





RealActorRob
Members
-
Joined
-
Last visited
Everything posted by RealActorRob
-
Specs: Unraid 6.12.4 Cheap 120GB SSD Cache Disk SMB User Shares OS X 12.6.8 1Gb Ethernet 10GB Single File in about 2 mins. Filled the RAM first of course, file is on the cache SATA SSD. Used these from the Samba Wiki https://wiki.samba.org/index.php/Configure_Samba_to_Work_Better_with_Mac_OS_X #Changes by Rob server min protocol = SMB2 ea support = yes #Fruit Settings [Global] vfs objects = fruit streams_xattr fruit:metadata = stream fruit:model = MacSamba fruit:posix_rename = yes fruit:veto_appledouble = no fruit:nfs_aces = no fruit:wipe_intentionally_left_blank_rfork = yes fruit:delete_empty_adfiles = yes [TimeMachineBackup] fruit:time machine = yes #End changes by Rob
-
2.10.6 Some drives don't appear to bench. Stats plugin doesn't show activity, but drive is online, smart green etc. and hdparm works. /dev/sdf: Timing cached reads: 14826 MB in 1.99 seconds = 7443.88 MB/sec Timing buffered disk reads: 500 MB in 3.01 seconds = 166.26 MB/sec root@BlackTower:/mnt/disk5# sudo hdparm -Tt /dev/sdm /dev/sdm: Timing cached reads: 18884 MB in 1.99 seconds = 9490.98 MB/sec Timing buffered disk reads: 552 MB in 3.00 seconds = 183.74 MB/sec But on those drives the Diskspeed webgui sits there. WD40EFZX drives Clicking Abort just also sits there. /sdh works as expected. All drives are data drives in the array. Nothing in logs. Over 30 mins old and last log entries: WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release 10-Jul-2023 18:00:42.061 INFO [main] org.apache.coyote.AbstractProtocol.start Starting ProtocolHandler ["http-nio-8888"] 10-Jul-2023 18:00:42.075 INFO [main] org.apache.catalina.startup.Catalina.start Server startup in [14279] milliseconds Also rescanned controller, devs hadn't changed.
-
Similar. 06-07-2023 22:17Unraid Parity-CheckNotice [BLACKTOWER] - Parity-Check finished (0 errors)Canceledwarning I didn't cancel it but my server locked (no hardware issues noted yet, but my usb stick was corrupted a couple of weeks ago) Dirty bit set 'some corruption' warnings etc. It appears to me, yet AGAIN that the USB stick is the weak link in Unraid. For God's sake, please add some sort of redundancy at least to this weak link, say, it checks the USB stick against 2 other mirror files of it on the disk as a boot stick check.
-
----Event: Unraid device dev3 SMART health [199] Subject: Warning [BLACKTOWER] - udma crc error count is 10242 Description: APPLE_SSD_SM1024G_S218NYAH400397 (dev3) Importance: warning--- -Event: Unraid device dev3 SMART health [199] Subject: Warning [BLACKTOWER] - udma crc error count is 9 Description: APPLE_SSD_SM1024G_S218NYAH400397 (dev3) Importance: warning- So. in a week, it gave me over 10000 notifications. blacktower-diagnostics-20230628-1430.zip
-
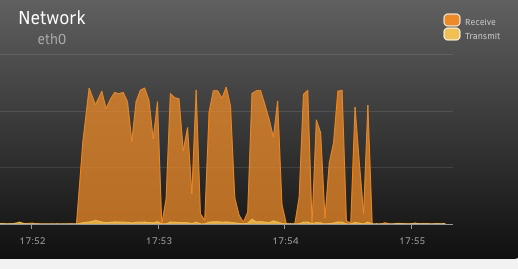
About one every minute. So, a connection issue? Flaky card? NVME previously in my Mac Pro. 1Tb Apple OEM card with no issues. So, card, slot, guesses? Remove, reseat, etc. is what I'll do. And lots of these
-
This page: When I hit 'Apply' auto start didn't stick and every click on apply had the temps changing, sometimes self setting to negative temperatures. After array start, worked fine. Could be related to my corrup disk.cfg I detailed in another post?
-
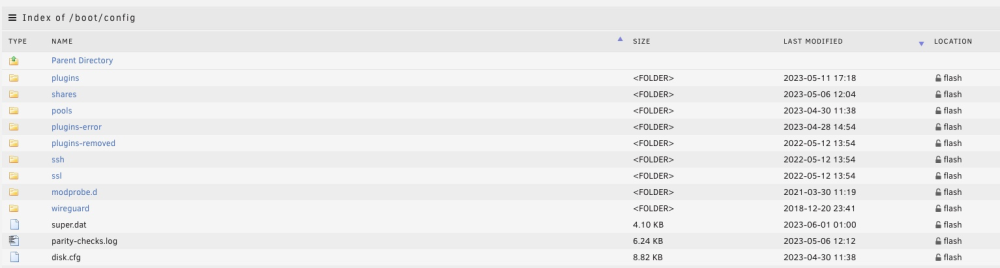
Found corruption in disk.cfg such as "diskSpindownD%lay.8="-1" (see the % vs an 'e'.) Had to delete more .notify files that wouldn't drag and drop but got the array started finally. USB drive was dying which was causing the NMI error on my Dell R720xd. New USB drive, key transferred after update Community Apps and adding Unraid Connect. Boots now. Whew. Glad it wasn't hardware....also found a apparently unoptimized BIOS setting, something I/O related for storage that I turned on.
-
Had to install a community apps update...took a couple of tries. THEN I was able to install Unraid Connect.
-
Put drive in Windows 10 machine. Chkdsk and the 'Tools' option under 'Properties' vai right click reported no isses. disk.cfg was readable just fine. Did a drag and drop backup of files. Couple of .notify files were unreadable but no big deal there (the bitrot plugin checker that always reports storj node files as 'corrupt' despite my efforts to exclude them...forget the name) ugh now have an error on server...interrupt at 0000:5819 on Dell R720xd
-
So what's the fix?
-
Weird, the browser shows the file is present and non zero but vi opens it with zero length.
-
mmm...so what to do about that? I have of course the previous backup but that was for a diff Unriad version and I have the drive assignments screenshot.
-
I have the backup from pre-6.9.2 (end of April backup) I just downloaded the backup from the 'corrupted' 6.11.5 (today, 6 Jun 2023) and that completed normally and quickly. So, to me it just looks like a temp glitch. How do I know if it's really corrupted or just went offline for a bit? Diagnostics attached. blacktower-diagnostics-20230606-1527.zip
-
Same. BTRFS NVME solo drive with a single VM on it says: "Unable to benchmark for the following reason * No mounted partitions were found. You will need to restart the DiskSpeed docker after making changes to mounted drives for changes to take effect." Been working with it all day so I know it has a fs.
-
This is in settings /mnt/user/BlackTowerMain/storj,/mnt/user/storjnode2 (second entry I just added) for folders, and *.db,*.v1,*.sj1,*.log,*.tmp,.storj*,.Recycle.Bin in Custom files. Storj nodes update so much (and are self healing probably) but I was still getting log lines such as BLAKE3 hash key mismatch, /mnt/disk3/BlackTowerMain/storj/storage/blobs/pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa/2q/ouw7yyys2wfigjx2vfmmns4if2naa77erhiudde3p6y2apqhaa.sj1 is corrupted (and LOTS of them!) Or am I missing some syntax/formatting? Basically, I really don't care about corruption in these directories at all. It's all storj slices so I doubt it'd even matter. The other nodes, I presume, would just heal it and I'd get a CRC/parity error etc.
-
I have a 2230 Kioxia with no heatsink on a PCIe card that's at 58C. No heatsink. I figure that's a reasonable temp. I set the warnings to 140/145F. 2600MB/s in an R720xd if anyone is interested in the future. Also it isn't a flat line in Diskspeed and isn't being used just yet, so there's a datapoint. 2728mb high and 2579 low so something like 8% variance?
-
Had a parity disk disable due a read error (forget the exact problem) but subsequent preclears are going fine. One completed, another almost completed, plan to read 3. Speaking of, is there a way to test R/W a particular sector say, 50 times? Thoughts on using it? Probably use it as a Chia drive but might press it back into service if it passes a bunch. Also: I've got a drive pushing 93,000 power on hours but only 110 start/stop counts. It's at a nice 35C now. WD20EARS.
-
Ugh. I tried it several times this way with a few variations thrown in and even used 'defaults write com.apple.systempreferences TMShowUnsupportedNetworkVolumes 1' Nada.
-
All I had to do was click the red 'X' by preclear on the Main tab and FORMAT is now orange. Not using it just yet, but looks good to go if/when needed.

-
I did 'Fix Preclear' on that tools page, and I'm running another preclear but 99.99% sure it wasn't interrupted last time. I also cleared all the preclear reports on that drive, but I suppose those are stored in appdata and not on the precleared drive. Hopefully a complete preclear will fix it, and why not run another one LOL.
-
Interesting, this is two disks: The second one has no filsesystem and neither does the top one. But one has a mount option greyed, and the other doesn't. All I've done is preclears so I wonder what I've done differently to the top one....confusing. Destructive mode is obv. enabled. After formatting second disk: So it's like sdi is in a limbo where it doesn't have a filesystem but also I never formatted it and the format button isn't avail.


-
Ah, that's probably it. All I did was a preclear.
-
Ok, what am I missing? 'Mount' is greyed out. All I want to do it mount/automount the unassigned disk. Not even share it. Just want to use it to play around with Chia mining. One thought: do I have to restart the array to get it to work?


-
Will be doing another one if the drive passes another preclear or two and the extended SMART test passes. I have a WD Red CMR NAS on order to replace it. Edit: Seagate Ironwolf NAS was a little cheaper and a little higher rated, review-wise.
-
I'm doing a preclear at the same time as an extended test, which should hammer this drive pretty well.








