




linenoise
Members
-
Joined
-
Last visited
Everything posted by linenoise
-
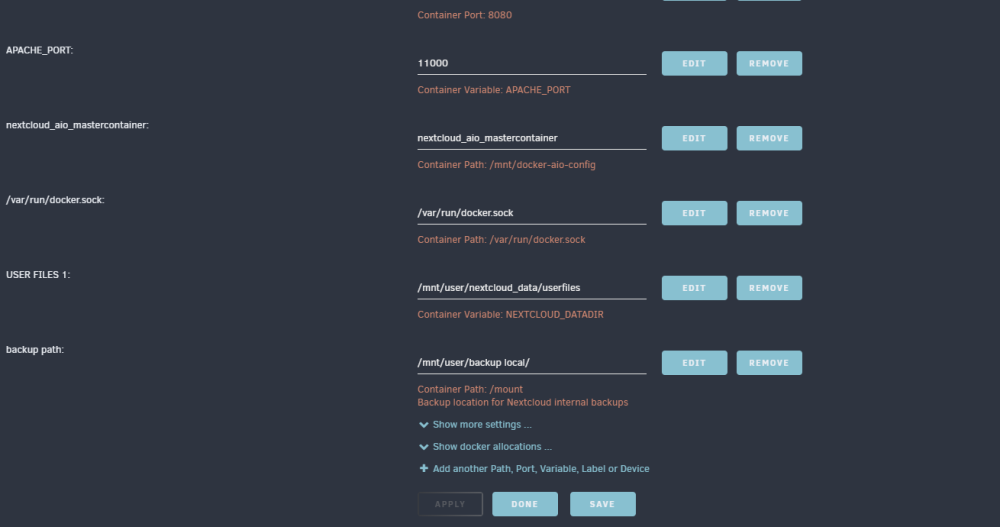
I found a container in the Appstore that looks very straight forward but there is no link to a support forum so I figured I will piggy back on this one. Looking at the installation docker settings in unraid I tried to move the backup directory to its own share /mnt/user/backup local/ but when I perform a backup it still saves the file in /mount in the root directory. I am not sure where the backups are physically stored, my guess is the cache drive but I wasn't able to find it using krusader when navigate to the drive directly. From the information on Nextcloud AIO GitHub page it says the you can backup to multiple locations but I have no idea on how to do this. My plan was to save 1 copy on the array then use rclone to back it up to a external usb drive and an offsite location. Second question I have is that I am using NGNx proxy manager for letsencrypt certs and forwarding port http to port 11000 which seems to be working fine but according to the Nextcloud AIO you need to forward port 80 to the Nextcloud to renew certificates. Since Unraid is using port 80 for the UI will there be any impact to the functioning of nextcloud AIO? Thrid question, if I am using NGINX proxy manager how do I forward ports 3478/TCP and 3478/UDP for the Talk container? I only see http (80) and https 9 (443) as options in nginx proxy manager. Do I have to forward those ports directly from my router? I would prefer to use a reverse proxy if this is possible. Thanks
-
I am not sure its because this has not been updated in a while but it no longer shows on the appstore. I was able to pull the image and have community applications build the template for me and it seems to work fine. Can you place a more official copy of this docker back? Also the icon is also broken at the top of this post which I planned to link to for the docker that was created.
-
Has anyone got this to work? I am getting the following error. I followed the gethub instructions to get the cookies and create the cookies.txt file. What I am not clear on is how to enter the YTDL_OPTIONS in the unraid form. The instructions on the gethub page show for a docker compose file but I am unsure how to enter this in the unraid format. A screen shot of a working config like the one above would be great. It would also be helpful to see an example of multiple YTDL_OPTIONS such as subs, audio, etc. Have seen some example strings in this thread but am not sure how to enter it in the Key:, Value: format, unraid uses. Thanks

-
OK I went ahead and deleted the log file. This worked, I am assuming that the impact deleting the metadata file had was the files that it was confused about placed in a directory called "lost and found", but preliminary scan shows that all the files are there. Thanks for the quick and helpful response.
-
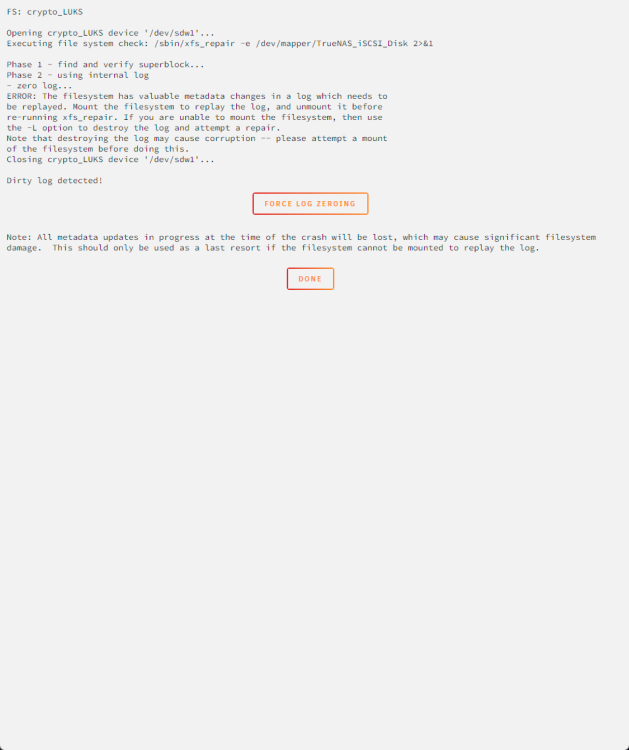
OK I ran the disk check using the checkmark. Got this result. I tried to mount the files system and got this error Is there any other way to run the log file, or do I have to wipe it and move on? If I do how much damge would this do, would it end up deleting files?
-
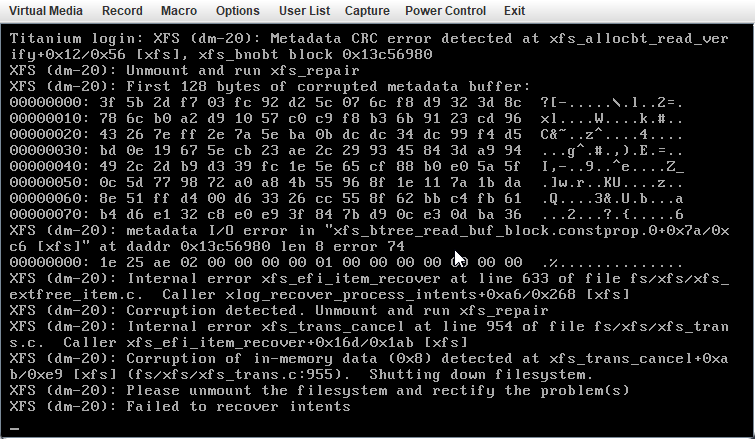
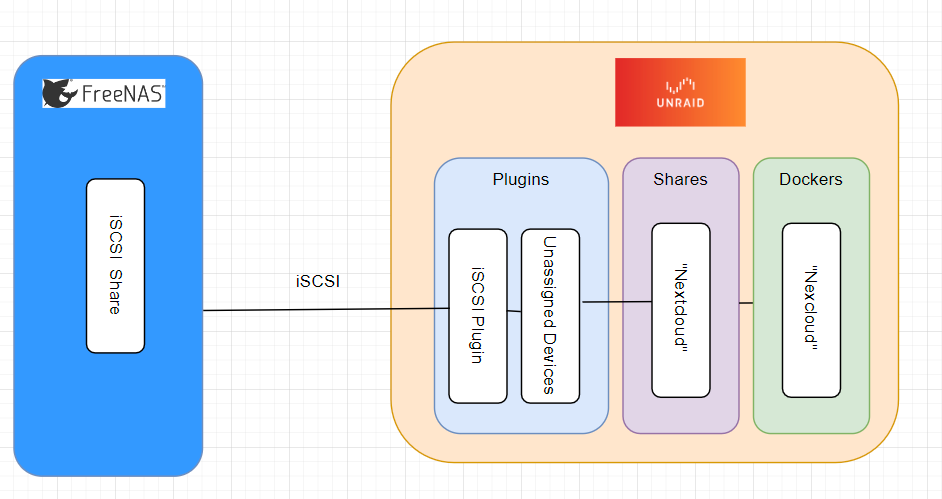
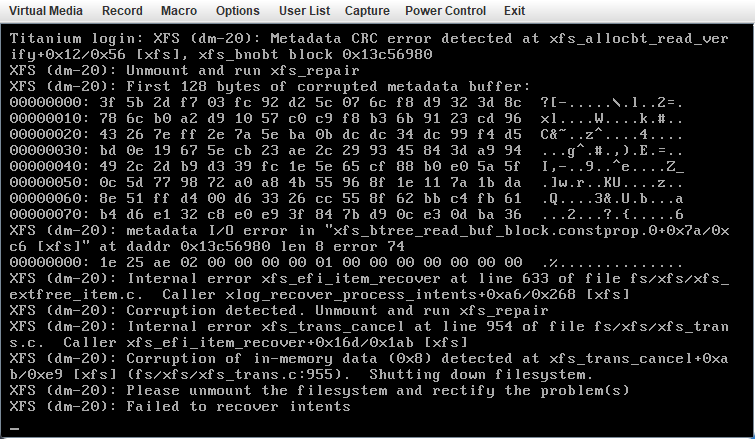
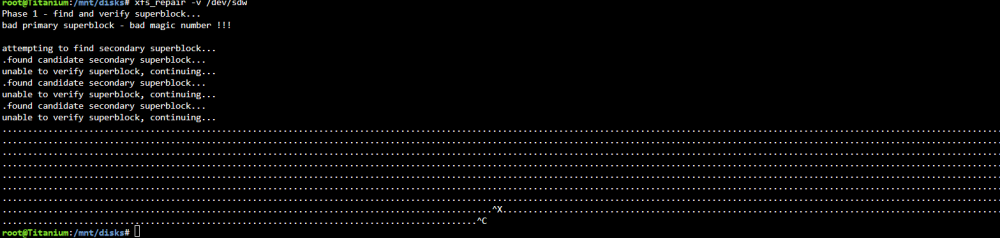
I hope this is the right place to post this. It looks like I have a corrupted XFS system that I need to repair. I have been running this setup without any issues for over a year. The catch is that the file system is located on an iSCSI attached file share accross 10Gig optic, that is mounted using unassigned devices. Here is a high level diagram of the setup. Unassigned device as it shows up in main menu (hope you can see it) I cant mount the drive under unassigned devices. This is the error I get when I mount the array with unassigned devices for the iSCSI drive. Then it reverts back to unmounted The drive shows up as dev\sdw so I THINK? the iSCSI interface is working correctly, but this could be cashed from when it was working. I am not too experienced with iSCSI. I didn't see a way from the GUI to do an xfs_repair, so I tried from the command line. This is what I get, the result is that xfs_repair tries to verify superblock and I get "............" continuously until I ctl^c to break out. Before you ask why I am doing this. 1. I like the docker for nextcloud and the docker system in general in unraid better then freeNAS jails and plugins. 2. the idea was to use the docker in unraid then take advantage of the ZFS files system in freeNAS for better error protection and speed. Not sure how the speed aspect turned out since freeNAS array is ZFS but when it was connected to unraid the share was formatted XFS, I think that's how it works. To be honest it was hacked this together using several different tutorials and trial and error.. Anyway I didn't do any speed tests but it didn't feel like it was an improvement in speed over unraid. Yes I am using a 10gb interface between freenas<->Unraid<->Client computer. I am not sure if it is even using ZFS since it is mounted using XFS. 3. Once I get access to the data, I plan to just run nextcloud on freeNAS since this seems to be more headache then its worth.

-
I tried the command hdparm -w 1 /dev/sdm but it didn't work, there is a slight typo, you have to remove the space between the W and 1 . The command should be. hdparm -W1 /dev/sdm I found a great resource for hdparm commands here with detailed descriptions and when its best to turn disk cash on and off. https://www.linux-magazine.com/Online/Features/Tune-Your-Hard-Disk-with-hdparm
-
Yes drive 14 was offline when I formatted it trying to fix the xfs_corruption. Thanks @JorgeB this was extremely helpful might want to pin it for future reference I didn't see the dm-n mentioned in the other xfs_repair thread on here or @SpaceInvaderOne excellent youtube video on xfs repair. For completeness I ran xfl_repair from the GUI and below are the results, this appears to have fixed the problem. Phase 1 - find and verify superblock... - block cache size set to 6175816 entries Phase 2 - using internal log - zero log... zero_log: head block 194465 tail block 194465 - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 bad CRC for inode 540099641 bad CRC for inode 540099641, will rewrite Bad atime nsec 2223570943 on inode 540099641, resetting to zero cleared inode 540099641 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 2 - agno = 1 - agno = 3 clearing reflink flag on inode 671443 clearing reflink flag on inode 1611822151 clearing reflink flag on inode 671446 clearing reflink flag on inode 671454 clearing reflink flag on inode 537782798 clearing reflink flag on inode 537782803 clearing reflink flag on inode 1075407107 clearing reflink flag on inode 1611822153 clearing reflink flag on inode 1611822597 clearing reflink flag on inode 1075407108 clearing reflink flag on inode 1075407111 clearing reflink flag on inode 537782807 clearing reflink flag on inode 1611822609 clearing reflink flag on inode 537782808 clearing reflink flag on inode 1611822610 clearing reflink flag on inode 672347 clearing reflink flag on inode 1075407115 clearing reflink flag on inode 537782809 clearing reflink flag on inode 1611822611 clearing reflink flag on inode 672365 clearing reflink flag on inode 1611822643 clearing reflink flag on inode 1611953539 clearing reflink flag on inode 1611953540 clearing reflink flag on inode 1611953543 clearing reflink flag on inode 1611953544 clearing reflink flag on inode 1079722387 clearing reflink flag on inode 1079722388 clearing reflink flag on inode 1079723377 clearing reflink flag on inode 1079723380 clearing reflink flag on inode 598095808 clearing reflink flag on inode 1080759596 clearing reflink flag on inode 1080759597 clearing reflink flag on inode 598095809 clearing reflink flag on inode 598095810 clearing reflink flag on inode 598095811 clearing reflink flag on inode 598114240 clearing reflink flag on inode 598114242 clearing reflink flag on inode 598114243 clearing reflink flag on inode 598114244 clearing reflink flag on inode 598114246 clearing reflink flag on inode 598114247 clearing reflink flag on inode 598114263 clearing reflink flag on inode 598114264 clearing reflink flag on inode 598114265 clearing reflink flag on inode 598114266 clearing reflink flag on inode 598114267 clearing reflink flag on inode 598114268 clearing reflink flag on inode 598114269 clearing reflink flag on inode 598114270 clearing reflink flag on inode 598114271 clearing reflink flag on inode 598114272 clearing reflink flag on inode 598114273 clearing reflink flag on inode 598114274 clearing reflink flag on inode 598114275 clearing reflink flag on inode 598114276 clearing reflink flag on inode 598114277 clearing reflink flag on inode 598114278 clearing reflink flag on inode 598114279 clearing reflink flag on inode 598114280 clearing reflink flag on inode 598114281 clearing reflink flag on inode 598114282 clearing reflink flag on inode 598114284 clearing reflink flag on inode 598114285 clearing reflink flag on inode 598114286 clearing reflink flag on inode 598114287 clearing reflink flag on inode 598114288 clearing reflink flag on inode 598114289 clearing reflink flag on inode 598114290 clearing reflink flag on inode 1088114259 clearing reflink flag on inode 598114292 clearing reflink flag on inode 598114293 clearing reflink flag on inode 1088114271 clearing reflink flag on inode 598114294 clearing reflink flag on inode 598114295 clearing reflink flag on inode 598114296 clearing reflink flag on inode 598114298 clearing reflink flag on inode 598114299 clearing reflink flag on inode 598114300 clearing reflink flag on inode 598114301 clearing reflink flag on inode 598115714 clearing reflink flag on inode 598115715 clearing reflink flag on inode 598115716 clearing reflink flag on inode 598115717 clearing reflink flag on inode 598115718 clearing reflink flag on inode 598115719 clearing reflink flag on inode 598115721 clearing reflink flag on inode 598115723 clearing reflink flag on inode 598115728 clearing reflink flag on inode 598115730 clearing reflink flag on inode 598115733 clearing reflink flag on inode 598115734 clearing reflink flag on inode 598115739 clearing reflink flag on inode 598115740 clearing reflink flag on inode 598115742 clearing reflink flag on inode 598115744 clearing reflink flag on inode 598115745 clearing reflink flag on inode 598115747 clearing reflink flag on inode 598115749 clearing reflink flag on inode 598115750 clearing reflink flag on inode 598115751 clearing reflink flag on inode 598115753 clearing reflink flag on inode 598115756 clearing reflink flag on inode 598115757 clearing reflink flag on inode 598115759 clearing reflink flag on inode 598115763 clearing reflink flag on inode 598115765 clearing reflink flag on inode 598115766 clearing reflink flag on inode 598115767 clearing reflink flag on inode 598115770 clearing reflink flag on inode 598115771 clearing reflink flag on inode 598115772 clearing reflink flag on inode 598115773 clearing reflink flag on inode 598115774 clearing reflink flag on inode 598115776 clearing reflink flag on inode 598115777 clearing reflink flag on inode 598115778 clearing reflink flag on inode 598115779 clearing reflink flag on inode 598115780 clearing reflink flag on inode 598115781 clearing reflink flag on inode 598115782 clearing reflink flag on inode 598115783 clearing reflink flag on inode 598115784 clearing reflink flag on inode 598228417 clearing reflink flag on inode 598228418 clearing reflink flag on inode 598228420 clearing reflink flag on inode 598343178 clearing reflink flag on inode 598576950 clearing reflink flag on inode 598576955 clearing reflink flag on inode 598580393 clearing reflink flag on inode 598591356 Phase 5 - rebuild AG headers and trees... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... XFS_REPAIR Summary Thu Feb 3 10:02:15 2022 Phase Start End Duration Phase 1: 02/03 10:02:12 02/03 10:02:12 Phase 2: 02/03 10:02:12 02/03 10:02:12 Phase 3: 02/03 10:02:12 02/03 10:02:13 1 second Phase 4: 02/03 10:02:13 02/03 10:02:14 1 second Phase 5: 02/03 10:02:14 02/03 10:02:14 Phase 6: 02/03 10:02:14 02/03 10:02:15 1 second Phase 7: 02/03 10:02:15 02/03 10:02:15 Total run time: 3 seconds done looks like that was the issue. Thanks @JorgeB and @Squid I am amazed how you guys find the time to develop, have a family and be so responsive and helpful for the community.
-
wow that is super not intuitive. How about DM-14 i am getting errors on DM-14, my guess is its the other ssd drive. I'm guessing the reason is that the dm-n, n = the drive number in the system as it is iterated through, guessing that SSD drives are counted after the array drives. When I removed 1 drive the cache went from DM-14 to DM-13. For future reference where in the diagnostic file is that information located?
-
Here is the diagnostic file. Thanks titanium-diagnostics-20220203-0905.zip
-
Ok I'm at a complete loss here on this XFS repair. I moved all data off of drive 14, took drive 14 offline then the xfs corrupted error went from dm-14 to dm-13. I performed a webgui repair on drive 13. Did not stop the error. Feb 3 06:42:17 Titanium kernel: XFS (dm-13): Unmount and run xfs_repair Feb 3 06:42:17 Titanium kernel: XFS (dm-13): First 128 bytes of corrupted metadata buffer: Feb 3 06:42:17 Titanium kernel: 00000000: 49 4e 41 ed 03 01 00 00 00 00 00 63 00 00 00 64 INA........c...d Feb 3 06:42:17 Titanium kernel: 00000010: 00 00 00 02 00 00 00 00 00 00 00 00 00 00 00 00 ................ Feb 3 06:42:17 Titanium kernel: 00000020: 98 8f 34 fb 84 88 ff ff 61 96 0a ae 34 dd db 6c ..4.....a...4..l Feb 3 06:42:17 Titanium kernel: 00000030: 61 96 0a ae 34 dd db 6c 00 00 00 00 00 00 00 1a a...4..l........ Feb 3 06:42:17 Titanium kernel: 00000040: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Feb 3 06:42:17 Titanium kernel: 00000050: 00 00 00 02 00 00 00 00 00 00 00 00 7b 94 ec 72 ............{..r Feb 3 06:42:17 Titanium kernel: 00000060: ff ff ff ff 9c 27 7a e1 00 00 00 00 00 00 00 06 .....'z......... Feb 3 06:42:17 Titanium kernel: 00000070: 00 00 00 b1 00 09 b6 1c 00 00 00 00 00 00 00 00 ................ Feb 3 06:42:17 Titanium kernel: XFS (dm-13): Metadata corruption detected at xfs_dinode_verify+0xa7/0x56c [xfs], inode 0x20314439 I formatted drive 14 by converting from xfs encrypted to xfs back to xfs encrypted. xfs encrypted -> format -> xfs -> format -> xfs encrypted. Then the corruption error came back to dm-14. Feb 3 07:22:35 Titanium kernel: XFS (dm-14): Unmount and run xfs_repair Feb 3 07:22:35 Titanium kernel: XFS (dm-14): First 128 bytes of corrupted metadata buffer: Feb 3 07:22:35 Titanium kernel: 00000000: 49 4e 41 ed 03 01 00 00 00 00 00 63 00 00 00 64 INA........c...d Feb 3 07:22:35 Titanium kernel: 00000010: 00 00 00 02 00 00 00 00 00 00 00 00 00 00 00 00 ................ Feb 3 07:22:35 Titanium kernel: 00000020: 98 8f 34 fb 84 88 ff ff 61 96 0a ae 34 dd db 6c ..4.....a...4..l Feb 3 07:22:35 Titanium kernel: 00000030: 61 96 0a ae 34 dd db 6c 00 00 00 00 00 00 00 1a a...4..l........ Feb 3 07:22:35 Titanium kernel: 00000040: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Feb 3 07:22:35 Titanium kernel: 00000050: 00 00 00 02 00 00 00 00 00 00 00 00 7b 94 ec 72 ............{..r Feb 3 07:22:35 Titanium kernel: 00000060: ff ff ff ff 9c 27 7a e1 00 00 00 00 00 00 00 06 .....'z......... Feb 3 07:22:35 Titanium kernel: 00000070: 00 00 00 b1 00 09 b6 1c 00 00 00 00 00 00 00 00 ................ stoped errors on dm-13 and moved back to dm-14 I then performed a Guix XFS-repair using -L to zero the log and then ran gui-xfs repair -V but I am still getting the error. I am beginning to think that dm-14 does not correlate to drive 14 that the corruption is somewhere else. If I run parity will it fix the corruption or will it just write the corruption to the parity drive?
-
Tried running the xfx repair from the gui several times using the -v flag no luck. I'm considering the Aliens 2 approach and nuke from orbit. Currently moving data off the drive and will reformat. Hopefully that will work.
-
I am still getting this error in my logs avery 15 sec or so. Feb 2 18:20:09 Titanium kernel: XFS (dm-14): Metadata corruption detected at xfs_dinode_verify+0xa7/0x56c [xfs], inode 0x20314439 dinode Feb 2 18:20:09 Titanium kernel: XFS (dm-14): Unmount and run xfs_repair Feb 2 18:20:09 Titanium kernel: XFS (dm-14): First 128 bytes of corrupted metadata buffer: Feb 2 18:20:09 Titanium kernel: 00000000: 49 4e 41 ed 03 01 00 00 00 00 00 63 00 00 00 64 INA........c...d Feb 2 18:20:09 Titanium kernel: 00000010: 00 00 00 02 00 00 00 00 00 00 00 00 00 00 00 00 ................ Feb 2 18:20:09 Titanium kernel: 00000020: 98 8f 34 fb 84 88 ff ff 61 96 0a ae 34 dd db 6c ..4.....a...4..l Feb 2 18:20:09 Titanium kernel: 00000030: 61 96 0a ae 34 dd db 6c 00 00 00 00 00 00 00 1a a...4..l........ Feb 2 18:20:09 Titanium kernel: 00000040: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Feb 2 18:20:09 Titanium kernel: 00000050: 00 00 00 02 00 00 00 00 00 00 00 00 7b 94 ec 72 ............{..r Feb 2 18:20:09 Titanium kernel: 00000060: ff ff ff ff 9c 27 7a e1 00 00 00 00 00 00 00 06 .....'z......... Feb 2 18:20:09 Titanium kernel: 00000070: 00 00 00 b1 00 09 b6 1c 00 00 00 00 00 00 00 00 ................ I ran this twice. Not sure if this was answered but is (dm-14) drive 14? I was expecting a sd something like sda, sdb, etc.
-
I ran with -lv flag This was the output. Phase 1 - find and verify superblock... - block cache size set to 6161160 entries Phase 2 - using internal log - zero log... zero_log: head block 1945344 tail block 1945344 - scan filesystem freespace and inode maps... clearing needsrepair flag and regenerating metadata - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 2 - agno = 1 - agno = 3 Phase 5 - rebuild AG headers and trees... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... Maximum metadata LSN (1:1945340) is ahead of log (1:2). Format log to cycle 4. XFS_REPAIR Summary Tue Feb 1 19:45:43 2022 Phase Start End Duration Phase 1: 02/01 19:42:47 02/01 19:42:47 Phase 2: 02/01 19:42:47 02/01 19:43:16 29 seconds Phase 3: 02/01 19:43:16 02/01 19:43:27 11 seconds Phase 4: 02/01 19:43:27 02/01 19:43:28 1 second Phase 5: 02/01 19:43:28 02/01 19:43:29 1 second Phase 6: 02/01 19:43:29 02/01 19:43:39 10 seconds Phase 7: 02/01 19:43:39 02/01 19:43:39 Total run time: 52 seconds done Yep, and you can sympathize with my poor wife that has to live with me.....
-
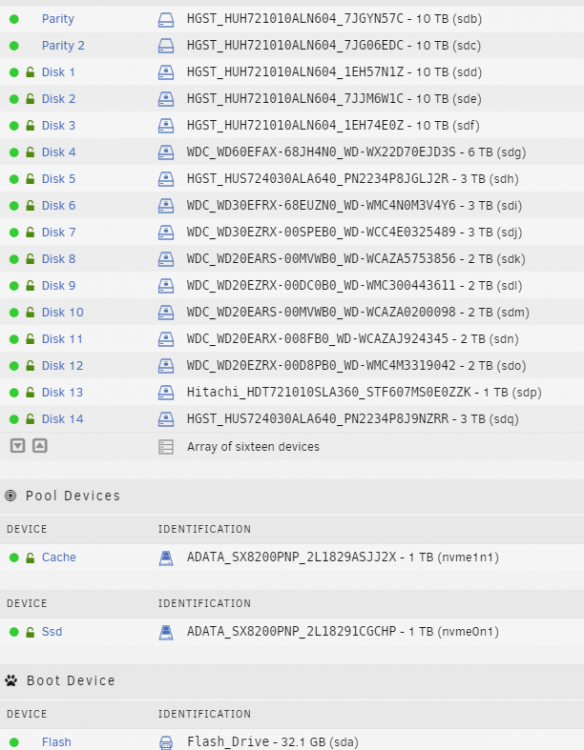
OK, I have to give Credit to @Squid for this same solution, I ignored him because I didn't think i had any custom IP addresses. When you posted the log with the name of my server all up in my face, I checked my dockers and sure enough my speed test_tracker docker was using a custom ip. So my sincere apologies to Mr. Squid, who nailed this early on and thanks @JorgeB for pointing it out again. I made the changes to the docker settings hopefully this will work. Not sure if should start a new thread but since this likely due to all of the kernel crashes I thought i'd post it here. I have some corrupted XFS files. I saw spaceinvader's excellent video on how to fix xfs corruption and this thread But I have no idea what drive dm-14 refers to, I was expecting something like sda or sdb. Using an educated guess I ran the xfs-repair from the unraid GUI on drive 14 but that didn't seem to fix the issue. Below is the error message in the logs and a list of my unraid drives and their Linux name. Feb 1 17:58:02 Titanium kernel: XFS (dm-14): Metadata corruption detected at xfs_dinode_verify+0xa7/0x56c [xfs], inode 0x20314439 dinode Feb 1 17:58:02 Titanium kernel: XFS (dm-14): Unmount and run xfs_repair Feb 1 17:58:02 Titanium kernel: XFS (dm-14): First 128 bytes of corrupted metadata buffer:
-
I ran a memtest and didn't see any issues. I think I might have a breakthrough, I enabled syslogs server and saved the syslogs to my cache drive according to the post here. This allowed me to catch some errors before they were lost due to reboot. From the logs looks like the preclear plugin was blowing up nginx web server if i'm reading the logs correctly. I didn't get a kernel panic but I was getting no response from any of the dockers or unraid interface. Not sure this would eventually cause a kernel panic type error but I removed the plugin and will see if unraid stabilizes. I attached the syslogs. syslog-10.0.0.11 - Copy.log.zip
-
Thanks for the quick and detailed response. I normally try to go with official containers when I can, but your point about Plex update strategy makes perfect sense. I was using LSIO because there docker had entries for nvidia card information. My Unraid server crashed again today. I do get temp warnings on my M.3 1tb SSD (ADATA_SX8200PNP_2L1829ASJJ2X SSD) running as my cache, up to around 42C, this happens normally when i am transcoding h264 to h265 when its doing a lot of read/writes to the cache drive. Could cache drive high temp cause unraid to crash?
-
Another note, I am running unraid 6.10.0-RC2 and found that heimdall was constantly generating log entries to the point where the log was at 12 Gigs in just a few days. From what I was reading on the forum it might have been caused by an enhanced app but when I removed heimdall ran cleanup appdata to remove the old config and ran a base install of heimdall it was still generating tons of log entries. Not sure this is a result of the RC, but I can see this quickly filling up the docker file and crashing docker. Had to uninstall heimdall for the time being. I attached a sample of the log file, already at 52mb after about 1 min of running. Not sure if this is related to our crashes but another data point. @Squid Can you expand on what the RC2 version of Unraid was supposed to fix? I am finding some of the dockers are having compatibility issues or versions I used on the stable versions are not showing in the appstore. Is there a filter to only show compatiable apps with the installed version in the appstore? thanks laravel.log.txt
-
Interesting I am also running 2 x SSD m.2 in pcie adapters.
-
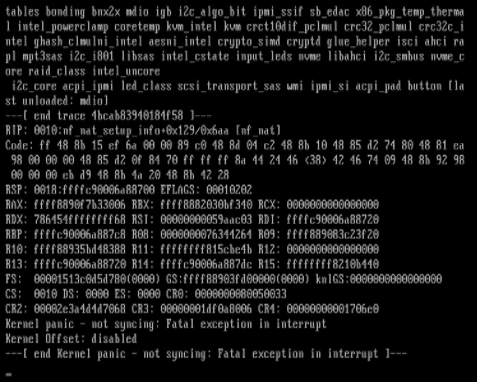
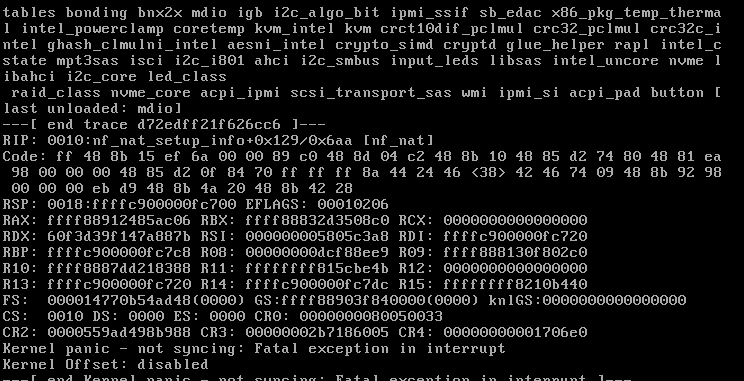
I'm back, I upgraded to the RC version of unraid, it broke my plex that was using NVIDA plugin and an NVIDA card to transcode. By break I bean the old container would crash when I tried to start it. I had to d/l a different docker, none of the ones on the app store, at least for the RC have the NVIDA transcode. This time around I was able to get 2 screen shots of errors. Also during the last 2 days 1 of my Hard drives died, running emulated currently waiting for a replacement drive. Should get her on Wednesday hopefully. I do have some old hard drives 10+ years of run time that are giving some reallocation errors, going to consolidate the data and replace them with a new drive. This is going to take a few days I have to rebuild the drive that completely died then consolidate the data off the other 3 drives before removing and replacing with the new drive. In the mean time I am going to remove the NVidia video card and see if the fixes anything.
-
No custom IP addresses on any of my dockers although I would love to implement them if they were ever stable, I am using all Network Type: Host. I am installing 6.10.rc2. I'll see if it will stabilize. PS thanks for the quick response and love your Sent via tag at the end.
-
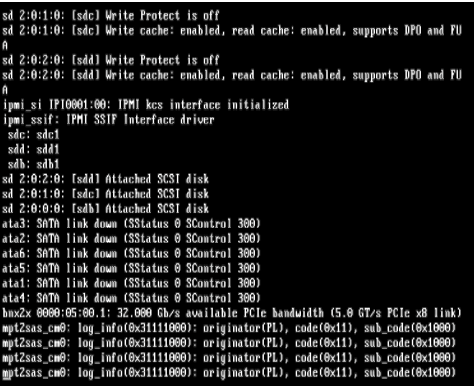
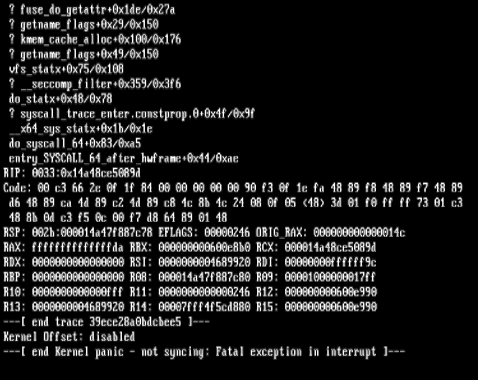
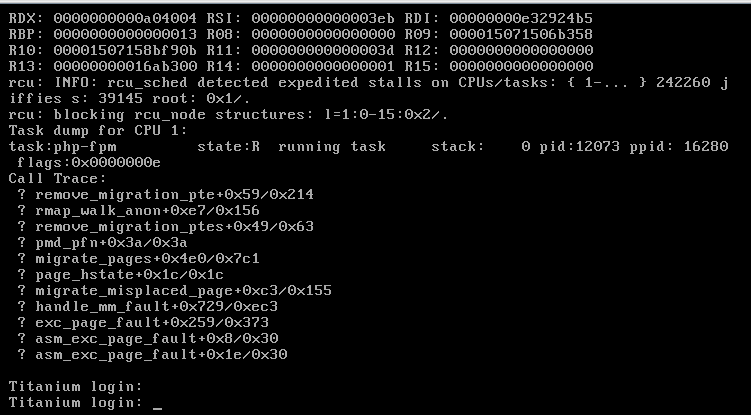
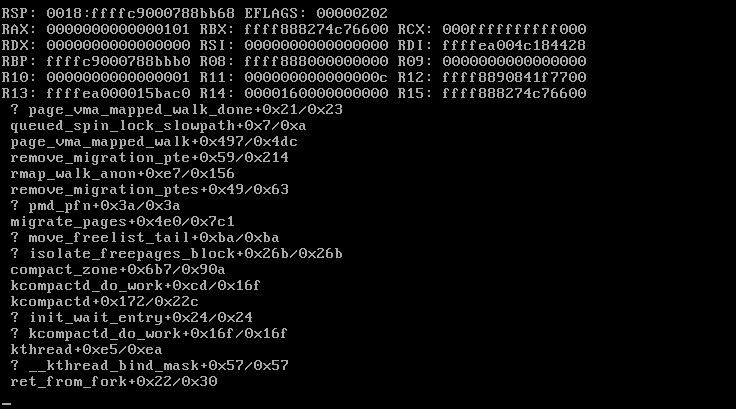
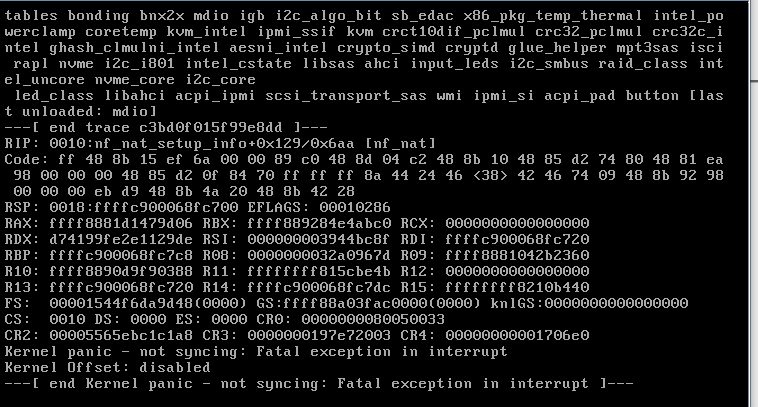
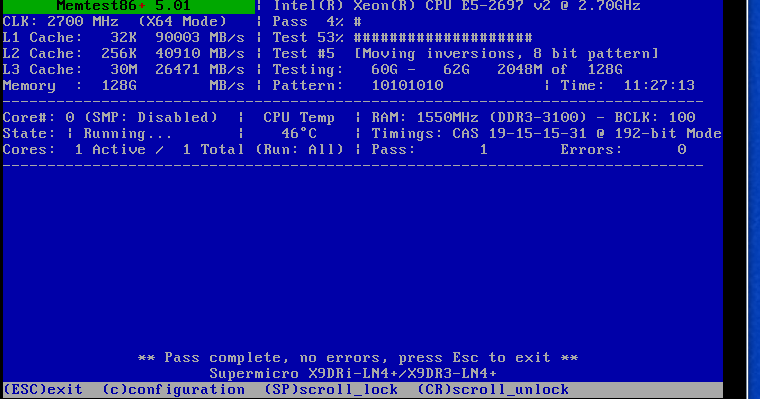
Background: I have been running Unraid for several years and it normally runs well. I have had issues with Kernel panics that stemmed from XFS corruption to issues with custom IP addresses. Tired of constantly rebooting due to these issues, I invested $2.5k in server grade equipment hoping that it will resolve many of these issues. Unfortunately I am still running into this issue. EDIT: I wanted to also note that I have performed a clean fresh install on the new hardware. Equipment: SuperMicro 6047R-E1R24N 24x LFF SuperStorage Server W/ X9DRI-LN4F+ 2 x Xeon CPU E5-2697 @ 2.70 GHz (48 cores total) 128 GiB DDR3 Multi-bit ECC memory Interface 1: 10GB Intel onboard 1 Gib interface 1 TB M.3 SSD (Cache) 1 TB M.3 SSD (VM/Downloads) 2 x 10TB parity Drives Assorted size drives (59 TB) Attached Files: Uploaded Diagnostic file titanium-diagnostics-20220111-1342.zip Screen Shots of several Kernel panic error messages: Here was a partial crash where the webUI was nonresponsive and nothing worked but the CLI Had to power cycle to resolve Another non kernel panic but system became unresponsive non of the dockers worked similar to above. With this said most of the crashes are Kernel panics. Memory check I performed a memory check using the the Mem tool option during unraid boot. I only did 1 pass as it took over 12 hours to perform My Thoughts what I have done: in the past I had kernel panic issues related to Nextcloud. (deactivated docker) I stopped all dockers execpt for (Plex, Sonarr, Radarr, SABNZB, Qbitorrent, Privoxy, Overseerr, prowlarr, speedtest-tracker- whoogle search) I do have some drives with errors and are failing some older WD Green drives, not sure that would cause a kernel panic. I do get SSD temp warnings from time to time but they recover fairly quickly. I am running an Nvida video card for plex transcoding it gave me issues with the bios when during the build requiring me to pull the Mobo battery and reset the bios to resolve whenever I install or pull the card. Hope to finally resolve this as I spent a ton of money building this. The old server is now running on truenas and is rock solid I love Unraid and would hate to switch. I think I got all of the information to help with troubleshooting this. thanks
-
Here is the link to my new server build thread about the physical ports and docker I mentioned above in case your looking.
-
I have had several issues with custom ip address with dockers causing kernal panics and crashing unraid. I am putting together a new unraid server and was hoping to get direction on how to best set up dockers and fully take advantage of several physical ethernet ports. Here is one of my threads demeonstrating the problem I was having and what inspired me to redesign my dockers. Ports I have available: PCIE Fiber card, with support for 2 x sfp ports, currently has 1 10gb optic supermicro server class motherboard (Supermicro X9DRi-LN4+/X9DR3-LN4+) 4 x 1 gb copper ethernet ports. Goals I would like to accomplish is: Use the 10gb for high bandwidth items such as file transfers, media streaming, multiple ip surveillance cameras (on separate VLAN) separate the unraid ip address from dockers, (to avoid the kernal panic issues mentioned above) Best way to use the available physical ethernet ports. use a custom docker network to allow communication between dockers. My thoughts, I am open to suggestions. reserve 1 x 1 gb ethernet port as a management port for unraid Use the 10 gb port to stream media dockers, transfer files use 1 x 1 gb port for custom docker network separate from unraid. Split the remaining 1 GB ports between dockers and VM Allow VM and Dockers access to VLAN Some additional questions: I think by having media dockers on the 10gb port and the other dockers on a separate 1gb port will break goal 4 Regardless of using additional physical ports, will installing and using portainer bypass the limitations of the built in unraid docker management? I do like the unraid docker UI for installing dockers but am not opposed to splitting dockers up between protainer and unraid to better use custom docker IP addresses. Open to suggestion on how to split up the available ports. Some notes about my network. I have a 10Gb switch that provides 10GB connections to my Main desktop computer, a TrueNAS server (same rack). I have multiple IP surveillance cameras on 1Gb ports on my 10GB switch that then save to Windows VM running blueIris on the Unraid server. I have several VLANs to isolate my network mostly for security. PF Sense firewall manages the firewall rules. I have a lightweight docker box (my terminology) where I run portaminer for some apps, secondary VPN, HA piehole (the other in unraid),, dashboard, vaultwarden, other dockers that are critical incase unraid goes down. Proxmox servers are not always on, they suck up lots of power and are loud (enterprise servers) Truenas for critical files, documents, family photos pictures, anything needing fast read/write, (files backed up on unraid) Unraid my heavy lifter has my media files(not backed up on freenas), tons of dockers, VMs, files that are not super critical or can be backed up on truenas, and don't require fast read/write speeds. See diagram below for an idea of my network does not include everything but the main stuff.
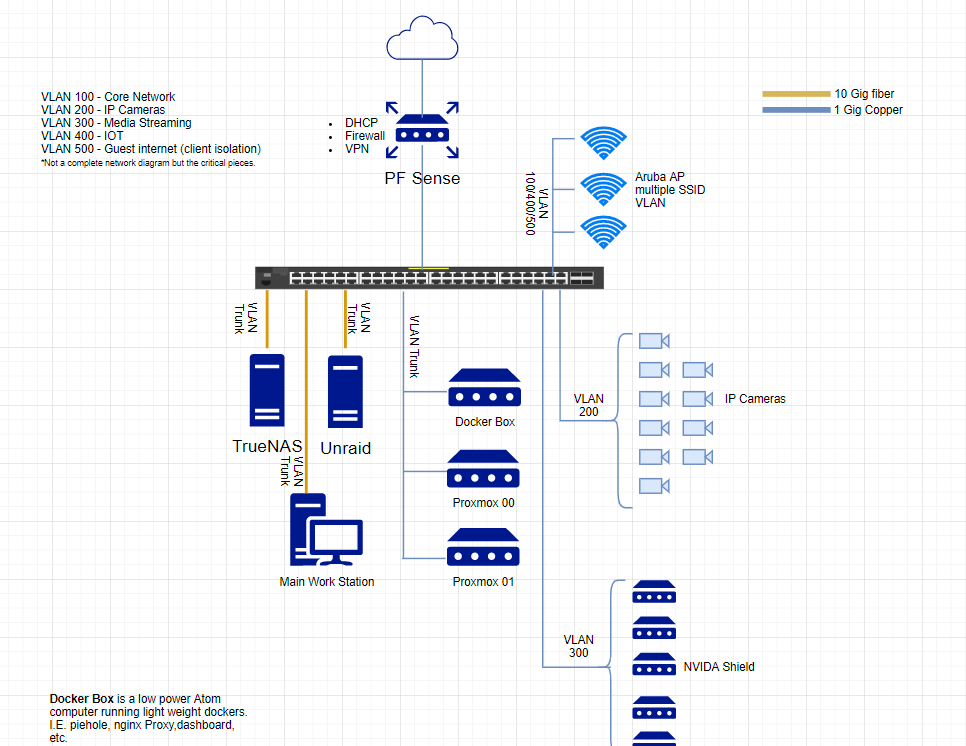
-
Closing the loop on this. It looks like the kernal panic was a result of using custom docker IP addresses for some dockers namely: Nginx reverse proxy manager, nextcloud, and PiHole. It has something to do with the way Unraid manages and bridges custom IP address on a single ethernet port. I got frustrated with trying to get it to work inside unraid and just moved the applications to another server that was running portainer. I am now in the process of building a new unraid server which will have 1 x 10gig fiber card, and 4 x 1gig copper ethernet ports. I'm getting ready to post the best way to set up docker to take advantage of the multiple ports. i.e., stream movies, share files, over the 10gb port, use 1 x gb port as an unraid management port, split the remaining 3 x 1 gb ports between dockers and VMs but not sure how to do this. Another question I have is, if I install portainer and use that for the docker manager will that bypass the limitations of the unraid built in docker? I am going to post this to a new thread. Will link the thread back here after I create it.



















