





RealActorRob
Members
-
Joined
-
Last visited
Everything posted by RealActorRob
-
It wasn't, and I turned FTP off. It had no users enabled and firewall wasn't opened so it was pretty secure, but, one less thing. Thought I'd turned off FTP already...might have been doing something with it and forgot to re-disable. I also turned off the mover log, since mover isn't having issues ATM to reduce log file size.
-
Found this on the device page under SMART log: ATA Error Count: 1 CR = Command Register [HEX] FR = Features Register [HEX] SC = Sector Count Register [HEX] SN = Sector Number Register [HEX] CL = Cylinder Low Register [HEX] CH = Cylinder High Register [HEX] DH = Device/Head Register [HEX] DC = Device Command Register [HEX] ER = Error register [HEX] ST = Status register [HEX] Powered_Up_Time is measured from power on, and printed as DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes, SS=sec, and sss=millisec. It "wraps" after 49.710 days. Error 1 occurred at disk power-on lifetime: 54381 hours (2265 days + 21 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 10 51 08 70 c9 a5 02 Error: IDNF Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 2f 00 01 10 00 00 00 00 3d+07:43:39.996 READ LOG EXT 60 20 08 e8 93 6d 40 00 3d+07:43:39.996 READ FPDMA QUEUED 60 00 00 e8 8f 6d 40 00 3d+07:43:39.996 READ FPDMA QUEUED 60 b0 00 38 8c 6d 40 00 3d+07:43:39.991 READ FPDMA QUEUED 60 00 00 38 88 6d 40 00 3d+07:43:39.986 READ FPDMA QUEUED
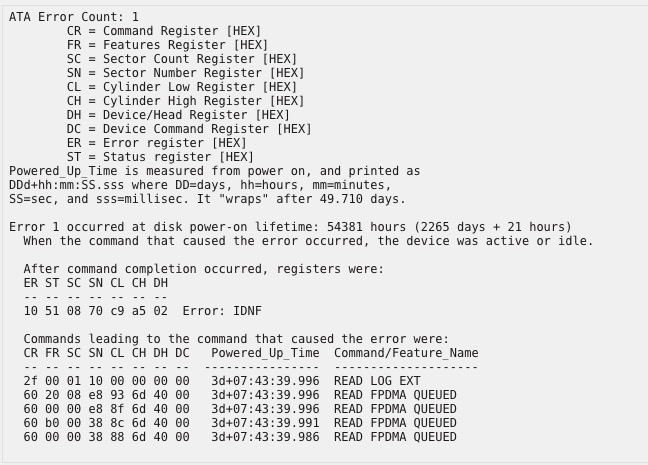
-
It's from Automounter, which helps keep SMB shares from dropping and/or it's a discovery of services from same. It's helped with my SMB issues doing backups on Mac OS X Mojave.
-
It's a 4TB I've run other tests on and all turned out fine. I replaced my working 3TB Parity 2 drive for future upgrades. So, this drive got x'd during a rebuild of parity onto it. Drive is in a disk tray on a server, so I doubt this is a 'cable' issue. Preclear went normally. Rebuild had 1 read errors but the SMART doesn't show ANY read errors or fails. running another preclear now and an extended test now. A short time ago, 800 hrs, this also passed an extended. Diags attached. Thoughts? To sum: other than the 1 read error on the parity rebuild, I don't see ANY indication of drive problems. I'm sure this is an ex-data center drive, noting the power on hours vs. power cycle count. blacktower-diagnostics-20211213-1224.zip

-
Votes for: 1. Algorithmic caching of files, perhaps saying, use 50% of an SSD for this. A FIFO. Older files get aged out and written to the array. Drobos have a cache 'accelerator' bay that presumably does this. Hybrid drives have this. I.e., the Windows OS probably lives on the SSD portion of the drive as it gets read and written the most. 2. A certain % of fullness where the mover triggers vs. being time based. 3. Autobackup to array of VMs etc. that are on the cache drive. And should really rename this function since this isn't really caching? It's just fast storage. 4. Perhaps an asynchronous mirror of the cache drive. I.e., cache drive is priority read/write on the mirror then the SSD gets sync'd to it's mirror as speed allows. Example: I could have a 1TB SSD and a 1TB 5400 drive in the array that is a mirror of the SSD. No problem as long as the drive can catch up eventually.
-
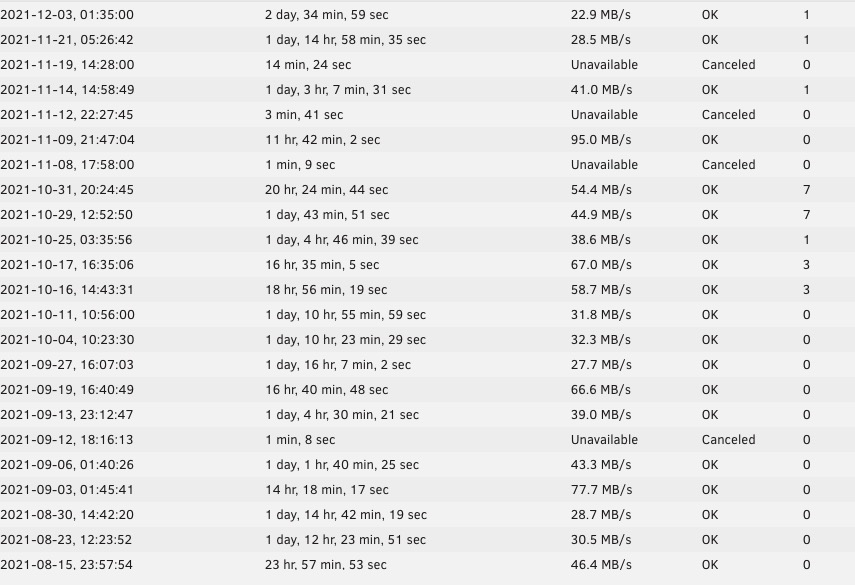
Same drives, same USB stick. I just moved from an X3440 Xeon T310 to an R720XD. (Intel® Xeon® CPU E5-2630 0 @ 2.30GHz) 16GB RAM vs 32GB RAM in the 720. All that said, my parity checks are RADCIALLY faster in the 720. Two parity disks, but the X3440 never was above 40% usage or so. So, I can't figure out why the older was so much slower, SOMETIMES. Just put the drives in the 720 and I'm getting 67.5 about 15% in to the check. The 1 error is the same uncorrected one, on one of the parity drives, so I'm just running another due to the drive move. On the 9th tho, it ran at 95Mb/s (!!) but the speeds are all over the map. Just a puzzler. Before I shut it down it had an uptime of like 3 weeks and that has been because of power issues. UPS battery just failed today so it evidently was erroneously saying it was good....which lead to the power issues and I'm sure, the parity issues. And per advice here, now I only do the parity check once per month. I'll probably correct that 1 error on the Q drive IIRC the next time I run it.
-
You've got ALL new drives? I'd just move the existing drives (backup beforehand if you can) and then replace them later one by one after preclearing or doing some sort of burn-in. Then if the drives are really new you don't have to worry about if 1 or 2 die relatively quickly, as occasionally happens. I like to have drives of different brands/ages/etc. as well in case there's a bad lot. I run 2 parity drives as well, since some of my drives are older.
-
Bummer. I suppose there's a way to autosync the files but it wouldn't be quite the same...
-
I.e., if I have an SSD of 120GB and a hard drive of 120GB, will the pool operate at the speed of the slower device or will it write to the SSD then finish the write to the hard drive later? I'd like redundancy on the cheap. It's not a ton of data at the moment so it's not going to flood the hard drive in reality. Use case: I have a 120GB SSD and several 320GB WD Green drives I could throw in to mirror that. Although, yes, I should just buy a cheap SSD and probably will, this is a bit academic. But it could come into play, say, if I wanted to save a little and had a 512GB NVME mirrored by a 1TB drive.
-
Yup, did that. Now to see if my format is correct to exclude the other node. It'd be nice just to have checkboxes for drilling down to subdirs.

-
I'm running two storj nodes and that's where all my 'errors' are reported. The exclusions in settings are for top level folders, so now I have to figure out how to exclude a subfolder.... Can I request that feature or am I missing something?
-
This *MAY* be Automounter. A tool that keeps shares from disconnecting. Not sure why it would show vsftpd connections other than maybe it's scanning something....
-
I turned off the FTP server. Not sure why it was on. There were no usernames in the FTP user(s): slot. Blank. It says user access is disallowed but if I enable the server with no usernames still, I get connections from an internal machine. 9 19:02:42 BlackTower ool www[6129]: /usr/local/emhttp/plugins/dynamix/scripts/ftpusers '1' '' Nov 9 19:02:49 BlackTower vsftpd[8488]: connect from 192.168.1.105 (192.168.1.105) Nov 9 19:02:53 BlackTower ool www[6129]: /usr/local/emhttp/plugins/dynamix/scripts/ftpusers '0' '' Nov 9 19:14:59 BlackTower ool www[2467]: /usr/local/emhttp/plugins/dynamix/scripts/ftpusers '1' '' Nov 9 19:15:12 BlackTower vsftpd[25242]: connect from 192.168.1.105 (192.168.1.105) Nov 9 19:15:27 BlackTower vsftpd[26488]: connect from 192.168.1.105 (192.168.1.105) Nov 9 19:15:32 BlackTower ool www[26467]: /usr/local/emhttp/plugins/dynamix/scripts/ftpusers '0' '' Am I hacked? Scanning for viruses/malware now and installing 'Little Snitch' on my Mac Pro, which is the machine it's coming from.
-
I don't spin down disks, probably would increase wear if I did because I span disks for two storj nodes. If storj takes off, it'd be somewhat harder to increase storage I'd think if I limited it to certain disks. One thing that would make this easier is if unraid had a feature to unspan directories. Would also help to remove a disk without losing parity.
-
The complete File Integrity hash build should be a good test to see if anything's truly wrong since that'll read every file on the array, correct? Backups to the NAS have seen no big issues, so that's good.
-
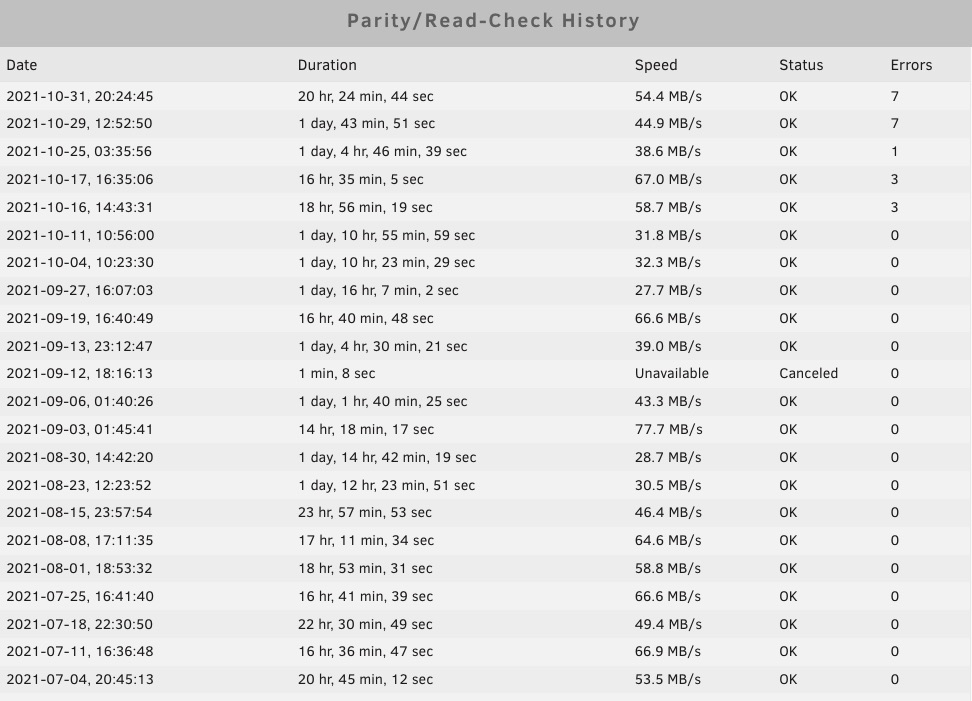
SUGGESTION: We need a good guid in the FAQ to handle parity issues. Some sort of flow to follow. First, there were power issues and though I have a UPS, I cannot assure that shutdown wasn't dirty. IIRC, there were some. As of now, UPS load is around 150W with a runtime of 40+ minutes so shutdowns SHOULD be graceful going forward...can't recall what load I had before, been doing some tweaks. (Crypto mining.) No SMART errors, but I'm running extended tests on all my drives. I'm Dynamix File Integrity is building now. I've been meaning to do that. Sorry, there's no log yet since I've had to shutdown for power issues since the last parity error. Schedule is to run on Sundays. In October, Sunday was 3rd/10/17/24/31. So, assuming the 16th was a power issue, and maybe I ran the 25th accidentally to correct but that means 7 popped up on the 29th. But none appeared between the 29th and 31st. The 16th must have been for power. My server has ECC so I'm guessing this is not a RAM issue but a dirty shutdown issue. I have two parity disks. When File Integrity is done, I'll run a check and get some logs. Log:
-
Got it running. Notes and a YouTube video to follow. Using XMrig CPU only just to get it going. First note, 3GB of RAM is enough. Have 300+mb left over. I suppose this might not be enough for GPU mining, but it's fine for CPU XMR mining.
-
I gave up and got HiveOS installed in a VM.
-
I'm thinking I need to allocate more resources to the Container....gotta research that. Every time I go to CA and pull it, it just more or less stops updating during the install. Sometimes it's running, sometimes not. When I edited it last time, it just left me with an orphan image. Where should I look in the logs/start? EDIT: Here's something: Sep 11 22:08:01 BlackTower nginx: 2021/09/11 22:08:01 [error] 8214#8214: *63500 upstream timed out (110: Connection timed out) while reading upstream, client: 2600:1700:4c60:e8f0:f1ab:d0ad:81bd:db28, server: , request: "POST /Apps/AddContainer?xmlTemplate=default:/tmp/community.applications/tempFiles/templates-community-apps/lnxdsRepository/lnxd-XMRig-latest.xml HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:"
-
My other dockers are normal. Also, when I go to edit it and apply, just sits at Stopping container: XMRig for a good long time. 16 gig RAM XEON X3440 (4 cores, 8 HT) Usually have plenty of CPU/RAM. The big peak was the pinned XMR task...decided to use only one core/HT leaving other 3 of each free. (No, not CPU 0 ) Also, when I go to the Docker tab from the Stats tab...VERY slow to show Docker images. Like, MINUTES to even show the Unraid undulating 'wave'. Last time, it installed and going to Docker in another tab showed it running but the install never showed it as complete. As far as I can see, feels beta. GTG, but will play later. Overall it feels like it kinda works but appears to fully load down the machine, and when installs complete, it doesn't say so. And it's a simple CPU mine, no GPU passthru.

-
Installs hang, typical example: IMAGE ID [1638176776]: Pulling from lnxd/xmrig. IMAGE ID [a70d879fa598]: Already exists. IMAGE ID [c4394a92d1f8]: Already exists. IMAGE ID [10e6159c56c0]: Already exists. IMAGE ID [4e603f86bf28]: Already exists. IMAGE ID [82c680df2f37]: Pulling fs layer. Extracting. Pull complete. IMAGE ID [8c1b41ba1f70]: Pulling fs layer. Download complete. Extracting. Pull complete. IMAGE ID [216bbbf373ef]: Pulling fs layer. Download complete. Extracting. Pull complete. IMAGE ID [0014a10ac7a2]: Pulling fs layer. Download complete. Extracting. IMAGE ID [e1091e29ea56]: Pulling fs layer. Download complete. IMAGE ID [4a0de8df1f80]: Pulling fs layer. Download complete. IMAGE ID [6fdc9aa00473]: Pulling fs layer. Download complete. IMAGE ID [2e39212cd8e6]: Pulling fs layer. Download complete. IMAGE ID [a9178ef1956c]: Pulling fs layer. Download complete. IMAGE ID [0828d163e125]: Pulling fs layer. Download complete. IMAGE ID [59304a045975]: Pulling fs layer. Download complete. IMAGE ID [1520d09c5763]: Pulling fs layer. Download complete. IMAGE ID [88f444ce6619]: Pulling fs layer. Download complete. IMAGE ID [fc60839e3db2]: Pulling fs layer. Download complete. IMAGE ID [0d598aeec96a]: Pulling fs layer. Download complete. And it's been sitting there. Server normal in other resepects. Tried at least 3 or 4 times.
-
I've done a lot of things, but this helped the most: https://www.pixeleyes.co.nz/automounter/support/ It remounts shares if they get disconnected. That's all. I was having issues with losing the shares when backing up with Carbon Copy Cloner. Cautiously optimistic as my backups complete way more often now. SMB sucks and I wish AFP were not deprecated in 6.9 Also, I think not backing up folders with lots of files / long path names has helped. Such as the Mail folder. Don't back up Mail.
-
Can this be used with data drives on 6.9.2? Don't have any cache drives.
-
Can't view the 'bands' directory that Time Machine creates as part of a .sparsebundle In general, I'm finding Unraid and Mac OS backups to be just suck. Carbon Copy Cloner also dies most times saying the filesystem isn't responding. I just think Unraid in general chokes on too many files/dirs. I have two storj nodes running so that is perhaps part of it. I'm sure it has a fiar amount of open files. That said, storj works fine. Any ideas for this issue? 16 gigs of RAM, gigabit, Xeon X3440 with ECC. Should be a fine system for these few things. No media being served.
-
Greaaaat.....as if SMB didn't suck enough already. Still on 6.8.3 here on Dell T310 and it's dropping the connection during a Carbon Copy Cloner backup. Sometimes it works, sometimes it don't. Fairly small backup, something like under 500GB over GigE.








