




Shonky
Members
-
Joined
-
Last visited
-
Reported here too: https://product.unraid.net/p/7-3-2-dashboard-nginx-log-spam-from-stale-docker-template-fallback-icons
-
Are you sure it's this problem? Have you confirmed http://<ip of unraid>/nchan_stub_status is showing increasing memory usage? In my experience this doesn't "hard lock" the server at all. It's a bit hard to test but changing Settings->Display Settings->Allow realtime updates on inactive browsers to "No" might help. Basically if you change to another window after a few seconds the live updates stop.
-
Which timeout? I changed it to 600 seconds (so this now said "Waiting up to 600 seconds...") and it shutdown in under 5 minutes including the doing the diagnostics collection when it worked. So no chance it reached the set timeout. The diagnostics should still timeout. Do you know where this diagnostics collection is implemented?
-
It's more than a script. I've grepped through the whole FS and can't seem to find even where that string comes from. The docs indicate unclean is really a timeout on shutdown. It would seem perhaps mine is triggered by a docker shutdown timeout. That's not really an unclean shutdown IMO. Setting the General shutdown timer on mine to 10 minutes still results in the diagnostics collection and it reboots and restarts all the way in less than 5 minutes so that's not triggering it. https://docs.unraid.net/unraid-os/troubleshooting/common-issues/unclean-shutdowns/ Still doesn't really change the fact that the diagnostics collection should timeout. Particularly in the case of a bad system I want a best effort to shutdown. Edit: It's not the docker one. I set it the timeout to 30 seconds (which is supposed to be per docker). It shutdown 20+ dockers and got to the "diagnostics collection" in about 47 seconds based on the web interface.
-
This is not the correct. Or at least mine does the diagnostics collection thing every time and always has as far as I know. This is on my current VM but running it bare metal was my original post where it did the same. It may be an option I've set but I can't seem to find it now. This is an example of a successful shutdown where it doesn't hang, it successfully unmounts everything and reboots fine. But it still does the diagnostics collection. I note that a real "unclean" shutdown usually does a parity check. Even when I have to hard reset after the diagnostics hang, the array is considered clean.
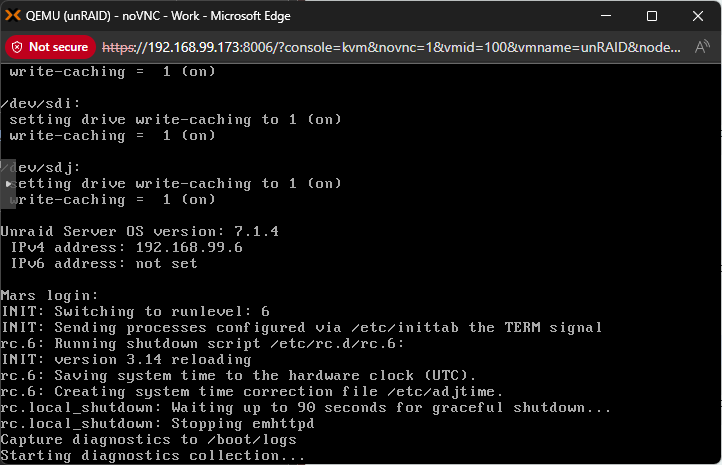
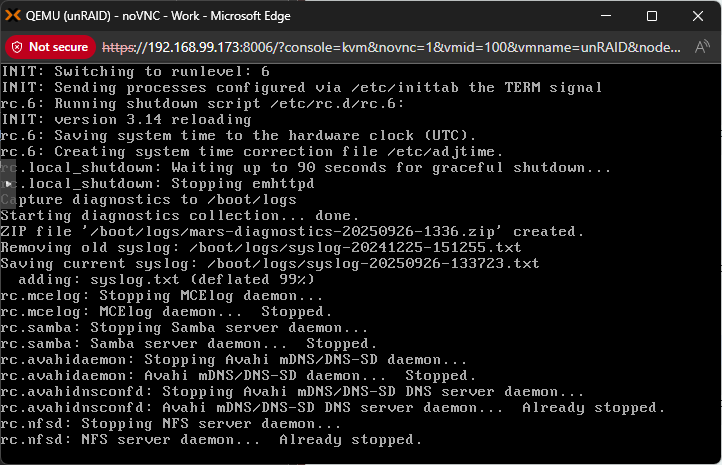
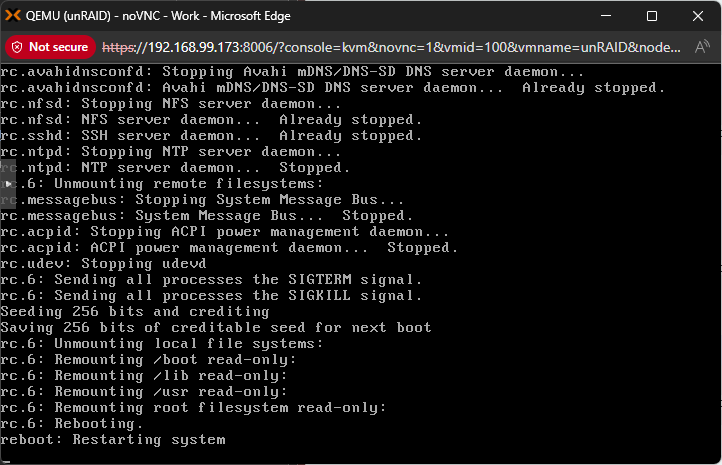
-
Whilst that seems to be the only solution which you repeat each time, it's not ideal. The problem is that if you reboot it, the next time it shuts down fine. It really should have some form of timeout on these processes rather than hanging there forever. There's not really anything logged to the screen to determined exactly what it's waiting on or anything. Perhaps it's because the logs are large but it shouldn't take 15 minutes or more. Edit: I can't even find where the "Starting diagnostics collection..." string even comes from. Seems a bit more than just a simple shutdown script but even grepping through the binaries I'm not seeing it.
-
unRAID 7.1.4 has been running about a week or two but getting this today: total published messages: 3173183 stored messages: 6534 shared memory used: 78236K shared memory limit: 262144K channels: 20 subscribers: 5 redis pending commands: 0 redis connected servers: 0 redis unhealthy upstreams: 0 total redis commands sent: 0 total interprocess alerts received: 0 interprocess alerts in transit: 0 interprocess queued alerts: 0 total interprocess send delay: 0 total interprocess receive delay: 0 nchan version: 1.3.7 stored messages and shared memory usage are increase about 1 and 4-8kB per second respectively. I had the WebUI open on a few tabs across two machines. I closed the browser completely on one machine (Chrome) and made sure there were no zombie processes or anything. No change. Other machine, I went to the tab and it looked to briefly refresh and had a bunch of very quick updates. Going back to the debug output and it's back to total published messages: 3174928 stored messages: 19 shared memory used: 56K shared memory limit: 262144K channels: 20 subscribers: 5 redis pending commands: 0 redis connected servers: 0 redis unhealthy upstreams: 0 total redis commands sent: 0 total interprocess alerts received: 0 interprocess alerts in transit: 0 interprocess queued alerts: 0 total interprocess send delay: 0 total interprocess receive delay: 0 nchan version: 1.3.7 I didn't get to nginx falling over with out of memory errors but I suspect they would have started once it reached the 256MB on shared memory used So it's still an issue with 7.1.4 unfortunately.
-
Not sure if this symptom been reported, but a couple of times I've gone back to a browser tab with a dashboard page showing. This could have been even after sleeping/hibernating the machine with the tab open. I see it very quickly updating i.e. there's a bunch of queued updates somewhere (likely buffered on the unRAID side given the memory issue). Quickly going to that diag link and I see the memory allocated figure drop rapidly to something like 500kB. Perhaps it's something like tabs being put partly to sleep in Chromium so they're not updating or at least not able to receive updates. Do the updates get pushed from the unRAID side rather than requested by the client? For the record it's not happened in 7.0.1 so far but it's only early days for me. It only happens rarely since I'm very careful to not leave tabs open because of this issue specifically.
-
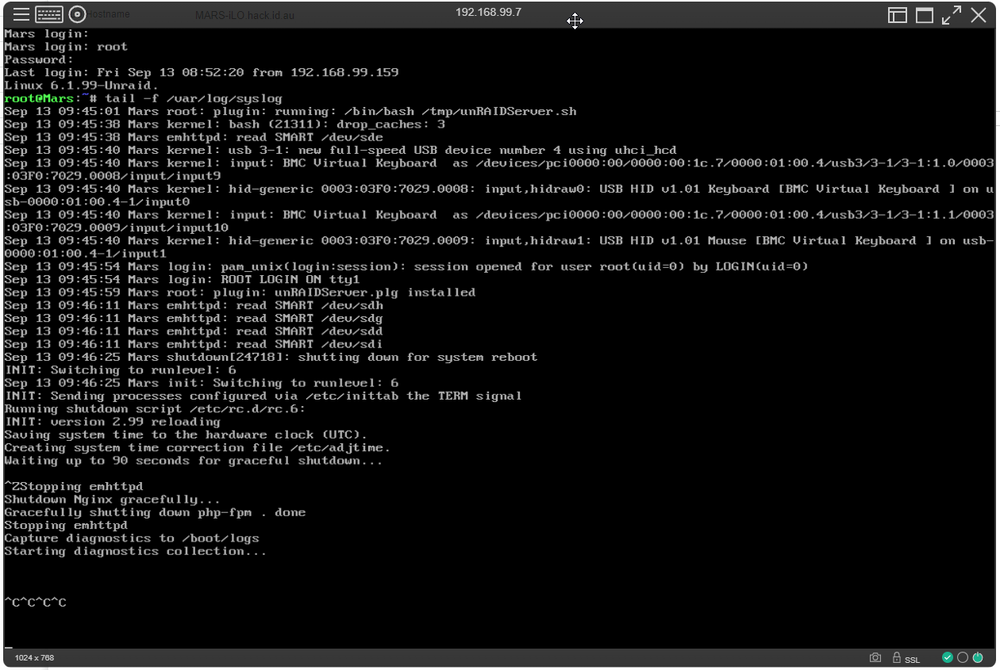
Did you ever find a reason for this? I just shutdown to upgrade from 6.12.11 to 6.12.13 (not because of a hang) and mine has stuck at the "Starting Diagnostics collection". It's been there for about 15 minutes now and it hasn't ever done this before.
-
On 6.12.11 I'm seeing it correctly detect 6.12.13 as the next stable branch update. But if I select the next branch it tests for 6.12.10.
-
Live demo link in unRAID apps ( https://dash.mauz.io/ ) goes to possibly dangerous websites vie multiple redirects. Should be https://dash.mauz.dev/
-
Well this docker template is not the same as the one I linked to. If you're having trouble with the other one then this thread is the wrong thread. The thread I linked I believe is the best and most up to date one. There have been a couple and also there have been significant changes to Crashplan over time e.g. the removal of the Home product.
-
Well firstly have you found the service.log.0 file and checked if it really is the same issue? Just because it's similar symptoms doesn't mean it's thae same problem. If it's the same problem go to the Docker tab then click the Crashplan then ">_ Console". Then you should be able to just "chmod 777 /usr/local/crashplan" without quotes and restore should just start from memory. Note that this is essentially a hack to make it work and possibly won't last if the container is restarted. The other container I use ended up getting a permanent fix.
-
Take a look at this. Could be the same or a similar thing. Check Crashplan's log files. It creates quite a few.
-
Did some more digging and found the code in /usr/local/emhttp/webGui/nchan/update1 #!/usr/bin/php -q <?PHP /* Copyright 2005-2021, Lime Technology * Copyright 2012-2021, Bergware International. * * This program is free software; you can redistribute it and/or * modify it under the terms of the GNU General Public License version 2, * as published by the Free Software Foundation. * * The above copyright notice and this permission notice shall be included in * all copies or substantial portions of the Software. */ ?> <? $docroot = '/usr/local/emhttp'; $varroot = '/var/local/emhttp'; require_once "$docroot/webGui/include/publish.php"; while (true) { unset($memory,$sys,$rpms,$lsof); exec("grep -Po '^Mem(Total|Available):\s+\K\d+' /proc/meminfo",$memory); exec("df /boot /var/log /var/lib/docker|grep -Po '\d+%'",$sys); exec("sensors -uA 2>/dev/null|grep -Po 'fan\d_input: \K\d+'",$rpms); $info = max(round((1-$memory[1]/$memory[0])*100),0)."%\0".implode("\0",$sys); $rpms = count($rpms) ? implode(" RPM\0",$rpms).' RPM' : ''; $names = array_keys((array)parse_ini_file("$varroot/shares.ini")); exec("LANG='en_US.UTF8' lsof -Owl /mnt/disk[0-9]* 2>/dev/null|awk '/^shfs/ && \$0!~/\.AppleD(B|ouble)/ && \$5==\"REG\"'|awk -F/ '{print \$4}'",$lsof); $counts = array_count_values($lsof); $count = []; foreach ($names as $name) $count[] = $counts[$name] ?? 0; $count = implode("\0",$count); publish('update1', "$info\1$rpms\1$count"); sleep(5); } ?> My regex skills aren't the best so perhaps excluding the Apple files and just counting open files? But why does it even do this if there's no WebGui reading it?




