




wildfire305
Members
-
Joined
-
Last visited
Everything posted by wildfire305
-
Certainly the new integration of the VirtioFS is exciting. I upgraded to 6.11.1 with no problems. I got VirtioFS working on a windows 10 vm . I get an unexpected result - I can read all the data I want from the share, I can delete anything I want, I can create folders.....but I can't create files. I tried this on a BTRFS and XFS filesystem. The VM user is one of the approved users for those shares (although that is likely irrelevant because this would bypass all user permissions). Where would I look to start diagnosing this?
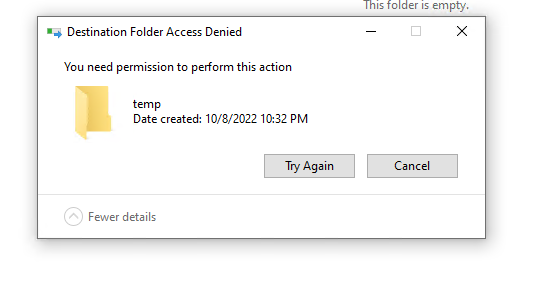
-
I have that same error, too. I don't know what it means, but it hasn't stopped anything from working, yet.
-
yes, but I used Unraid to create a share called backup first and then I pointed the container at it.
-
I created a share called Backup and I pointed my docker container to that so I could control access to that folder specifically. The urbackup_tmp_files is in my mnt/user/backup/ directory. That's probably why I haven't noticed it before.
-
That is probably in your /mnt/user/appdata/urbackup/config folder? It's probably used for temporary files needed by urbackup. Did you specify the location for the backups when installing the docker?
-
Yes, I use it for 6 windows computers and have tested/restored two of them. Interesting side note: all of the windows computers I run have veracrypt encrypted hard drives as the primary drive that urbackup backs up. When restoring, it is unencrypted until re-encrypting with veracrypt. But the important thing is that it still works!
-
Original array disk, no. Vibrating disk I was testing, yes
-
Do I...stop the array switch emulated disk to none, start array, stop array, put original disk back in that slot, start array and it will rebuild from parity
-
I was testing some 2TB and 3TB non-array disks in the same enclosure as my array disks. Docker and VMs were already disabled prior to testing. One of the non-array test disks started vibrating wildly and kicking udma crc errors left and right. Then, some array disks started building crc errors and one of them became disabled. I stopped all of my processes (badblocks on 5 disks) and tried to powerdown gracefully with the powerdown command. The system hung and could not be ping-ed. I waited 15 minutes and manually powered off everything. I removed the offending drive and promptly put two .22 caliber bullet holes into it for a quick, easy, and satisfying wipe before putting it in the trash. Now the server is restarted, and I'm testing the non-array disks again. The array came up with one disabled/emulated disk. I started it leaving the configuration alone as it said it would do a read test of all the other disks. I figured that would be a good thing and it continued gracefully with no weird format prompts. Questions/Options: Is it possible to get this disabled disk back in the array, or do I have to rebuild it onto itself? Do I have to stop the array to run an XFS filesystem check on the disabled disk? It won't mount read only because I assume the emulated disk is using its uuid. If I were successful at getting it back into the array (possibly using new config), would I need to rebuild/recheck the parity? Ideally, I would like to get this disk mounted somehow, copy it's contents to another disk, and then put it in the array letting the parity rebuild it. Someone helped me before with an XFS command that generated a new UUID (I found my previous post), But I know if I do that, I probably can't bring it back into the array. All the data is backed up...to B2. The disks I'm testing are for my onsite backup pool which I had to destroy the data to retest them. I got some larger disks and freed up slots in the server (12 total) So I could move my backup disks from esata/usb3 enclosures and put them into the main server box. Diagnostics attached for posterity. If y'all have any better paths than what I've thought of, I'm open to suggestions. cvg02-diagnostics-20220319-1817.zip
-
Unfortunately, no I didn't. I haven't had much free time to dig into it lately - started a new job in January and I'm still learning the ropes. I just tried it again and it did not succeed, but I didn't get an error in the log. I can confirm that the backups absolutely work awesome, even when the client system is using a veracrypt hard drive.
-
That's where I got to with it. I couldn't understand how it was seeing sr0 as sr0 still when I intentionally tried to map it to a different sr(x) for testing purposes. This docker works excellent with one drive. My server has one built-in (laptop style) dvd burner. I have a usb bluray burner. In order to rip blurays I have to use the makemkv docker or a vm or my w10 laptop. I could never get ripper to ignore sr0 and go for the external. Mapping sr5 (external burner) to sr0 caused it to try to read from both drives simultaneously. I've been dabbling with Linux since 1999 Redhat 5.2, but only really got stuck in firm last year so I'm just chalking it up to my own inexperience. I can follow complex directions, but I need more directions.
-
@rixAre you in the USA? I have a spare internal sata or external usb optical drive (choose one) I'd donate and ship to you. DM me if interested.
-
This happened again when I upgraded the firmware on my router this week.
-
Did you have success with this? I've tried various mappings with docker parameters and I got it to see the other drive, but the directory structure was garbage on output. I tried modding the .sh file and that still was a problem. I've kind of given up on multiple disks and just use something else for bluray (separate drive). @rixI think all of us need more specific instructions on how to get this to work with something other than sr0. Can you post an example of something like sr5/sg12 on the container syntax? I have tried with and without privileged, and I have used --device=/dev/sr5:/dev/sr0 \ --device=/dev/sg12:/dev/sg0 \ and --device=/dev/sr0:/dev/sr5 \ --device=/dev/sg0:/dev/sg12 \ and (I can't remember which one) one of them worked, but the output folder structure that led to the ripped files was all goofed.
-
I've been having some trouble with my unifi UDM router running out of ram and locking up since the December update. Strangely, if it reboots, sometimes it causes the unraid server to also reboot - dirty. I intentionally rebooted the router this morning because that temporarily solves the lockup issue for a few days. When I rebooted the router unraid kicked some errors into the log and also rebooted. Does this seem like a hardware or software issue? Logs attached, server description in signature. Below are some lines in the syslog that may not show up in diagnostics: cvg02-diagnostics-20220208-1503.zip
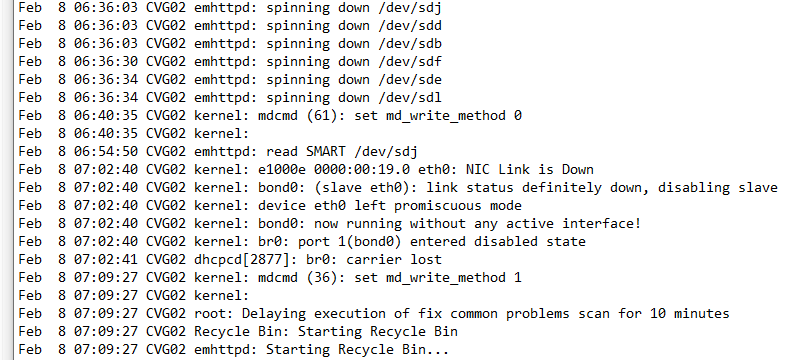
-
Worked like a charm. Thanks! I'm assuming that UUID was assigned to the array and I removed the disk from the array, the system was playing safe not letting the disk back in. Running a diff on it and the new disk 3 now for "peace of mind" comparison.
-
I found a clue: Jan 23 02:05:52 CVG02 kernel: XFS (sdl1): Filesystem has duplicate UUID d0ba1183-2aa6-432f-9ae6-1c029498de77 - can't mount I assume I need to generate a new UUID somehow since it was an array disk? Can anyone show me how to do that? Something like this: https://www.tecmint.com/change-uuid-of-partition-in-linux/ ?
-
I'm going to preface this by saying "I have no concern for data loss - I am backed up three ways." So please have no concern for my data. I came here to be educated on this topic. Storytime: I had a bad 8087 x 4 sata cable that caused a bunch of UDMA CRC errors with a disk. I diagnosed it by swapping the cable to another disk and saw it build some crc errors during a parity check. I pulled the CRC failed disk out of caution and started rebuilding the removed disk with a tested spare. My curiosity asked - "Hey I wonder if I can mount this pulled unraid disk in another computer if I had to recover data?" Sure enough, I plugged it into a Fedora VM on my laptop using a usb enclosure and it was seen immediately and automatically mounted. I tested my skills unmounting it, running xfs_repair to check it and so forth. I plugged it into an OMV 5 server and was able to mount it and read the directory structure just fine as well. Then I put it back in the unraid server and attempted to mount using unassigned devices - NO LOVE. Dropped into terminal and tried manually - unsuccessful - "error was wrong FS type". I tried again specifying -t xfs - still NO LOVE same error. I put it back in the Fedora VM and it works perfectly fine I can mount it all day long. I ran some par2 checks on the stored data and it was fine. I'm going to save the disk from further testing until its replacement is rebuilt in the server. Can anyone tell me why I can't get it to mount in unraid? I used "mount /dev/sdl1 /mnt/old3" and "mount -t xfs /dev/sdl1 /mnt/old3" and had no success - both times gave me the wrong filesystem error message.
-
I have a one disk pool that I am using for the DVR for my security cameras. I expect this disk to always be full as the security camera software is managing the use of the disk. So, I set the notifications for this pool to zero as specified by the popup help. Despite this, I am still receiving notifications that the disk is approaching full. Have I done something wrong or missed an additional setting, or is this a genuine bug? Please see attached screenshot and diagnostics (I know I have a paused parity check, I accidentally rebooted with a terminal session open). cvg02-diagnostics-20220109-1339.zip
-
https://www.pc-pitstop.com/scsat84xb If unfamiliar with serial attached storage, keep these two terms in mind SFF-8087 = internal 6GB/s connections, SFF-8088 = external 6GB/s connections. I also bought a dell perc h310 HBA raid controller flashed in IT mode (JBOD with no raid) from ebay (i would suggest buying a different model with external ports, I converted mine) I used the HBA controller, two sff-8087 cables to get to an sff-8087 to sff-8088 adapter pci slot (this made the h310 have two external sff-8088 ports) I then connected the 9 bay box with two SFF-8088 cables. When purchasing the box, I specified that I wanted it set up with SFF-8087 to 4x sata cables and 8088 to 8087 adapter. In the end I get one 6GB/s channel direct to each disk. The Dell hba is an 8x pcie card that provides 8 channels to the memory and cpu. My disk performance doing a parity check is almost 1GB/s spanned across five data and one parity. 180MB/s per disk Prior to that I had 2 port esata with a 4x pcie port multiplier card and two 4 disk boxes connected by esata - performance was 80MB/s per disk doing a parity check. The port multiplier card worked and was mostly reliable unless I put a seagate brand drive in the enclosure and didn't disable NCQ. Prior to that I had the same boxes connected USB 3.0 with 40MB/s per disk performance from my old stablebit drivepool windows server. In the last four years of upgrades, I have gained greater performance out of the same drives by changing my operating system and connection method. Let me know if you have any additional questions about the setup.
-
I converted everything to SAS using an enclosure from pc-pitstop. Then I was able to retire the mediasonic enclosures.
-
SANTA DELIVERED! I converted everything to an external SAS enclosure and while I now get around 160 MB/s on a parity check across six disks, it didn't resolve the issue with the disks not staying asleep. However, after doing some more digging, I used the inotifywait command to watch what was actually going on with the disks. Problems found: 1. I had mistakenly put a syslog server on the array instead of the ssd cache 2. I had configured all of the windows computers (eight) on the network to use file history (w10 built-in backup) to backup to the array. I had it landing on the cache, but I failed to realize that windows would compare existing files in the backup and it was waking the disks to do that. I moved those shares completely to cache - they were already being backed up to the cloud daily. 3. I re-configured a lot of daily server maintenance tasks to take place within the same two hour window. 4. I temporarily stopped all VM's and dockers and the automatic part of the file integrity plug-in. I'll see if I find more, but the point of this post was to mention the use of the inotifywait command allowed me to quickly and easily see what was going on. Syntax I used was: inotifywait -r -m /mnt/diskx Be patient, sometimes that command took a while (several minutes) to start.
-
I can confirm that the log webUI is working
-
All that being said, you could create a Linux virtual machine with a mapping to the array share that you want to backup and pass it to the urbackup server. Be careful you exclude your backup location or you'll create a loop.
-
Rsync can also be made to display all the desired statuses and send reports of the completed task with the proper syntax. You can send the output of the program to another program to do whatever you desire. Admittedly, I've not used it to send reports because I haven't had the time to dig that deep into the syntax. However, whenever I need to copy a bunch of files or sync two folders (my offline backup system) it's my go to tool and probably most of us here. It's a lot more powerful than cp and mv.




