




wildfire305
Members
-
Joined
-
Last visited
Everything posted by wildfire305
-
2021-12-04 17:08:28,933 DEBG 'urbackup' stdout output: ERROR: Image mounting failed: Loading FUSE kernel module... modprobe: FATAL: Module fuse not found in directory /lib/modules/5.10.28-Unraid Starting VHD background process... Waiting for background process to become available... Timeout while waiting for background process. Please see logfile (/var/log/urbackup-fuse.log) for error details. UrBackup mount process returned non-zero return code
-
All of the four mac os installation versions method 1 results in monterey being installed. Method 2 doesn't seem to download a complete file - 2GB img.
-
Urbackup has a mount ability for the images built-in to the web gui. However, because I get "TEST FAILED: guestmount is missing (libguestfs-tools)" that feature doesn't work. Is it safe to manually install the libguestfs-tools manually from the dockers' console, or is this something Binhex can add to the image? I also don't currently know how to install libguestfs-tools, but I'm sure it's something simple like sudo apt get libguest blah blah blah.
-
You could set the mount point of the external disk as a path in the container and map that in settings backup storage path.
-
I believe the config is inside the docker image. I thought it used the flac file to make the mp3. I could be wrong.
-
I have file integrity set to generate automatically. It seems to keep up on a daily basis. The hashes are stored in the metadata in the filesystem (If I understand the process correctly). Check export, if done after build and export, should verify the hashes. Mine performs with thousands of checks when I do it. I also maintain separate hash catalogs and par2 for the really really important data. You could be safe with par2 as it generates hashes. I'm really surprised to see that not more people are using par2 as an action plan for corruption when restoring from backup. Obviously this is only practical for archival data and not constantly modified data.
-
It works now! Thanks!
-
I can pass escape characters to ddrescue and it works fine in terminal. So the problem has something to do with the ripper.sh script. What I don't know is why it fails when the script sends $ISOPATH to it with a volume with spaces in its name. I'm not good enough in linux to diagnose or fix that yet. I don't know what I need to change in the script to make that work. I would like to have it replace the spaces with underscores, but I don't know the syntax to get that done.
-
In attempting to solve this my google search may have revealed that ddrescue struggles with spaces in volume names. Which isn't a problem with ripper, it might be a problem with ddrescue. The data discs I was trying to rip did indeed have spaces in their volume names. How do I overcome this? edit: maybe struggles isn't the right word. Something to do with the "escape characters" like this "file\ with\ spaces\ in\ it" Maybe the ripper script is feeding ddrescue the volume name without escape characters or ddrescue is not liking the spaces. I think I've identified the problem, but I don't know how to solve the problem.
-
I'm having an unusual problem. First time I'm trying to use the Ripper docker to rip an iso. I've already used it successfully to rip audio, dvd, blu-ray. When I try to rip an iso (insert data disc): The unraid docker log shows it loading the disc then it "looks like it works" then it says it completed successfully then it ejects the disc Upon inspection of the out path - the folder structure for the disc is created in ../DATA, but no iso or files are created in the folder. Inspection of the Ripper.log reveals the line: ddrescue: Too many files I opened the ripper.sh in nano to inspect the command. I can manually type in my ssh unraid terminal: ddrescue /dev/sr0 iso.iso and it works to create an iso from the disc. What do I need to do to correct the error? Multiple data discs were tried with the same result. I am a bit of a noob so please go easy on me I might be missing something obvious.
-
Thanks! Those instructions worked perfect. The older ssd had drug it down to 125 MB/s. Now its over 500 MB/s with the offending disk gone.
-
I would greatly appreciate it. I'm a noob, but not scared of the command line, I just grew up on the other side of the tracks with commodore and dos. I had played with the btrfs command line tools with some spare disks in a usb enclosure a little while ago, but I don't remember much. I really like that filesystem.
-
Hopefully, this will be a quick one. I have a four drive SSD cache pool in raid 0 btrfs. I want to remove one because it overheats and performs poorly compared to the other three. The pool is only 25% full. Using using Unraid 6.9.2. Not sure if this is a super easy GUI task or if I need to run a btrfs command from terminal first. I read the post from 2020 about this, but I think that was for an older unraid version and the documentation needed to be updated. Is the procedure correct as follows: 1. Disable docker and vm (runs from said pool) 2. stop array 3. Disable disk desired to be removed in gui 4. start array 5. allow balance to complete (moving the data from the removed disk automagically) 6. stop array 7. remove fourth disk slot from pool. 8. start array 9. reenable docker and vm My fear is that the programming may or may not be there to handle the automated removal for the raid 0 situation. If not, then my procedure would lead to data loss/corruption. I have a backup of all data on cache so I'm not worried about that.
-
Open but not running anything.... Will that do it? That could be the answer to all of my unclean shutdowns if so. I see the message that the server is shutting down, and then I just let it fail the putty session. I'm a bit of a noob, If I comb the logs, what would be a good search term for finding the reason for the unclean? I set up the syslog server last week so I should have it all.
-
No rush, my day job is building a school so I'll be busy for a bit.
-
Card is working great. I got it to work in foldingathome by modifying the config.xml file. I really wanted to try something that I knew would blast the thermals into this card for testing since it is used. However, out of two more tries, if I change the driver it results in a dirty array reboot both times. But regular rebooting works fine. Could just be my configuration or card. I have an MSI Geforce GTX 1050 2GB. I can live with the problem, but if you want to know more or diagnose I'm willing to provide as much information and testing as needed. Otherwise, everything is awesome.
-
Looks like it's working perfect in jellyfin. I appreciate all the help. I was just giving it a bad test (dockers I didn't know didn't support it). It appears to be working fine. Cpu load is low and gpu is about 8% transcoding a 265 playback over the internet to my android tablet. I'm a happy camper. Now I get to play with more power. Got room in this old tank for a second gpu...
-
Changed it and handbrake worked perfect! 700fps on a 264 encode! Only 45% loaded probably means it can do two or more encodes at a time! Typo, I meant worker node not client. I'll try adding the three parameters to the node docker and see if it works. Tdarr is used to do massive multiple node (or single) transcoding. I've used it for two weeks and gained 2tb switching some things to h265 from h264 and avi. You can use the server docker and nodes (win/mac/Linux/docker) to distribute the process across your network. We now have three gtx class cards in the network that can make the process go even faster. The beauty of tdarr is that it fully manages the workload and any failures and retries, and tests the output to confirm it did a complete job. That's a lot of work that I do not have to manage. Understood, thanks for the clarification. I don't think I did the smi command in the console for the container. I did it from the main terminal. If it doesn't work in the container console, does it mean that the container probably doesn't support it (or I don't have the container configured properly). Good to know. My card came from a uefi system, maybe it was just grumpy on first startup in a new system. I'll try some more reboots and hook up a screen and see if I am missing something.
-
Well that explains that, I am using the default from ca. How do I change that? What is recommended? I've also used tdarr on this server, but haven't tried the nvidia part yet on that docker. Do I just need to add the commands to the client? The default folding at home in CA. Maybe it doesn't support it either. The smi command yields results and adding the extra parameters line does still allow the docker to start. It seems like perhaps my tests may have been invalid. It seems like I need to try different dockers. I have plex and jellyfin running I may try those or tdarr node, or handbrake again if anyone can point me to how to choose a different docker for it. Thanks for your help and taking the time to be thorough. Not sure why the array was coming up dirty. The server is headless and I wasn't watching what was actually happening on a screen, I could just tell that it was getting half started and then rebooting. Do you know if I need to enable uefi for these cards? I currently have it set up as legacy. It is a Dell t5810 workstation.
-
Not sure how to troubleshoot. Previously I had an nvidia nvs 300 installed, tried the plugin, realized it didn't work with that card and uninstalled the plug in. Then much later I installed a GTX 1050. The plugin recognized the card, the dashboard plugin works, I added the three things to a couple of dockers (handbrake and folding at home), but neither one are using the card. I get no errors in the docker logs. I did disable and re-enable docker and rebooted a few times. I changed the driver to production. Now some of my reboots come up dirty with the array. when I installed the card first it rebooted while first boot up (resulted in a parity check). When I changed the driver to production from latest, it did the same thing. What is my next step in diagnosis? I'm not sure if step 7 (from 1st post about the daemon has been completed, but I don't know how to check it). cvg02-diagnostics-20211103-0604.zip
-
It has taken more time, but ultimately the hard drive has become bad with VERY slow write speeds slowing down the whole array to kilobytes per second. This program fail count was in the thousands a few weeks ago. The error log in my case was reporting the activity early. Interestingly, SMART still says the drive is okay. I have a few full metal jacketed Mauser rounds waiting for me to get this disk out. I like taking my bad disks to the shooting range = stress relief. It's also a lot faster than running a secure erase before trashing.
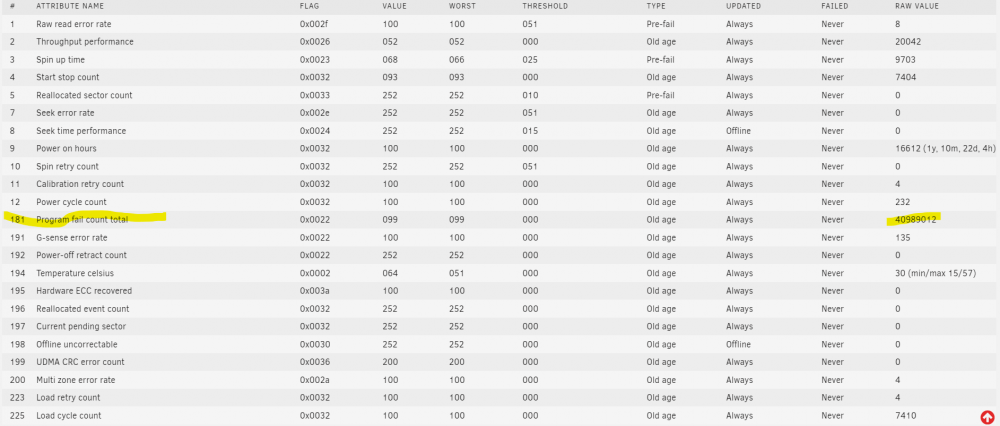
-
By the way moving slots and moving the disk to a direct connection to the motherboard produces the same errors. It must be something with the drive, but I'm not experiencing any problems (that I know of). File Verification plugin completed with no errors. Can anyone interpret the errors?
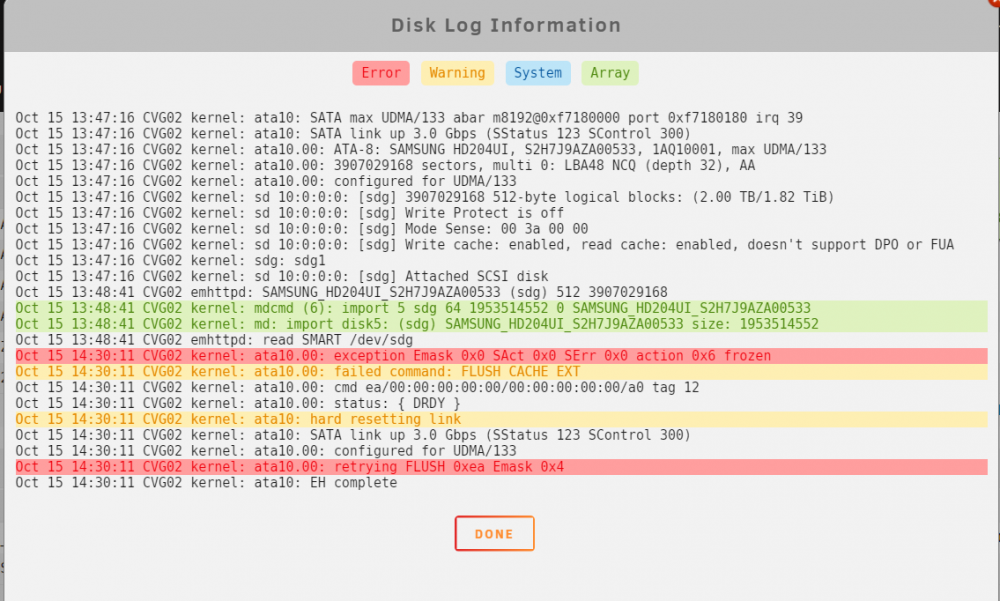
-
My mind is now blown. My first server was an IBM dual Pentium II 266 with two 9 GB SCSI discs in raid 0 with a SCSI cd burner that I .... made a ton of money with making mix discs for friends from usenet and napster. I changed careers from IT to construction almost 20 years ago so I'm a bit out of touch with the modern server styles. Fast-forward five servers and I'm about ready to take the next step to upgrading the storage enclosure method. This type of card seems to be the key to unlocking much more potential. Do you pair it with something like a 2U 12 disk enclosure with 8088 connectors?
-
😲Does it really support 32 disks?!?!!! I put my card in a spare HP desktop and it has no card bios (and ctrl -R doesn't do anything) on startup and shows up as dell 6gps hard drive controller in windows device manager. I received this card in error from an ebay seller that also sells IT mode flashed cards. Is it likely that the card is already flashed? I created a usb stick per directions I found about flashing the cards, but the allinfo commands didn't return the correct results so I didn't modify the card. I don't have any 8087 cables or I would try to hook up a drive.
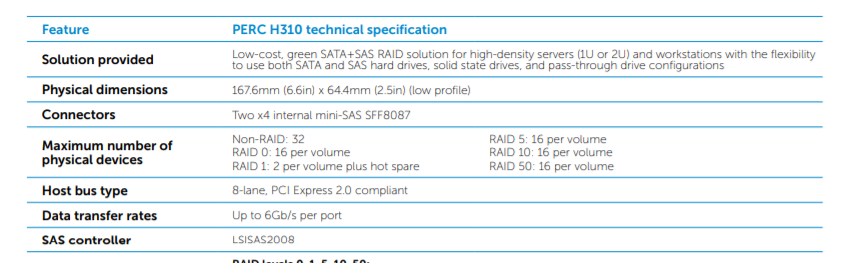
-
If I got the correct cables, is this the kind of thing I could connect to the h310? https://www.pc-pitstop.com/scsat84xb I assume the card is limited to 8 disks.



