




SBH
Members
-
Joined
-
Last visited
Everything posted by SBH
-
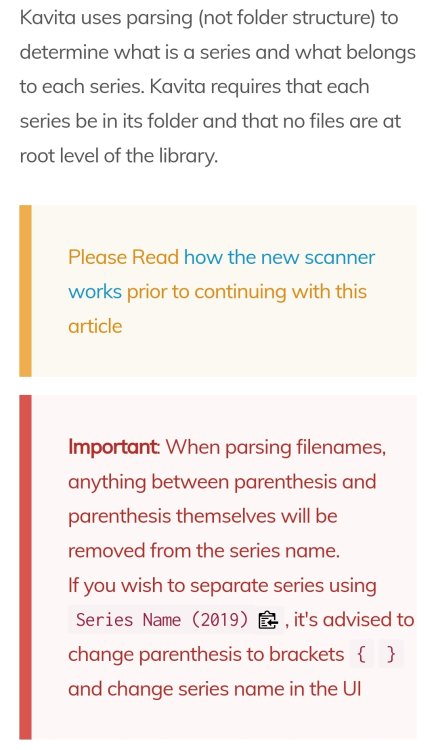
For the case that someone need to do the same. With following command you will get an order for each .epub element. Please make Sure that the folder is correct. When you have other Elements, you have to change .epub to your element type find /mnt/user/ebooks/Books -name "*.epub" -exec sh -c 'mkdir "${1%.*}" && mv "$1" "${1%.*}"' _ {} \;
-
I think, I got it. I need folders. Currently all data in one folder. No action required from your side. I have to check this first It works now. Minimum one folder is required in the root
-
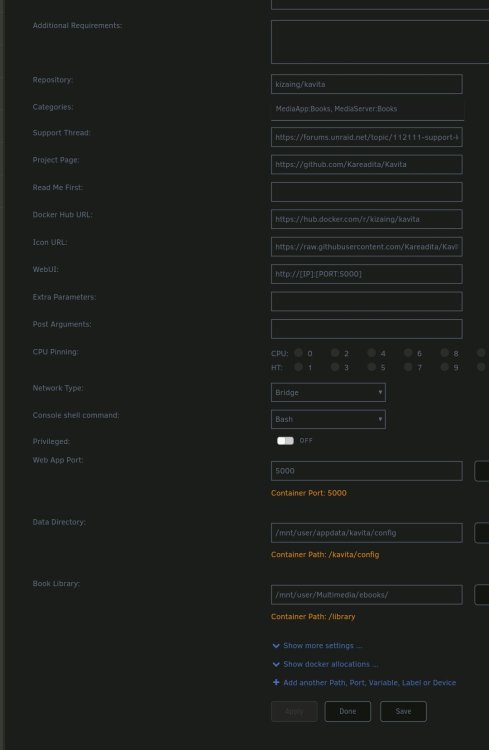
Good day to you. I'm new with unraid and installed the docker. I understood anything wrong. Is the script also required when the docker will installed via App Center? I installed it via App Center and set the folders via edit Docker. WebGui works fine and I see my Folder Library in the Web. I created a Library but scanning don't found anything. Could you please try to help Thanks a lot
-
Mir hatte dieser Post extrem geholfen, um zu verstehen, was überhaupt alles gemacht werden muss. Kannst ja mal als Selbstkontrolle durchgehen und dann Feedback an alturismo und ich777 senden
-
Thanks again for info
-
I thought, that it should be equal with recommendation of NVIDIA. Thanks for this input, I was really thought about to using GPU for HW Transcoding and the iGPU for a small VM. In this case, I will switch. My iGPU is performing well for the HW Transcoding. Thanks for the support
-
I installed a gainward gtx650ti GPU On gainward site driver is referred to NVIDIA page. There is this driver noted for this GPU. I'm on Version: 6.11.5 tower-diagnostics-20230124-1750.zip
-
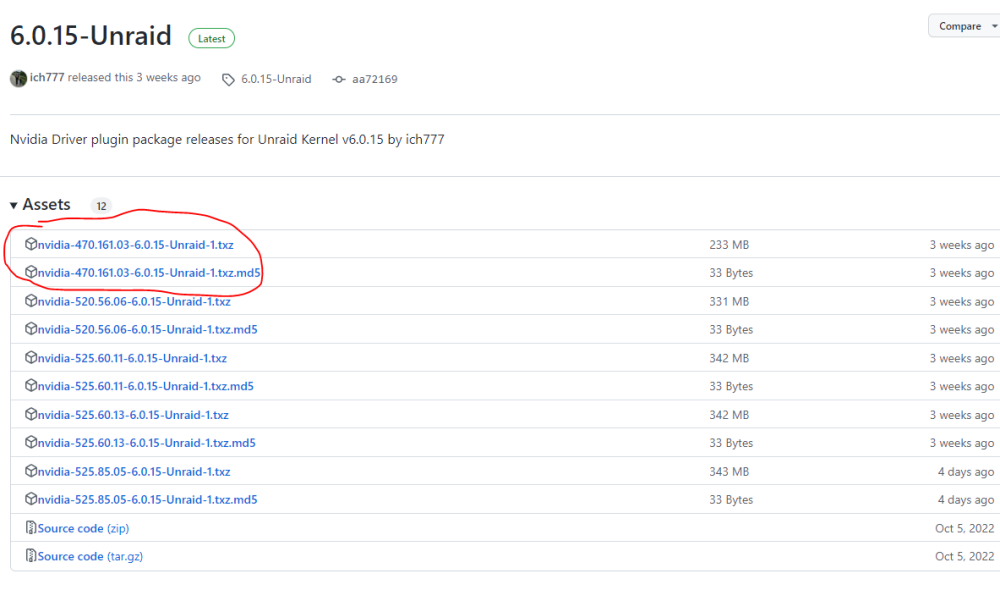
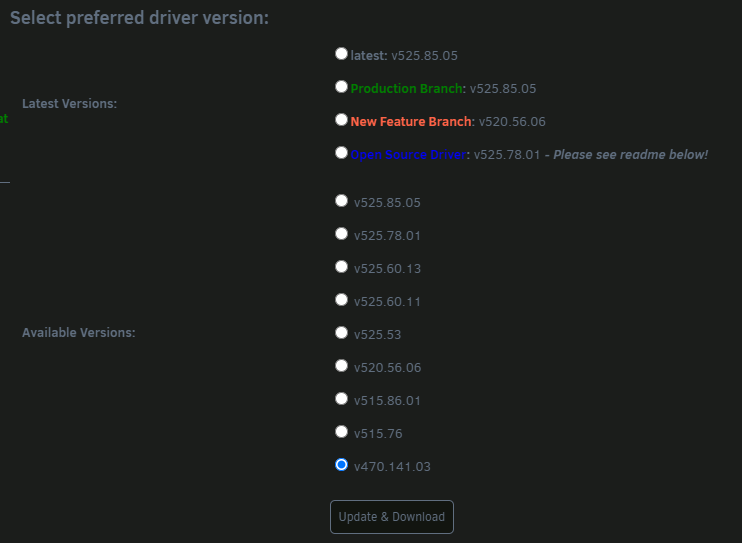
I need a little bit support. I need the driver package 470.161.03 I saw that you released it. But I cannot choose it in the plugin. How is the procedure? Thanks a lot
-
Ja habe ich schon gehört Hat der Name irgeneine Auswirkung? Ja ist eine 12900k und ja war mit Software- Transcoding, daher wollte ich auch das HW Transkoding nutzen. Ich habe einen Arctic Feezer i35 A-RGB drauf, für die meisten Anwendungen sicher auch ausreichend. Die Tests dazu die ich gelesen habe, waren nicht so schlecht. Gibt sicher eine ganze Latte von Kühlern die besser sind.
-
Sorry kann nicht ganz folgen. Bei Name? Sorry habe Erfahrung von einer Woche mit Unraid oder Linux Ich lasse konvertieren über alle Filme laufen, für mobile Devices. Die CPU ist alleine echt schnell und schafft das auch. Ich wollte die aber nicht dauerhaft auf hoher Temperatur laufen lassen. Die steigt auf knapp unter 80°C. Müsste vllt. mal einen anderen Kühler drauf bauen. Mit iGPU ist der bei knapp über 40 °C Danke und Gruß
-
Jetzt funktioniert es auch ohne Front Slash. Kann es sein, dass es erst durch das hin und her ändern geklappt hat und garnichts mit dem Front-Slash zutun hat?
-
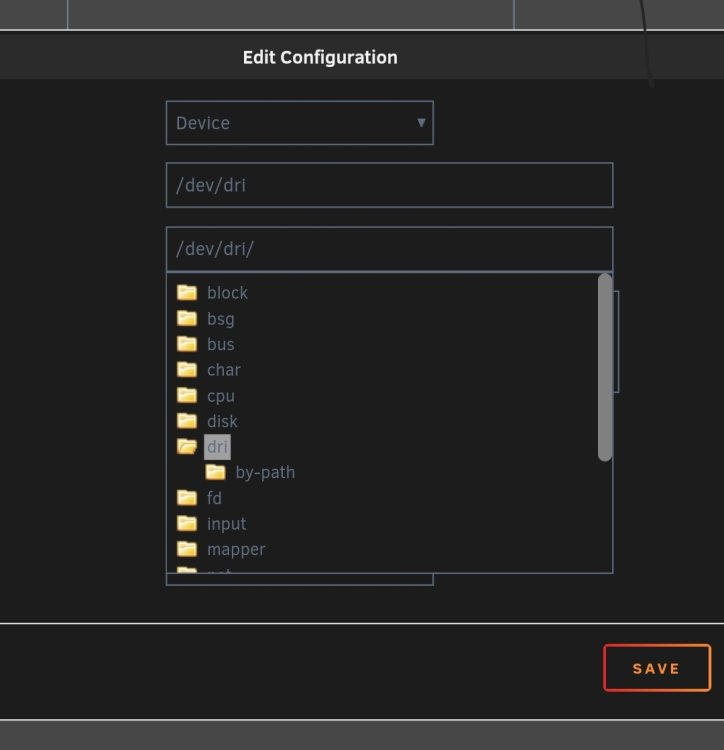
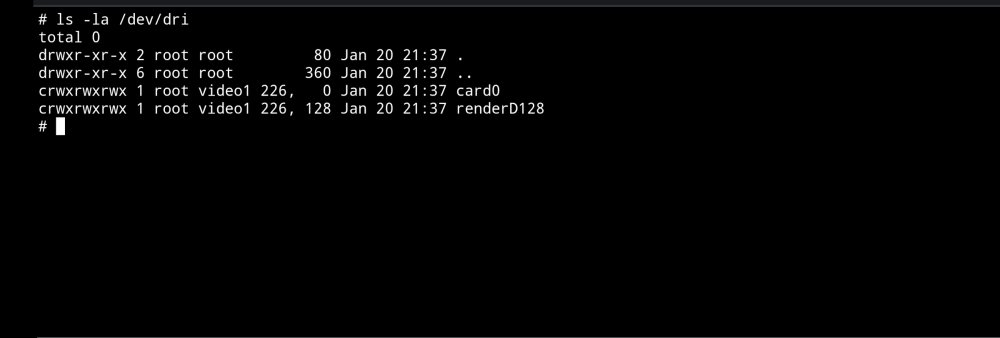
6.11.5 Als Vergleich: So sieht es, wenn ich den Pfad /dev/dri/ auswähle
-
Wenn ich "/dev/" eingeben, und dann aus dem Dropdown dri auswähle, dann gibt er mir "/dev/dri/" an und das funktioniert. Habe es eben mal zurückgestellt auf "/dev/dri" und es funktioniert wieder nicht. Ich kann dir nicht sagen warum, bei mir funktioniert es nur mit mit dem Front- Slash am Ende Naja es funktioniert Danke und Gruß
-
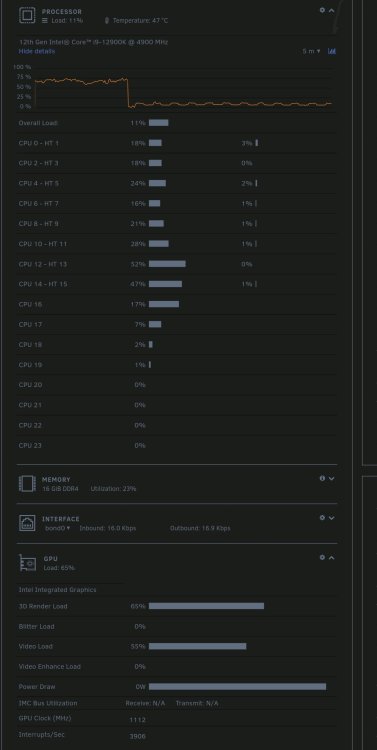
Anbei mal ein Ausschnitt, ich habe die Zeit von der CPU Auslastung erhöht. Man sieht gut, wann die Hardware- Beschleunigung funktioniert hat und zugeschaltet wurde.
-
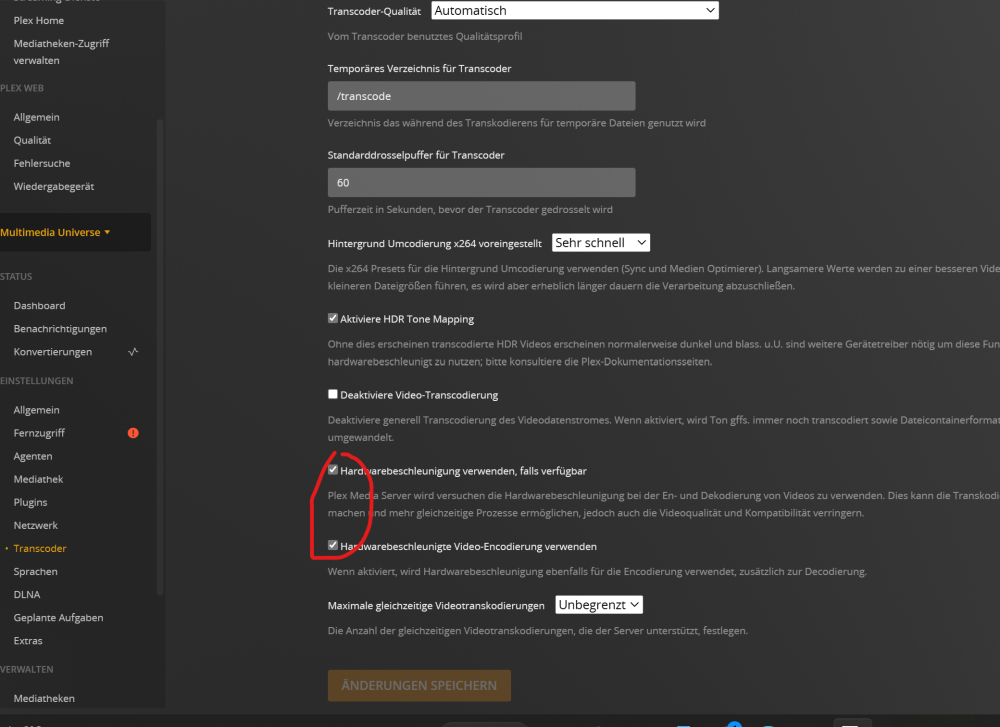
Hallo zusammen, Ich glaube es nicht. Ich habe den Fehler gefunden und könnte mich dafür Schlagen. Ich habe im Plex Docker das Device eingebunden und habe folgendes reingeschrieben: Name: /dev/dri Value: /dev/dri Es fehlte bei Value ein Front Slash. Korrekt ist bei Value: /dev/dri/ Der Name konnte so bleiben, ist nicht so wichtig. Jetzt sehe ich auch im Daschboard Aktivität. @mgutt, sorry das ich dir deine Zeit geklaut habe Danke und Gruß
-
Sorry, hatte ich vergessen zu erwähnen. Plex Unlimeted Pass habe ich. Die Haken für Hardwarebeschleunigung sind auch drin.
-
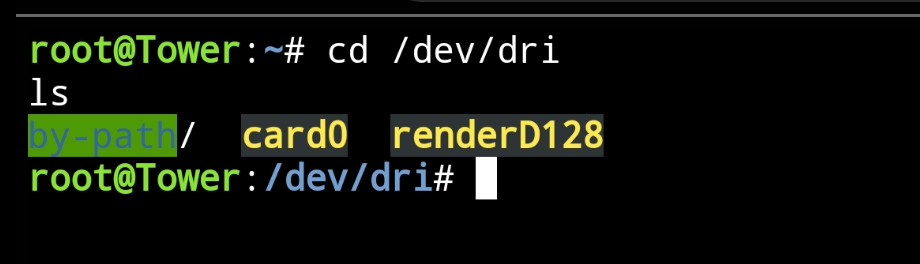
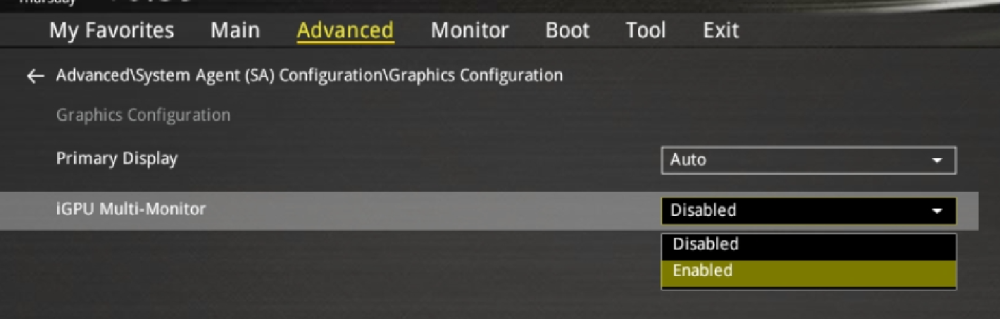
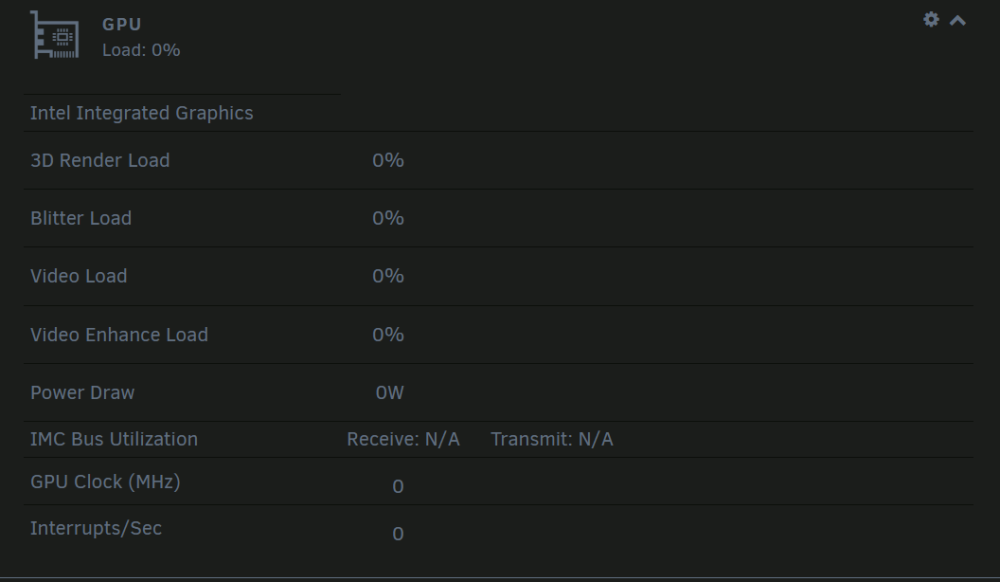
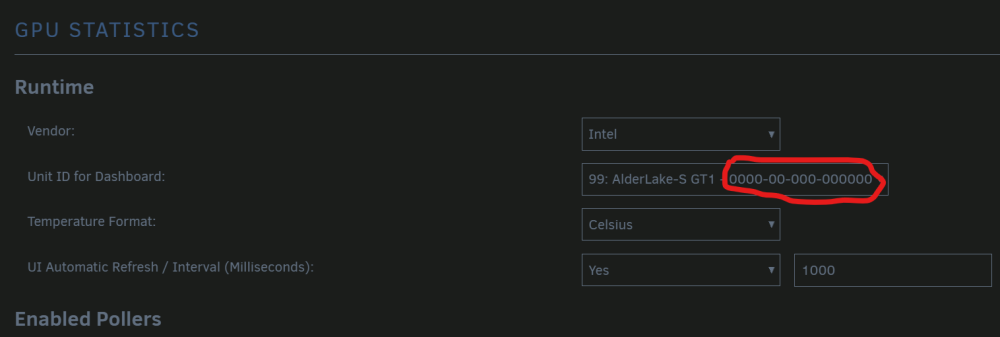
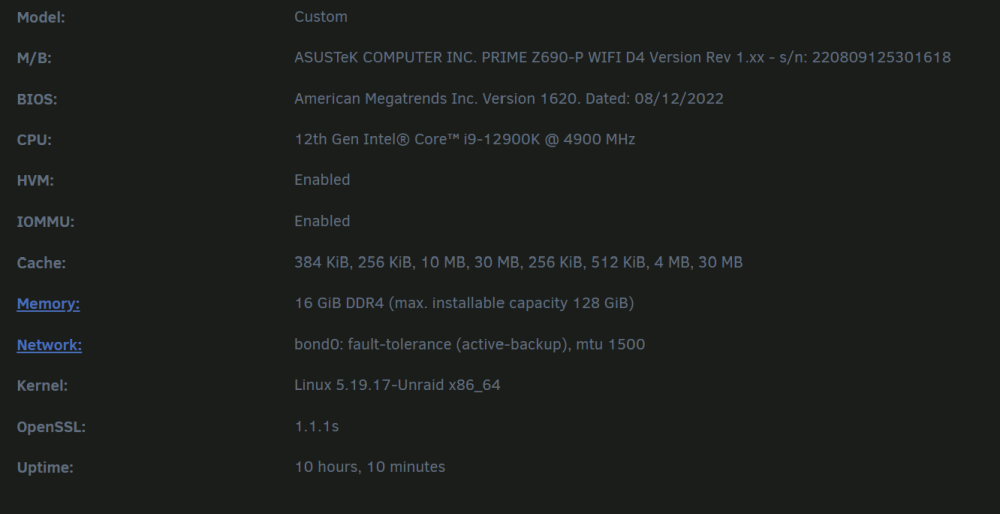
Hallo zusammen, ich hoffe dass jemand bereits eine Lösung parat hat. Ich habe jetzt unzählige Foren, Videos und Berichte angeschaut, inklusive der Communities auf Docker und GitHub. Ich würde gerne Hardware Transcoding über die iGPU für Plex verwenden Ich komme einfach nicht weiter. Hardware Setup: ASUSTeK COMPUTER INC. PRIME Z690-P WIFI D4 , Version Rev 1.xx (Intel Z690 Chipsatz) 12th Gen Intel® Core™ i9-12900K @ 4900 MHz Es ist keine extra GPU verbaut (Nur die iGPU des Prozessors) Ich habe den offizielen "Plex MediaServer" Docker und habe "/dev/dri" eingebunden als device Ich bin mir nicht ganz sicher wegen Blacklisten, ob es jetzt benötigt wird oder nicht, da gibt es irgendwie mehrere Meinungen, manche setzen auch die Dateigröße auf "0 Byte". Bei mir siehts so aus. Ich habe im Bios den IGPU Multi-Monitor auf Enabled gestellt, habe gelesen, dass dies manchen geholfen hat. Den Server habe ich natürlich schon ein paar mal neu gestartet Es ist auch das Intel GPU TOP Plugin und GPU Statistics installiert. Hardware Transcoding ist natürlich in Plex auch markiert. Bei Plex selbst, kann ich zwar Transkodieren, allerdings steht bei keiner Auswahlmöglichkeit "HW" oder "Hardware" dran. Wenn ich etwas auswähle, springt die IGPU auch nicht an. Siehe Terminal Siehe Dashboard GPU Statistics Anbei mal noch ein Ausschnitt vom GPU Statistics Ich bin echt noch Anfänger und versuche noch mir irgendwie ein Überblick zu verschaffen, aber dass sind für mich irgendwie zu viele Nuller. Kann jemand bestätigen, dass die Nuller so korrekt sind? Weitere Infos: Unraid OS 6.11.5 PlexMediaserver wurde gestern nochmals installiert, ist also auch Up-to-Date Danke vielmals an alle, ist echt ein super Forum



-
-
Dank dir vielmals. Ich hatte da ein Denkfehler. Ich dachte, dass die Backup Funktion, stumpf alle Daten kopiert, ohne Abgleich, ob die Daten bereits im Ziel vorhanden sind. Ich gebe dir 100% Recht, die Backup Funktion reicht dann aus. Sorry hatte die Funktion falsch verstanden. Bezüglich der Kommando Option, die hatte ich nicht berücksichtigt. Hat sich aber somit sowieso erledigt, ich stelle auf Backup Task um. Ich bin hier neu, ist vermutlich aufgefallen:) Muss ich diese Topic im Forum noch irgendwo schließen?
-
Wenn ich die Backup Funktion benutze gebe ich dir Recht. Mit einem Task für Synchronisation geht es aber in beide Richtungen, das will ich eigentlich auch. Ich bin da vielleicht etwas paranoid, ich Synchroniere einmal die Woche meine externe Festplatte mit den Wichtigsten Verzeichnissen. Und einmal im Monat ein Backup auf eine andere externe Festplatte. Die Synchronisation Festplatte, ist damit ich immer die neustem Dateien habe. Mit dem Synchronisations Task im Lucky Backup erstellt der aber eine Datei neu, wenn die im Ziel oder Quelle gelöscht wurde. Noch witziger ist es beim Verschieben einer Datei. Verschiebe ich eine Datei in der Quelle. Dann erstellt er mir die Datei wieder am Ursprünglichen Ort, da es im Ziel noch so ist. Und im Ziel kopiert er die Datei im neuen Verzeichnis, weil die dort fehlt.
-
Danke vielmals für den Input. Ich werde mich dann mal mit den Parametern von rsync beschäftigen. Mal schauen ob ich da auch etwas wegen dem Synchronisieren finde, bezüglich Master. Ich hätte halt schon gerne, dass Dateien die ich auf dem Server lösche, dann mit dem nächsten Synchronisationslauf auf dem Backup System verschwinden Danke vielmals und Gruß
-
Vielen Dank für den Input. Ich habe die einzelnen Verzeichnisse auch über den Docker Lucky Backup einstellen können. Ich frage mich nur wie die Logik ist. Ich hatte irgendwo mal gelesen, dass er standardmäßig die neuste Version einer Datei als Master nimmt und diese dann synchronisiert. Egal ob die Datei auf der Quelle oder Ziel liegt, dass wäre soweit auch in Ordnung für mich. Kann das jemand bestätigen? Lässt sich im Lucky Backup bei der Syncro ein Master definieren, wenn ich eine Datei verschieben will, würde es sonst, die vom Backup System auf den Ursprünglichen Verzeichnis wieder herstellen und auf dem Backup System nochmal das gleiche auf dem neuen Verzeichnis, wäre ja irgendwie nicht so ganz Synchronisierung. Ggf. müsste ich doch auf rsync umsteigen, da müsste das ja gehen, oder? Danke und Gruß
-
Hallo zusammen, ich bin neu hier. Ich habe einen neuen Unraid Server gebaut und meine ganzen Daten noch auf einer externen Festplatte. Ich hatte angefangen die Daten von der externen Festplatte auf mein Array zu kopieren. Die externe Festplatte ist aber schon etwas älter und wurde irgendwann 47°C, daher hatte ich eine Pause eingelegt. Der Kopiervorgang wurde dabei leider abgebrochen. Nun möchte ich den Kopiervorgang nicht nochmal anstoßen, weil ja schon viele Daten da sind. Es ist noch ungefähr 2,5TB von 6TB offen. Die Idee wäre nun mit dem Lucky Backup per Sync- Funktion die restlichen Daten zu holen. Wenn ich es richtig verstanden habe, holt der ja dann nur die Differenz (also was noch fehlt) Ich habe es noch nicht ausprobiert, weil ich bedenken habe. Woher weiß das System wer der Master ist. Es könnte ja theoretisch sein, dass Lucky Backup mein Array als Master sieht und denkt, dass auf der externen Festplatte zu viele Daten da sind und dann anfängt Daten zu löschen, oder bin ich nur Paranoid?
-
Hello, it's my first post. I build up a completely new unraid server and use dynamics file server to copy all data of my backup system ( external hdd. I know it needs time. However, I have a question. I'm currently copying 13 folders bit sometimes I cannot see the remaining time or status. At the beginning, it was possible to the the progress status of the document which the program is copying. But not the remaining time of complete 13 folders. If I check now, I see nothing, no remaining time of document nor of 13 folders. Is this a bug of my system or of the software. Maybe its too much data, approx 3 TB Thanks a lot Issue is solved. It`s up to the parity check. I paused it and it was fixed. As long as parity check is not running I could see the information incl. speed and remaing time. When parity check is running and reading data from the same disk, it will hide the information of copy window

















