




kingy444
Members
-
Joined
Everything posted by kingy444
-
When i get the issue again i can report that info - i have checked that personally (-l switch only) and confirmed owner was still listed not sure if this is related but a copy/paste of your post highlighted that the share in question (and .Recycle Bin) have my account listed as owner where the others have root or nobody listed. At first i thought this related to before moving to secure shares but a share post secure has nobody as owner
-
Just want to throw my two cents in here before disabling (work in IT so understand where you are going) Given we are currently looking at an unknown length of time before reoccurance with no known way to 'force' a reoccurrance is that the best course? When we were looking at 2-3 days between occurrances i do believe i already tried this (and had success) but this was much easier to gauge when we were talking 6-7 days to test. With the last occurrance occuring 21 days of uptime when do we call the test a success/failure? I believe excluding the share did help and my intial thought was it being related to recycle bin. Please let me know how you want me to proceed - I am just concerned we could remove it and wait 4-6 weeks. Then enable it and have to wait the same again. Thinking maybe look at doing that after getting the next set of diagnostics. if of use i have also attached some from my recent clean reboot One of the weird things i have with this (noting i am a windows guy) is that: \\unraid\share loses the the Owner \\unraid\cache\share Owner is present (and files can be deleted) So permissions appear fine - just the way the smb share is presented at the /mnt/user vs /mnt/cache appears to be an issue
-
I had held off rebooting as i wasnt sure if the machine being in a 'broken' state was of use. Originally the issue would reappear every 2-3 days but since replacing with the SSD the issue has taken roughtly 21 days to reappear (and didnt want to wait that long to provide something of use) Unfortunately i am not sure what the catalyst is (and this would go a log way to fixing the issue of course) so i have no way to 'force' the issue. I will do a reboot shortly - however as the hdd issue was obviously a red herring could you take a look at the diagnostics in the first post in this thread. Perhaps there is something there that was missed due to the hdd diagnosis
-
Thanks for your help to here @dlandon - unfortunately it doesnt appear to have been the issue I have removed cache1 and cache2 (wd black) with a new Samsung SSD 870 EVO (just a single cache drive atm) and changed to xfs from btrfs as part of this process It appears roughly 22 days of online in the issue has resurfaced and i cant see any SMART errors for the SSD in the logs Could you please take another look? EDIT: I noted the "refused mount request" too - cleared this now - this was related to a share i deleted and forgot about an active connection EDIT2: Want to highlight the issue only occurs on a cache only share and only when accessing via \\unraid\sharename and not via \\unraid\cache\sharename - makes me think there has to be something in the software here - and that the issue dissapears post samba restart would indicate the same to me
-
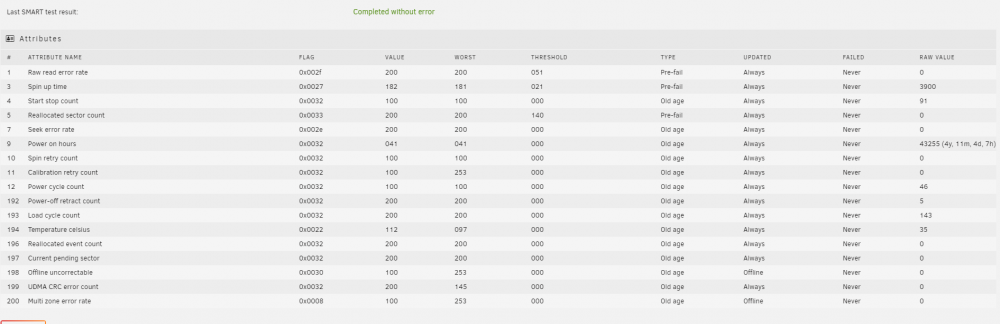
thanks - can see that now, i was just basing it off the web interface and didnt realise i could download a text report. The web is still saying no errors even though there are some in the report
-
thanks - i havent been able to force the issue - this was a diagnostic from the last occurance I did check the SMART report in the web but it said the disk passed all issues (and still does - see cache disk below) Why is the UI not showing there to be an error? cache2 has similar values im a little surprised i havent had any docker issues as that lives on those drives too
-
there is diagnostics in the first post too from before the encryption - here is another, hopefully the two combined help I dont currently have the issue - but this was a diagnostic i took when i was trying to work it out myself I am only using 1 user, theirs all have read only (no one actually uses them they all log on to the my pc anyway). The main and only user with access on this share has read/write access with SMB set to Secure and Auto case sensitive names I am wondering if it is somehow related to a bad drive but would love something to point there in a more concrete way then a stab in the dark before dropping $$ on a replacement simply to test. I did have a good period for a while (which i hated as i had no root cause) - then I recently had the log fill to which i found there was a likelyhood of a bad sata cable (cant remember the exact error but found errors on one of the cache drives via "btrfs dev stats -c /mnt/cache" Post fixing the above, scrubbing etc it was about a week later the issues occurred again for the first time in about a month
-
Hoping for some guidance (full context is here ) I have a weird issue relating to a cache-only drive where files are unable to be deleted - they rather lose permission to windows devices across the network (simultaneously) so all windows devices see the file as having no owner if i access the drive direct through cache\sharerather than the user share this problem doesnt exist (again full detail on above thread, trying not to spam here) I can also delete the file fine through linux shell through the share direct, cache\share is only required for windows i went the last 60 days without it, then needed to reboot for a different reason and had the issue within a few hours so i am now considering going back to 6.8.3 but have a seperate issue there too since moving to 6.9.2 i also encrpyted my drives and setup user accounts - will i have any issues rolling back now? Also wanting to see if there is anything i can provide here to help identify cause for such a weird bug.
-
Bumping this one - i would also be interested in getting webdriver working
-
if thats all the restart is doing then i agree it is going to be samba related - any idea who to tag here to get some assistance in core @dlandon?
-
@dlandon tagging you as it looks like you are the owner of the recycle bin plugin from here I believe i found the issue above and have been able to replicate, but not sure if you need any logs to help reslolve the issue. Details summarised below: After upgrading to 6.9.2 I also redid my shares, setting them to Secure and encrypted. I then started having strange issues where everynow and again my cache only share would start presenting an issue where Windows machines would not be able to recognise the owner of a file after a failed deletion attempt. Some screenshots on this above I downgraded to 6.8.3 and the issue was still present - i then realised that i had not excluded the new share from the recycle bin, after excluding the share the issue did not present itself so i thought i would try the upgrade again. After two days running 6.9.2 again i now have the issue presenting itself again (and the share is still excluded in the recycle bin) Havent been able to get much help on this one, not sure why the recycle bin would be having issues with a cache only share, and whether the issue is in the plugin or the core ? Really appreciate some input, I havent rebooted or anything yet incase you need specific information while the issue is present. I will need to downgrade to 6.8.3 again at some time too. I only appear to have the issue using user shares on a cache only drive, i havent experienced the issue on a drive that is part of the array - and as noted above the issue appears for all Window machines on the network (making me thing something with the core samba integration) - i can still delete the files if i browse directly to the same files using linux or samba to the cache drive directly (more on that above) Note currently running 2021.10.27 of the plugin EDIT: I have just tested and selecting 'restart' in Recycle Bin Settings has also resolved the issue (temporarily i assume) so a full reboot was not required, but would definitely make me lean more towards the issue being with the plugin
-
This is a screenshot of the same files in \\unraid\share and \\unraid\cache\share at the same time. You can see in \\unraid\share that the Owner is missing You can see in \\unraid\cache\share that the Owner is present The fact the owner is missing prevents the file from being deleted. But what happens (when the issue is present) is the file has an Owner, you delete it, it dissappears for about 10 seconds, then comes back with no owner I dont share \\unraid\cache normally but did as part of my troubleshooting here as i could still see the Owner on the files in unraid shell. TLDR: But your point is exactly mine. These are the same files. So something is happening to make \\unraid\share forget the Owner of the files until samba restarts
-
So i downgraded to 6.8.3 and after just over 5 days of uptime the issue has returned so it is not related I can still write to the nas during the time of the issue - but cannot delete files Really appreciate any help - my assumption is it may be related to the cahce drive now being encrypted as i didnt have the issue before and only happens on Windows Hosts (but all windows hosts on the network at the same time) so must somehow be related to the samba conf edit: After posting i thought i would try setting the share to not use the recycle bin - not sure if that is the issue but didnt want to sit around doing nothing As soon as i excluded the share windows hosts could see the owner again - appreciate any other advice people can provide as i am not sure this will be a permanent resolution
-
mmmm - wonder if i could be experiencing a similar bug with samba I am running much older intel kit on an i3-3220 but started having weird stabiity recently - just posted this and waiting for some feedback
-
Thought i would add that the issue is not linked to the windows host - all windows machines on the network experience the same issues at the same time I do have the option to downgrade to 6.8.3 but just seeking some advice before doing so as everything was solid before and unsure if related to securing shares or the upgrade Same files in \\unraid\share vs \\unraid\cache\share
-
I recently upgraded to 6.9.2 just before initiating the below so not sure if issue would have been present on previous versions After upgrading to 6.9.2 i cleared my cache and array and started to use BTRFS encryption for cache pool and XFS encryption for the array, in addition i started using Secure instead of public shares. Prior to this i had no issues and all files would be owned by 'nobody'. I have noticed on 3 seperate occassions now an issue where my SMB connection from Windows is causing an issue where when i delete a file rather than deleting the file the file stays but loses its 'owner' as far as Windows is concerned. (note i mean actually blank and not be set to nobody) - No error is received the file just reappears with no owner Checking the file in UNRAID shell you can see the file still has its owner etc - but further attempts to delete the file from windows will be prevented due to no owner. On the first occassion i rebooted the server and everything came good On the second occassion i browsed to the \\UNRAID\cache\share rather than \\UNRAID\share and could successfully delete files i cannot delete from \\UNRAID\share. I then renamed the share in the UI (for like 10 seconds) then named it back and could again delete files from \\UNRAID\share I am now on the third occassion and again tested successfully deleting from \\UNRAID\cache\share and that \\UNRAID\share results in files losing ownership instead. I have not rebooted or renamed incase there is something i should do while the system is still broken This only appears to be affecting the share i have set to "Cache: Only" - i can delete from other shares atm
-
Definitely clears that up, obviously a useful feature. Any recommendations on 'rebalancing'... sounds like that might be another enhancement at another time? Any suggestions to speed up manually doing this?
-
Just after some direction here, and what im looking for might be the gather function but im not sure what exactly that is planned to provide. Basically i have just moved all my data using unbalance in order to move from reinfs to xfs, now i have one completely empty disk. I would like to distribute the data on the other disks to this one, so that i end up with all drives having relatively the same amount of free space. Whats the besr way to accomplish this?
-
apologies mate. i must not have hit reply - it was a browser thing. Working fine in IE EDGE. Cleared cache in Chrome and its working again Thanks for the help
-
no dice same thing. any other suggestions?
-
Have done that actually since posting. No difference.
-
attached. thanks for your help unraid-diagnostics-20170713-1251.zip
-
thanks. so i emptied now. but the page at http://10.0.0.21/Settings/RecycleBin is just spinning and chrome is doing the not responding wait thing. any idea why it would be doing that and how to fix it? the bin is empty so i would expect it to relatively quick with nothing to compute?
-
I am trying to clear my recycle bin after deleting some data i now have a problem where the recycle bin GUI isn't even opening. The page just keeps spinning and asking if I want to wait for the unresponsive page any advice on how to clear the recycle bin and expedite the process as the GUI won't load ?
