




apandey
Members
-
Joined
-
Last visited
Everything posted by apandey
-
i created partitions on sdv using sgdisk and did replace as above. its resilvering now
-
same result after reboot, it is still somehow trying to run wipefs on /dev/sdo I had 2 slots empty on my server (hot swap drive bays). What I did was I plugged in the new drive, it showed up under unassigned drives I stopped the array. changed the drive next to zdata 5 with the new drive rebooted and started the array. drive in slot 8 showed red mark, but i found it showing online in zpool status command How should I do manual replacement? would it be zpool replace zdata /dev/sdq /dev/sdv
-
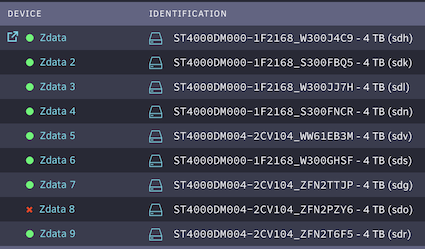
the new drive is showing as sdv, so I am not sure why it tied to run wipefs on sdo sdo is the exiting drive from the pool in slot 8 (which is showing a red cross). I did not touch it, yet it is somehow in play slot 5 is the new drive, it showing as sdv. the drive before replacement in slot 5 was showing sdq I did not touch slot 8, that was and is sdo, and became red after I started array after replace zpool status is showing this # zpool status -xv pool: zdata state: DEGRADED status: One or more devices could not be used because the label is missing or invalid. Sufficient replicas exist for the pool to continue functioning in a degraded state. action: Replace the device using 'zpool replace'. see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-4J scan: scrub repaired 0B in 02:36:08 with 0 errors on Tue Oct 3 09:36:09 2023 config: NAME STATE READ WRITE CKSUM zdata DEGRADED 0 0 0 raidz2-0 DEGRADED 0 0 0 sdk ONLINE 0 0 0 sds ONLINE 0 0 0 sdl ONLINE 0 0 0 sdo ONLINE 0 0 0 sdg ONLINE 0 0 0 sdn ONLINE 0 0 0 sdh ONLINE 0 0 0 10871034331009088735 UNAVAIL 0 0 0 was /dev/sdq1 sdr ONLINE 0 0 0 notice the ordering difference (missing drive is same position as the red drive in UI, but sdo is showing elsewhere in 4th slot. sdv is nowhere) I will run wipefs on sdv and see what happens
-
One of my drive in zfs rzidz2 pool started throwing increasing number of pending sectors, so I decided to replace it I followed the instructions here: basically stopped array, changed the bad drive in dropdown with new one and started array Unlike the instructions, I don't see replace happening automatically. status shows the following status: One or more devices could not be used because the label is missing or invalid. Sufficient replicas exist for the pool to continue functioning in a degraded state. I also noticed another issue. The failing drive was zdata5, and that slot now shows the new drive ID However, zdata8, a different drive which seems healthy is showing a red cross next to it with message "device is disabled, contents emulated" In the zfs pool status, there is this in the 8th row 10871034331009088735 UNAVAIL 0 0 0 was /dev/sdq1 but, sdq was the previous identifier for the failed drive (it shows unassigned now) and it was in slot 5 before. The drive in slot 8 is sdo which shows online in zfs status. Is this just a UI glitch? Anyway, how should I proceed? do I need to run the replace command, or something else has gone wrong? Diags attached godaam-diagnostics-20231011-2146.zip
-
How do you know the hba is overheating? I have the same one, and I don't think it has a temperature sensor. If it's just crc errors, it may just be cables. SATA cables and connectors unfortunately are one of the worst when it comes to pc connectivity, and even a bit of unsettling with vibrations or other activity can dislodge or wear them out
-
scrub finished and corrected all verify + csum errors. thanks for pointers
-
I have switched the affected drive to the other motherboard SATA controller, so far so good started a scrub on the tsdb pool, and its reporting some errors. I did not check the fix errors Scrub started: Sat Jun 24 11:12:36 2023 Status: running Duration: 0:13:38 Time left: 3:06:22 ETA: Sat Jun 24 14:32:36 2023 Total to scrub: 2.48TiB Bytes scrubbed: 173.21GiB (6.82%) Rate: 216.83MiB/s Error summary: verify=2 csum=120266 Corrected: 0 Uncorrectable: 0 Unverified: 0 how do I go about fixing the errors? should I run with fix errors checkbox? need to wait for initial scrube to finish, or just cancel and do the fix steps? EDIT: started a correcting scrub
-
arrrrgggh. sorry, and thanks for spotting this. I mistakenly moved the other 2TB drive to the LSI controller. no wonder the crc errors didn't stop. I have a spare port on the motherboard SATA, so will rewire to that and report back
-
OK, I will swap things out once the current parity check finishes. I have also increased the shutdown timeout in disk settings for now to avoid this for next shutdown I did move the drive from motherboard SATA to my LSI controller when the crc errors first showed up. The drive bays use different cables too. I will also examine the drive side connectors this time when I swap it. I have one more spare slot where I can try to put the disk If this continues, is there a way I can downgrade tsdb to a single drive pool temporarily? would like to take the disk out and test it outside the system if swapping cables etc doesnt work
-
nice. I didn't know a diag is automatically saved in such a case. Attached the one from shutdown. seems the troubled btrfs pool drive had problems unmounting diags attached godaam-diagnostics-20230623-1255.zip I am still not clear why this should mark the array dirty. a bit scary if issues with a cache pool would affect array operations so what should be my next steps? I am not very familiar with btrfs recovery. I ran a scrub before reboot and it seemed OK, not sure how I see the same issue that the logs see. If the disk needs replacing, how do I replace it?
-
I was getting crc count error warnings for one of my disks (sdi in attached diagnostics), so I was moving it around to different drive bays (so as to use different SATA ports and cables), but somehow its always the same disk which seems to show CRC errors. Nothing was wrong with data / filesystems during this, except for the latest reboot. After the reboot, a parity check started automatically 1. can I know what caused this? I assume unclean shutdown, timeout on something exceeded, but I can't see what 2. the trouble disk was on a btrfs pool of 2 HDDs. Why did the array get affected? 3. Anything else I am missing? is there another underlying issue I upgraded from 6.11.5 to 6.12.1 yesterday, and it went smooth including importing a zfs pool. I don't believe this is probably the culprit, but still worth a mention the log is full of disk errors, but I cannot pinpoint which disk. I am assuming sdi based on creeping CRC errors diagnostics attached godaam-diagnostics-20230623-1312.zip
-
The specifications say: Interface: SATA to SATA, SAS to SAS Data Connector: SATA / SAS 6G Data Port x 5 https://www.sg-norco.com/pdfs/SS-500_5_bay_Hot_Swap_Module.pdf It says 6G, but I doubt it matters. see below the cable is simply pass through. The SAS controller decides what protocol to speak to the drives (SATA vs SAS) depending on what is connected. Since a SATA controller cannot speak SAS protocol, SAS drives have an extra plastic piece on the connector that blocks a SATA connector to be plugged in. But besides that, the cables don’t matter as long as they are rated for the throughput Ideally, you would want a SAS to SAS breakout cable. Practically, SAS backplanes would be SAS to SAS without any breakout involved The norco case, seems the ports will take both connectors and simply pass-through, so it really just depends on the controller. In theory, this will allow connecting simple SATA controller to SAS drives physically, but that will not work since the controller will fail to talk to any connected SAS drive. A SAS controller should work OK Note that it is not recommended to mix SATA and SAS on same controller / backplane Coming to practical implications, I think you are worrying about nothing. None of the drives you have can saturate 6G bandwidth, forget about 12G. Those ratings only come into picture when using SAS expanders where multiple drives have to share that 12G bandwidth
-
Yes, as long as the interface on the sata end can do 12gbps. SATA 3.2 can do up to 16gbps, but very few devices support more than 6gbps. Also, 12gbps sata drives are rare and expensive. The world has moved to pci express for faster storage I think this enclosure is only rated for 6gbps
-
You need to use the mount point for btrfs, so /mnt/cache if pool, or /mnt/diskX if array drive
-
Parity drive SMART status is bad SMART Health Status: FAILURE PREDICTION THRESHOLD EXCEEDED: ascq=0xfd [asc=5d, ascq=fd] Usually this means the drive firmware is expecting the drive to fail imminently based on its own monitoring. I would replace that drive
-
If you plan to use zfs, it would be handy to configure some RAM as cache You can use cache dirs plugin to speed up dir listings (and avoid unnecessary disk access), though I doubt it needs a lot of ram If you work with any transient data, you can create a ram disk, though this use case is more useful with apps then a basic NAS use case Linux anyway uses extra ram for IO buffers and caching, so if you happen to load same data repeatedly, spare RAM will help even when you don't see it being used explicitly In the end, don't sweat it too much. Spare RAM is good for a server, definitely better than running with very small headroom. 16GB is not too large to worry about
-
ZFS is better, but it's also a RC implementation in unraid, so at this point, you may run into caveats still showing up in RC threads. Specifically, zfs can do raidz levels reliably as compared to btrfs. Also has better bitrot protection Snapshots only help with fat finger scenarios, they are not true backups at hardware level. If you lose your pool, snapshots go with it. But, yes, they can help with certain human mistakes
-
This is pure FUD. Nothing wrong with running your own infra and having full control on your data, but you are misrepresenting things here. Here is what Google Drive terms say: "You retain ownership of any intellectual property rights that you hold in that content. In short, what belongs to you stays yours" https://support.google.com/drive/answer/2450387?hl=en I personally use backblaze as my off-site backup, which of course is purely storage on rental, since everything there gets encrypted with my own key. This is in addition to 2 local backups (one on unraid). I do this because I truly care about my photos and know that I am not the best running infrastructure and might end up losing data if all I had was my own storage infra to hold them
-
home.arpa is not a public TLD, so you need to use a self signed certificate. Since you are signing your own, you need to add the root signing cert to trust store of clients (which should all be under your own control inside the home network). The verification will work fine, and serves the trust chain as designed If you use a public domain, you can get a public trust certificate from any of the issuers, this is what I do If the connection is unencrypted, none of this matters
-
Where is your unifi controller running? I have a feeling something is wrong with your unifi network. Taking unraid off the network, does the rest of your network work well? Can you ping the gateway at that point. If not, you should fix that first
-
Do you see 10.0.0.1 assigned to any interface in unraid network, docker or VM settings? What is Vader, is it the name of your unraid server? Have you tried finding what the MAC address listed next to Vader in your first screenshot corresponds to? What acts as your dhcp server? Is that unifi? Check the configured dhcp ip allocation range as suggested Does the USG come back online if you unplug unraid from the network? Docker using unraid IP is OK, your problem is not that IP. Need to find out what 10.0.0.1 is assigned to
-
I have seen similar reports before. What do you see in parity history? If you haven't rebooted since parity check ran, post diagnostics
-
I can confirm that zfs_get_pool_data.lua is what spins up the pool for me. I'll have to probably spend a bit more time to deconstruct it and find the exact step that is the culprit, and see if any caching configuration can help. listing datasets and snapshots with zfs command does not spin up the pool for me
-
Generally, LSI cards are well supported. There is a list and some recommendations here: https://wiki.unraid.net/Hardware_Compatibility#PCI_SATA_Controllers There is also a thread here to talk about more recent updates to the list
-
please post diagnostics. would also help if you could tell one share which is having this issue


