




KyleS
Members
-
Joined
-
Last visited
Everything posted by KyleS
-
So I've bit the security bullet and moved all of my PVCs to the first folder because of Unraids incredibly poor support for subfolders. None of my shares are showing up??? folders look like the following... pvc-13cc4602-1b86-40a0-bbf3-76baedabf2ff_unraid_config
-
Yeah, I have a couple war games apps to keep the logic sane, but they never went quite right after hacking on them for a couple hours. I'm still on the road for the holidays, so haven't spent the time to sit down and finish them properly. Really pisses me off that Unraid is this closed paid product that doesn't even get the basics correct.
-
Certainly doesn't fill the most empty disk.
-
Yeah - none of this reasonable. Here's a real solution. What a complete piss-off.
-
As Unraid continues to be completely worthless at managing data, I've gone back to the roots which is mergerfs. Thankfully, there's a modicum of thought, and they have a balance utility. Spinning a container and running balance still maintains the data consistency rules of shfs, and automates splitting as appropriate. It's completely unbelievable how terrible mover is, and how it ignores all placement rules. Of course the container needs to be privileged, with /mnt passed to the container, and /dev/fuse passed as a device. Cheers. FROM alpine:3.17 RUN apk add --no-cache curl && \ curl -L https://github.com/trapexit/mergerfs-tools/archive/master.tar.gz -o /tmp/mergerfs-tools.tar.gz && \ tar xvf /tmp/mergerfs-tools.tar.gz mergerfs-tools-master/src/ -C /usr/local/bin --strip-components=2 && \ chmod +x /usr/local/bin/mergerfs.* && \ rm -rf /tmp/mergerfs-tools.tar.gz && echo "@testing https://dl-cdn.alpinelinux.org/alpine/edge/testing" | tee -a /etc/apk/repositories && apk add --no-cache mergerfs@testing bash python3 rsync CMD ["/bin/ash", "-c", "/bin/mkdir /tmp/balance && /bin/mount -t mergerfs '/mnt/disk[0-9]*' /tmp/balance && /usr/local/bin/mergerfs.balance /tmp/balance"]
-
Simply not correct. The disks aren't even included in the share and mover fills those disks anyway.
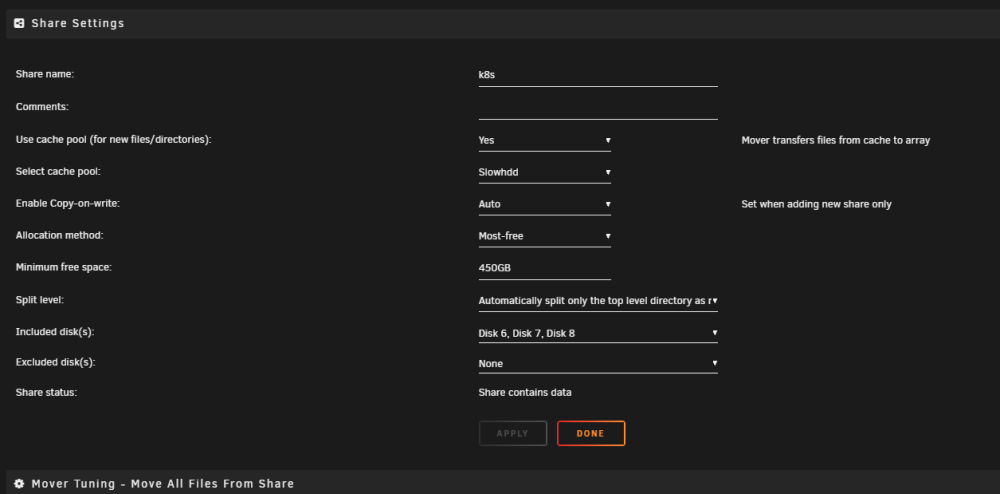
-
Unraid doesn't seem to have any real thought put into it. Mover continues to move to full disks and ignores quota assignments. Disk splitting continues to just fill full disks (500G is reserved, which I find to be ridiculous that this is ignored and disks fill to 64KB). Does anyone actually use this seriously? Besides shfs everything else seems to be completely worthless. What am I missing?
-
Yeah - that's definitely not how it works with Mover. It just picks the first disk and loads it up. It's super silly and has been causing me nothing but pain. Unless if I'm missing something, this is no where near production ready (realizing, that yes, it's been around for many many years).
-
/dev/mapper/md*
-
Doesn't work at all with encryption (can't find the disks). - just needs a minor change to your "regex". Do you have a layout defragger as well?
-
Seeing as no one has brought it up... thinking I'm the first to fix this incredibly silly issue with Unraid. Cloudflare(1) saw latency issues years ago with dm-crypt and implemented no_write_workqueue and no_read_workqueue which was upstreamed in Kernel 5.9 (with external patches for lower versions, of course). Using xfs-encryption on my 8 core system results in a nice system load of atleast 40, if not 120 (yes, 120, on a 8! thread system) with crazy WA times - making the system completely unusable. As Unraid doesn't use /etc/crypttab, the only way to do this is to set the persistent flags on the volume. To apply this configuration to your disks is very simple. cryptsetup --perf-no_read_workqueue --perf-no_write_workqueue --allow-discards --persistent refresh md8 To check your volumes, spin through `ls /dev/mapper`. Yes, right now these disks are all rotational and there's a massive reduction in system load. No, I haven't played with read/writes or other ciphers to see if there's even more performance to get out of this. My system is usable again with a modicum of array writing so I'm moving on for now. The system load is even worse without encryption from it what seems like, ironically. Cheers. https://blog.cloudflare.com/speeding-up-linux-disk-encryption/
-
Likely the most impactful change for 6.11. Thanks much.
-
9p shouldn't be the default anymore, flip it to virtio-fs.
-
eBPF has been in the tree forever, can we please enable this so our docker containers using this can launch.
-
@limetech any update on this one? It's pretty critical for newer networking applications.
-
nah, it looks like @limetech is paying attention now. Still disappointing there's countless reports for this closed product and still no fix.
-
cc @limetech
-
Any update on this trivial critical issue?
-
it's using ixgbe on both systems. From a working box: ``` [ 3.430109] kernel: ixgbe 0000:07:00.1: Intel(R) 10 Gigabit Network Connection [ 3.431727] kernel: ixgbe 0000:05:00.0 eno1: renamed from eth0 [ 3.444996] kernel: ixgbe 0000:07:00.0 eno3: renamed from eth2 [ 3.469108] kernel: ixgbe 0000:05:00.1 eno2: renamed from eth1 [ 3.488806] kernel: ixgbe 0000:07:00.1 eno4: renamed from eth3 ```
-
Ubuntu LTS retail works with the onboard SoC. Trying to change this enterprise board to Unraid but the in-kernel driver doesn't seem to be there. For whatever reason it's trying to load some external module which taints the kernel, but the network doesn't come up (bonds or not). It also maddeningly looks like stable internet iface names from 2013 are not present either... What am I doing wrong?


