /dev/sgX disks that were Seagate Ironwolf connected to my LSI card.
---
Once that portion was completed, I followed the guide below to rebuild the drive from parity
There was one caveat, for some reason I could not stop the array while it was is maintenance mode.
It kept saying Retry Unmounting Shares (for about 40 minutes) so I did a powerdown from terminal
powerdownOnce the server came back up I did the following procedure outlined in the guide linked below (TL;DR)
Stop array
Unassign disabled disk
Start array so the missing disk is registered
Stop array
Reassign disabled Disk (the symbol turned to a blue square)
Start array in maintenance mode
Clicked Sync button to rebuild the disk from parity
https://docs.unraid.net/unraid-os/manual/storage-management/#rebuilding-a-drive-onto-itself