





Neldonado
Members
-
Joined
-
Last visited
Everything posted by Neldonado
-
rebooted/ shut down server and went to replace the sata power splitters, found one with a bent / smashed pin. Culprit? IMG_0534.heic
-
skynet-diagnostics-20230317-0744.zip
-
no progress 2hrs later. Edit: it's been over 24 hours with no progress... what should I do?
-
So my parity rebuilds have never taken this long... it's been hovering around 20% since this morning... any reason to worry?
-
Hmm ok. Were you able to tell what happened with my first diagnostics yesterday? What are the next steps if the cables I just replaced are fine?
-
And what if this pool is just one device?
-
I just replaced the breakout cables for this drive even though it didn't cause issues before. I will check connections again. Since parity rebuild is 25% complete should I let that finish before stopping/ checking cables? How do I go about running a scrub and what does that do?
-
Oops! accidentally attached the smart drive test twice. I attached my diagnostics. I went and moved some drives around and a different drive was throwing errors which made me think it was the cables. So I replaced both of the breakout cables. I saw no errors after this so I started the parity rebuild. Fast forward 7-8hrs and I see now one of my cache drives is giving me errors. I am a bit lost at this point. I included the diagnostics for right now as well. skynet-diagnostics-20230315-1907.zip skynet-diagnostics-20230316-0345.zip
-
SO! it's been almost a week and I just got a notification that same parity drive was disabled. I attached a short smart test of the disk a screen shot of errors, and my diagnostics. I haven't had any issues for over a week! All I did was maybe 30 minutes ago invoke the mover. ST10000NM0226_ZA290T3P0000C905MDCF_35000c500a6c8fc23-20230315-1905.txt skynet-smart-20230315-1905.zip
-
Connected the SSD's to onboard sata ports and rebuilt the data disk + parity, all is well! Thank you!
-
as in, remove the disabled data disk, and put in a new disk? I don't have an extra disk lying around, unless I used my cache drive to replace it. but then I would be moving data from my cache back to my emulated array.
-
I agree that I think it's connection related. Fact is I was in there moving drives around just hours before, and both of these drives were on different PSU's and different SAS breakout cables. I purchased a few replacement cables and will try to put the SSD's on the mobo or remove them entirely from the equation. Can you recommend the safest method for me to rebuild the parity and data disk?
-
I will try a new SAS breakout cable for that sds drive, or see if I have room to plug directly into the mobo. Do SSD's not play nice? Is there anything you can see that would tell you what caused these drives to disable in the first place? just loose cables? What's the safest way for me to go about rebuilding the contents assuming it's all there? thank you so much for all the time helping me.
-
OK, here is the 2nd drive and my diagnostics after starting the array! H7280A520SUN8.0T_001701PVZUGV_VLKVZUGV_35000cca260da2f70-20230308-0332.txt skynet-diagnostics-20230308-1134.zip
-
Here is the parity drive that failed. The data disk is still testing, and it looks like it's got another 4-5hrs until it's complete. ST10000NM0226_ZA290T3P0000C905MDCF_35000c500a6c8fc23-20230307-1812.txt
-
how long do the tests usually take? One of the drives has been at 100% for a few hours now but not complete. The second is at 67%... I started them both over 12hours ago. I also noticed this in the logs while waiting. The array is stopped.
-
I've posted my docs and extended tests for my drives. Both appear to be fine from what I can tell. I stopped my array after getting the diagnostics. I am not sure if leaving it on is a good idea until I know what's going on and how to fix. skynet-diagnostics-20230306-2345.zip ST10000NM0226_ZA290T3P0000C905MDCF_35000c500a6c8fc23-20230306-1532.txt H7280A520SUN8.0T_001701PVZUGV_VLKVZUGV_35000cca260da2f70-20230306-1532.txt
-
Which order of these should I go? Do tests, reboot, start array, post diags, and after that fix cache? Am I starting the array normally or in maintenance mode?
-
I will run a long smart test for both drives but I agree it looks more power/ connection related. How would I know if I fixed the problem by reseating all the drives? If I unassign, start, stop, and reassign the cache drives will I lose any data? how do I fix the disabled drives without losing any data (assuming smart tests come back ok)?
-
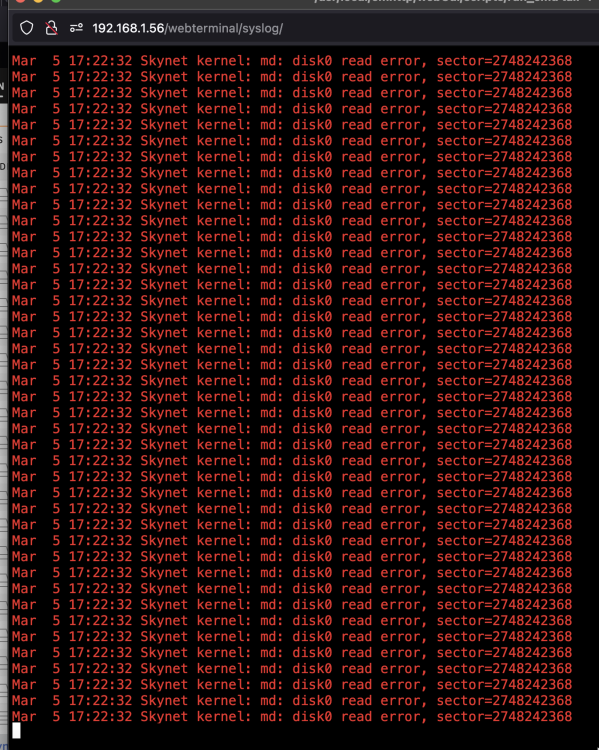
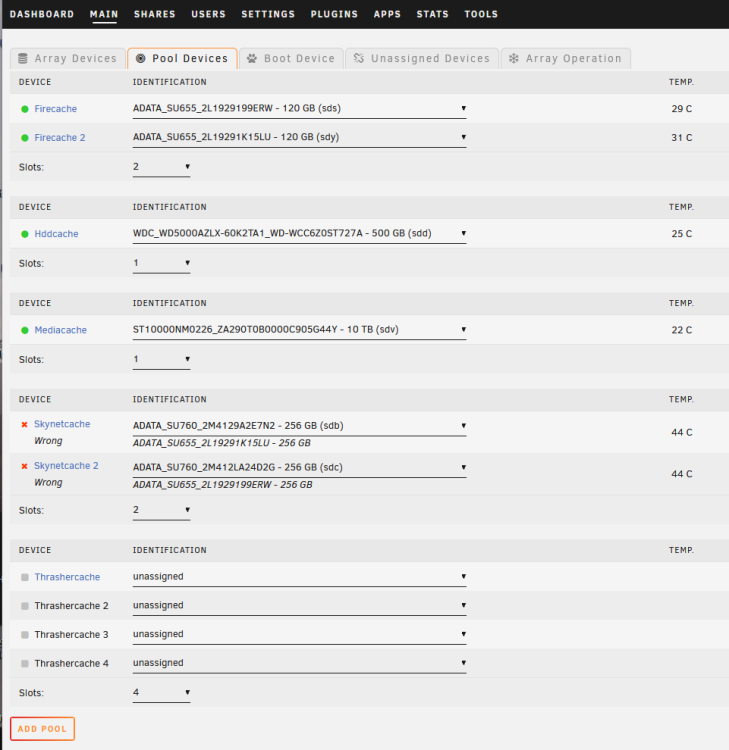
I started the day by moving my appdata, system, and domain folders off my cache pool onto the array so that I could upgrade to bigger cache drives. I moved the two 120gb ssd's into my DAS, and added two new 256gb ssds into my server in their place. I booted up, selected the new ssd's as the new disks for my appdata cache pool and hit the mover. Everything was fine. Then some time later my 2nd parity drive ended up being disabled. Mar 5 16:00:08 Skynet kernel: critical target error, dev sdy, sector 230862839 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Mar 5 16:00:08 Skynet kernel: BTRFS warning (device sdy1): failed to trim 1 device(s), last error -121 Mar 5 16:00:08 Skynet root: /etc/libvirt: 920.8 MiB (965480448 bytes) trimmed on /dev/loop3 Mar 5 16:00:08 Skynet root: /var/lib/docker: 21.8 GiB (23369732096 bytes) trimmed on /dev/loop2 Mar 5 16:00:08 Skynet root: /mnt/skynetcache: 339.6 GiB (364687364096 bytes) trimmed on /dev/sdb1 Mar 5 16:00:13 Skynet sSMTP[18250]: Creating SSL connection to host Mar 5 16:00:13 Skynet sSMTP[18250]: SSL connection using TLS_AES_256_GCM_SHA384 Mar 5 16:00:15 Skynet sSMTP[18250]: Sent mail for [email protected] (221 2.0.0 closing connection i8-20020aa79088000000b00594235980e4sm5017473pfa.181 - gsmtp) uid=0 username=root outbytes=468 Mar 5 16:10:24 Skynet webGUI: Successful login user root from 192.168.1.228 Mar 5 16:15:30 Skynet kernel: mpt2sas_cm0: log_info(0x31120101): originator(PL), code(0x12), sub_code(0x0101) Mar 5 16:15:30 Skynet kernel: mpt2sas_cm0: log_info(0x31120101): originator(PL), code(0x12), sub_code(0x0101) Mar 5 16:15:30 Skynet kernel: mpt2sas_cm0: log_info(0x31120101): originator(PL), code(0x12), sub_code(0x0101) Mar 5 16:15:30 Skynet kernel: mpt2sas_cm0: log_info(0x31120101): originator(PL), code(0x12), sub_code(0x0101) Mar 5 16:15:30 Skynet kernel: mpt2sas_cm0: log_info(0x31120101): originator(PL), code(0x12), sub_code(0x0101) Mar 5 16:15:30 Skynet kernel: mpt2sas_cm0: log_info(0x31120101): originator(PL), code(0x12), sub_code(0x0101) Mar 5 16:15:30 Skynet kernel: mpt2sas_cm0: log_info(0x31120101): originator(PL), code(0x12), sub_code(0x0101) Mar 5 16:15:30 Skynet kernel: mpt2sas_cm0: log_info(0x31120101): originator(PL), code(0x12), sub_code(0x0101) Mar 5 16:15:30 Skynet kernel: mpt2sas_cm0: log_info(0x31120101): originator(PL), code(0x12), sub_code(0x0101) Mar 5 16:15:30 Skynet kernel: mpt2sas_cm0: log_info(0x31120101): originator(PL), code(0x12), sub_code(0x0101) Mar 5 16:15:30 Skynet kernel: mpt2sas_cm0: log_info(0x31120101): originator(PL), code(0x12), sub_code(0x0101) Mar 5 16:15:30 Skynet kernel: mpt2sas_cm0: log_info(0x31120101): originator(PL), code(0x12), sub_code(0x0101) Mar 5 16:15:30 Skynet kernel: mpt2sas_cm0: log_info(0x31120101): originator(PL), code(0x12), sub_code(0x0101) Mar 5 16:15:30 Skynet kernel: mpt2sas_cm0: log_info(0x31120101): originator(PL), code(0x12), sub_code(0x0101) Mar 5 16:15:30 Skynet kernel: sd 15:0:17:0: device_block, handle(0x001c) Mar 5 16:15:30 Skynet kernel: sd 15:0:18:0: device_block, handle(0x001d) Mar 5 16:15:30 Skynet kernel: sd 15:0:17:0: [sdu] tag#3035 UNKNOWN(0x2003) Result: hostbyte=0x0e driverbyte=DRIVER_OK cmd_age=0s Mar 5 16:15:30 Skynet kernel: sd 15:0:17:0: [sdu] tag#3035 CDB: opcode=0x2a 2a 00 0f 6d 59 e5 00 00 03 00 Mar 5 16:15:30 Skynet kernel: I/O error, dev sdu, sector 2070597416 op 0x1:(WRITE) flags 0x0 phys_seg 3 prio class 0 Mar 5 16:15:30 Skynet kernel: md: disk29 write error, sector=2070597352 Mar 5 16:15:30 Skynet kernel: md: disk29 write error, sector=2070597360 Mar 5 16:15:30 Skynet kernel: md: disk29 write error, sector=2070597368 Mar 5 16:15:30 Skynet kernel: sd 15:0:17:0: [sdu] tag#3034 UNKNOWN(0x2003) Result: hostbyte=0x0e driverbyte=DRIVER_OK cmd_age=0s Mar 5 16:15:30 Skynet kernel: sd 15:0:17:0: [sdu] tag#3034 CDB: opcode=0x2a 2a 00 00 5d c4 30 00 00 04 00 Mar 5 16:15:30 Skynet kernel: I/O error, dev sdu, sector 49160576 op 0x1:(WRITE) flags 0x0 phys_seg 4 prio class 0 Mar 5 16:15:30 Skynet kernel: md: disk29 write error, sector=49160512 Mar 5 16:15:30 Skynet kernel: md: disk29 write error, sector=49160520 Mar 5 16:15:30 Skynet kernel: md: disk29 write error, sector=49160528 Mar 5 16:15:30 Skynet kernel: md: disk29 write error, sector=49160536 Mar 5 16:15:31 Skynet kernel: sd 15:0:17:0: device_unblock and setting to running, handle(0x001c) Mar 5 16:15:31 Skynet kernel: sd 15:0:17:0: Power-on or device reset occurred Mar 5 16:15:31 Skynet kernel: sd 15:0:18:0: device_unblock and setting to running, handle(0x001d) Mar 5 16:15:31 Skynet kernel: sd 15:0:18:0: Power-on or device reset occurred Mar 5 16:15:33 Skynet flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Mar 5 16:21:04 Skynet rpc.mountd[6271]: v4.2 client detached: 0x6f4ca8e26404f5fe from "192.168.1.48:768" after seeing the logs I assumed I may have bumped a cable loose or something like that, so I stopped the array, shut it down, and reseated all the drives. I booted back up and was presented with no errors but the drive was still disabled. So I began to look up the process to re-enable the drive, and roughly 20-30 minutes later a data disk throws up an error and is disabled. I checked the logs and this is all I saw: so I panic and decide to stop the array and shut it down. The array stopped, or so I thought, and then I saw at the bottom it said Array Stopping•Sync filesystems... after around 20 minutes of it just completely locked up like this I did a hard shut down. I pulled both the server and das out and reseated every cable and even moved some drives around from the das to server and server to das just for more trouble shooting help. I booted everything back up and did a smart test on the drives (attached) ST1 is the parity drive, and H72 is the data disk. I also just noticed that my two new cache drives (that holds my appdata, domains, and system) are showing up as incorrect. I've uploaded my diagnostics... At this point I am totally lost at what I should be doing. I think I have two issues here, 1) the two disabled disks, and 2) the cache drives reporting as "wrong" when they are not. Any help is appreciated. skynet-diagnostics-20230306-0325.zip
-
any reason I couldn't map this to my appdata folder? I have a 2 ssd cache pool where nothing but my appdata sits. Wondering if that's a bad idea due to read/write or its fine?
-
How do you run the sync server? unraid?
-
I recently noticed my scanned documents are just sitting in the file queue. https://i.hah.rip/j2m.png I use a scanning app on my phone, and send them to a webdav that moves them to the consume folder. They are immediately picked up by paperless and but then they just sit in the queued state. I don't get any errors from the log, so I am a bit lost of where to even look? I am running this on unraid, from ghcr.io/paperless-ngx/paperless-ngx Here is my log after a fresh restart and you can see it see's the two documents in my folder. https://paste.hah.rip/?703a6fc41ea425aa#HHECEbTDQzwmHEAq1Hk9pEy8RgskBTgyHinYH5ygicNb
-
Hello! I am trying to upgrade my nextcloud versions and keep getting this error after typing docker exec -it nextcloud occ upgrade I get this error: root@Skynet:~# docker exec -it nextcloud occ upgrade Nextcloud or one of the apps require upgrade - only a limited number of commands are available You may use your browser or the occ upgrade command to do the upgrade Set log level to debug Updating database schema An unhandled exception has been thrown: Error: Class 'Doctrine\DBAL\Types\Types' not found in /config/www/nextcloud/core/Migrations/Version21000Date20210309185126.php:49 Stack trace: #0 /config/www/nextcloud/lib/private/DB/MigrationService.php(478): OC\Core\Migrations\Version21000Date20210309185126->changeSchema() #1 /config/www/nextcloud/lib/private/DB/MigrationService.php(414): OC\DB\MigrationService->executeStep() #2 /config/www/nextcloud/lib/private/Updater.php(298): OC\DB\MigrationService->migrate() #3 /config/www/nextcloud/lib/private/Updater.php(244): OC\Updater->doCoreUpgrade() #4 /config/www/nextcloud/lib/private/Updater.php(131): OC\Updater->doUpgrade() #5 /config/www/nextcloud/core/Command/Upgrade.php(257): OC\Updater->upgrade() #6 /config/www/nextcloud/3rdparty/symfony/console/Command/Command.php(255): OC\Core\Command\Upgrade->execute() #7 /config/www/nextcloud/3rdparty/symfony/console/Application.php(915): Symfony\Component\Console\Command\Command->run() #8 /config/www/nextcloud/3rdparty/symfony/console/Application.php(272): Symfony\Component\Console\Application->doRunCommand() #9 /config/www/nextcloud/3rdparty/symfony/console/Application.php(148): Symfony\Component\Console\Application->doRun() #10 /config/www/nextcloud/lib/private/Console/Application.php(214): Symfony\Component\Console\Application->run() #11 /config/www/nextcloud/console.php(99): OC\Console\Application->run() #12 /config/www/nextcloud/occ(11): require_once('/config/www/nex...') #13 {main}root@Skynet:~# I am not really sure what's going on. My nextcloud instance is kind of stuck in this limbo now and I can't find anyone with an issue similar to mine. Any help would be appreciated.
-
I reinstalled it and deleted all the files, it worked 100% for 3-4 hours and now some of my most recent clips are not working. It seems inconsistent with the ones I get errors with and the one's I don't. Only thing I can think is that I am using a cache with the video share.. would that affect anything?



