



abhi.ko
Members
-
Joined
-
Last visited
Everything posted by abhi.ko
-
Not a precleared one. But I do have a 10TB disk that is not in the case or array.
-
Both mounted fine - still disabled and emulated. Disk 12 has no lost+found Disk 19 only has lost+found Diagnostics & screenshots below. What now please? Thanks for all the help till now. tower-diagnostics-20220213-1131.zip
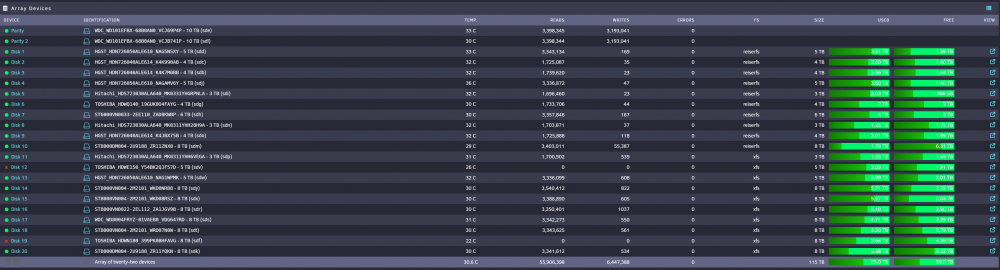


-
Phase 1 - find and verify superblock... sb root inode value 18446744073709551615 (NULLFSINO) inconsistent with calculated value 128 resetting superblock root inode pointer to 128 sb realtime bitmap inode value 18446744073709551615 (NULLFSINO) inconsistent with calculated value 129 resetting superblock realtime bitmap inode pointer to 129 sb realtime summary inode value 18446744073709551615 (NULLFSINO) inconsistent with calculated value 130 resetting superblock realtime summary inode pointer to 130 Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being destroyed because the -L option was used. - scan filesystem freespace and inode maps... clearing needsrepair flag and regenerating metadata sb_icount 0, counted 100480 sb_ifree 0, counted 224 sb_fdblocks 1952984857, counted 1078863610 - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 bad CRC for inode 128 bad CRC for inode 128, will rewrite cleared root inode 128 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 2 - agno = 4 - agno = 3 - agno = 6 - agno = 5 - agno = 7 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... reinitializing root directory - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... disconnected dir inode 131, moving to lost+found disconnected dir inode 1171237, moving to lost+found disconnected dir inode 4294967432, moving to lost+found disconnected dir inode 6442451075, moving to lost+found disconnected dir inode 6517809021, moving to lost+found disconnected dir inode 10737418371, moving to lost+found disconnected dir inode 15032385664, moving to lost+found disconnected dir inode 15032385666, moving to lost+found disconnected dir inode 15032385667, moving to lost+found disconnected dir inode 15609373013, moving to lost+found Phase 7 - verify and correct link counts... resetting inode 98436057 nlinks from 2 to 12 Maximum metadata LSN (1:438928) is ahead of log (1:2). Format log to cycle 4. done Disk 19 had lot more lost+found moves.
-
Oh that's right - I ran it without the -n just the -L - so repair is already done, you are right. Let me do the same for disk 19 and then try and mount both drives - start array without maintenance mode. Will report soon.
-
Thank you. Below is the output of the -L option on Disk 12 (sdv) Phase 1 - find and verify superblock... sb root inode value 18446744073709551615 (NULLFSINO) inconsistent with calculated value 96 resetting superblock root inode pointer to 96 sb realtime bitmap inode value 18446744073709551615 (NULLFSINO) inconsistent with calculated value 97 resetting superblock realtime bitmap inode pointer to 97 sb realtime summary inode value 18446744073709551615 (NULLFSINO) inconsistent with calculated value 98 resetting superblock realtime summary inode pointer to 98 Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being destroyed because the -L option was used. - scan filesystem freespace and inode maps... clearing needsrepair flag and regenerating metadata sb_icount 0, counted 127424 sb_ifree 0, counted 48832 sb_fdblocks 1220420880, counted 466358182 - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 bad CRC for inode 128 bad CRC for inode 128, will rewrite cleared inode 128 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 2 - agno = 3 - agno = 1 - agno = 4 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... Maximum metadata LSN (14:3179447) is ahead of log (1:2). Format log to cycle 17. done Planning to run now from terminal - xfs_repair -v /dev/md12 confirming that is the right next step?
-
Thank You. Will do now. Was worried about the comment "this might cause corruption"
-
Phase 1 - find and verify superblock... bad primary superblock - bad CRC in superblock !!! attempting to find secondary superblock... .found candidate secondary superblock... verified secondary superblock... writing modified primary superblock sb root inode value 18446744073709551615 (NULLFSINO) inconsistent with calculated value 128 resetting superblock root inode pointer to 128 sb realtime bitmap inode value 18446744073709551615 (NULLFSINO) inconsistent with calculated value 129 resetting superblock realtime bitmap inode pointer to 129 sb realtime summary inode value 18446744073709551615 (NULLFSINO) inconsistent with calculated value 130 resetting superblock realtime summary inode pointer to 130 Phase 2 - using internal log - zero log... ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this. Got this now. The disks are unmountable as seen earlier. So should I run the check with -L and then attempt the repair or just ditch trying to repair and just resync parity to the same disk?
-
@JorgeB As instructed, I ran the xfs filesystem check with the -nv option on both my disabled disks (12 & 19), and both was not able to run came back with this: Phase 1 - find and verify superblock... bad primary superblock - bad CRC in superblock !!! attempting to find secondary superblock... .found candidate secondary superblock... verified secondary superblock... would write modified primary superblock Primary superblock would have been modified. Cannot proceed further in no_modify mode. Exiting now. What do you recommend? Should I even tryin repair or just resync parity? Could you please specify the steps for resyncing parity with 2 failed drives for me? Thank you @Michael_P and @Vr2Io - I will distribute the molex connections better and report back. I am planning to use 1 backplane to 1 SATA/PERIF connector on the PSU.
-
thanks again. I do not plan to do the DIY connectors - is using the SATA to Molex adapters not a good substitute? Where would I get additional molex connector cables for the PSU from would any cable work with any PSU or do I have to buy the same PSU manufacturer.
-
Thank you both for clarifying. So long term if I get a PSU that has 6 SATA/PERIF 6 pin outputs, something like this one, and setup a one backplane to one connector ratio, on the PSU that should be ideal right? 4 HDD's on one PSU connector. Also if I use a SATA to molex cables to connect these single back planes to a SATA PSU connector would that be okay or do I need to get 6 molex to 6pin PSU connectors? Appreciate all the help guys. Learning things I did not know, so I appreciate it very much.
-
Thanks - but I am a little confused, because this is all still on a single 12V line right, irrespective of what connector we plug it into? So how does it distribute the load? Apologies if I am missing something obvious. Is the 83A power draw enough to boot up the whole system, I thought that was the problem and I needed a more beefier PSU with more amperage on the single 12V line. If yes, then I have a few of these lying around - shouldn't these do the trick, connect them to the SATA connectors from the PSU, and connect 6 backplanes to the 4 SATA/PERIF connectors. Not 1:1 but that distribution of the load should help right, currently everything is on one connector to the PSU.
-
Thank you @JorgeB I will do it. should I do something about the power situation in my case before that. Based on other comments here from @Michael_P and @Vr2Io - Thank you both and yes I am using power splitters to connect all 6 backplanes to a single PSU connector (picture attached) - which I think might be causing all of this, please correct me if I am wrong. Should I get a different PSU - I currently have this - which I believe is a single +12V rail PSU with a 83A max output. I have a total of 23 disks including parity and cache (cache is an SSD) and majority of these HDD's are the 7200RPM ones. If I should change - do you have any recommendations? Or should I change how they are powered?

-
Diagnostics attached. Also attached is a picture I took from the monitor attached to the server, seems like that is for the two disabled disks, but attached just in case if it gave more info. All other disks mounted fine. No sounds other than the normal bootup and fan noises were noticed. Hopefully this diagnostics has enough information. tower-diagnostics-20220208-1240.zip
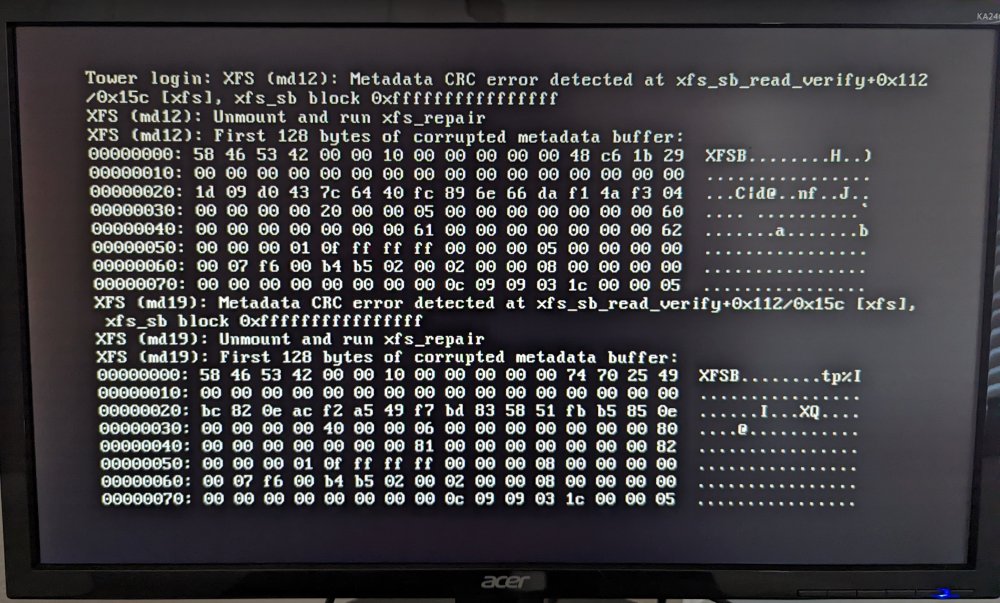
-
Thank you @Michael_P What do you mean by splitters? Like a SAS to SATA cable? I use a Norco 4224 case which has a SAS backplane with 6 SAS connectors (1 per 4 drive tray) and I have 8 Sata slots on my motherboard, which are connected using 2 SAS to 4 Sata reverse breakout cables and 16 drives goes directly to the LSI 9300 16i card, using SAS connectors similar to this. Both failed drives are on the SAS cables connected directly to the HBA card. Only one of the sata connected discs are showing errors. Do you mean the reverse breakout cables when you say splitters?
-
Will do. At work now, but will post soon.
-
Okay I will turn on and listen to it and see if I hear anything. I have reconnected all the cables and re-seated the LSI card and made sure all connections are tight. Question - I have two drives that are disabled in the array - what are the next steps when I turn it on, do I just unassign them and start the array and stop again and reassign the same drives and let the parity resync run for both drives at once, or do I do one drive at a time, or should I do something else? I have dual parity, so if one more drive becomes disabled then I will loose data wouldn't I? I just rebuilt another old Seagate drive that failed last week, not sure if that is related to this or not, so I'm concerned whether one of these drives with reallocated sectors will go bad before the parity sync finishes and cause me to loose data. Any suggestions you have for next steps would be very helpful, as I had asked I can turn the array on and run/post diagnostics as a first step, and then shutdown the server, if you think more information would help and if that is safer.
-
Thank you both. How can we make sure if it is the drive or the PSU or the cables? I do not know why it is only those Toshiba drives and not any of the other 18 or so drives.
-
What do you suggest? Should I start the array with the two disabled disks and run diagnostics to post here. Array is mountable though. I am just worried about loosing data. I keep getting sector reallocated errors and the counts going up on all the Toshiba disks I have on the array, weird that it is just those disks they are spread over in different trays (physically) on the case as well. So it is not like one tray/backplate has gone bad, other disks are not having the same errors. Is there any issues with Toshiba disks that has been reported, especially with RC2? Screenshot below of all the warnings I got when I turned the server on for a few minutes. Any advice on next steps please?
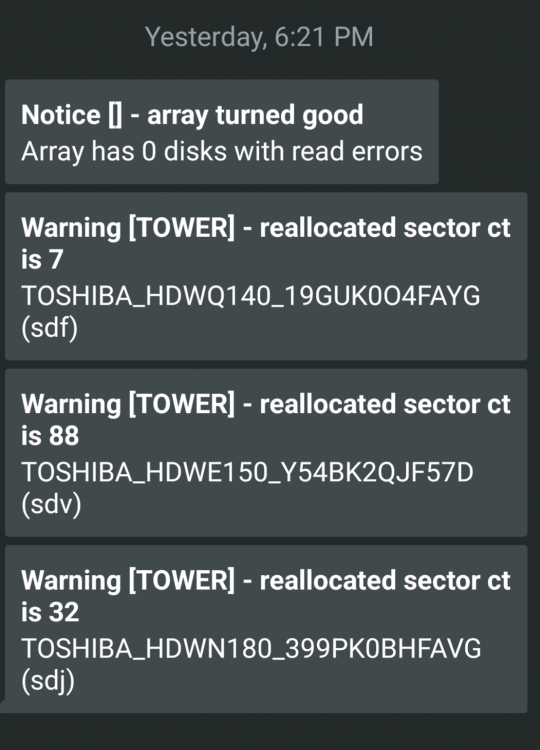
-
I have an LSI 9300 16i controller and 4 SAS cables plugged into it and it has a power connection from the psu as well. psu is a 1000w EVGA psu which should be plenty of power I thought, shouldn't it be? I just reconnected all the cables to the LSI card again and re-seated the card. I started the server and see the two disks are in disabled error state. I have dual parity can I just rebuild it on to itself. Attached a diagnostics output without starting the array, not sure if that helps. tower-diagnostics-20220207-1833.zip
-
Hello All - I have multiple disks in the array failing and multiple disks with errors, out of the blue. Seems like it is my controller or cables that is causing the issue, but not sure, i did check everything recently when I added some RAM and all looked good. I have the server shutdown currently since there are 2 failed disks now. The attached diagnostics was before the second one had failed. Multiple disks with errors as well, I did replace one failed disk and while the parity sync was going on I got a log full of errors and multiple disks were reporting errors and one failed at the beginning of parity sync and the second one towards the end. I did recently update to 6.10 rc2, but the initial issue started while I was on 6.9 stable, referenced here, the disk now in failed state is the same one referenced in that thread. I did a Win 11 VM yesterday which got added fine and everything was working well, and then this started. Please help. I have an HA virtual machine that is always running and hence my home automation is not working either currently. I am trying to determine next course of action, all hardware is pretty new. tower-diagnostics-20220207-0650.zip
-
@Squid Disk 12 was rebuilt as we discussed and you had suggested, but I keep having errors. I have checked cables and everything looks good but no idea why the errors keep happening. Another disk failed, but that was a really old disk so I replaced it and now it is stuck mounting. the diagnostics I downloaded before stopping the array to restart is attached as well. PLease - all help is welcome. tower-diagnostics-20220206-1206.zip
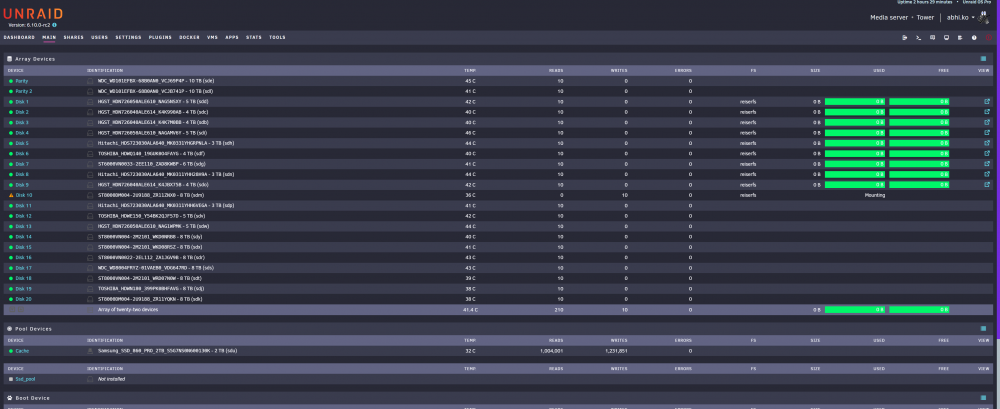
-
Perfect - thank you @Squid
-
Thank you sir! When you say 'being it' you mean just reassign the disk to the same slot or added to another empty slot after the new disk is rebuild? Does the disk look okay? Also should I wait for the Read-Check to finish or just cancel it and start with the rebuild process.
-
Happy New Year everyone! My new year started with a minor issue on the server. I have one disk showing up as disabled/error after I had to reboot the server mid-parity check, I forgot parity check was running. Currently the server is performing a Read-Check after the unclean shutdown was detected. I only have a single disk parity enabled, was planning to upgrade to dual soon, I have two drives pre-cleared and ready for an emergency such as this, so I can swap the failed drive and rebuild. One drive is the same size as my current parity and the other one is smaller, however I had a few questions before I start that process. Wanted to make sure that the failed drive is actually a goner and need to be thrown away or if that can still be cleared and added back to the array. Diagnostics posted below - can someone please take a look and let me know what you think about Disk 12 (sdv)? Should the second parity drive be the same size as the current one? Also is adding a second parity drive as simple as assigning the pre-cleared drive to the second parity slot on the array and restart. Order of operations - planning to first rebuild the new disk to replace the failed one, once that is finished run a parity check with the new disk assignment and then upgrade to dual parity? All help appreciated as always. tower-diagnostics-20220101-1441.zip
-
Hello - installed this plugin and it is working fine - Thanks for the work. I am not super knowledgeable regarding networking - but I am using the remote access to LAN as shown below, followed the steps laid out in the very detailed write up, and I can connect to Unraid and docker containers (e.g. Plex, Emby etc.) well from outside my home network, so ports are forwarded correctly and everything seems to be working well. However I cannot access anything else connected to my LAN (e.g. Pi-Hole running on an R-Pi) or my router admin page. I was using openVPN before this and could access all devices on the network easily. Any advice for me to try and get to everything connected to the LAN? Thanks in advance.








