




je82
Members
-
Joined
-
Last visited
Everything posted by je82
-
trying to shutdown the system gracefully now, capturing these logs:
-
It seems my previous unraid installation that has been stable for years is starting to show misc errors, now all the dockers dropped, what is your suggested approach here? The system is an expensive one running ECC ram and passed memtest 10 passes when built. Maybe its the ssd that is failing? I tried to look at the scrub stats of the docker container and it found no issues? " "UUID: 7430bd32-eee4-4538-9616-eb39918be503 Scrub started: Sun Nov 5 12:03:46 2023 Status: aborted Duration: 0:00:00 Total to scrub: 13.33GiB Rate: 0.00B/s Error summary: no errors found" Attached diags in case you experts can find what could be causing it, appreciate any help. (Removed diags for privacy reasons)
-
i ran the filecheck again with just -v flag i cannot see that it fixes anything, should i just relax and monitor ? can it perhaps be a ram issue? but then why did it spew errors only directed at DM-3 ? Also as far as i can tell i had no real read/write operations going on when it started, the server was pretty much in a relaxed state. Your feedback is appreciated
-
uhm okay, but shouldnt the scan see the problems? and alert me that there are problems that needs fixing? or did i miss something here, it looked like the scan returned no errors?
-
Here are the results: any expert advice? should i replace the drive or should i let it go for now and monitor the situation?
-
nevermind missed @itimpi answer. gotcha.
-
So follow up question, a filesystem check can i do that directly through the unraid gui? click the disk > extended smart test or are you referring to something else? like something via the cli? thanks.
-
looks like its /mnt/disk4 could this be correct? found this inside syslog.txt: Sep 27 11:16:04 NAS kernel: XFS (dm-3): Ending clean mount Sep 27 11:16:04 NAS kernel: xfs filesystem being mounted at /mnt/disk4 supports timestamps until 2038 (0x7fffffff)
-
i have dual parity, does that mean i should check disk 5?
-
Im trying to understand what XFS dm-3 is, when i do cli: dmsetup info -c dm-3 Device does not exist. What am i looking at here? dmsetup ls returns: md1 (254:0) md2 (254:1) md3 (254:2) md4 (254:3) md5 (254:4) md6 (254:5) md7 (254:6) md8 (254:7) md9 (254:8) sdb1 (254:9) sdc1 (254:10)
-
Today i saw in the log, from unraid: On my logserver i see the log server captured nearly 25 000 lines of log errors like this, it was occuring for nearly 1.5 hours! I dont know if it was occuring that long because it took that long to generate the log or if it actually was something happening for 1.5 hours. Anyway, i dont understand this message, i just saw it now, everything works fine as far as i can tell and the web gui shows no disk errors? What am i looking at here? What could be the cause? Should i be worried? The server has had no issues for years.
-
nevermind mover is running but really slow, a lot of small files to the disk array a big weakness
-
I ran some backups and there was a ton of files written to the cache ssd, over 4 million files. The mover ran, and i just noticed its still running, its been 16 hours, and the ssd is still filled with stuff, i can't see anything actually moving. 2 questions: 1. how can i see what the mover is doing? 2. how can i stop the mover and restart it? Thanks.
-
Darn, scary read, but i have NFS disable as well as hardlink support, but i found someone who was doing stuff over SMB via a WM that was hosted on the same unraid machine, this is actually something i was also doing when this error occured, at first i though it was due to rsync running but looking closer the rsync script finished sucessfully just seconds before this error occured so its more likely i managed to trigger the error doing stuff via SMB from the WM. Makes me wonder if you can craft a bad smb packet and just crash shfs on demand? Ill monitor the situation and hope for the best, thanks for the information @JorgeB
-
Running Version: 6.10.3 i had SHFS crash on me for the frist time, the system is very stable, runtime was over half a year and previously before that the same, never had this happen before and would like to try to investigate why it suddenly happened. Log isn't very helpful, no issues until suddenly: Sep 27 10:33:40 NAS shfs: shfs: ../lib/fuse.c:836: unref_node: Assertion `node->refctr > 0' failed. Sep 27 10:33:41 NAS emhttpd: error: get_filesystem_status, 6258: Transport endpoint is not connected (107): scandir Transport endpoint is not connected All i know is that rsync was running at the time it happened, my guess this is the culprit? Is it that it ran out of memory or something else, like i said i am not getting much help from the logs. For future reference, is there anyway to start SHFS if this occurs or do i have to unmount the array and then remount it again in order to get it back up running? I had all my docker containers mapped directly instead of via shfs so the only thing that happened when shfs crashed was that i couldnt access any data via the smb shares.
-
I have this issue to, seems very random, not available at random times on random dockers. My uneducated guess is that docker is limiting the amount of requests it takes from a client, and if you have too many dockers and do a check it will flood their system and it will block some of the requests ending up in not available, none of the fixes in this thread solved my issue, it randomly comes up as not available at random dockers at random times. I cannot use squids patch because i am on an old version, for now i have to live with it.
-
Had a major unraid crash today. So once more the oom memory ran while the mover ran and killed my biggest VM, it seems like whenever the fuse process is taking place it consumes a massive amount of extra virtual memory that is not visible via the normal tools to look at the memory pool. After the oom-killer had killed my VM the memory consumption while mover was running according to unraid was 30%, my VM consumes 50% of the total memory, that means 20% should have been left over. I start the VM again without waiting for mover to stop. Once i do this, the webgui instantly becomes unresponsive. I SSH into the machine and try to see whats consuming memory. I start from the heaviest docker and try to to stop it via command "docker stop name" this yelds no result, it cannot be stopped because something is not responding (dont remember exactly how the message was formulated) i try command docker kill name this yeild the exact same result as docker stop. next i try to do virtsh list -all to see if my vm is running, the command just hangs in the air, never respond, i wait over 10 minutes. next i do top and sort for whatever is consuming most virtual memory, i see that SHFS is asking for a massive amount of virtual memory so i do a kill -9 PID to free up memory process is killed but nothing really happens, webgui still completely unresponsive, no docker containers can be shut down via cli, trying to interact with virsh yields no result completely unresponsive. finally i give up, i issue command powerdown in the cli. looking at my logserver, it actually does somthing this time, it actually shutsdown all the docker containers and unmounts the disks, (why could i not shut down the dockers is my main question here). eventually it locks up trying to umount several of processes, such as umount sys/fs/cgroup target is busy umount sys/fs/cgroup/cpu target is busy umount sys/fs/cgroup/cpu/freezer target is busy umount /mnt target is busy i wait for some minutes then i hard reset using the hardware reset button. i am out of options here, my main 2 questions are: 1. why is so much virtual memory being randomly consumed by the fuse operation at random times? How can i put a cap on this? I use unraid for VM hosting and its becoming unreliable because the fuse system just eats memory at random and then oom-killer defaults to killing the process eating most memory which is always going to be my VM because it consumes 50% of the total memory when running statically. 2. any ideas why docker and virsh was both unoperationable, virsh was actually tototally unresponsive issuing any command to it yielded no response, but the strange part is docker was responding just fine but i couldn't shut down any of the containers using stop or kill, both responded in the same way that something (i cannot rememeber exactly what it said) is not responding and therefor it cannot be stopped. thanks.
-
I'm not a proficent coder, but can someone tell me if it would at all be possible to re-write some of the functions of "Active Streams" and have it log opened media files to a log file? I've been experimenting with samba logging and the problem is it is far to noisy, if you open a playlist of mp3 containing 10 000 mp3s for whatever reason the program makes a quick check to stat check to see each file is indeed there, and this makes samba logging make 10000 entrys for "opened files" which makes the log sort of useless. My though is since activity streams has an indicator of "how long" a file has been opened, could you lets say make it so that it would only log a file as opened if it "streams data" for 10+seconds making it log this entry, but not the ones that come and go under 10 seconds? I'd also like to know how acitivty streams knows when someone openes something, is it hooked up to some kind of api to know when to run smbstatus or is it continously running smbstatus every second draining server resources even though nothing is going on? (Maybe this is not as taxing as i may think but still) Is it even worth starting to look into this or should i stop right here? I really really want some way of logging whats going on via smb on my unraid server without things getting crazy noisy and the logging options in smb does seem to get too noisy, need some kind of way to ignore quick smb connections but keep the ones that are relevant because they are streaming data and log those only.
-
Thanks, yes i noticed a lot of changes to SMB going on in both recycle.bin and unassigned devices All works now, thanks for clarifying! Have a good day and thanks for the amazing plugin!
-
ok, but there is still an recycle.bin entry directly inside smb.conf saying: # recycle bin parameters syslog only = No syslog = 0 logging = 0 log level = 0 vfs:0 Will this setting not overwrite my own loglevel setting in smb-extra.conf
-
damn, my unraid is actually a production server so i cannot reboot it right now, can i just modify the files and run if yes? which parts would i remove safetly? the entry in smb.conf for recycle.bin i take it? and perhaps one of the multiple includes? Thank you again for the support.
-
Whats going on with this plugin, constant changes to SMB messing with my config, i am trying to figure out what to do here. I want to log my smb user activity, so i have configured in extra settings: This does not appear to work because recycle.bin plugin has put its configuations regarding smb everywhere it seems, first we have: /etc/samba/smb.conf and a little lower in the same conf.smb file: A double entry to multiple configs, checking these files we have: smb-recycle.bin.conf smb-recycle_bin.conf Is this working as intended? Why is it incisting on being in global, why are these multiple entries leading to the same configurations multiple times? I want to have some kind of acitivty logging of files being accessed via smb, i put this into extra but i believe the global variable that recycle bin plugin puts in many places of loglevel 0 overwrites my settings as it works on unraid without recycle.bin plugin installed. I love this plugin and its a must have, so i really want to make sure i am not breaking anything by fiddling with these settings, your advise would be greatly appreciated, thank you!
-
previously 32 gb when i ran unraid just as a nas, now i host everything on unraid so i have 128gb ram, i have multiple webservers that combined rack up around 60k unique visitors per day so i need to keep those database indexes in ram for smooth operation
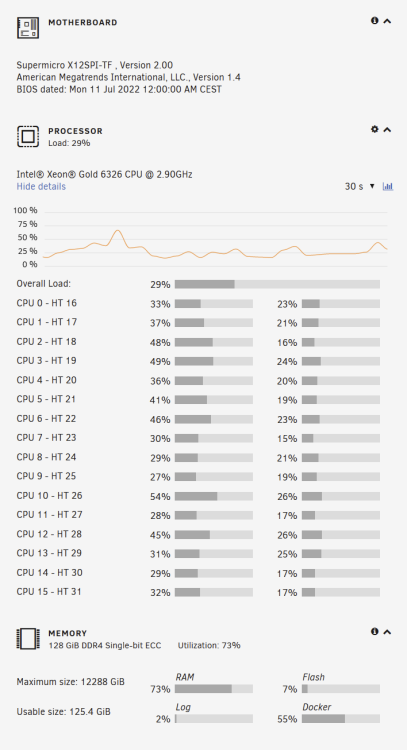
-
You can find the digest used by running Replace "lscr.io/linuxserver/mariadb:latest" with whatever the id of the container you want to extract the digest from But i could not find the exact digest among the tags so i had to query database by running SELECT @@version; which gave me the version and solved the issue.
-
Not sure if this is the correct forum for this question. But i have a docker container that i do not want it to be updated anymore and stay at where it is right now because it is a crucial application for some of the stuff i am running on unraid. The particular docker container is MariaDB (lscr.io/linuxserver/mariadb) Since it is just set to lscr.io/linuxserver/mariadb it will always grab the latest from list: https://hub.docker.com/r/linuxserver/mariadb/tags But i don't want to update it, i want to make it stay where it is now. How can i figure out which exact version it is running right now? docker ps just shows "lscr.io/linuxserver/mariadb" Any ideas?

