




Agent531C
Members
-
Joined
-
Last visited
Everything posted by Agent531C
-
Interesting, it seems I must have reinstalled at some point. I know I had removed when the updated one first released, but it was in my plugin list. I removed it, and it all works as expected now - Thanks!
-
There are two errors. One when the page first loads, and one after it resolves. Then the Error after it resolves is an Uncaught Type Error: Uncaught (in promise) TypeError: callback is not a function apply_folder http://tower/Docker:4121 waitForGlobal http://tower/Docker:3007 apply_folder http://tower/Docker:4074 anonymous http://tower/Docker line 3755 > Function:36 c http://tower/webGui/javascript/dynamix.js?v=1680052794:5 fireWith http://tower/webGui/javascript/dynamix.js?v=1680052794:5 l http://tower/webGui/javascript/dynamix.js?v=1680052794:5 o http://tower/webGui/javascript/dynamix.js?v=1680052794:5 send http://tower/webGui/javascript/dynamix.js?v=1680052794:5 ajax http://tower/webGui/javascript/dynamix.js?v=1680052794:5 i http://tower/webGui/javascript/dynamix.js?v=1680052794:5 anonymous http://tower/Docker line 3755 > Function:5 <anonymous> http://tower/Docker:1851 e http://tower/webGui/javascript/dynamix.js?v=1680052794:5 t http://tower/webGui/javascript/dynamix.js?v=1680052794:5 setTimeout handler*Deferred/then/l/< http://tower/webGui/javascript/dynamix.js?v=1680052794:5 c http://tower/webGui/javascript/dynamix.js?v=1680052794:5 fireWith http://tower/webGui/javascript/dynamix.js?v=1680052794:5 fire http://tower/webGui/javascript/dynamix.js?v=1680052794:5 c http://tower/webGui/javascript/dynamix.js?v=1680052794:5 fireWith http://tower/webGui/javascript/dynamix.js?v=1680052794:5 ready http://tower/webGui/javascript/dynamix.js?v=1680052794:5 $ http://tower/webGui/javascript/dynamix.js?v=1680052794:5 I do have some privacy extensions on my browser, such as Adblock. Has a recent update possibly made it incompatible with those? If I export the list of folders, there are no folders in the export, so something weird is definitely going on
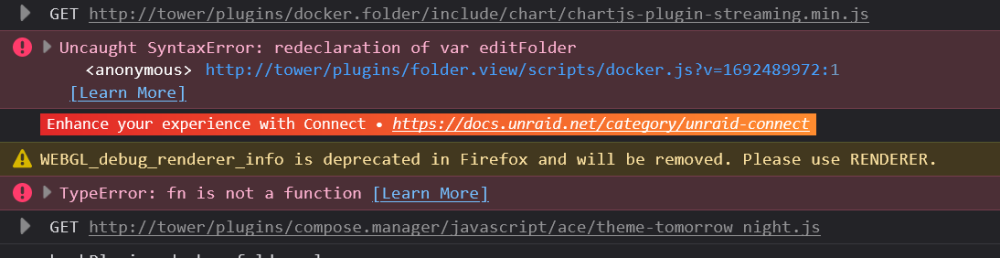
-
I wasn't able to get the log to download from the Docker tab, however I was able to get it from the Dashboard tab. If this doesn't help, Ill restart my server and see if that fixes some oddities happening in the docker tab debug-DASHBOARD-DOCKER.json
-
Ive got kind of a weird bug. My docker image became corrupt last night, so I had to delete my .img file and rebuild it by reinstalling all 130+ containers Im running on my machine. The Docker Tab doesn't sort them into folders after their reinstallation, however the Dashboard tab still has all of my existing folders with the apps in their correct folders. Im assuming that the config which stored the containers is indeed there, since the Dashboard can read it right, however Im not sure why the Docker Page isn't sorting containers into the right space now. Ideally, Id love to not re-sort 130+ containers into 18 new folders, so is there any logs/config info you need to take a look at the issue?
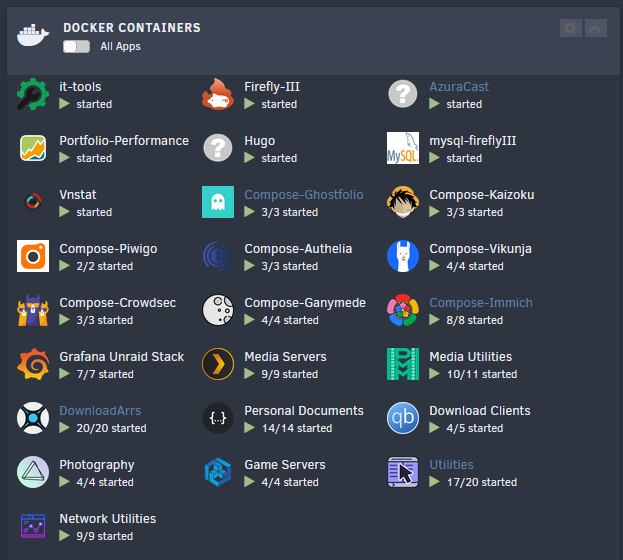
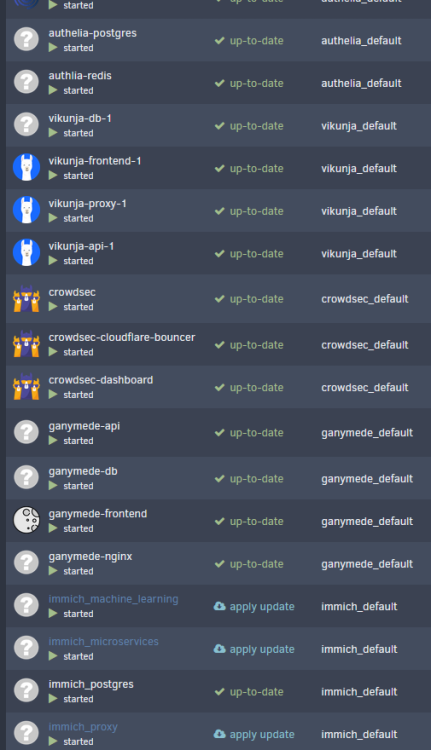
-
So, perhaps I don't quite understand how the 'threshold' value works, but based on my experience its my understanding that it checks the threshold of the total disk space used before it runs the mover command for each individual share. Ive noticed that once all of the big files are moved off of one share, other shares with large amounts of data don't get their data 'moved' because the threshold is no longer met. It'd be great if there were an option to 'force' the mover for specific shares when the mover triggers at that threshold point. If my understanding was right, Ideally it would check the threshold at the start and move each share sequentially once it triggers, instead of doing the threshold check before each individual share is run.
-
Perhaps Im missing something, but where exactly can we install the fork for use with RC6? The apps store seems to be out of date, as does the link posted at the top of the thread.
-
No native Docker-Compose option 🥲
-
Is this any different than the existing actual-server container?
-
I was rsyncing some files between drives, and saw in the file manager that some files had a Red font color, as opposed to the usual white font color other files in the same folder had. What exactly does the Red font mean?
-
Ended up doing that, renaming, and rebooting, but still no luck. I ended up just pulling the compose/.env files out of the config, and then deleting the folders and recreating them through the web gui with no spaces. Seems to have no issues so far
-
Ended up shutting down the array, renaming them, and then restarting the array, but it cause a weird docker crash where the manager wouldn't start. So I uninstalled the compose plugin, rebooted, and everything came back up fine. Added the Compose plugin again (with the renamed folders), and all of the ones in the originally attached image showed up fine, but none of the others are in the web ui, even though their containers are started. Should I try/have tried removing the containers completely, orphan images and all?
-
I have an odd problem, and perhaps its related to ShadowBerts problem, but I just noticed that some of my compose stacks are missing from the web UI, even though they are in the compose.manager/project folder and are still being autostarted when the array starts. I am on 6.11-rc3, and the 'invisible stacks' all start fine, but have no representation in the UI for pull/up/down/editing. The Web UI: The Folder:
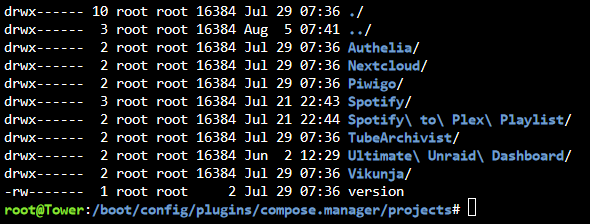
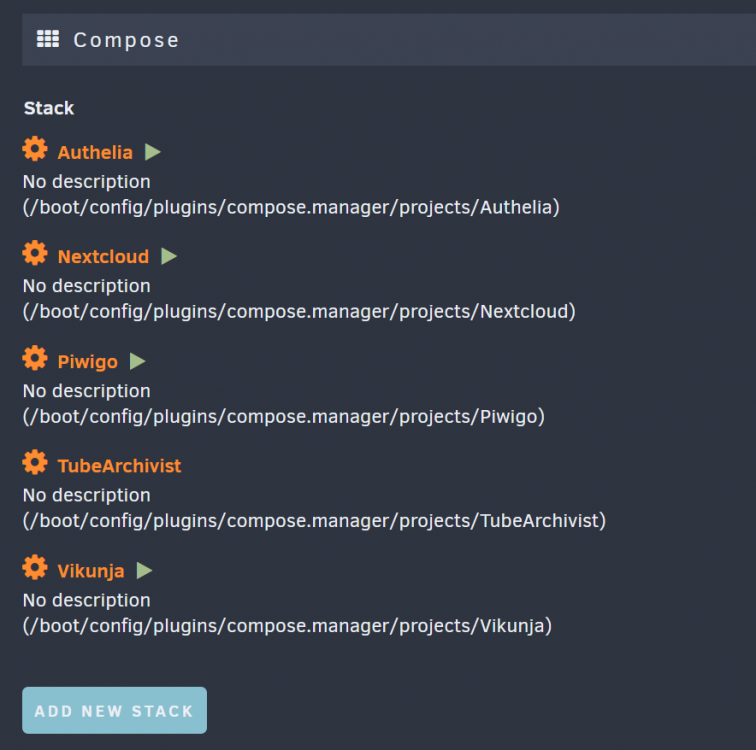
-
Do the 'share' specific move buttons follow the mover tuner settings when they are run manually and the 'Move Now button follows plug-in filters' is enabled? I have a downloads/incomplete folder filtered out with a text file, so files are never moved out while they are downloading and processing, but using the 'share' move button seems to try and move the incomplete files over regardless. I assumed it would follow the plugin filters, since the setting was turned on, but does only the 'Move Now' button on the 'Main' tab follow the rules?
-
Ive had a weird issue since updating from 6.9.2 where I have been unable to shut down my array, meaning every time I need to stop it, I have to hard reboot it. Docker looks like it shuts down properly, and as far as Im aware, I have no shell sessions active. (unless Ive been hacked and I havent recognized it). This applies to reboots as well as stopping the array I installed the 'Dynamixs Stop Shell' script hoping that may solve the issue, but unfortunately it did not, and Im still having issues shutting down the array. tower-diagnostics-20220627-0553.zip
-
Just popping in to ask about the Docker Volume vs File System problem Ive seen mentioned in the past. I switched to File System image recently, and noticed that my /storage mount is now missing, just like mentioned in other comments. Curious if a workaround has been found to work, or if I need to go back to a docker image for it to work properly again.
-
It looks like some recent changes in the radarr api makes it so the :latest varken tag doesn't work. Ive switched over fully to develop, so it may be worth it to migrate now instead of later. Im not sure why they haven't pushed a single update to the main repo in 2 years, but the develop one has been moving strong with a lot of new features (like Overseerr support)
-
Glad it worked out! I do wish it brought over some of the info it doesn't, but I only have about 9 months of tautulli data, so Im not super concerned about it. Can't wait for 1.7, and to see what it has in store.
-
I honestly didn't know that about compose-up. As for the first part, the actual webui doesn't pick up the changes for any label changes. If I set a label for an icon, and change it, it remains the first one even through reboots, deleting the cached image, and deleting/rebuilding the stack alltogether. Same goes for the 'webui' button on the popup. If I set a 'webui' label, and then go change it later, it remains whatever that first label was set on. I am on 6.10.2, but this very well could be a limetech issue with the way labels work at an OS level as opposed to the compose plugin.
-
I didn't notice any data duplication, corruption, or schema issues since my total plays broken down by device looked similar to what I had in tautulli. Because of the discrepancies I had noticed, I actually ended up running it, and then deleting all the data from my influx to run it again 'fresh' in case of data duplication. I only had a couple days worth, since I set the retention policy after seeing your post on it. My numbers looked similar on the run + backfill as they did when I cleared out all of my data and backfilled it, so I don't think it duplicates things, but I don't want to say for sure. I was definitely in the same boat of wanting all my data viewable in grafana, which is why I went looking. Worst comes to, you can always back up your DB and run it to see what happens. As for building everything into a single container, Im not too sure about that. It seems like the GUS container used a lot of custom scripts to build/grab config files out that I don't have experience with. Id love to learn, and know some apps (like AzuraCast) have 'monolith' containers that have 5 services running in one. Its definitely possible, but I'd need to look deeper at it.
-
Ive got some really weird behavior surrounding changing labels after setting them initially. If I set an icon/webui port option, and then change it later, the old one sticks for some reason. Restarting the server doesn't clear them out, deleting the stack and rebuilding it under a different name doesn't clear them out either. Also, a great feature would be a 'restart' button. With how the unraid gui loads, I spent a lot of time waiting for things to load while editing docker compose files. Id change one thing, save, load. Compose down, load. Compose up, load. Itd be nice to have a restart button which does down followed by up for when you're editing compose files and testing things out.
-
If you haven't figured it out, I was able to backfill all of my Tautulli data into influxdb using their backfill script on the 'develop' tag. Unfortunately, it does have some side effects with what seems like data structure changes, but it fills out enough that its usable. I've mainly noticed some fields act up, like 'Time', 'Plex Version', and 'Stream Status'. Sometimes the 'Location' would show as 'None - None' as well, but it usually got it correctly. To get started, change your varken container to the 'develop' tag. From there, open the console for it and run these commands: This moves the script to a location it can recognize the varken python import from mv /app/data/utilities/historical_tautulli_import.py /app From there, run the script with a few arguments: python3 /app/historical_tautulli_import.py -d '/config' -D 365 -d points to your appdata/varken.ini -D is the number of days to run it for That should backfill everything into your influxdb. I tried to run this on the 'latest' tag, but unfortunately the script is broken in it, and doesn't fill any data, so you have to use the develop tag.
-
Hey, I saw talk about turning the project into a single container to rule them all. Obviously testdasi has done it, so it is possible. I felt like docker-compose was more appropriate for the use case, so I wrote up a compose file and guide on how to set it up on Unraid using the Docker Compose Manager plugin: https://github.com/HStep20/Ultimate-Unraid-Dashboard-Guid I can't wait till they add native support, but this works great in the meantime.
-
I saw the discussion about installing proton via script, but it would be great to get it in the container natively. With the advent of the steam deck, it's really become a powerhouse. I assume this will transition to the Steam OS theyve been building for the deck, once it officially releases as 'Big Picture 2.0', or whatever they call it? --------- I am actually having some permission issues with the proton install script provided earlier, so Ill have to take a look at it. Not used to handling user's permissions/owners properly in linux. ------- After a bit more investigation, the permission thing seems to be a protonup problem: https://github.com/AUNaseef/protonup/issues/25 The Author of ProtonUp is MIA, so a new PyPi package was created in the meantime: protonup-ng The PR detailing the switch to Protonup-ng is here: https://github.com/AUNaseef/protonup/pull/26 You can fix your boot script running protonup by simply changing 'pip3 install protonup' to 'pip3 install protonup-ng'
-
Are you pointed to the 'log' or the 'logs' directory in NPM? I had the same issue pointed to the 'logs' folder, but switching it over to the NPM 'logs' folder fixed it. Almost seemed like it was recursively adding stuff from the 'log' folder
-
Glad someone else was noticing this too. I had it filling up my docker.img, and now it refuses to boot. Hopefully they push an update soon







