





zoggy
Members
-
Joined
-
Last visited
-
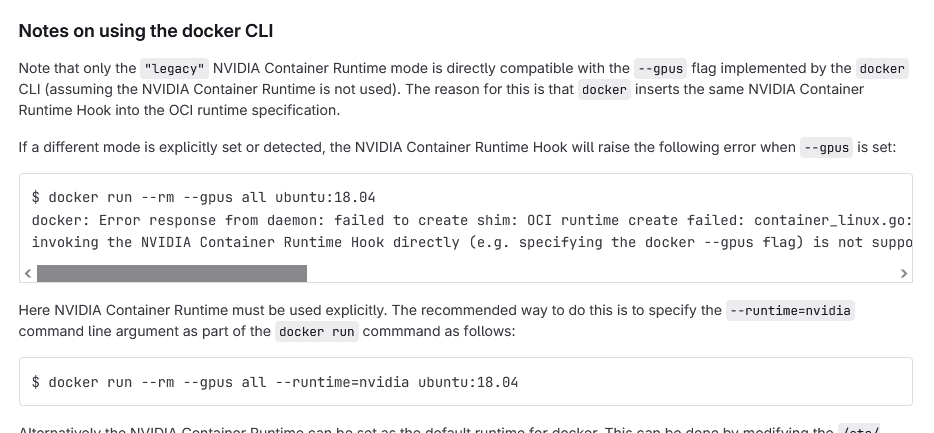
--gpus came with docker 19.03, and a lot of improvements with --gpus came with docker29 ( https://docs.docker.com/engine/release-notes/29/ ) https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/docker-specialized.html so why would someone not want to use --gpus today and instead the legacy --runtime ? browsing i found https://gitlab.com/nvidia/container-toolkit/container-toolkit/-/tree/main/cmd/nvidia-container-runtime#notes-on-using-the-docker-cli
-
booted up test box, installed 7.2.3 and it has 0 plugins. went to install CA and see the same thing. its fallout of redirect being broken for https://github.com/unraid/webgui/blob/master/emhttp/plugins/dynamix/Apps.page#L26C41-L26C171 short term fix is correcting that url this to not need that redirect and then it will install just fine sed -i 's#https://ca.unraid.net/dl/##g' /usr/local/emhttp/webGui/Apps.page long term fix, unraid side needs to fix their redirect to restore the broken url to work.. update redirect has been fixed, above is no longer needed
-
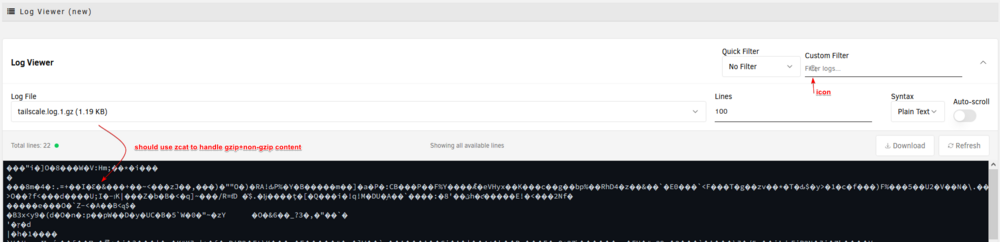
win10 pro w/ firefox 145.01 can see icon badly placed on filter, and trying to view gzip logs doesnt work -- you should use zcat to view since it will handle gzip+non-gzip files then the log area also suffers from some overlap where you cant scroll horz due to overlap of vert scroll until you resize it to get past it the vert scroll then you can access the >


-
Windows 10 with Firefox 141 Installed 7.2.0b1 on test box, noticed that the tooltips get cut off when you use tabbed laout... technically overflow creates scroll region but if you try to scroll it snaps back up. easy to see on main > boot device / unassigned devices example:
-
per irc you are running unraid 6.10.3 which is like 2.5 years out of date which doesnt understand oci docker images update unraid
-
I noticed that on unraid 7.0.0 when mover runs with logging enabled there is a bit of log spam with the init_debugging lines which I do not recall before.. can this entry be removed as it does not serve any value to users. Jan 17 16:21:11 husky emhttpd: shcmd (4537947): /usr/local/sbin/mover start |& logger -t move & Jan 17 16:21:11 husky move: Log Level: 1 Jan 17 16:21:11 husky move: mover: started Jan 17 16:21:11 husky move: init_debugging: 1 Jan 17 16:21:15 husky move: move: /mnt/cache/Movies/Movies-HD/Flow.(2024).{tmdb-823219}/media.mkv Success Jan 17 16:21:15 husky move: init_debugging: 1 Jan 17 16:22:04 husky move: move: /mnt/cache/Movies/Movies-Asian/Start-Up.(2019).{tmdb-581530}/movie.mkv Success Jan 17 16:22:04 husky move: init_debugging: 1 Jan 17 16:22:04 husky move: init_debugging: 1 Jan 17 16:22:04 husky move: mover: finished
-
a 2G prob works with a clean install (no plugins/no baggage of logs-notifications-backups).. but yeah prob doesnt hurt to bump min requirement to 4G these days as everything keeps growing.... but anyways to note, upgraded to 7.0 from 7.0rc2 without any issues. using 4G usb stick
-
i would think the .idea folder should be ignored for CA appfeed (as this is meant for an IDE). That way CA doesnt wrongly try and think there is xml in there it should care about.. as it just adds noise to to the "Invalid Templates" page. example: { "TemplatePath": "/tmp/appFeed/templates/OfficialWizarrRepository/.idea/dataSources.xml", "errors": [ "Not an unRaid Application (no Repository or PluginURL entry)" ], "FirstSeen": null }, { "TemplatePath": "/tmp/appFeed/templates/OfficialWizarrRepository/.idea/misc.xml", "errors": [ "Not an unRaid Application (no Repository or PluginURL entry)" ], "FirstSeen": null }, { "TemplatePath": "/tmp/appFeed/templates/OfficialWizarrRepository/.idea/modules.xml", "errors": [ "Not an unRaid Application (no Repository or PluginURL entry)" ], "FirstSeen": null }, { "TemplatePath": "/tmp/appFeed/templates/OfficialWizarrRepository/.idea/inspectionProfiles/profiles_settings.xml", "errors": [ "Not an unRaid Application (no Repository or PluginURL entry)" ], "FirstSeen": null },
-
I have several shares that I setup awhile ago to go directly to array since I never wanted that data at risk. I see that when upgrading to unraid 7 (now on rc1, was on b2 before) I see that those Array only shares now show as "Cache" only... The two shares as example are "Music" and "Personal". I have not modified either of these shares since early 6.x days, so figured it was just bad conversion on upgrade as they havent been 'saved' since on unraid7... I edited my "Personal" share to have primary storage of Array with secondary storage of None. Now it shows nothing instead of the expected "Array": Looking at the flash/config/shares/*.cfg personal = just updated on unraid7 rc1 to fix 'array' only (now show as no name on shares page). music = still on legacy 'array' only (which wrongly now is 'cache' only) husky-diagnostics-20241211-1230.zip
-
on my backups, the flash drive is actually the largest thing... and its mainly because of "bzfirmware". I tried using global exclude and putting "bzfirmware" in there but no luck. Anyone know an a solution?
-
might be worth while creating your own form post for your version of the plugin mover to do a proper page of whats its features over squids (or hugenbdd even).. also can do proper support link in your plugin and so on. as it can easily get confused between versions since one doesnt upgrade the other they are just basically two same named plugins at the moment..
-
It was not, I had given up on your plugin and went back to hugenbdd/original version and did the symlink and its working fine.. so at some point I'm sure I'll try it out again but at this point it didn't seem like it was ready with all the active development and bugs.
-
updating to the latest version, it resolves the fatal error but does not move anything... to comment you are showing: Info: you may optionally install 'bc' from 'NerdTools' to have more precise size value IMHO: this should not be mentioned in logs, as nerdtools is not really recommended for unraid 7.x nor alive anymore. if you think bc should be included, just included with the plugin... or offer up an option to enable more precise sizes and blip on there about telling the user to go install bc. Then, your plugin has "Test Mode (dry run):" defaulting to yes.. and as this is buried middle way down in the options it makes it easy to miss (!it got me). I'd recommend moving this to the very top (or bottom like old plugin) or something for better visibility.
-
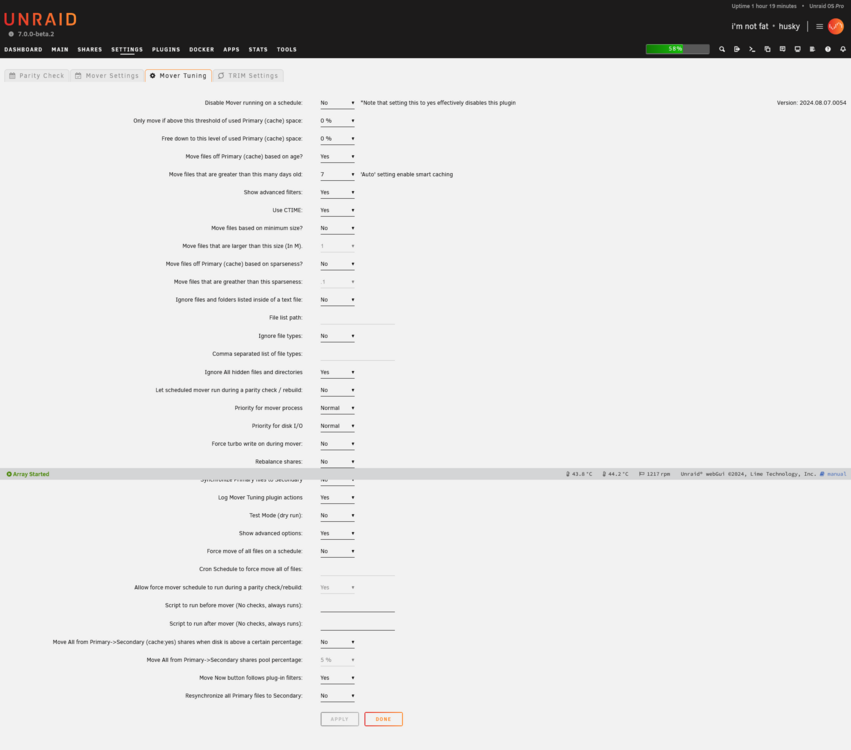
Went to try out Reynald version 2024.08.07.0054 now that I upgraded to unraid 7b2, however it errors: Fatal error: cache not enabled and less than 2 pools set up. Not sure why its saying that, I do have a cache pool (1 drive) and an array.
-
just ran into this myself unraid 6.12.10 on firefox 128 (no adblocker enabled) Firefox can’t establish a connection to the server at wss://192.168.0.100/sub/session,var,notify. cleared cache+cookies, logged back in.. still nothing. loaded up chrome 126.0.6478.127, worked fine. went back to firefox, seeing it spamming browser console that it cant get a wss going. then poof started working, refresh paged and all good now. odd indeed.







