




Agent531C
Members
-
Joined
-
Last visited
Everything posted by Agent531C
-
I purchased an nvme drive a month ago to set up an appdata cache pool on, however it seems to be having issues. I first noticed it when the scheduled Appdata Backup ran last week. I woke up to see that it looked like the drive was unmounted/unreadable at some point during the process. I shut it down, and brought it back up only for the drive to work great until the next week when the appdata backup ran again. I thought it may be overheating, so I installed a heatsink last night, and tried to run it again overnight only to see that it had the same problem. I restarted again this morning, and saw my logs were full. I tried an extended smart test, but that seemed to cause the same problem as well. tower-diagnostics-20211116-0821.zip
-
I recommend using PhotoSync with Photoview. Photoview has the nicest UI/UX (imo), and the PhotoSync android app lets you do automatic uploads and configure directory structure in the app. I have it to auto sync photos in a Pictures/yyyy/mm file structure. If you want more advanced features, like object recognition, then Photoprism is the way to go. Its not pretty though, imo.
-
I came in here to bring up the same thing. Losing descriptions on the page itself is a major step backwards in terms of UX. If they can only allow them on certain 'categories', I think the 'New Apps' is the one it should be on. It'd give a quick overview of new applications for everyone when they show up, instead of apps people may have seen a bunch already.
-
For anyone that returns to this topic looking for advice, I ended up going back to an older version of Ubuntu and using an xrdp install script to get it all set up. It functions properly now, but Ubuntu 21.10 had issues with it.
-
I seem to be having an issue setting up the Code Server behind NGinx. I've set the 'Self SIgned Cert' to no, and all of my other cert path fields are blank as the FAQ suggests. When I try to log in from my domain, I can log in via the password then get this error: The workbench failed to connect to the server (Error: WebSocket close with status code 1006) These are some of the browser console outputs that happen: ERR WebSocket close with status code 1006: L@https://dev.domain.net/static/4cd55f94c0a72f05c18cea070e10b969996614d2/usr/lib/code-server/vendor/modules/code-oss-dev/out/vs/workbench/workbench.web.api.js:609:130012 <@https://dev.domain.net/static/4cd55f94c0a72f05c18cea070e10b969996614d2/usr/lib/code-sever/vendor/modules/code-oss-dev/out/vs/workbench/workbench.web.api.js:609:131742 log.ts:301:11 Uncaught (in promise) Error: WebSocket close with status code 1006 L remoteAuthorityResolver.ts:72 E browserSocketFactory.ts:148 Is there some extra config work that needs to be done in the advanced area of the Nginx Entry to make it work? There's no info in the logs, and Ive got websockets enabled in cloudflare, so that shouldn't be the source of the issue.
-
Any chance of an update to the UUD? I know its currently on v1.3, but I believe the official one is up to v1.6 now with lots of plex and other stat goodies included. Hope you're doing well
-
Since I moved to Intel, switched out my motherboard, and removed my Nvidia card, my syslog keeps filling up with this error: Sep 26 04:41:10 Tower kernel: pcieport 0000:00:1b.0: [12] Timeout Sep 26 04:41:10 Tower kernel: pcieport 0000:00:1b.0: AER: Corrected error received: 0000:00:1b.0 Sep 26 04:41:10 Tower kernel: pcieport 0000:00:1b.0: PCIe Bus Error: severity=Corrected, type=Data Link Layer, (Transmitter ID) Sep 26 04:41:10 Tower kernel: pcieport 0000:00:1b.0: device [8086:43c0] error status/mask=00001000/00002000 Sep 26 04:41:10 Tower kernel: pcieport 0000:00:1b.0: [12] Timeout Sep 26 04:41:10 Tower kernel: pcieport 0000:00:1b.0: AER: Corrected error received: 0000:00:1b.0 Sep 26 04:41:10 Tower kernel: pcieport 0000:00:1b.0: PCIe Bus Error: severity=Corrected, type=Data Link Layer, (Transmitter ID) Sep 26 04:41:10 Tower kernel: pcieport 0000:00:1b.0: device [8086:43c0] error status/mask=00001000/00002000 It writes the error over 100 times a second. Currently, I have no items installed in pcie slots - Only this sata expansion in an m.2 slot. It could possibly be a rogue container still using --runtime=nvidia, but I checked through all running, and nothing had that in the advanced options anymore tower-diagnostics-20210926-0859.zip
-
Now that its a few days later, Ive tried out the suggestions. I set the iommu to soft, and it didn't help. I can't disable AMD-V, as I run a vm that I work in, but I did disable the power option, and yet the gpu still drops off. I wouldnt think the hardware is causing the problem, since it isnt that old, but it is a mini board. I don't know if they have limits on power draw or anything of that sort set up.
-
I have been having problems with my plex container for ages now. It was originally causing problems a couple months ago, so I decided to nuke plex and rebuild from the ground up. It helped for a bit, but now the problems are back. If I shut down the plex container, it sends the signal for the shutdown script, and then never actually shuts down. Once this container is frozen, no kill or docker remove commands work to shut it down. It just hangs for good, and I need to do an unclean shutdown to get it 'fixed', until it breaks again within a few days. Heres the end of the plex container log: 2021-08-24 07:55:34,593 WARN received SIGTERM indicating exit request 2021-08-24 07:55:34,594 DEBG killing shutdown-script (pid 65) with signal SIGTERM 2021-08-24 07:55:34,594 INFO waiting for plexmediaserver, shutdown-script to die 2021-08-24 07:55:34,605 DEBG 'shutdown-script' stdout output: [info] Initialising shutdown of process(es) '^/usr/lib/plexmediaserver/Plex Media Server' ... 2021-08-24 07:55:37,608 INFO waiting for plexmediaserver, shutdown-script to die 2021-08-24 07:55:40,611 INFO waiting for plexmediaserver, shutdown-script to die 2021-08-24 07:55:43,614 INFO waiting for plexmediaserver, shutdown-script to die If I try to do anything related to stopping the process, the server has issues. Stopping the array doesn't work, restarting/shutdown buttons don't work, only a hard power off will work. I had to do it last night as well. I'm not sure if this behavior is a problem with the container, a problem with something inside plex going wrong, or a problem with unraid itself, but it only happens on this container (both plexpass and plex variant). I have had a problem with my GPU dropping out of view of Unraid, and still do, so maybe thats related. tower-diagnostics-20210826-0852.zip
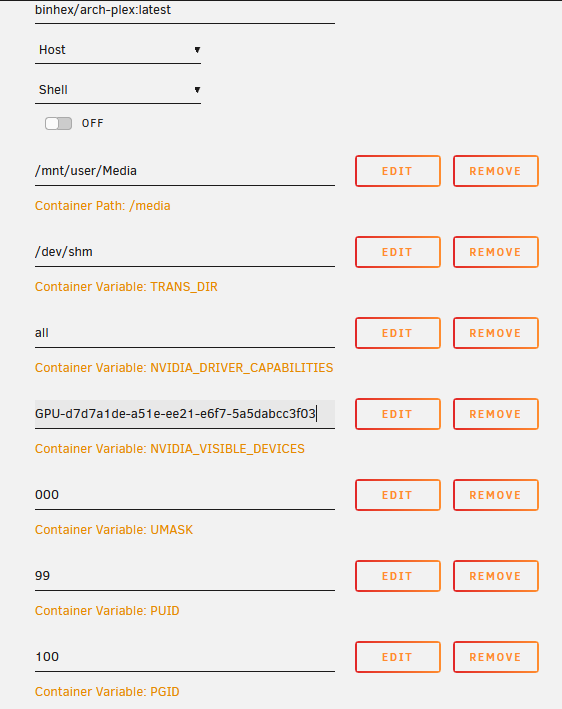
-
I've added the iommu bit to the config, so Ill give it a few days and see if it drops off again. My old 970 would drop off as well. I initially thought it was a graphics card problem, so It was incentive to replace it, but now that its happened on both, Im sure it something else. The BIOS option sounds like it could be a culprit as well.
-
After a few days, as usual, the graphics card has disappeared from use. You can see the containers with no devices, the tower itself with no devices, the plugin missing the device, and finally the device at the very least being seen by the OS with lspci. Ive also attached the diagnostics, now that they should have relevant info. tower-diagnostics-20210816-1231.zip
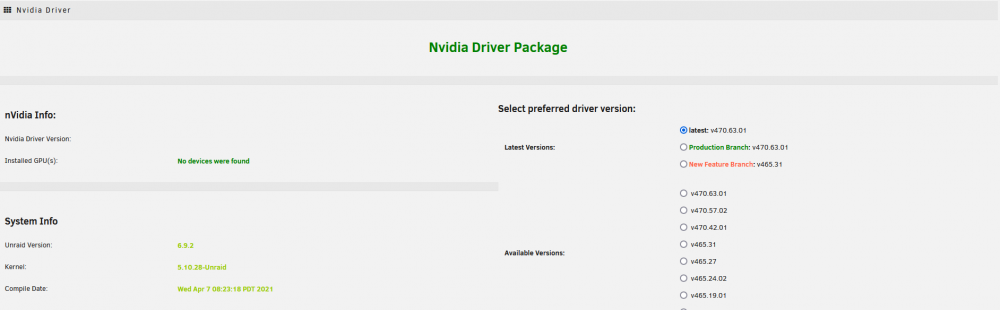
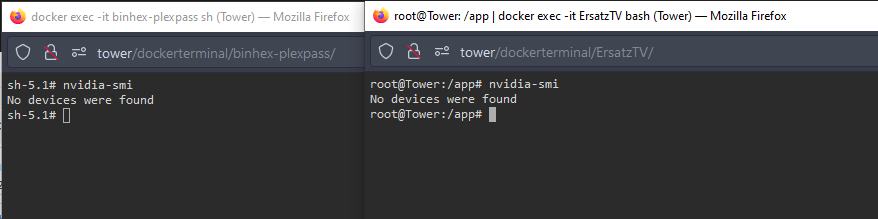
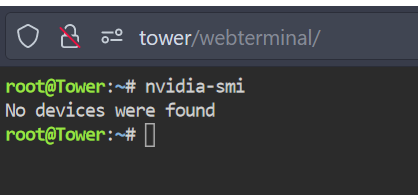

-
So, I actually ended up crashing my server by trying to run nvidia-smi on the unraid console inside a vm. Now that it's rebooted, its recognizing the graphics card, which Ive attached a couple images of. You can see that the server recognizes it. Now that it's reappeared, I'll have to wait for them to disappear for some pictures of it, but it basically stops being detected by the plugin. Since it isn't detected, the docker containers can no longer utilize it. (which I can show when it happens again). This isn't specific to this graphics card, as it happened with my old 970 too.
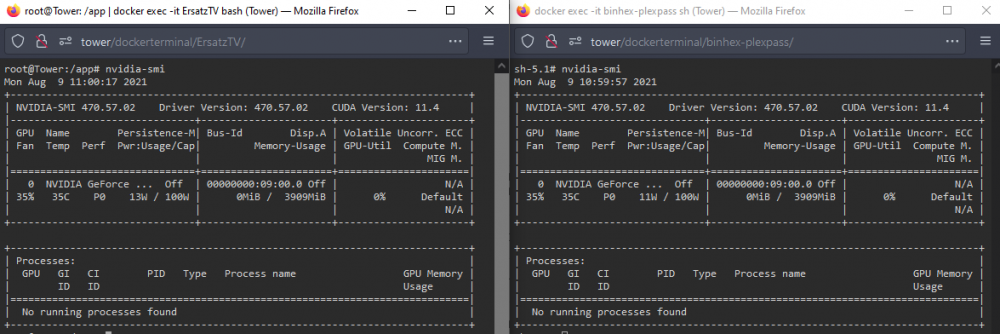

-
I have a 1650s that I use for transcoding in a plex docker and in an ErsatzTV docker (emulates DVR scheduling of plex media to the Live TV section). When I boot the server up and check the nvidia plugin, I see the card listed as well as its info and driver version. If I go into the console of both docker containers and run the nvidia-smi command, I can see the card listed and working. After a few days though, the card just disappears from the nvidia plugin, and the containers. If I run nvidia-smi in the unraid console, I still see the card listed in the devices, and if I run the lspci command, I see it listed in the hardware there as well. It is plugged into the first pcie slot. I have a sata adapter plugged into my m.2 slot, in order to add more drive capacity to the motherboard. My PSU is 650w, so it should be enough to power everything simultaneously. Im currently away from my tower, so I'll add any required images in a few hours when I have access to it again.
-
Ive found a couple of docker containers I want to set up (https://github.com/kelvie/web-brogue-docker, https://github.com/kelvie/dcss-web-docker), however I am completely lost on how to do it - especially since these seem kinda poorly put together and run off of an existing repository. Ive taken a look at Portainer to use docker-compose with, but kept having issues with that (probably my ignorance more than Portainer) and also took a look at This guide, but I wasn't able to make much work from it. If someone more competent could help, that would be awesome.
-
Dumb question, but what is the port forwarding configuration to set up in the router for this? Do I use the unraid box IP for the external, and the reserved network IP for the Local IP port forwarding info? For example, would it be set up like this, with the AMP internal ip setting being set to eth0? Local IP Address: 192.168.0.101 (the unraid local ip) Port: 25565 External (Internet) IP Address: 420.86.75.309 (The bridged docker ip) Port: 25565 Protocol: TCP
-
Unfortunately the router at my apartment was recently replaced, and the port forwarding feature is locked behind some Comcast BS. Ive been trying to set up a Minecraft server using the PortMiner spigot plugin, but I was curious if I needed to open more ports on the docker container for it to work. It uses UPnP to open the port on the router, but it seems to use a few different ports in the process. Using configuration: org.fourthline.cling.DefaultUpnpServiceConfiguration Creating Router: org.fourthline.cling.transport.RouterImpl Creating wildcard socket (for receiving multicast datagrams) on port: 1900 Joining multicast group: /xxx.xxx.xxx.xxx:1900 on network interface: eth0 Created server (for receiving TCP streams) on: /xxx.xxx.xxx.xxx:44443 Creating bound socket (for datagram input/output) on: /xxx.xxx.xxx.xxx <<< UPnP service started successfully [PortMinerPlugin]: Opened port 25565 The ports on line 3 and 5 are different each time its started. I can connect locally, which is never an issue, but everyone outside the network is getting a 'Connection Timed Out' failure.






