




Shonky
Members
-
Joined
-
Last visited
Everything posted by Shonky
-
Reported here too: https://product.unraid.net/p/7-3-2-dashboard-nginx-log-spam-from-stale-docker-template-fallback-icons
-
Are you sure it's this problem? Have you confirmed http://<ip of unraid>/nchan_stub_status is showing increasing memory usage? In my experience this doesn't "hard lock" the server at all. It's a bit hard to test but changing Settings->Display Settings->Allow realtime updates on inactive browsers to "No" might help. Basically if you change to another window after a few seconds the live updates stop.
-
Which timeout? I changed it to 600 seconds (so this now said "Waiting up to 600 seconds...") and it shutdown in under 5 minutes including the doing the diagnostics collection when it worked. So no chance it reached the set timeout. The diagnostics should still timeout. Do you know where this diagnostics collection is implemented?
-
It's more than a script. I've grepped through the whole FS and can't seem to find even where that string comes from. The docs indicate unclean is really a timeout on shutdown. It would seem perhaps mine is triggered by a docker shutdown timeout. That's not really an unclean shutdown IMO. Setting the General shutdown timer on mine to 10 minutes still results in the diagnostics collection and it reboots and restarts all the way in less than 5 minutes so that's not triggering it. https://docs.unraid.net/unraid-os/troubleshooting/common-issues/unclean-shutdowns/ Still doesn't really change the fact that the diagnostics collection should timeout. Particularly in the case of a bad system I want a best effort to shutdown. Edit: It's not the docker one. I set it the timeout to 30 seconds (which is supposed to be per docker). It shutdown 20+ dockers and got to the "diagnostics collection" in about 47 seconds based on the web interface.
-
This is not the correct. Or at least mine does the diagnostics collection thing every time and always has as far as I know. This is on my current VM but running it bare metal was my original post where it did the same. It may be an option I've set but I can't seem to find it now. This is an example of a successful shutdown where it doesn't hang, it successfully unmounts everything and reboots fine. But it still does the diagnostics collection. I note that a real "unclean" shutdown usually does a parity check. Even when I have to hard reset after the diagnostics hang, the array is considered clean.
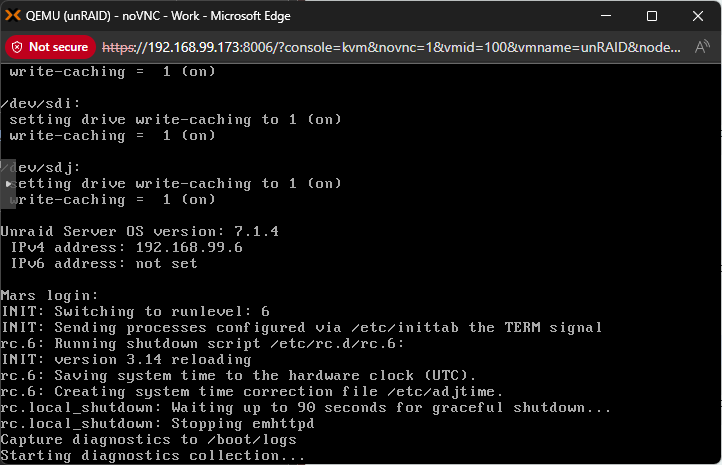
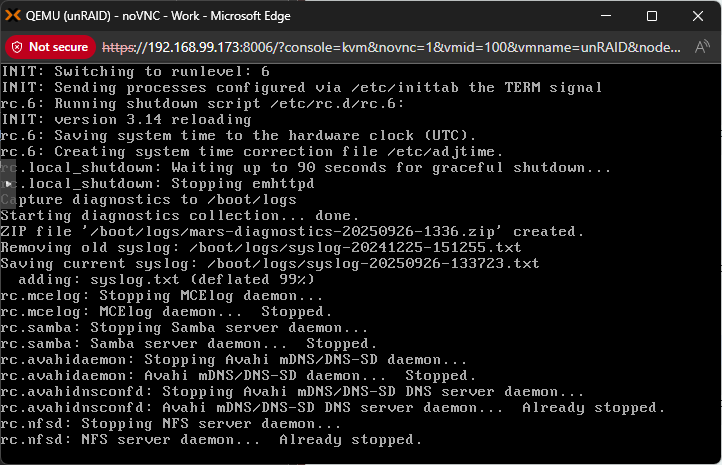
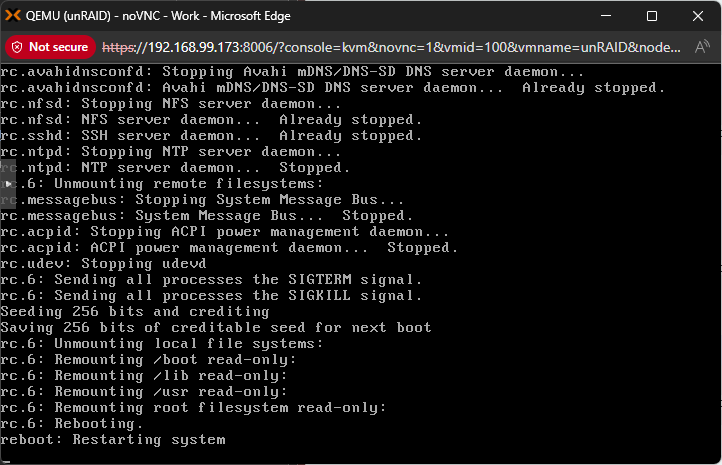
-
Whilst that seems to be the only solution which you repeat each time, it's not ideal. The problem is that if you reboot it, the next time it shuts down fine. It really should have some form of timeout on these processes rather than hanging there forever. There's not really anything logged to the screen to determined exactly what it's waiting on or anything. Perhaps it's because the logs are large but it shouldn't take 15 minutes or more. Edit: I can't even find where the "Starting diagnostics collection..." string even comes from. Seems a bit more than just a simple shutdown script but even grepping through the binaries I'm not seeing it.
-
unRAID 7.1.4 has been running about a week or two but getting this today: total published messages: 3173183 stored messages: 6534 shared memory used: 78236K shared memory limit: 262144K channels: 20 subscribers: 5 redis pending commands: 0 redis connected servers: 0 redis unhealthy upstreams: 0 total redis commands sent: 0 total interprocess alerts received: 0 interprocess alerts in transit: 0 interprocess queued alerts: 0 total interprocess send delay: 0 total interprocess receive delay: 0 nchan version: 1.3.7 stored messages and shared memory usage are increase about 1 and 4-8kB per second respectively. I had the WebUI open on a few tabs across two machines. I closed the browser completely on one machine (Chrome) and made sure there were no zombie processes or anything. No change. Other machine, I went to the tab and it looked to briefly refresh and had a bunch of very quick updates. Going back to the debug output and it's back to total published messages: 3174928 stored messages: 19 shared memory used: 56K shared memory limit: 262144K channels: 20 subscribers: 5 redis pending commands: 0 redis connected servers: 0 redis unhealthy upstreams: 0 total redis commands sent: 0 total interprocess alerts received: 0 interprocess alerts in transit: 0 interprocess queued alerts: 0 total interprocess send delay: 0 total interprocess receive delay: 0 nchan version: 1.3.7 I didn't get to nginx falling over with out of memory errors but I suspect they would have started once it reached the 256MB on shared memory used So it's still an issue with 7.1.4 unfortunately.
-
Not sure if this symptom been reported, but a couple of times I've gone back to a browser tab with a dashboard page showing. This could have been even after sleeping/hibernating the machine with the tab open. I see it very quickly updating i.e. there's a bunch of queued updates somewhere (likely buffered on the unRAID side given the memory issue). Quickly going to that diag link and I see the memory allocated figure drop rapidly to something like 500kB. Perhaps it's something like tabs being put partly to sleep in Chromium so they're not updating or at least not able to receive updates. Do the updates get pushed from the unRAID side rather than requested by the client? For the record it's not happened in 7.0.1 so far but it's only early days for me. It only happens rarely since I'm very careful to not leave tabs open because of this issue specifically.
-
Did you ever find a reason for this? I just shutdown to upgrade from 6.12.11 to 6.12.13 (not because of a hang) and mine has stuck at the "Starting Diagnostics collection". It's been there for about 15 minutes now and it hasn't ever done this before.
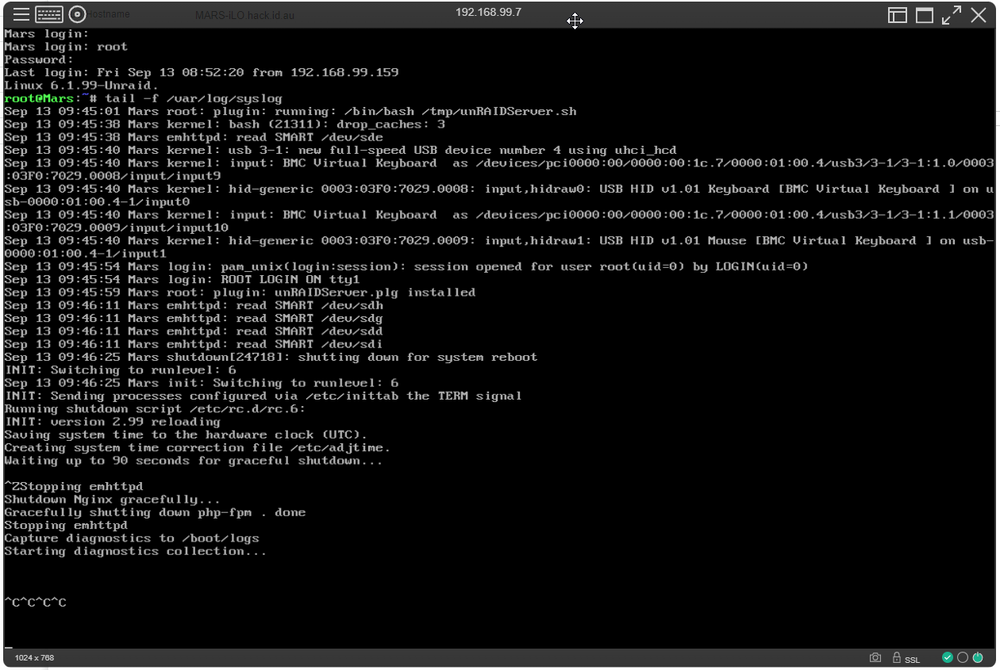
-
On 6.12.11 I'm seeing it correctly detect 6.12.13 as the next stable branch update. But if I select the next branch it tests for 6.12.10.
-
Live demo link in unRAID apps ( https://dash.mauz.io/ ) goes to possibly dangerous websites vie multiple redirects. Should be https://dash.mauz.dev/
-
Well this docker template is not the same as the one I linked to. If you're having trouble with the other one then this thread is the wrong thread. The thread I linked I believe is the best and most up to date one. There have been a couple and also there have been significant changes to Crashplan over time e.g. the removal of the Home product.
-
Well firstly have you found the service.log.0 file and checked if it really is the same issue? Just because it's similar symptoms doesn't mean it's thae same problem. If it's the same problem go to the Docker tab then click the Crashplan then ">_ Console". Then you should be able to just "chmod 777 /usr/local/crashplan" without quotes and restore should just start from memory. Note that this is essentially a hack to make it work and possibly won't last if the container is restarted. The other container I use ended up getting a permanent fix.
-
Take a look at this. Could be the same or a similar thing. Check Crashplan's log files. It creates quite a few.
-
Did some more digging and found the code in /usr/local/emhttp/webGui/nchan/update1 #!/usr/bin/php -q <?PHP /* Copyright 2005-2021, Lime Technology * Copyright 2012-2021, Bergware International. * * This program is free software; you can redistribute it and/or * modify it under the terms of the GNU General Public License version 2, * as published by the Free Software Foundation. * * The above copyright notice and this permission notice shall be included in * all copies or substantial portions of the Software. */ ?> <? $docroot = '/usr/local/emhttp'; $varroot = '/var/local/emhttp'; require_once "$docroot/webGui/include/publish.php"; while (true) { unset($memory,$sys,$rpms,$lsof); exec("grep -Po '^Mem(Total|Available):\s+\K\d+' /proc/meminfo",$memory); exec("df /boot /var/log /var/lib/docker|grep -Po '\d+%'",$sys); exec("sensors -uA 2>/dev/null|grep -Po 'fan\d_input: \K\d+'",$rpms); $info = max(round((1-$memory[1]/$memory[0])*100),0)."%\0".implode("\0",$sys); $rpms = count($rpms) ? implode(" RPM\0",$rpms).' RPM' : ''; $names = array_keys((array)parse_ini_file("$varroot/shares.ini")); exec("LANG='en_US.UTF8' lsof -Owl /mnt/disk[0-9]* 2>/dev/null|awk '/^shfs/ && \$0!~/\.AppleD(B|ouble)/ && \$5==\"REG\"'|awk -F/ '{print \$4}'",$lsof); $counts = array_count_values($lsof); $count = []; foreach ($names as $name) $count[] = $counts[$name] ?? 0; $count = implode("\0",$count); publish('update1', "$info\1$rpms\1$count"); sleep(5); } ?> My regex skills aren't the best so perhaps excluding the Apple files and just counting open files? But why does it even do this if there's no WebGui reading it?
-
Did you figure out what "feature" causes this? I see an lsof task running every 5-10 seconds as a process spawned by update1. I have made sure I closed all WebUI interfaces (closed browser completely, made sure no processes still running) but they persist. This is the command that keeps running sh -c LANG='en_US.UTF8' lsof -Owl /mnt/disk[0-9]* 2>/dev/null|awk '/^shfs/ && $0!~/\.AppleD(B|ouble)/ && $5=="REG"'|awk -F/ '{print $4}' I don't have any Apple devices so whilst mine's not pegging the CPU at 100% for extended periods it's not necessary. Just runs 100% for maybe a second each time. Seems to be look for hidden files left by Macs and then prints them somewhere. Seems kind of pointless to me. I see a sleep 2, so perhaps running every two seconds: ps aux | grep ls[o]f -A5 -B5 root 17957 0.0 0.1 88744 29040 ? SL Jul03 24:23 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/wg_poller root 17960 0.0 0.1 88744 29000 ? SL Jul03 6:40 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/update_1 root 17963 0.0 0.1 88944 29716 ? SL Jul03 34:08 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/update_2 root 17966 0.1 0.1 88884 29408 ? SL Jul03 64:21 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/update_3 root 18095 0.0 0.0 0 0 ? I 17:31 0:00 [kworker/2:0] root 18149 0.0 0.0 3936 2984 ? S 17:31 0:00 sh -c LANG='en_US.UTF8' lsof -Owl /mnt/disk[0-9]* 2>/dev/null|awk '/^shfs/ && $0!~/\.AppleD(B|ouble)/ && $5=="REG"'|awk -F/ '{print $4}' root 18150 13.0 0.0 5340 3292 ? S 17:31 0:00 lsof -Owl /mnt/disk1 /mnt/disk2 /mnt/disk3 /mnt/disk4 /mnt/disk5 root 18151 0.0 0.0 8376 2560 ? S 17:31 0:00 awk /^shfs/ && $0!~/\.AppleD(B|ouble)/ && $5=="REG" root 18152 0.0 0.0 8244 2496 ? S 17:31 0:00 awk -F/ {print $4} root 18155 0.0 0.0 2464 732 ? S 17:31 0:00 sleep 2 root 18156 0.0 0.0 4860 2908 pts/27 R+ 17:31 0:00 ps aux root 18157 0.0 0.0 3980 2228 pts/27 S+ 17:31 0:00 grep ls[o]f -A5 -B5
-
Right but the Change time is being updated (see original post) which appears to be what hashbackup is seeing.
-
It did appear to be the file integrity plugin as updating one of the file date attributes resulting in hashbackup backing them up again. I've stopped the plugin for now.
-
I came across this solution separately, and then found this other thread just now. Seems like it could be a possible solution. My router (pfSense) was complaining about an IP having two different MAC addresses (the real hardware and a virtual interfaces called something like br0-shim but responds to ARP requests I presume resulting in packets to one IP coming in on two different network interfaces)
-
Turn cache off or if doing it on the machine itself, copy direct to /mnt/user0/...
-
Upgrade your crashplan docker. Crashplan tries to upgrade itself but that doesnt work in the unraid docker. Should be v8.8.1 from memory. Mine had to be upgraded twice recently although the 8.8.1 I don't think changed. Crashplan was downloading the same ~20MB file hundreds of times into its /tmp directory.
-
System is a Microserver Gen 8 with "07:00.0 SATA controller: Marvell Technology Group Ltd. 88SE9230 PCIe 2.0 x2 4-port SATA 6 Gb/s RAID Controller (rev 11)" connected to an external drive enclosure via an eSATA port through a port multiplier. Works fine in 6.9.2 and it has been part of my system for at least 4 years. Drives sdb, sdc, sdd, sde are in the main chassis and sdi, sdg are in the enclosure. Also sdh and sdj are installed but not part of the array. Drives are getting quite full, I was going to add a new drive soon. Upgraded from 6.9.2 to 6.10.0-rc2. Initially everything started OK. However shortly after booting as I was just checking things over, it started dropping all the drives in the enclosure - both in the array and not. Log ending from is 6.10.0-rc2 boot from /boot/logs. I didn't request it - is it created automatically? Nov 8 12:22:00 Mars root: Fix Common Problems Version 2021.08.05 Nov 8 12:26:54 Mars kernel: ata8: SATA link down (SStatus 0 SControl 300) Nov 8 12:27:00 Mars kernel: ata8: SATA link down (SStatus 0 SControl 300) Nov 8 12:27:05 Mars kernel: ata11: SATA link down (SStatus 0 SControl 300) Nov 8 12:27:10 Mars kernel: ata12: SATA link down (SStatus 0 SControl 300) Nov 8 12:27:15 Mars kernel: ata12: SATA link down (SStatus 0 SControl 300) Nov 8 12:27:21 Mars kernel: ata8: SATA link down (SStatus 0 SControl 300) Nov 8 12:27:21 Mars kernel: ata8.00: disabled Nov 8 12:27:21 Mars kernel: ata11: SATA link down (SStatus 0 SControl 300) Nov 8 12:27:21 Mars kernel: sd 8:0:0:0: rejecting I/O to offline device Nov 8 12:27:21 Mars kernel: blk_update_request: I/O error, dev sdg, sector 3910845296 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 Nov 8 12:27:21 Mars kernel: md: disk5 read error, sector=3910845232 Nov 8 12:27:26 Mars kernel: ata13: SATA link down (SStatus 0 SControl 300) Nov 8 12:27:31 Mars kernel: ata8.00: detaching (SCSI 8:0:0:0) Nov 8 12:27:31 Mars kernel: sd 8:0:0:0: [sdg] Synchronizing SCSI cache Nov 8 12:27:31 Mars kernel: sd 8:0:0:0: [sdg] Synchronize Cache(10) failed: Result: hostbyte=0x04 driverbyte=DRIVER_OK Nov 8 12:27:31 Mars kernel: sd 8:0:0:0: [sdg] Stopping disk Nov 8 12:27:31 Mars kernel: sd 8:0:0:0: [sdg] Start/Stop Unit failed: Result: hostbyte=0x04 driverbyte=DRIVER_OK Nov 8 12:27:31 Mars kernel: ata11: SATA link down (SStatus 0 SControl 300) Nov 8 12:27:31 Mars kernel: ata11.00: disabled Nov 8 12:27:31 Mars kernel: ata12: SATA link down (SStatus 0 SControl 300) Nov 8 12:27:31 Mars kernel: ata12.00: disabled Nov 8 12:27:31 Mars kernel: ata13: SATA link down (SStatus 0 SControl 300) Nov 8 12:27:31 Mars kernel: sd 12:0:0:0: rejecting I/O to offline device Nov 8 12:27:31 Mars kernel: blk_update_request: I/O error, dev sdi, sector 3910845296 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 Nov 8 12:27:31 Mars kernel: md: disk4 read error, sector=3910845232 Nov 8 12:27:31 Mars kernel: XFS (md5): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0xe91ac330 len 8 error 5 Nov 8 12:27:31 Mars kernel: XFS (md5): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0xe91ac330 len 8 error 5 Nov 8 12:27:31 Mars kernel: XFS (md5): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0xe91ac330 len 8 error 5 Nov 8 12:27:31 Mars kernel: XFS (md5): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0xe91ac330 len 8 error 5 Nov 8 12:27:31 Mars kernel: XFS (md5): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0xe91ac330 len 8 error 5 Nov 8 12:27:31 Mars kernel: XFS (md5): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0xe91ac330 len 8 error 5 Nov 8 12:27:31 Mars kernel: XFS (md5): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0xe91ac330 len 8 error 5 Nov 8 12:27:31 Mars kernel: XFS (md5): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0xe91ac330 len 8 error 5 Nov 8 12:27:31 Mars kernel: XFS (md5): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0xe91ac330 len 8 error 5 Nov 8 12:27:31 Mars kernel: XFS (md5): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0xe91ac330 len 8 error 5 Nov 8 12:27:31 Mars kernel: md: disk5 read error, sector=6143051080 Nov 8 12:27:31 Mars kernel: blk_update_request: I/O error, dev sdi, sector 6143051144 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 Nov 8 12:27:31 Mars kernel: md: disk4 read error, sector=6143051080 Nov 8 12:27:32 Mars kernel: md: disk5 read error, sector=6143089464 Nov 8 12:27:32 Mars kernel: blk_update_request: I/O error, dev sdi, sector 6143089528 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 Nov 8 12:27:32 Mars kernel: md: disk4 read error, sector=6143089464 Nov 8 12:27:37 Mars kernel: ata12.00: detaching (SCSI 12:0:0:0) Nov 8 12:27:37 Mars kernel: ata11.00: detaching (SCSI 11:0:0:0) Nov 8 12:27:37 Mars kernel: sd 11:0:0:0: [sdh] Synchronizing SCSI cache Nov 8 12:27:37 Mars kernel: sd 11:0:0:0: [sdh] Synchronize Cache(10) failed: Result: hostbyte=0x04 driverbyte=DRIVER_OK Nov 8 12:27:37 Mars kernel: sd 11:0:0:0: [sdh] Stopping disk Nov 8 12:27:37 Mars kernel: sd 11:0:0:0: [sdh] Start/Stop Unit failed: Result: hostbyte=0x04 driverbyte=DRIVER_OK Nov 8 12:27:37 Mars kernel: sd 12:0:0:0: [sdi] Synchronizing SCSI cache Nov 8 12:27:37 Mars kernel: sd 12:0:0:0: [sdi] Synchronize Cache(10) failed: Result: hostbyte=0x04 driverbyte=DRIVER_OK Nov 8 12:27:37 Mars kernel: sd 12:0:0:0: [sdi] Stopping disk Nov 8 12:27:37 Mars kernel: sd 12:0:0:0: [sdi] Start/Stop Unit failed: Result: hostbyte=0x04 driverbyte=DRIVER_OK Nov 8 12:27:37 Mars kernel: ata13: SATA link down (SStatus 0 SControl 300) Nov 8 12:27:37 Mars kernel: ata13.00: disabled Nov 8 12:27:37 Mars emhttpd: error: get_device_size, 1549: No such device or address (6): open: /dev/sdj Nov 8 12:27:37 Mars emhttpd: error: device_inventory, 1704: No such file or directory (2): readlink: /sys/dev/block/8:112 Nov 8 12:27:37 Mars emhttpd: error: device_inventory, 1704: No such file or directory (2): readlink: /sys/dev/block/8:129 Nov 8 12:27:37 Mars emhttpd: error: device_inventory, 1704: No such file or directory (2): readlink: /sys/dev/block/8:113 Nov 8 12:27:37 Mars emhttpd: error: device_inventory, 1704: No such file or directory (2): readlink: /sys/dev/block/8:128 Nov 8 12:27:37 Mars kernel: ata13.00: detaching (SCSI 13:0:0:0) Nov 8 12:27:37 Mars kernel: sd 13:0:0:0: [sdj] Synchronizing SCSI cache Nov 8 12:27:37 Mars kernel: sd 13:0:0:0: [sdj] Synchronize Cache(10) failed: Result: hostbyte=0x04 driverbyte=DRIVER_OK Nov 8 12:27:37 Mars kernel: sd 13:0:0:0: [sdj] Stopping disk Nov 8 12:27:37 Mars kernel: sd 13:0:0:0: [sdj] Start/Stop Unit failed: Result: hostbyte=0x04 driverbyte=DRIVER_OK Nov 8 12:27:37 Mars unassigned.devices: Warning: Can't get rotational setting of 'sdj'. Nov 8 12:27:44 Mars kernel: md: disk4 read error, sector=282765536 Nov 8 12:27:44 Mars kernel: md: disk5 read error, sector=282765536 Nov 8 12:27:44 Mars kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0x10daa8e0 len 8 error 5 Nov 8 12:27:44 Mars kernel: md: disk5 read error, sector=5988858984 Nov 8 12:27:44 Mars kernel: md: disk5 read error, sector=5988858992 Nov 8 12:27:44 Mars kernel: md: disk5 read error, sector=5988859000 Nov 8 12:27:44 Mars kernel: md: disk5 read error, sector=5988859008 Nov 8 12:27:44 Mars kernel: md: disk4 read error, sector=5988858984 Nov 8 12:27:44 Mars kernel: md: disk4 read error, sector=5988858992 Nov 8 12:27:44 Mars kernel: md: disk4 read error, sector=5988859000 Nov 8 12:27:44 Mars kernel: md: disk4 read error, sector=5988859008 Nov 8 12:27:44 Mars kernel: md: disk4 read error, sector=6008286176 Nov 8 12:27:44 Mars kernel: md: disk5 read error, sector=6008286176 Nov 8 12:27:44 Mars kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0x1661f2be0 len 8 error 5 Nov 8 12:27:44 Mars kernel: md: disk5 read error, sector=4035502192 Nov 8 12:27:44 Mars kernel: md: disk5 read error, sector=4035502200 Nov 8 12:27:44 Mars kernel: md: disk5 read error, sector=4035502208 Nov 8 12:27:44 Mars kernel: md: disk5 read error, sector=4035502216 Nov 8 12:27:44 Mars kernel: md: disk4 read error, sector=4035502192 Nov 8 12:27:44 Mars kernel: md: disk4 read error, sector=4035502200 Nov 8 12:27:44 Mars kernel: md: disk4 read error, sector=4035502208 Nov 8 12:27:44 Mars kernel: md: disk4 read error, sector=4035502216 Nov 8 12:27:44 Mars kernel: md: disk5 read error, sector=5990007848 Nov 8 12:27:44 Mars kernel: md: disk5 read error, sector=5990007856 Nov 8 12:27:44 Mars kernel: md: disk5 read error, sector=5990007864 Nov 8 12:27:44 Mars kernel: md: disk5 read error, sector=5990007872 Nov 8 12:27:44 Mars kernel: md: disk4 read error, sector=5990007848 Nov 8 12:27:44 Mars kernel: md: disk4 read error, sector=5990007856 Nov 8 12:27:44 Mars kernel: md: disk4 read error, sector=5990007864 Nov 8 12:27:44 Mars kernel: md: disk4 read error, sector=5990007872 Nov 8 12:27:50 Mars kernel: md: disk4 read error, sector=66720 Nov 8 12:27:50 Mars kernel: md: disk5 read error, sector=66720 Nov 8 12:27:50 Mars kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0x104a0 len 8 error 5 Nov 8 12:27:50 Mars kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0x104a0 len 8 error 5 Nov 8 12:27:50 Mars kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0x104a0 len 8 error 5 Nov 8 12:27:50 Mars kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0x104a0 len 8 error 5 Nov 8 12:27:50 Mars kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0x104a0 len 8 error 5 Nov 8 12:27:50 Mars kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0x104a0 len 8 error 5 Nov 8 12:27:50 Mars kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0x104a0 len 8 error 5 Nov 8 12:27:50 Mars kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0xa3/0x103 [xfs]" at daddr 0x104a0 len 8 error 5 Nov 8 12:27:50 Mars kernel: md: disk4 read error, sector=2303691736 .... I didn't really want to hang around long so fairly quickly reverted back to 6.9.2 and everything is working again. Started a parity check and that's going ok after 200GB of checking. I wouldn't call this urgent, but it's not minor or annoyance. I would consider it a major problem though certainly for a next release. The priority options aren't the best IMO. mars-diagnostics-20211108-1230.zip
-
Would be much clearer with a simple "none of the above" and likely people would actually vote. It's in no way clear that clicking "view results" counts as abstention. The current numbers show 135 out of 219 voted, i.e. "no vote" is second choice by a slim margin to ApplePay (89 vs 84)
-
https://forums.unraid.net/topic/51633-plugin-rclone ?
-
Polls don't work in Tapatalk.




