




MarcelCliff
Members
-
Joined
-
Last visited
-
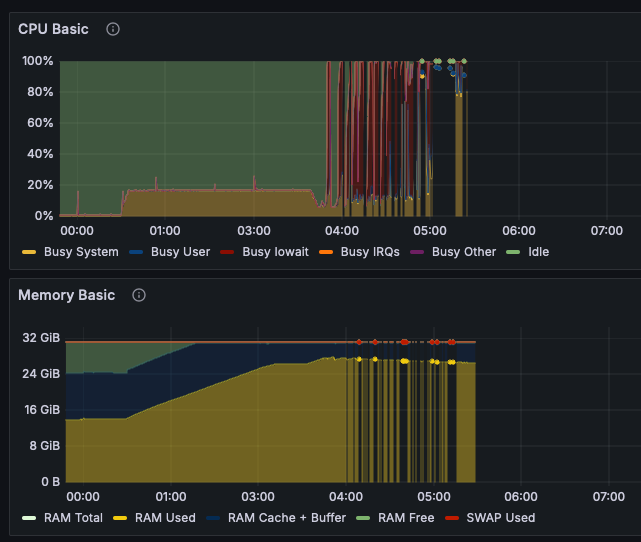
Hi, tonight my Unraid server version 6.12.8 crashed, and I had to hard reset it to get it to work again. Uptime Kuma, running on another system, started to report issues with the first Docker service at around 3:57 AM, continuing until 7:15 AM when every service was unreachable. My backup script which is supposed to run at 6 AM, that would restart all containers, was also not successful. At 8:30 AM I checked the server and saw that the WebUI was not reachable, neither was server reachable via SSH. Only a hard reboot by holding down the power button resolved the issue. I attached the diagnostics from after the reboot, and the syslog file which was written during the crash. Note: Tonight was also the switch to DST, which is why there are no logs from 2 AM to 3 AM. This is what Prometheus recorded tonight: Any idea what caused this crash and how I can avoid a crash like that in the future? gandalf-diagnostics-20240331-0912.zip syslog-2024-03-31.log
-
Do you think that rebuilding is better than moving the files off of the emulated disk 1? Not sure if I can trust Disk 1 or the controller if the reported size suddenly changed. Edit: Rebuild is running now.
-
I checked some files on the emulated disk and they seem okay. Here is the new diagnostics file.gandalf-diagnostics-20230912-1732.zipgandalf-diagnostics-20230912-1732.zip
-
I'm not sure what you mean by that. If I understand you correctly I should do the following: 1. Start the array with Disk 1 disabled 2. Check if files on (emulated) Disk 1 is readable 3. Stop the Array 4. Assign the same disk to the first Disk's slot 5. Start the Array 6. Wait for the rebuild to complete. Is this correct?
-
No, I did not touch the hardware. The last thing I did before stopping the array was moving ~7TB to Disk 1 which was newly formatted as zfs.
-
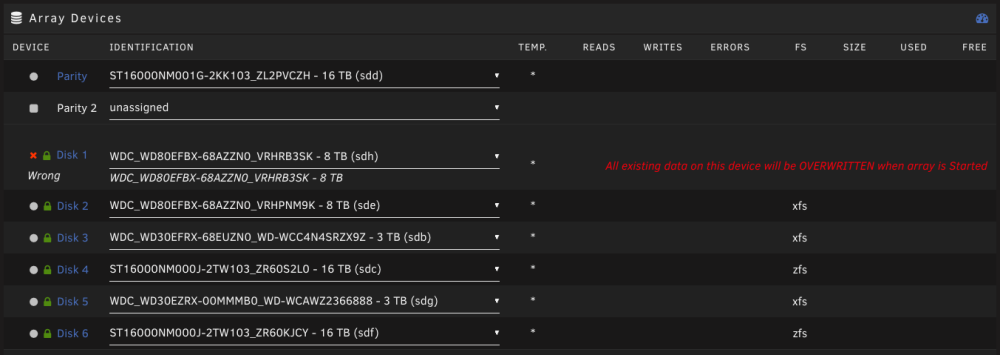
Hi, I stopped my array this morning and I'm now getting this error message: All existing data on this device will be OVERWRITTEN when array is Started Disk 1 is seen as a replacement disk by unraid, which is not correct. No disk was changed. Additionally this disk shows a high number of UDMA CRC errors. I'm not sure if these errors were already there yesterday, but Unraid did send a notification about these, after shutting down the array. While UDMA CRC error count often means that the SATA cable is defect this won't help me with the error message that the data will be overwritten, right? Edit: I just checked, and the UDMA CRC error count was the same in January, therefore I don't think that this is an issue. What should be my course of action? If the drive is really defect, I don't want to replace it, because I've got enough space left on the other drives, should I proceed like that? 1. Unassign Disk 1 2. Copy the emulated data from Disk 1 to somewhere else 3. Create a new config without Disk 1, and rebuild Parity. If the drive is not defect (which is what I currently assume), I should be able to just start the array and the same data would be rebuild on Disk 1, without any data loss, right? gandalf-diagnostics-20230912-0947.zip
-
Leider helfen alle 3 Optionen nicht.
-
Hab einen macOS Client. Neustart hat nichts geholfen. Auch force group = root hilft nicht. Ich kann auf dem share Dateien erstellen, diese sind dann aber direkt nicht mehr lesbar und auch nicht mehr schreibbar. Dann werde ich wohl weiterhin die Scripte per sshfs als root mounten und damit bearbeiten.
-
Ich habe mir das eben auch eingerichtet (natürlich mit meinem eigenen user bei valid user und write list). Jedoch habe ich weder Lese- noch Schreibberechtigung auf dem share. Die Linux Rechte in diesem Verzeichnis sind 700 root:root. Habe versucht diese als root anzupassen aber weder chmod noch chown funktionieren auf diesen Verzeichnissen. chown: changing ownership of 'Backup': Operation not permitted
-
Danke für den link @saber1 Dann werde ich meine checks wohl auch auf non-correcting umstellen.
-
Ich bin auch der Meinung, dass regelmäßige Parity Checks gemacht werden sollten. Bei mir sind sie auf alle 2 Monate gescheduled. Cumulative parity checks nutze ich, damit die checks nur Nachts laufen. Bei mir hauptsächlich aus Lautstärkegründen. Anders als @DataCollector habe ich "write corrections to parity disk" aktiviert. Wenn eine Korrektur nötig ist, habe ich kaum Möglichkeiten herauszufinden, ob die Parity oder die Daten nicht mehr korrekt sind. Also kann die Parity auch direkt repariert werden und zur Not muss ich mich eben auf mein Backup verlassen.
-
I reported the issue to AVM. Their support response wasn't really helpful. However, I also reported the issue including diagnostic data through the Fritzbox UI of the beta firmware I was using. I've never received an answer for this report, but the issue is fixed now. I guess an automatic firmware upgrade resolved it. Unfortunately, I wasn't monitoring the issue close enough to prove this.
-
I had the same issue, and this seems to solve it for me as well.
-
I did set up my backup strategy in the last couple of days, and had the same thoughts that you're having. As a rough strategy I went with your second option, but with some specifics: Container configurations Wherever possible, I try to use the backup functionality build into the application running in the container. For paperless this is a scheduled user script running: docker exec -i paperless-ngx document_exporter ../export --use-filename-format --delete this exports all the documents including the tags and the metadata to a share which is mounted as /export into the container. See the documentation for more details. For other tools I'm mostly using the webGUI provided backup schedules, backing up to a backups share. This step is not strictly necessary, because I also backup the appdata share. However, especially for paperless, I do want all the documents in a readable format in my backup. Appdata backups As not all tools in the containers provide a native backup functionality I additionally backup the appdata share using yet another user script, which stops all containers, rsyncs /mnt/user/appdata to a backups share and afterward restarts the containers. I didn't want to use the Appdata Backup/Restore v3 plugin, as it didn't provide me with all the functionality I required, but you may as well just use it. The important part is, that you should stop your containers, before backing up, and in case of any issues send a notification to unRAID which then can send you an email or any other notification (the plugin does all of that for you). Flash backups I'm using this script: If you're ok with the data from the flash drive being stored unencrypted on unRAID's servers, you can also use the MyServers plugin. Share backups I backup all my "backup-worthy" shares (including the previously mentioned "backups" share), using restic to Backblaze B2. Restic comes as a single binary which I just download using wget, when needed. From your list, and if you prefer a GUI I tested Duplicacy, and it worked quite well. For me, the most important thing was that the whole backup process is automated and scheduled, otherwise I cannot be sure that a backup is up-to-date when I really need it. In your case you'd need to open up e.g. Duplicacy and start the backups manually after connecting your external drive.
-
After installing the Intel I225-V NIC, I see the same issue. I now also tested the connection between my WiFi Macbook and a wired PC -> same issue. I'm quite sure now that the issue is caused by my Router.



