



almulder
Members
-
Joined
-
Last visited
-
@SimonF any luck getting it to show booting and array starting and such before its fully up and running?
-
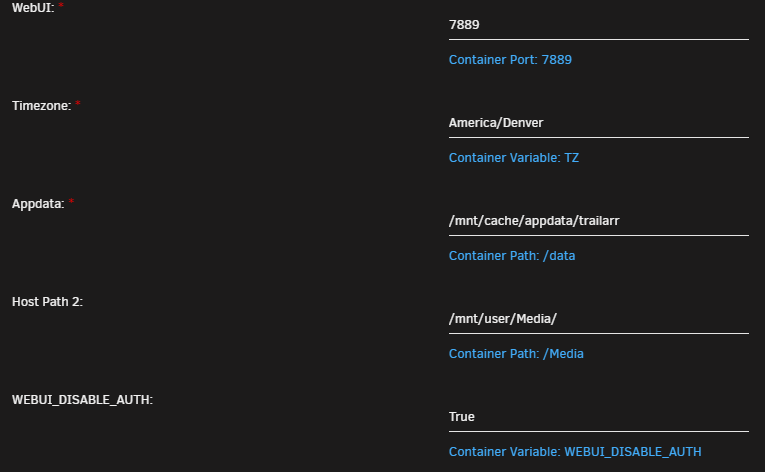
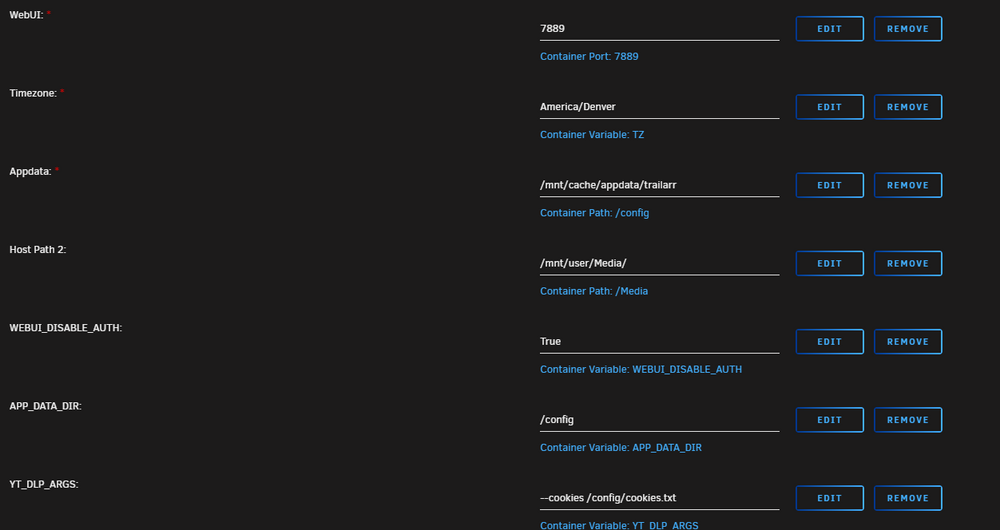
yes that does do it. myabe you can help with one more. i am getting Some trailers will not download, in the log it says "Sign in to confirm your age. " So i looked into how to export my cookies as load then into the docker, but they never seem to take (Exported them from firefox using ym per their github) see my updated screenshots above. Also the docker defaulted to /mnt/docker_v/appdata/trailarr/, it should be defaulting to /mnt/user/appdata/trailarr
-
Need help with Trailarr. I have it setup as follows: No config files are ever saved at the app data location. The app will work, but if it gets shutdown and restarted, it looses all info. and I have to resetup everything. this happens every time. I don't belive it was setup corectly since it will not save the config info. Please help! Update: Ok I have it saving the files, but it will not download videos. here is my config: I get this error: Exception: ERROR: [youtube] 8Zv7wd1a-5A: Sign in to confirm you’re not a bot. Use --cookies-from-browser or --cookies for the authentication. See https://github.com/yt-dlp/yt-dlp/wiki/FAQ#how-do-i-pass-cookies-to-yt-dlp for how to manually pass cookies. Also see https://github.com/yt-dlp/yt-dlp/wiki/Extractors#exporting-youtube-cookies for tips on effectively exporting YouTube cookies I logged into youtube via firefox and exported my cookies and addded them into trailarr, but continue to get the error.
-
system says there is an update to "Fix Common Problems" Installed Version2024.12.04 Upgrade Version2024.12.19a but when I run the update i get this message: plugin: updating: fix.common.problems.plg Executing hook script: pre_plugin_checks +============================================================================== | Skipping package fix.common.problems-2024.12.04-x86_64-1 (already installed) +============================================================================== ---------------------------------------------------- fix.common.problems has been installed. Copyright 2016-2024, Andrew Zawadzki Version: 2024.12.04 ---------------------------------------------------- plugin: fix.common.problems.plg updated Executing hook script: gui_search_post_hook.sh Executing hook script: post_plugin_checks Just wanted to make you aware as I am sure a line of code was missed.
-
I might just look into using user scripts to make a backup of what is needed i nexcloud-aio so I dont backup useless stuff.
-
So what is the best way to get Nextcloud-aio to backup and restart properly. I have been trying appdata backup but it seems to have issue and all the sub containers dont work after Nextcloud-aio-mastercontainer is backed and restarted, I have to go into the GUI and tell it to restart them. Not sure what I am missing. thoughs
-
yes the nvme is passed through from the IOMMU, But all the times I have been doing this, I never noticed the boot order section, I was always doing it in the bios. did it here and now it works flawlessly thanks
-
can you clarify what you mean
-
So I have my stuff setup for passthrough, but what is the proper way to setup for windows 11 to be able to boot from the NVME as a standard drive not a img on the nvme. I have installed, but then windows never reboots to the nvme. I have to manualy select it in the vm bios. I have nuked everything a few times retrying. i have looked at a few videos but no luck. please help.
-
anyone?
-
nic2 is passed through to VM2, VM1 shares nic1 with unraid and uses the vitrio driver.
-
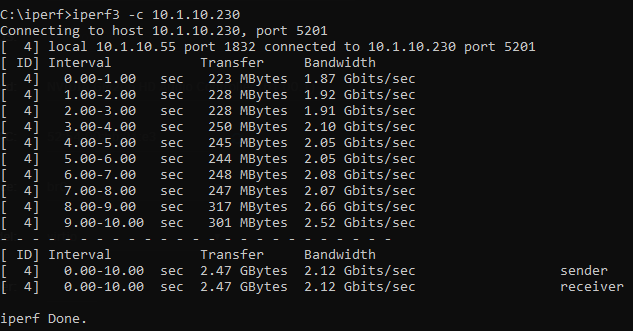
So I have a Pro WS WRX80E-SAGE SE that has 2 10GB nic's One is passed through to a VM (Connected to a switch at 1GB) and the other is used for unraid and shared to a different VM (And this nic is connected via a 10GB switch and shows "10000 Mbps, full duplex, mtu 1500" so its connected 10GB however my VM is only getting 2GB when testing using iperf3 The VM is using virtio and in windows set jumbo frames to 9014. Any idea how to get the full 10GB speed between them?
-
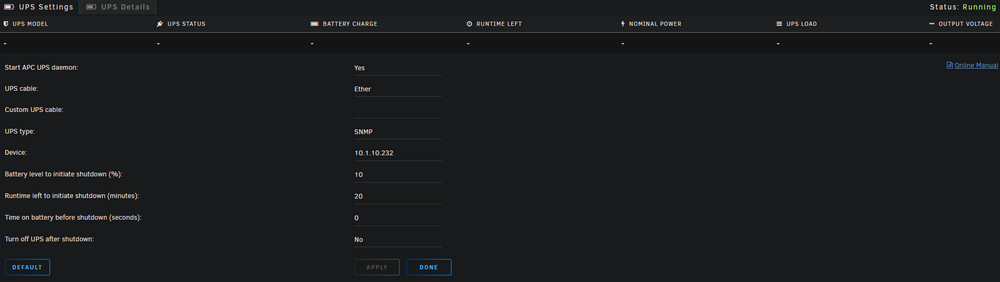
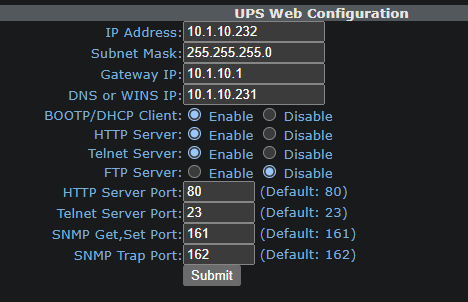
anyone else have issues with the UPS plugin not working?
-
So I have a Minutman E1000RTXL2U UPS and it was working, I got a second one and was going to use that and have unraid monitor that one instead, put in the info and is never populates, changed it back to the original and now that one does not populate. Anyone else have this issue? (they both had different IP address, so that is not the issue, Even removed the second one from the network, same issue)
-
The issue has gone away. I did nothing (6.12.8)






