




thestip
Members
-
Joined
-
Last visited
Everything posted by thestip
-
No, but I didn't expect it to since I said every drive was being read, in the array or not. And now I see it's been happening in safe mode as well. The SMART check is set for 1,800 seconds, so that's not it. (I even set it to 0 to make sure) Update: Found the issue. "BTRFS operation is running". I just happened to be looking at the "STOP" button when the drives all got read. It grayed out for just a moment and some text flashed next to it. (the button did not gray out every time.) Managed to get a screenshot and could see "BTRFS operation is running". I had an unused drive in a pool that was BTRFS (old drive was going to wipe it). Took the drive out of the pool, deleted the pool. No more checks every minute, drives all spin down and stay down. Shouldn't something like that have been logged?
-
I was just about to post saying it didn't work when I went into safe mode again and spun a drive down. Damned thing spun up. I just didn't wait long enough to see it happen last time. Sorry for the bad info/waste of time. Fixed, thanks!
-
That's the thing. Nothing in the logs says anything about a SMART check or any unexpected drive activity, unless I spin a drive down, yet there's a check every minute. I have no idea how to tell what's checking the disks. Removed the extra cfg files, posted new diagnostics. Since it wasn't any of the plugins, I've reinstalled them. Recap: uninstalled all plugins aside from CA, disabled docker, disabled VMs. Drives still get read/checked every minute. Prometheus and a few associated apps are the only thing I've messed with that would do that, but they're no longer installed. It's like part of one of those apps didn't get uninstalled. planetexpress-diagnostics-20230129-1930.zip
-
(taps mic) This thing on? 😁
-
Friendly bump. 🙂 The interval between the reads is one minute. I played around with Grafana and Prometheus a while back, but I removed both of them. I don't know what else would be reading the SMART info all the time.
-
Moments after spinning down a drive... Jan 22 18:51:35 PlanetExpress emhttpd: spinning down /dev/sdl Jan 22 18:51:51 PlanetExpress emhttpd: spinning down /dev/sdm Jan 22 18:51:53 PlanetExpress emhttpd: spinning down /dev/sdd Jan 22 18:52:05 PlanetExpress emhttpd: read SMART /dev/sdd Jan 22 18:52:10 PlanetExpress emhttpd: read SMART /dev/sdm Jan 22 18:52:15 PlanetExpress emhttpd: read SMART /dev/sdl planetexpress-diagnostics-20230122-1859.zip
-
I was finally able to mess around and update the server. The drives don't spin up like this in safe mode, but I've uninstalled every plugin aside from CA, and it still happens. New diags attached! planetexpress-diagnostics-20230121-2206.zip
-
I'm using the SAS spin down because the drives are on Dell Perc 310 cards.
-
Just did that, drives are still getting spun up/read. Spun them down, spun right back up. Even the unassigned, unmounted, unmountable ones are getting read. The only "new" things are the OS upgrade, the user scripts plugin and a few things from theme park (custom login screen). I've uninstalled the scripts and theme plugins (but the custom login screen remains) The drives spin down just fine, something just keeps spinning them up again.
-
-
Hey everyone, I updated from 6.9...11(??) a few days ago and now something is reading from every drive in the server every few minutes. Array drives, cache pool drives, unassigned drives (mounted or not), all of them. I spin them down, they spin back up within minutes if not seconds. I disabled Docker, deleted any plugin relating to system stats/monitoring, stopped my VM, still happening. File Activity plugin is catching activity on my VM and a few dockers, that's it. (only by share, nothing at all by disk). These are SAS and I'm running the spin down plugin for them. I'm not sure what to try next, so here I am. 🙂 planetexpress-diagnostics-20221117-2058.zip
-
Hey everyone, quick question. I have dockers installed in 2 different folders and want to move them to a single folder in a new pool. I know I can change the share(s) location and run the mover to move the files onto the array and then off to the new pool drive, but what's the best way to change the folder paths of existing dockers? ie mnt/cache/docker_apps/dockername to mnt/cache/appdata/dockername. Do I move the 2 shares then copy/move the dockers in /docker_apps to /appdata, change the template info, and start up the dockers? Thanks in advance!
-
Great suggestions, thank you! I'll try a load test this weekend. Yes, the same UPS and batteries. I ran the self-test software with no errors, but not a load test. My bad for assuming the self test was good enough.; that's just sloppy troubleshooting.
-
So any idea as to why it's not getting told to shut down or how I can troubleshoot this further? There's not a lot to configure and it looks like I have it right... Start shutdown after being on the UPS for 4 minutes. When I've come home and the power's still off, the UPS battery is still nearly full. And if it did stay on the whole time, shouldn't there be something in the syslog after it went on the UPS?
-
*friendly bump* 😁
-
I switched to NUT when this started happening just to test things. Was using the normal UPS tool for years with no problem, always had clean shutdowns. If it were set to not shutdown, wouldn't it just keep running till the UPS died?
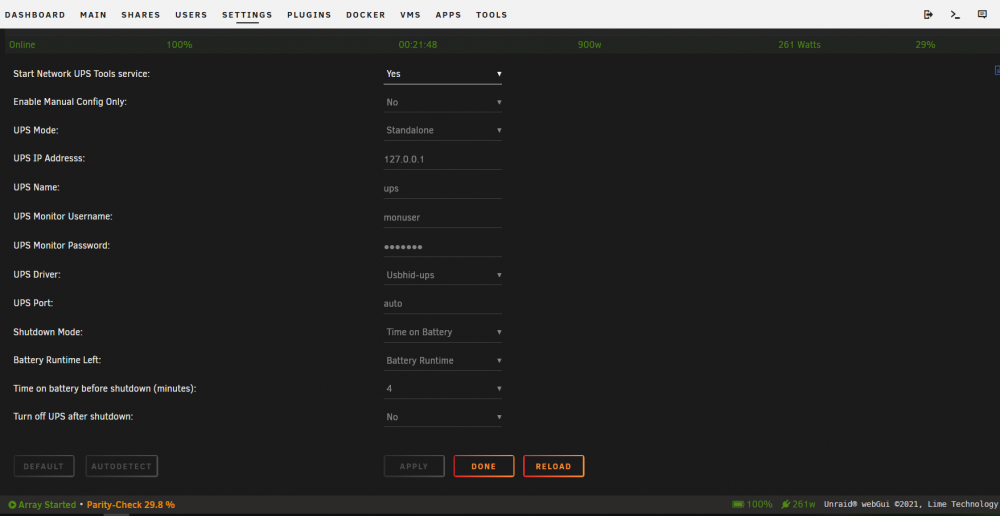
-
Nope. UPS still has 99% charge, so it has to be something in Unraid. Logs don't really tell me much... Power went off a little before 7, here's that part of the log. The full log is attached. "Sep 14 06:47:03 PlanetExpress upsmon[7634]: UPS [email protected] on battery <---- power lost here Sep 14 13:22:17 PlanetExpress kernel: microcode: microcode updated early to revision 0x1f, date = 2018-05-08" <------- power restored syslog.txt
-
Thank you. I set that up last night and the power went out again this morning. Gotta love fire season in California! I really hope I can nail down the issue later today as this happens far too often lately.
-
I realize that, but I don't know how to go about tracking down the exact cause. I can write to the flash drive from putty, so I'm just assuming that's not the issue. How do I track down the exact cause? I read that there are logs on the flash drive when this happens, but there's no log folder on it and the only log file I see is the parity check one. Where are those logs supposed to be? What should I be looking for in them?
-
Hey there everyone! I could use some help figuring out why I'm getting unclean shutdowns. I've read multiple posts, checked settings, rechecked settings... Clearly, I'm missing something. Hopefully, it's not too obvious. Using NUT (had the same problem with Unraid's UPS tool, that's currently disabled) Shutdown Mode: Time on Battery Time before shutdown: 4 Current shutdown settings: VM shutdown timeout: 300 (I have 2; 1 Windows, 1 Ubuntu. The Windows box does not get automatic updates.) Disk timeout: 420 ssh,bash killed by tips and tweaks The Cyberpower UPS passed it's diag tests (their software, run on my Win10 laptop) and there's plenty of charge left on the battery after the server's off. When I manually shut down the server, it gracefully shuts down in about a minute or so. Thanks for any and all help! ------------------------------------------------- SOLUTION: New batteries. -------------------------------------------------
-
You have no idea how much time I spent trying to figure out why my server lost 'net access. THANK YOU.
-
So I got the docker installed, tested it and can connect with the client, but I still can't login via the command line to do anything. I get the "welcome" text when I telnet in, but no prompt. Everything I type comes back with an error. IE "error id=1538 msg=invalid\sparameter" when I type "help" or "login"
-
I had the same problem, ended up deleting the sensors.conf from BOTH /etc/sensors.d/ AND /boot/config/plugins/dynamix.system.temp/. Then, I uninstalled the plugin and re-installed it. That fixed it, for me at least.
-
Just installed this docker and I get the following error when starting the UI: [12.12.2018 17:02:38] WebUI started. [12.12.2018 17:02:38] Bad response from server: (401 [error,getplugins]) Unauthorized Then, if I click on the setting icon, I get: [12.12.2018 17:03:27] JS error: [http://10.0.0.151:8082/js/webui.js : 762] Uncaught TypeError: Cannot read property 'rTorrent' of undefined Any ideas?
-
Just installed this plugin (on unraid 6.3.3) and the moment I click on the "start vboxwebsrv" button I lose all unraid GUI access. The only way to get back to the unraid gui is to ssh in and kill all the virtualbox stuff. Then everything immediately loads like it should. I've tried several ports, it doesn't make any difference. No errors, no log info, it just kills the unraid GUI.

