




MammothJerk
Members
-
Joined
-
Last visited
-
I also would like to know how to run tailscale on this container so that i can connect to it from outside of my network. i am able to get it working by setting "-u 0:0" in extra parameters instead of "-u 99:100" but im not so sure that is intended. for now i just tailscale into the server itself instead of the specific container which seems to work.
-
i removed the GPU from the jellyfin container and haven't gotten another crash yet... ill keep testing.
-
Did you ever resolve this? i have the same issue GTX 1080 Nvidia Driver Version: 580.126.18 nvidia-persistenced in go file, pcie_aspm=off pcie_port_pm=off in syslinux, set gen 3 on the pcie slot When this happens it locks up my jellyfin container and forces me to do an unclean shutdown. lspci | grep -i nvidia still shows my GPU connected but nvidia-smi throws this error: Unable to determine the device handle for GPU0: 0000:01:00.0: Unknown Error i also got these errors before adding the syslinux line for ASPM, they just preceded the NVRM ones. after adding the syslinux line these messages disappeared: I thought i could use my old 1080 for some light transcoding without having to buy a new GPU, i know it is old but it should still be supported on the 580.x branch right? Diagnostics attached. venasaur-diagnostics-20260311-0202.zip
-
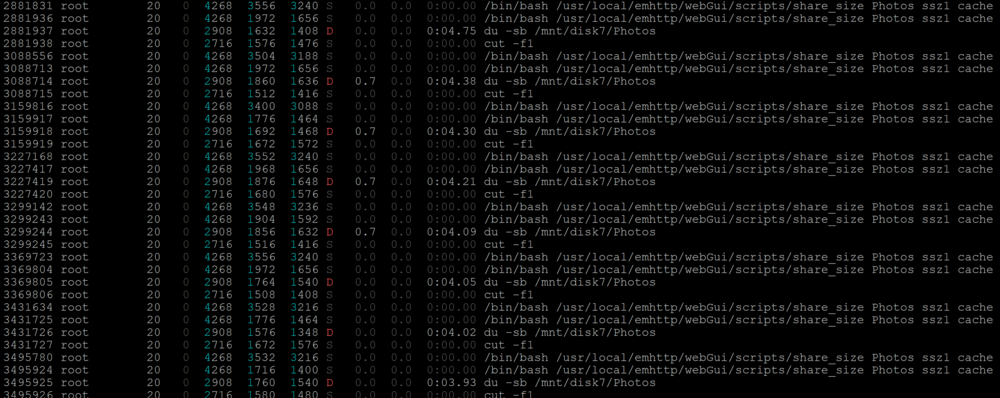
after just 2 hours of uptime i first stopped all dockers and then tried to stop the array The problem occurs with share_size script preventing the array from stopping successfully. i SIGTERM'ed the PIDs in htop to be able to successfully stop the array. i then disabled docker in settings (VMs was already off), i ticked the box for 'reboot in safe mode' and rebooted. 2 hours later i was able to stop the array with no issue. i then rebooted again (without enabling docker or VMs) waited 2 hours again stopped the array without issue. i re-enabled the docker service and then started the array. i instantly got those du -sb... commands in htop. on a hunch i stopped my hass-unraid docker and about 5-10 minutes later the du commands disappeared from htop. it would appear the hass-unraid docker is polling the shares for their sizes and with a share with multiple small files like my photos share it is taking a long time for the scan to finish thus not letting the array stop without finishing those commands. ill bring it up to the author. https://github.com/IDmedia/hass-unraid/issues/48
-
looks to be related to my issue as well... https://forums.unraid.net/topic/197450-cannot-stop-array-pool-or-dataset-is-busy-share_size-script/
-
unraid 7.2.3 diagnostics attached I am almost always unable to get a clean shutdown in unraid because of the "pool or dataset is busy" issue. to get around this issue and let the server shutdown correctly i have to connect via SSH and through htop sigkill a bunch of processes stuck on "/mnt/disk7/Photos" it appears the share_size script is getting stuck on this disk for some reason. Any ideas to fix this? could it be a broken file or is the script running into issues
-
i noticed after updating to the 7.2.0-beta i would no longer see any notifications without having to open the new notifications sidebar so i ran a test and it seems like the notification will disappear in a couple seconds ignoring the settings. During the test i also noticed that it is missing both the description and date info which was visible in older versions. They did however add the "open" button if a link is sent through the notification - which is nice.😊 running /usr/local/emhttp/webGui/scripts/notify -s "Test Complete" -d "Test has been completed" -l "/Main" in the terminal Here is the old notification from 7.0.1 and here is the new one from 7.2.0-beta Here are my settings in 7.2.0-beta.2, it is completely removed in 7.2.0-beta.3 Hopefully this can be fixed
-
New BIOS v4302 released mentions further microcode fixes. hopefully that fixes my issue of degrading 14900k's within 1-3 months 🫠
-
Just updated unraid from 7.0.1 to 7.1.4 and i started sometimes getting unraid syslog errors when a torrent changes download folder. deluge changes the torrent state to "error" and the "status" bar says "Error: Failed to move download folder: Numerical result out of range". this was also reported in 7.1.0 but for a different container so im unsure if its specifically a delugevpn issue or an unraid issue. if you believe this is a delugevpn issue i can proceed with the logs etc.
-
i just updated from 7.0.1 to 7.1.4 and i started to get these errors as well, they have different values though so it might not be the exact same issue as you're describing and they dont repeat. Jul 7 08:50:37 VeNASaur shfs: fuse: bad error value: -2132114223 Jul 7 08:51:36 VeNASaur shfs: fuse: bad error value: -1999095008 Jul 7 08:51:47 VeNASaur shfs: fuse: bad error value: -1987571494 Jul 7 08:54:57 VeNASaur shfs: fuse: bad error value: -2096408835 Jul 7 08:55:06 VeNASaur shfs: fuse: bad error value: -2007817299 Jul 7 08:55:13 VeNASaur shfs: fuse: bad error value: -1937627260 For me the issue seems to originate with the binhex-delugevpn container. Sometimes when a torrent is moved to a different folder it causes an error "Error: Failed to move download folder: Numerical result out of range"
-
after a month of usage without issues (other than the inotify segfault) i just got another full on crash, nothing in the syslog IPMI logged an OS_stop event 🫠
-
10 days later i got another segfault... hopefully a fluke.... Mar 12 16:39:13 Tower kernel: inotifywait[80561]: segfault at 0 ip 000000000040288b sp 00007ffc253d0550 error 4 in inotifywait[402000+2000] likely on CPU 3 (core 4, socket 0)
-
Another new CPU on warranty... issue is fixed again.
-
Does anyone know what going on with the H5Viewer here? 😊 This green flashing only seems to happen after booting into unraid. The BIOS screen, and the bootup screens have no issues, neither does the unraid boot menu where you can choose memtest and safe mode. unplugged the VGA cable from the IPMI card and it seems to have fixed this issue.
-
the 2nd option is preferable for me personally.




