




PhilBarker
Members
-
Joined
-
Last visited
Everything posted by PhilBarker
-
Just to answer this here as I found it in a google search - you now can with 7.3.0 dedicated boot pool - uses entire disk I'm migrating mine now from usb to a 16gb Intel Optane 🤞
-
Thanks Jorge Power Supply Idle Control - for some reason just doesn't exist on my X570 board Disabling global c-states 100% seems to fix it but it's just weird for me that they've been on for like 3+ years with no issues and now they cause crashing I did read about increasing ryzen voltage TBH with you I'm very tempted to swap the board and CPU out for an intel setup - ryzen on linux just seems a bit meh - and if I'm gonna do a board swap it makes sense to do it now before I switch to TPM licensing and internal boot Thanks ☺️
-
I've been dealing with issues for about a week with my unraid server It's a ryzen based system - 5600G on an X570 motherboard It randomly reboots (often in the middle of the night) and sometimes locks up halfway through the reboot or locks up during the day After doing a LOT of troubleshooting (including an overnight memtest which passed fine), it appears to be global C-States - after disabling them in bios the server stayed up for 3 days with zero issues, I then re-enabled them and it reset on the first night I was originally on 7.2.5 - tried upgrading to 7.3.0 - tried updating motherboard BIOS - none of which made any difference I've attached diagnostics but they don't show much as the syslog is just happily doing it's thing then reboot out of nowhere For now I've disabled global c-states again to get stability but I'm really intrigued why this is a thing now - my server's been running for years with perfect stability then about a week ago this started - no hardware changes at all - the only thing that happened is a power cut, my UPS kicked in but due to a degraded battery cut out before the full shutdown had occured so I had one unclean shutdown then for the following 3 days constant reboots and lock ups. Would be interested if anyone has any thoughts or similar issues? jarvis-diagnostics-20260518-0755.zip
-
The nvidia exporter - doesn't seem to export power usage properly It's always 0w Yet if I run : nvidia-smi --query-gpu=power.draw --format=csv I get : power.draw [W] 49.52 W Is this a limitation of the exporter? I have a GTX 1660ti EDIT: I have been able to bypass this by running the nvidia dcgm-exporter alongside this plugin and switching my grafana dashboard power usage graph to use DCGM_FI_DEV_POWER_USAGE
-
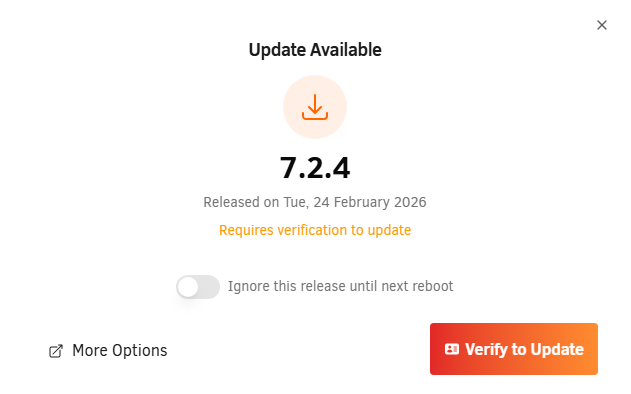
Just out of curiosity - I've never seen the "Requires verification to update" or the "Verify to Update" button before? Is that a 7.2.3 change? I probably just missed an update, I just get a bit paranoid when the process changes 🤣
-
I wasn’t manually adding it. I was using the dropdown It was 100% rebuild-dndc. It worked fine for years but now when it rebuilds a container Unraid loses track and thinks it’s 3rd party Not had the issue at all since moving to a different VPN stack
-
Thanks. I didn't think I'd need this as everything seemed to be fine - but a week or so later all the child containers started returning bad gateway - had to restart them all by hand I've added the autoheal container now 😊
-
So far switching to Gluetun and away from the binhex containers - no longer using Rebuild-DNDC - has been bullet proof, and as a nice side effect a LOT more responsive 👍
-
The templates are 100% still there - to "fix" them I just add container, choose template, it restarts the container - no longer shown as 3rd party I don't user docker compose - all were added through Apps It's very weird because this setup has been running for 4+ years now and never an issue. However, I've been meaning to get off the binhex- containers for a while because they take minutes to startup hanging on deleting from /tmp every time so this afternoon I've switched to gluetunvpn and migrated all the binhex containers to linuxserver ones - much faster setup. I'm going to keep Rebuild-DNDC turned off and see if this stays stable
-
Hey all, I’m trying to work out whether I’m hitting a weird edge case or if this is something others are seeing in Unraid 7.2.x. SetupUnraid 7.2.3 binhex-qbittorrentvpn binhex Sonarr / Radarr / Prowlarr / Lidarr / Flaresolverr + Bazarr All child containers use: --net=container:binhex-qbittorrentvpnRebuild-DNDC at the bottom of the startup order, running on bridge network This setup has been rock solid for a long time. What’s happeningAfter a VPN/network event, all containers using --net=container:binhex-qbittorrentvpn suddenly show up as “3rd party” in the Docker UI: No Edit button Can’t update them Containers themselves are running fine Only way to recover is to recreate them from the existing user templates This has now happened twice within 24 hours. What I’ve found so farLooking at the Rebuild-DNDC logs, this happens whenever the VPN container’s Docker endpoint ID changes. Rebuild-DNDC then (correctly) rebuilds all dependent containers. Example from the log: MASTER container ENDPOINTID DOESN'T MATCH REBUILDING: binhex-qbittorrentvpn The rebuild uses normal docker run commands with the same names, paths, and configs — everything works — but Unraid then treats those containers as permanently “3rd party”. Rebuild-DNDC questionI’ve seen a few comments suggesting Rebuild-DNDC isn’t needed anymore in 7.2.x because Unraid will restart child containers automatically? I tried disabling it for a week test this, but when the VPN container restarted, all child containers lost connectivity and never recovered until manually restarted. So at least in my setup, Rebuild-DNDC still seems necessary. Curious if others are seeing thisAnyone else using binhex-qbittorrentvpn + --net=container: seeing containers flip to 3rd party? Is this new behaviour in 7.2.x? Has anyone found a way to prevent Unraid losing track of these containers? Happy to share logs if helpful.
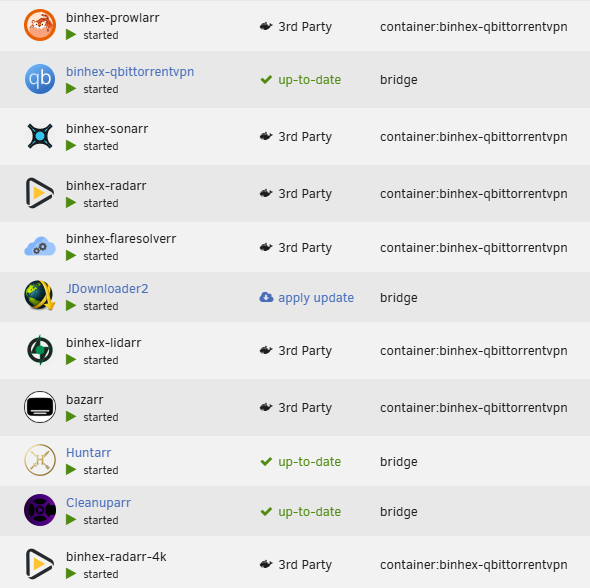
-
Thank you! That makes a lot of sense - when I added it through CA, it kept disappearing, so I kept re-adding it through CA But the last time it disappeared I did what you suggest, add container button, selected the template Since then it hasn't disappeared, I just hadn't put 2 and 2 together
-
Thanks Yeah they’re named different. I can’t think it’s related to run order because there’s simply no log for it even attempting to start But I’ll sort run order out first and keep an eye on it
-
I run 2 instances of binhex-radarr - one for my 1080p library, one for my 4k library I can't seem to make it stable - every time I reboot the server it only starts one instance, the other is lost entirely from the Docker view I've checked the xml files and both exist, can't see anything in the logs Asking chatGPT it did suggest there can be issues with containers that connect to other container networks - all of my radar/sonarr etc.. instances connect to the binhex-qbittorrentvpn container to route any internet traffic through VPN - I can see when the array starts a bunch of "Error response from daemon: cannot join network of a non running container" - I don't think this is the route cause though as other containers start up fine, my 2nd radarr instance completely vanishes and I have to add it again from the .xml file I have set "allow install of second instance" to Yes in community applications - I can't see any UI change though, not sure what this actually does Are there any "best practice" guides for running multiple instances of the same docker image?
-
I just attempted this because I've had a neighbour dispute and I wanted to dump the last week of footage from 2 cameras to my unraid NAS for long term storage It just kept creating .partial files over and over like it was stuck in a loop [global] server min protocol = SMB2 server max protocol = SMB3This seems to have done the trick now. The export on unifi is very slow, takes about 5-10 minutes for each 1 hour chunk to "Prepare" but I haven't had a failed .partial since I made that change so just letting it churn through I know this is digging up an old thread, but thank you ☺️
-
Ahh ok thanks, hadn't thought of that I've set it up through Usb Manager for the time being, but will get a PCIe usb carrd
-
I have a home assistant VM which I pass a broadcom bluetooth usb receiver and a zigbee usb controller through They're both selected in the VM and not optional - however most times the VM starts the bluetooth adapter isn't passed through I can go into the VMs tab and attach it using the hotplug - which works for a while then next day I'll look and it's disconnected again I couldn't find anything relevant searching google/this forum. Is there anything I can look into to work out why this is happening? Thanks

-
🤣 I came here looking to see if it had been reported - as I can't change the settings unless I zoom all the way out Guess I'll just keep working around the feature 😅
-
Just wanted to follow up to say - failed disk rebuilt with zero issues. Parity check done, now swapping out one of the other WD Red drives.... will do the last one in a few weeks - they're all off in the bin now 🙂
-
Thank you kind sir, just wanted a bit of confirmation ❤️
-
I have an array with 5 x 6tb disks in it Unfortunately 4 of them are the Western Digital Red's that later got confirmed as being SMR, and they're pretty rubbish. My plan was to cycle them out but my Parity is also 6tb so wanted to wait till I could afford some bigger drives Today one of the disks is dead - 1292 read errors then went offline, so is currently being emulated I've read https://forums.unraid.net/topic/187777-replace-dead-disc-new-larger-than-parity/ and believe the Parity Swap process will work for my situation. My understanding is - Power down server - Remove the dead drive (it's already disabled in the array) - Install the new 12TB Parity drive - Power on the server - with array stopped - Pre-clean new 12TB Parity drive - Unassign the current 6TB Parity drive - Assign the new 12TB Parity drive - Assign the old 6 tb Parity drive to Disk 1 (the failed disk) At this point Main -> Array Options should show me a copy function, which will copy the old parity drive to the new parity drive This will take several hours, once complete I can start the array and the OLD parity drive now in Disk 1 slot will be rebuilt I know this is all documented in the Parity Swap process but it's a "bit scary" copying the parity to a new disk and replacing a dead disk at the same time, not a process I've done before and was just looking for some reassurance that it's correct 🙂
-
I should have led with that sorry I have notifications for mover turned off, but still get them Send notifications for mover or backup running: No Send notifications for Pause or Resume of increments: Yes I do want to be notified when the the job is paused due to schedule, and when the job restarts - I just don't want to be notified every time mover finishes and the job doesn't restart because of schedule. I guess I could turn off the option to pause operation whilst mover is running, but it seems like that could cause a lot of load on the disks. It's not a huge issue as I only get alert spam once a month, but seems like that particular notification doesn't fit within the "Pause or Resume" category?
-
Same issue here But additionally - I've changed mover schedule to run every hour (I previously had it run once a day but was running low on cache space) and now I get a [...] Array operation not resumed - outside increment window alert every hour It seems every time the mover stops, it checks to see if it can start the parity check and then sends an alert to say it isn't because it's outside of the parity check schedule... not particularly a helpful alert to be receiving on my phone every hour
-
V6 UPDATE The author of Orbital-Sync has decided not to continue development. An alternative is available for pihole v6+ - nebula sync https://github.com/lovelaze/nebula-sync/ I have switched over and confirmed it works perfectly. If you're staying on V5 then this will continue to work, but for V6+ I'd suggest switching to nebula sync which is already available in the community apps
-
For those not checking the github issues - V6 support on orbital sync is in master - it's not released yet as they're missing a few features but they've announced it should be within a week or so
-
Yes this forum thread is just for support of the unraid package to install orbital sync orbital sync itself doesn’t support pihole v6 yet but looking at the GitHub ticket they are working on it




