




wirenut
Members
-
Joined
-
Last visited
-
Yes, you need to change/verify the boot order in your bios for your internal boot drive to be 1st. Keep in mind you will still need to leave your USB drive for license verification. If you move your license to TPM, and your internal boot drive is successful, you should then be able to remove the USB and use it for something else.
-
7.2.6 to 7.2.7 update went smoothly for me. All seems well. Thanks!
-
an update to 'fix common problems' v2026.05.16 solved the issue with a couple steps. update fix common problems and scan again. mark warning as ignore and scan again. unmark ignore warning and scan again. This is what worked for me.
-
fix common problems reports this to me this morning: The plugin dynamix.password.validator.plg is not known to Community Applications and is possibly incompatible with your server. Want to get this sorted prior to 7.3 update. Is this depreciated or something else? Currently running unraid v7.2.6
-
👍 Good advise. I mean unraid is trustworthy right? Otherwise we wouldn't be using it right?
-
Update. 24 hours and all is well. Thanks.
-
Recently my top share folder MEDIA, and some of the sub folders of media (movies and tv shows) are showing up on my cache drive empty. I run the mover and they go away for a while and then return again. I have identified Bazarr as the culprit, is this now expected behavior since the last update, prior to this update, this was not happening. SEE HERE: https://forums.unraid.net/topic/196410-empty-share-folders-showing-on-cache-drive/#comment-1600996
-
Well just wanted to update that I figured out what is causing my issue. It is Bazarr docker container. Do not know yet what it is doing to cause this behavior.
-
This would be a recent change in behavior, but agree could be possible since my regular dockers are set to auto update. Also, still getting my head around how "pools" work If this turns out to be the case @Frank1940 , I will definitely share what the culprit program that is behaving responsibly is. 😊 This doesn't seem to be causing any other issues right now other than I have to see empty folders on the cache drive when I look. UGH! For now I guess that I'll just have to accept this as expected behavior. I'll keep an eye on things and either get used to it, or report back again if something erroneous comes up. Thanks for the time and input!
-
only one folder named MEDIA. Been that way since I originally set up unraid in 2012. using unraid file manager shows same result. folders there, but empty. from parent directory:

-
cache is network mapped to drive x: from my windows computer. Opening each from there they show no files. hidden files is enable in windows. Also, doing a right click properties in windows show this:
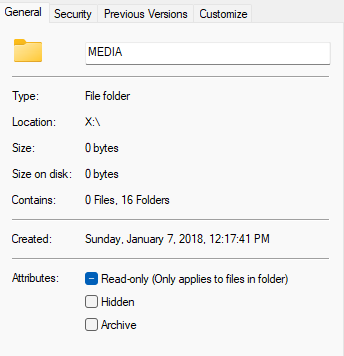
-
Recently my top share folder MEDIA, and some of the sub folders of media are showing up on my cache drive empty. I run the mover and they go away for a while and then return again. Behavior I am used to is only would see if there was something waiting for the mover to copy to the array, and then it would only be the MEDIA folder and the pertinent subfolder containing the file(s). An AI deep dive search says this could be expected behavior do to how fuse works, but I figured if this was the case, it would have shown up long ago. I have made no configuration changes recently other than changing monthly parity check date, and i have also recently added and been playing with a new WIN11 VM, which isn't running currently. I am not using the mover tuning plugin. Sync files in windows is turned off. i have rebooted the server and the window computer twice each, no change. Is this expected behavior now with ver.7 or do I have something goofy goin on? tower-diagnostics-20260110-1052.zip
-
Can confirm same issue using Chrome on my android device. Button dims and does nothing. Went to tools / update OS / and it works fine.
-
It's not reporting an issue. It's reporting a comment to let you know what happened. Run fix common problems scan one more time and those comments will disappear and it should report no issues found.
-
Upgraded 48hrs ago and all is working. Thanks to a warning notification "Share name contains restricted character(s)" and subsequent name change of that share, my log rotates now. https://forums.unraid.net/topic/186899-syslog-server-log-rotation-not-working-unraid-7/?&do=getNewComment




