





RealActorRob
Members
-
Joined
-
Last visited
Everything posted by RealActorRob
-
Killing this now....the docker is all shut down so this file is def not in use...plus 'find' is read-only.... root 779712 3868238 2 13:31 ? 00:01:00 find /mnt/disk3 -type f -name * -newer /tmp/d.29891.list.0 -exec getfattr -n u Not sure what started this but killing the process via Open Files plugin which opened a blank popup so that may or may not have worked...then issued 'kill 779712' via the GUI CLI worked and the array shut down after about 45 secs. storj generally in my years of experience has had all sorts of issues with Unraid, but most or all of it has been open file issues going way back. HTH

-
Not honoring memory limit? --memory=6144M via Extra Parameters fixed it ignoring the template limit. 24gb is my machine memory and I set the docker limit to 6144 via the max memory setting in the template. Other dockers are what I set. CrashPlan v11.6.0 Docker Image v25.07.2 CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS 16af8e353fba storagenode 3.03% 227.5MiB / 4GiB 5.55% 108MB / 88MB 1.17GB / 137MB 71 d44575bebc68 storagenodebig 2.18% 226MiB / 4GiB 5.52% 181MB / 124MB 1.58GB / 158MB 78 3f7ff220871c myst 0.75% 88.7MiB / 1GiB 8.66% 361MB / 397MB 2.33GB / 9.72MB 16 f10223b89d2a CrashPlanPRO 73.40% 780MiB / 23.43GiB 3.25% 27.5MB / 34.3MB 2.24GB / 3.14MB 208
-
If 6.12.4 is autotuning, it's doing a horrible job. Upping the strpes value made a HUGE diff in my rebuild speed, like 5x at least. 24gb RAM, Intel® Xeon® CPU E5-2697 v2 @ 2.70GHz Dell R720XD

-
I could not access the webgui with the error that there is no minecraft screen to attach to. I had forgotten the 'M' in the Dockert emplate settings for memory amount. Server appeared to start but really didn't I presume.

-
Also worked for me, boom. What things should I look for to stop from crashing tho?
-
Specifically: modprobe –r acpi_pad modprobe: FATAL: Module –r not found in directory /lib/modules/6.1.64-Unraid Works: modprobe --remove acpi_pad modprobe -h says "-r, --remove" So why is it not happy with what should be the same flags?
-
If anyone is running a storj node, it likes to leave open files even with docker stopped. Use the "Open Files" plugin to see what it's not closing and kill that process after making sure the Docker is stopped. This happens fairly often. In this case, CLI from web works if this plugin doesn't....window popped up blank so : kill 41524

-
Yeah, I'm looking for a good price on a drive...might get a lightly used datacenter large drive then replace it with one of the 4TB parity drives. Worst case if it fails I have a 4TB SMR or just swap them back...plus i can tolerate 2 fails. Note @JorgeB that I also changed the CPU governeor to 'on demand' and it's a bit faster tho it wasn't being pushed before anyway.
-
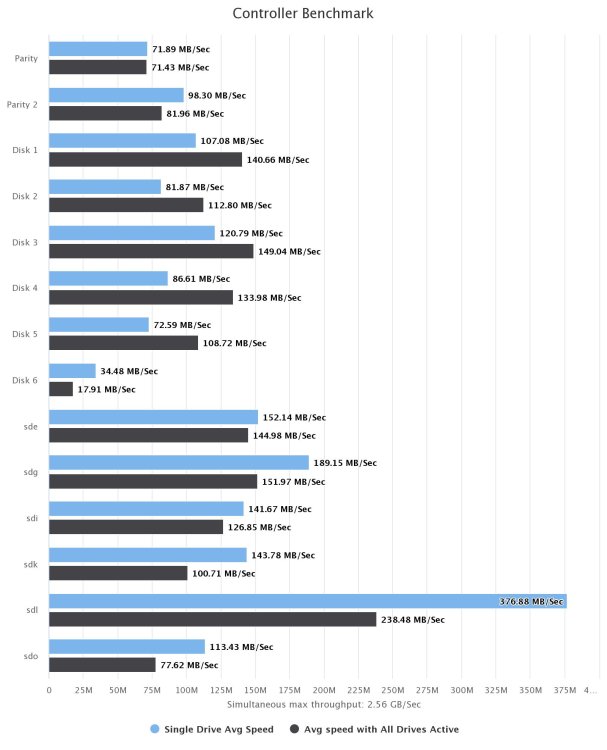
@itimpi Disk 6 seems a little wonky but here's diskspeed, ran just now DURING the parity check. It's getting pretty old, at over 7 years but SMART values are all 0 not even a CRC error. Cool at 40C as well.
-
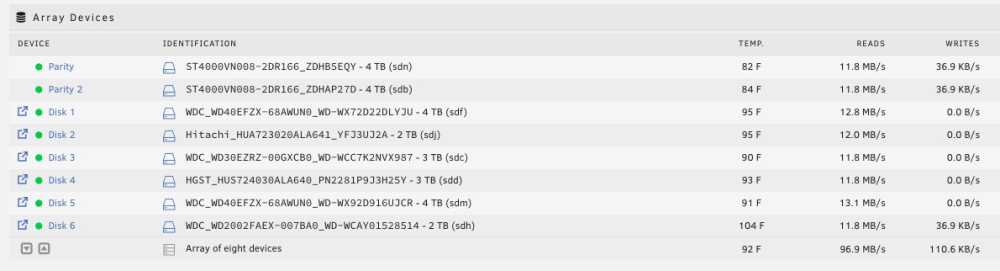
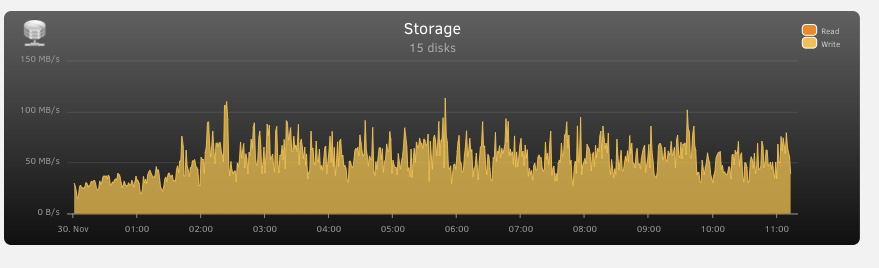
Still slow, but still don't see how they should be this slow. Only one bench didn't have a steady curve from Diskspeed, one of the parities. I watched it for a bit and never saw it peak over maybe 30 on one for a few seconds. Here's total throughput and something weird on reads: Obviously this isn't correct but maybe a clue? And I don't see how disk speed benches ok and then the parity check crawls, haven't had a fast one since March. And that's across the board slow not just sections of some disk. Real head scratcher.
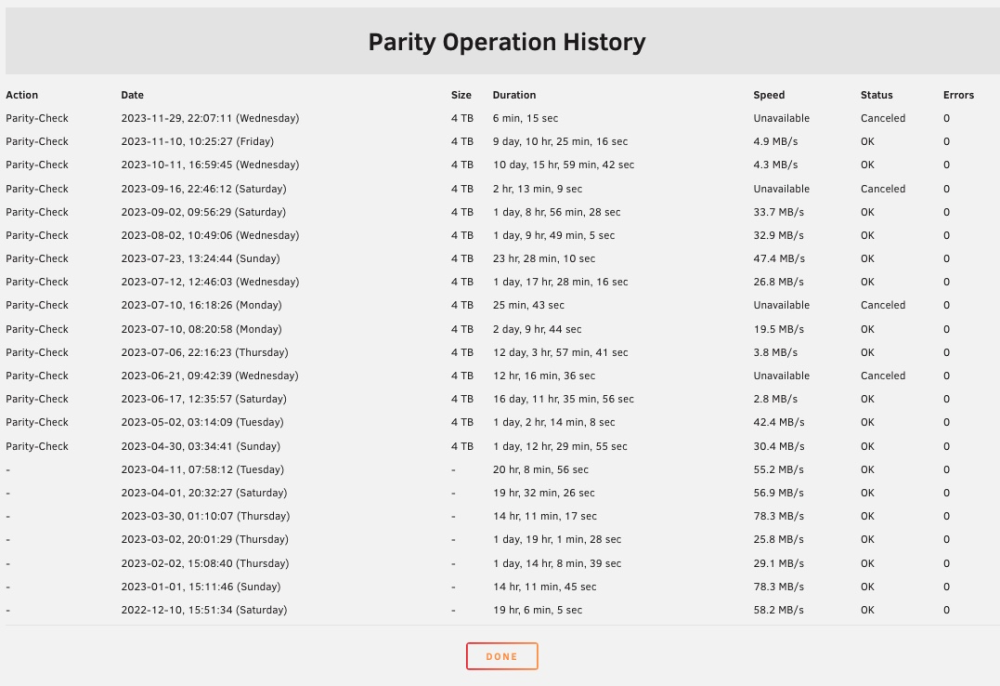
-
No errors, drives bench way fast, total drive throughput is about 35-40 max. 11 days projected to complete, largest drive 4tb. No SMR. For some reason two of my drives are slow at 50ish each (will address that) but there's no reason I can find for a sub 4Mb/s parity check. Controller links at 4GB/s. Diags attached. blacktower-diagnostics-20231130-0037.zip
-
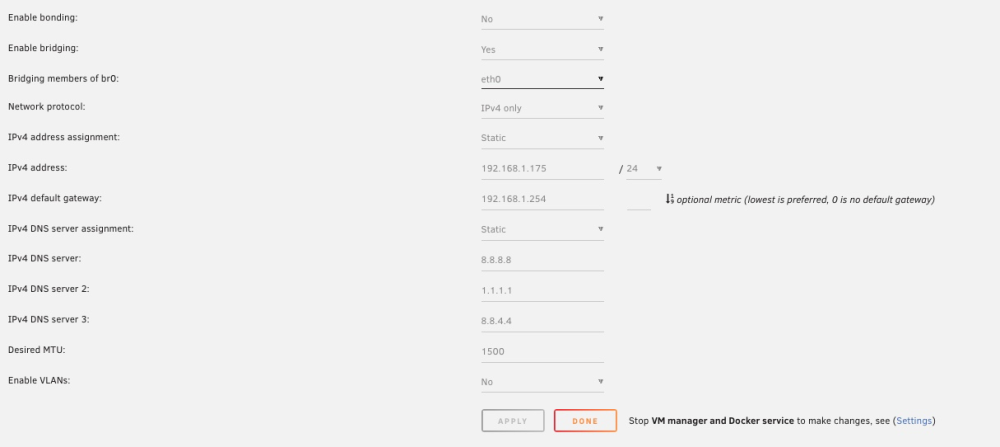
It was blank so 1500 was the default. I just input 1500, applied, erased 1500, applied so it would go to auto.
-
blacktower-diagnostics-20231129 Diags attached and yes, the array is getting full. Cache pool upgrade and capacity upgrade is underway.
-
Ok, this might be solved. Upgraded to 6.12.5 which seemed to help a tiny bit. Discovered errors in my Network settings though. 1. Somehow port 2 on my 4 port Dell R720xd Ethernet was 'Up' but there's no cable...perhaps all the DHCP requests etc. it was probably doing? 2. ipv6 was enabled so I changed it to ipV4 only. 3. Rearranged DNS to 8.8.8.8 first and 1.1.1.1 second and 8.8.4.4 as third. Shuffled. 4. Put 1500 in as MYU, applied, erased and applied smaking sure it's Auto. As of this moment, GUI is alo faster. Fingers crossed.
-
I'll attach diags when I can get them. Think it's this process at over 100% CPU? For instance, backing up USB drive takes forever. I wonder if the USB drive is failing. Or, perhaps one of the disks is failing but there have been no SMART issues. Diskspeed seems to have trouble. Real head scratcher. No errors just slow operation. Also at one point nginx wasn't running but nginx start started it. Next time, I've got the USB to SATA key that gives me a GUID instead of a USB stick. I've had more problems with those... Unraid, please just let us use a small SSD soon for boot. They're cheap.

-
Still having this issue. One Clue? Web GUI said it was still unmounting but it shut down clean fine via GUI when I pressed that button in the GUI after about 10 mins. Shut down so I could add an NVME. root@BlackTower:~# losetup NAME SIZELIMIT OFFSET AUTOCLEAR RO BACK-FILE DIO LOG-SEC /dev/loop1 0 0 1 1 /boot/bzfirmware 0 512 /dev/loop0 0 0 1 1 /boot/bzmodules 0 512 root@BlackTower:~# umount /var/lib/docker umount: /var/lib/docker: not mounted. root@BlackTower:~#

-
Have had unlcean shutdowns in the past. Changed timeout to 300 seconds. This time I also stopped the Dockers before a reboot. Not sure if it's fixed but here's the diags. blacktower-diagnostics-20231115-2027.zip Getting error -200 on diag upload but I have the one before reboot.
-
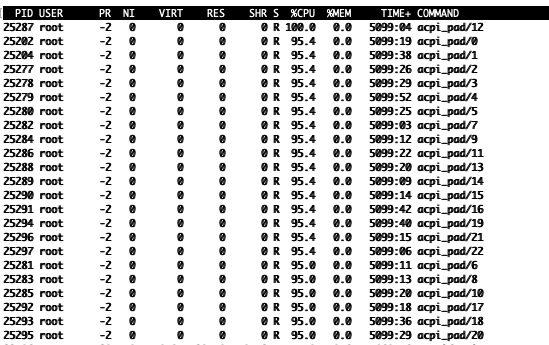
From Intel Doc "Intel® Omni-Path Performance Tuning" --quote-- Avoid acpi_pad Consuming CPU Resources acpi_pad is a module ACPI Processor Aggregator Driver. It is supposed to handle high core count processor power management. Unfortunately, the driver can cause a system to run acpi_pad and consume 100% of each core. A simple workaround is to blacklist acpi_pad by adding the following line to /etc/modprobe.d/blacklist.conf: blacklist acpi_pad This will keep the acpi_pad driver from loading at boot time. If you need to remove acpi_pad without a reboot you can use: modprobe –r acpi_pad This removes the driver. However, note that the driver will restart upon a reboot. --end quote-- modprobe –r acpi_pad worked. modprobe acpi_pad if you want to reload it. IMHO, this is an old Linux bug. CPU E2697v2 @Squid
-
That's what it came down too. Install failed but apparently uninstalled then it asked me to install it.
-
It looks like CA is just installing the same version over itself when I update. ca_log.txt
-
Edit: Finally unounted and was able to stop the array. Restarted to 'fix' acpi_pad multiple processes consuming all of the CPU resources. Waiting on other disk share unmounts but it did unmount the docker image finally. The acpi_pad sucking up all CPUs is perhaps why THAT is taking so long. Still mounted: NAME SIZELIMIT OFFSET AUTOCLEAR RO BACK-FILE DIO LOG-SEC /dev/loop1 0 0 1 1 /boot/bzfirmware 0 512 /dev/loop0 0 0 1 1 /boot/bzmodules 0 512
-
!'' Yes, I need to exclude folder that in my backup strategy but why grab all that, Diagnostics?

-
Can't get to GUI for diagnostics and not savvy enough for CMD process to do that but I'll try to find it later and update.
-
Similar situation. SMB copy from Mac OS to Unraid share, flipped off cache mid copy and copy was not interrupted. HTH. Was doing a copy via MC from an NVME to an /mnt share of 250+ GB with a 120GB cache, so it filled it. Aborted that, changed share to not use cache and re-did.
-
Doesn't OS X have SMB 3? Wouldn't connect with SMB 3 specified as min.
















