




je82
Members
-
Joined
-
Last visited
Everything posted by je82
-
would love to see this as well, even though it might be a complex implementation i think it would be worth moving towards.
-
I had been transfering files to disk 15 via smb but i checked so the files were written and the disk was not reading/writing before i pressed shutdown AI tells me this that sounds plausible? as ive never seen it happen before, could potentially a timed smb connection cause shutdown event to end not gracefully? i cannot see any issues with the server now and ive been using it for years, this just happened once so it threw me off.
-
for now i installed tips & tweaks to have the shutdown bash/ssh on shutdown, i think that might have caused it but i still don't understand why it would shutdown before the 200 seconds has passed if it couldn't do a graceful shutdown
-
I shutdown one of my NAS (7.1.4) servers, it simply shutdown without any issue with much spare time in the "graceful shutdown" timer, yet when i boot the NAS again it wants to scan parity? I have attached the syslog:
-
I hve some issues with recycle bin again, not sure if it started when i upgraded to 7.1.4 but for whatever reason recycle bin will not pickup files inside /mnt/user/Temp/.Recycle.Bin , it does however pickup all the files from other shares such as /mnt/user/Media/.Recycle.Bin /mnt/user/Applications/.Recycle.Bin when i delete a file inside /mnt/user/Temp it is successfully logged (Oct 29 12:30:42 MOVED_TO => /mnt/user/Temp/.Recycle.Bin/fdsfdsfdsfsfdsf.txt) but the bin itself wil not be displayed in the row above shere you can see the size of each bin for each share that has contents in their bins, i can see the other bins just fine. Checking the permissions for the bin, all seems fine: Ive reinstalled the plugin, restarted the plugin, tweaked settings, ive verified the share setting for the Temp share, nothing seem to help, the plugin will not display the contents of the bin for the Temp share even though the bin has multiple files and the plugin itself is also logging the deletions that are being made to the bin itself. Worth noting the recycle bin is showing "Recycle Bin total size 0B" even though right below in the share section we see 3 different shares with 65gb, 392gb and 13.8gb as well This was not a problem previously, i am unsure when it started but pretty sure it started when i updated to 7.1.4 Your ideas are welcome. EDIT: I found the issue, the data contained in /mnt/user/Temp/.Recycle.Bin was so large the script that builds the stats for recycle bin timed out which was why temp never showed up in the list, i went in and manually deleted some stuff and there were over a million files and 24tb of data in there, yeah ive been doing some cleaning, now it works fine again.
-
asked AI: TLDR: old unraid > LUKS1, new(er) unraid > LUKS2
-
Hmm this has me a little bit concerned, my oldest NAS which was created in 2019 using XFS Encrypted, whenever i backup the luksheader on this machine, the header is only 1028kb (1mb) , while all the headers backed up on NAS3 which was created 2 years ago, they are 16384kb (16MB) what is causing this massive difference in size? Disk size on old nas i 12tb, new nas 18tb, but going from 1028kb > 16384kb seems unreasonable? Can i trust these headers? Why is it outputting so small headers on the older nas? (older nas is using 7.1.4 but array was created using unraid 6x something i believe, whatever was modern in 2019.)
-
does this mean that my old luksheaders i backed up in older versions of unraid are wrong? or did the names of the devices change at some point as unraid has gotten updated? (just asking so i know if i have to go back and backup the headers in my other unraid boxes) according to my own documentation which is years old i used the /dev/ path previously when doing the luksheader backups.
-
Using 7.1.4 version of unraid, i cannot backup my xfs luksheaders? I've documented the commands ive used in the past to backup my luksheaders but they dont seem to work the same anymore? lsblk output: What am i doing wrong?
-
I see, thanks for letting me know, glad i asked!
-
Interesting, so you can have mixed filesystems in the same array? I never knew that. The main reason i would like to use ZFS is mainly bitrot protection, performance on the array is not crucial but considering its not the greatest for me as i am using dual parity with xfs encrypted maybe it would be a problem if its really really slow? So what usecase is mainly targeted for ZFS? I though most people used it for their main arrays?
-
So the official way of using ZFS is to have 1 pool per drive? do you have parity then? i definitely do not want the ZFS filesystem spread out over more drives, i like to keep the filesystem (jbod) so in case if extreme failure i can always just mount the single drives and extract the data.
-
Hi, I am looking to make the move to ZFS encrypted, what are the best ways of going about this? Considering unraid does not support multi arrays yet i guess the only way to do this is to setup an array on a temporary licensed unraid server and then move the data over the network? Or is there any better solution that i didn't think of?
-
oh wow! here i am relying on AI and i guess it had not been updated with this new information, when was this added? great stuff!
-
Came across another thing that would be a real quality of life improvement to unraid. Integrate something like https://github.com/doron1/unraid-newenckey to unraid to make an easy and convenient way for the end user to change their encryption keys to unlock array, right now its very finicky to do this manually and process to change this depends on what filesystem you are using, a universal way that makes it easy for user to change the pass-phrase to change encryption key no matter which filesystem they have encrypted would be a real improvement.
-
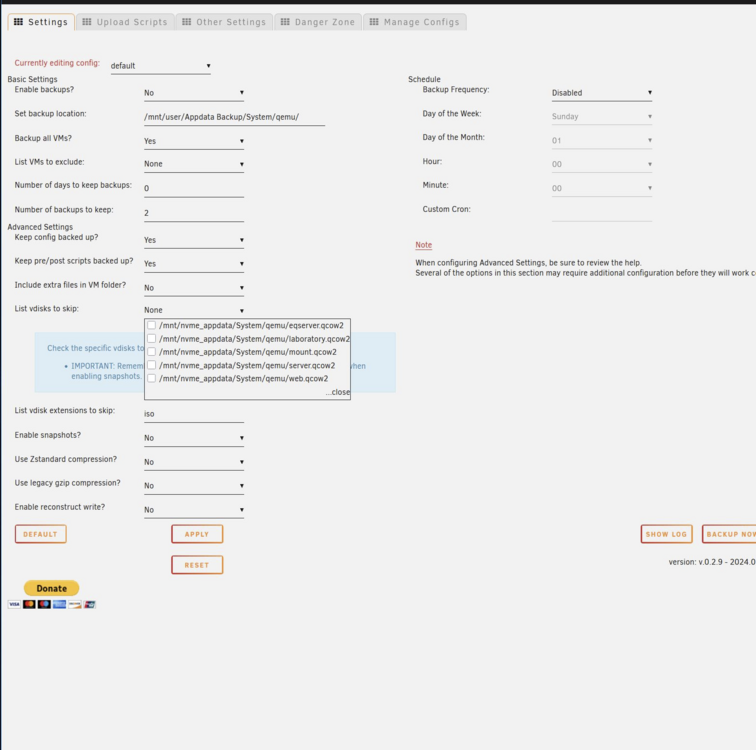
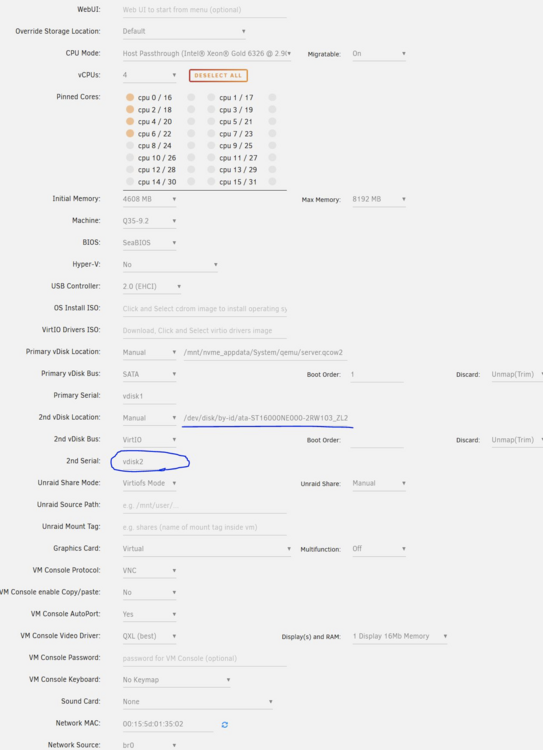
I have questions regarding my usecase, I want to backup my vms, but one vm has a secondary vdisk mounted that is bypassed in unraid, i DO NOT want this disk to be part of the backup. Looking at the configuration it seems i can only pick these vdisks that are pointed to a file on disk (qcow2) But the disk i want to make sure is bypassed is like i said bypassed by unraid and mounted directly to the vm as such: I have not yet tested the backup solution, but i am wondering if this vdisk2 will automatically be excluded? if no, how can i exclude it? EDIT: I guess it exlucdes this vdisk with a warning, would be nice to be able to really exclude it though: 2025-10-23 21:35:31 warning: There's an empty vdisk_path on Server. This is mainly caused by an empty cdrom file path. skipping vdisk.
-
I love unraid, it really is wonderful, here are some of my personal most wanted features for the future (currently on 7.1.4) Built in backup solution for virtual machines (major ++++ if it works while virtual machine is running.) Multiple arrays (not sure how this would work with the parity drive but i guess it would have to have 1 parity per array, either way, multiple arrays would be cool.) A nice way of monitoring files usage over smb or other protocols utilizing ionotify watchers or anything like this (i have my own script for this but its very rudimentary) it would be a very nice feature to have a nice overview of which user access what data, and the ability to filter out the verbose jibberish and get a pretty overview of whats going on files added/deleted, accessed etc. That is all i can think of, i think unraid has come a long way, i am looking to upgrade to zfs here soon to get rid of the bitrot worries, i recently updated to the most modern version and its running beautifully! Keep up the good work
-
i think i found the culprit, i just figured it had to do with the upgrade, but it actually was me changing some settings i found in unraid after the upgrade, such as the "power mode" feature that wasn't available previously, i tested it and put it to "power save" and i saw it dropped the watts used by the server by a lot ... nice i guess, but i guess this is the drawback, stuff like clicking the gui in a vm wont trigger the threads to boost and you're stuck trying to render an interface made for computers in 2020 with a 500mhz cpu because the threads are asleep, i'll tinker with it but this is definitely the reason for the sluggish feel. If any of you have any idea why the default features for the VM makes is not load, please let me know, as for the lagging VM i am considering that resolved, it was the power save feature.
-
Hi, I upgraded today to the very latest stable unraid version as it seems like there will be a new stable soon i want to be ready for that upgrade, anyway, i noticed now that my windows 2019 server VM that i have been using for years barely functions now, its lagging like crazy when i remote into it, but whenever i manage to open the task manager there is no memory or cpu usage. Since my virtual machine XML is from an unraid version from years ago, i decided to go in and check if maybe there is some new settings in QEMU that changed, but whenever i save my settings in the new virtual machine editor page, the VM wont even boot properly, it just hangs while loading, i cant see any error messages. Doing a manual "trial and error" i figured out which snippet in the xml that makes the vm stall when using the default settings provided by newest version of unraid: These "features" are auto populated by new unraid, and makes the VM not able to boot just hangs during loading "spinning bubbles" under unraid logo spins for awhile then just stops, never opens windows. These "features" were in my old configuration file, and if i use them instead the VM boots fine, but like i said its lagging like crazy. I don't know if this is of any relevance at all, but all i know is my VM worked amazingly fine in the older version of unraid but in the newer one it is bad. Here is the full "old configuration" that worked fine in the old unraid version:6.12.15 I was asking AI and it was suggesting me to use "virtio" instead of ide, but i cannot see any reference to IDE in my old configuration? Either way, i removed the entire disk block to see if the lagginess went away and it remains. My old config uses "pc-q35-6.2" i've changed that to the most modern version "pc-q35-9.2" the lag still remains. I've checked eventlog in the windows installation and there is no reference to any errors there. Here is the full "new configuration" that i'm using, but like mentioned earlier i have to grab the "features" from my old config to make the new one work, otherwise it just stalls during loading, i don't know why, maybe someone can tell me? your ideas would be very welcome, i should add that i mostly feel the lag when i am remoting to the server, i didn't notice any slowdowns accessing the VM via SMB or anything like that, which perhaps indicates its a gpu rendering issue? Either way, your ideas are very appreciated, thank you.
-
I have it setup so i have to enter the passphrase manually each time i start the system, but i also have some scripts running at launch to mount a share for remote logging: this is my go file: #!/bin/bash # Start the Management Utility /usr/local/sbin/emhttp & #Copy FSTAB to the system on boot and mount the logs folder #nvidia presistance mode #nvidia-smi -pm 1 cd /home mkdir nasbackuplogs cp /boot/fstab /etc/fstab sleep 5 mount -a # Copy files back to /root/.ssh folder and set permissions for key files and known_hosts and authorized_keys cd /root/.ssh/ #mkdir .ssh #cd .ssh cp /boot/config/sshroot/* /root/.ssh/ #cd /root/.ssh/ chmod 600 NAS-rsync-key.pub chmod 600 NAS-rsync-key # Copy the monitor script to a writable and executable location cp /boot/config/monitor.sh /tmp/monitor.sh chmod +x /tmp/monitor.sh # Wait for Unraid to fully boot before starting monitor script sleep 30 /tmp/monitor.sh & the fstab: /dev/disk/by-label/UNRAID /boot vfat auto,rw,flush,exec,noatime,nodiratime,umask=0,shortname=mixed 0 1 /boot/bzmodules /lib/modules squashfs ro,defaults 0 2 /boot/bzfirmware /lib/firmware squashfs ro,defaults 0 2 tmpfs /dev/shm tmpfs defaults 0 0 //10.1.1.15/Logs/NAS\040Backup\040Logs /home/nasbackuplogs cifs vers=3.0,username=WebSMB,password=xxxxxxxxxx,uid=0,gid=0,rw,dir_mode=0777,file_mode=0777,users 0 0 the monitor.sh is just a script that runs after array successful start that starts a bunch of inotifywait watches which i log to the path /home/nasbackuplogs/x so i can see what files are added/deleted after the fact. (i actually removed this before upgrading from the go file temporarily and it seems it was not the culprit) I would prefer to upgrade to 6.12.15 to begin with. what are your suggestions? Thanks for the support
-
unraid produced another diagnostic whenever it was unable to shutdown gracefully after the upgrade to 6.12.15, ive attached the syslog and the diag zip file here in case that helps understand what the issue is:
-
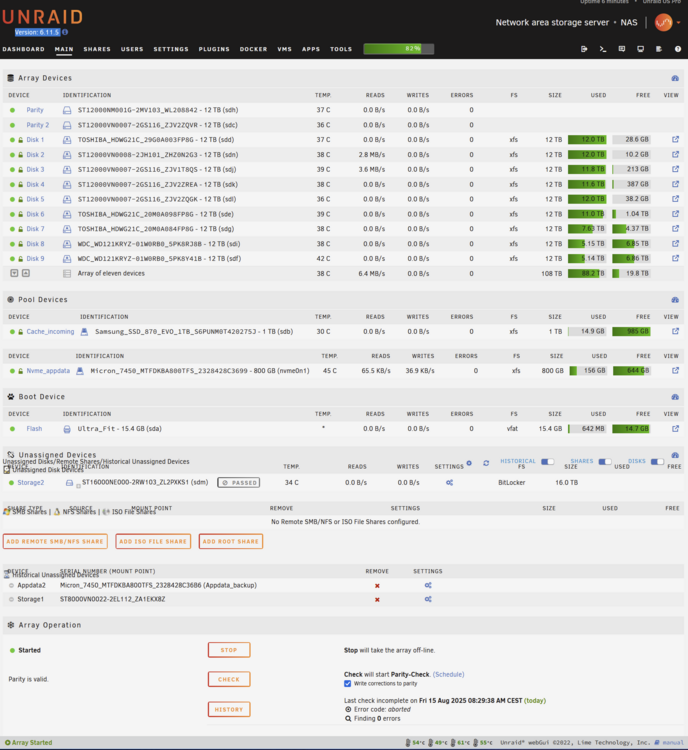
For now i downgraded to Version: 6.11.5 again and my array mounts just fine with xfs encrypted using the correct passkey. I would like to upgrade though so if you have ideas please let me know.
-
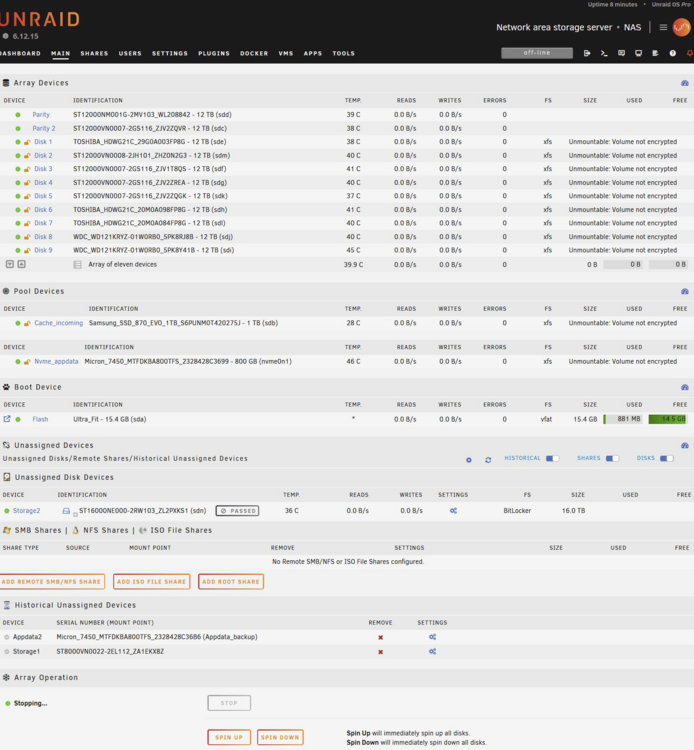
I tried to upgrade from Version: 6.11.5 , i simply stopped array, overwrote the BZ files in the usb , waited until it told me to reboot, rebooted. Now i have an unmountable array, ive previously tried to upgrade before and this happened that time too, this time i have more time to try to figure out what the problem is, after mounting the xfs encrypted array using the correct key, it looks like this: Trying the stop the array, results in this: Can anyone please help me? What am i doing wrong here? I do not want the latest unraid, i like to stay behind for stability sake. Thanks in advance

-
I suggest you uninstall and reinstall it, the uninstall only removes the PLG file from the plugin folder on your usb drive and removes the hooks, it doesn't actually touch any files in your .Recycle Bin folders so you don't have to worry about that. I did this and it resolved my issues with the plugin, once reinstalled it could see the files that had previously been deleted etc.
-
Interesting, i noticed that my Recycle Bin had stopped working after the most recent update, and it seems after fiddling around with it and eventually removing it, adding and old plg version back, then upgrading to the latest version, both the recycle bin started working and the smbd_calculate_access_mask_fsp disappeared as well. I see that recycle bin is somewhat related to SMB so it must have been the cause to the error, i saw on my log server that the SMB error actually started exactly a week ago but i don't look at my logs so often so i didn't see it until today, it seems to have started when i updated the recycle bin plugin that day. TLDR: if you find yourself having sudden issues with "smbd_calculate_access_mask_fsp" when accessing media on your unraid server, try re-installing the recycle bin plugin.




