SliMat
Members
-
Joined
-
Last visited
Everything posted by SliMat
-
Thanks, I read it as "you could do that" - and thought there might be a better way ;) The server I am using is an HP ProLiant ML30 Gen10 - I think I fitted an HP P410 RAID card and switched it to JBOD mode... is there a better (newer) SATA controller which anyone can recommend? Thanks again
-
Thanks @JorgeB As it was showing several disks as failed, I went into the room where the server is and it was quite warm, so I turned on the aircon and have left it on, so suspect that it is a heat issue. Assuming that is the cause would my de-assign then re-assign routine be correct? Thanks
-
Would I be correct in thinking that I should; Stop the array Unassign the existing parity disk Start the array to allow UnRAID to see the change Stop the array Assign the originally disabled disk as the parity drive Start the array and allow a parity build on the 'new' disk I just dont want to start something which is going to cause me an issue going forward Thanks
-
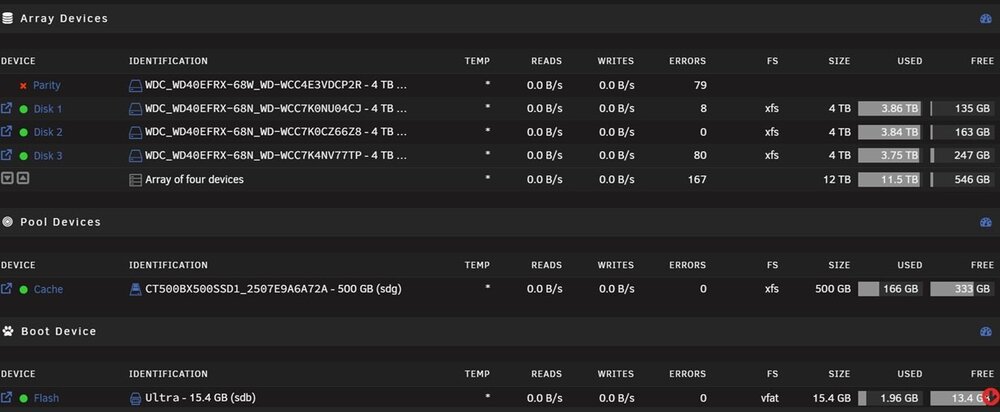
Hi All I got home tonight to find my server was showing read errors on 3 disks!!! This is what the dash showed... All my dockers were disabled. So, I downloaded the diags (attached) and then knowing that a reboot usually fixes most problems I rebooted it. It now shows that the parity disk is disabled... so, I am guessing it will need to rebuild (or check) the parity disk from the data drives... but, I am not sure what to do from here and am very twitchy about not having a working parity disk enabled. Can anyone advise what to do from here please? Thanks hector-2-diagnostics-20260621-1901.zip
-
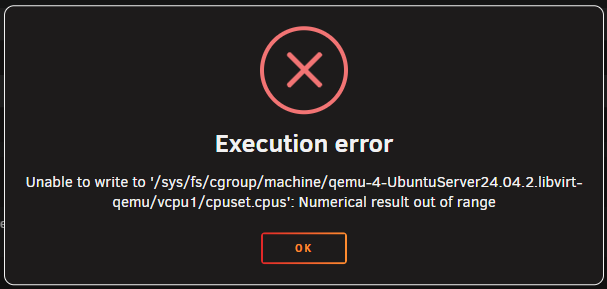
I have just found that my VMs wont boot on the new server and shows this error; I think this is because the old CPU (E3-1210 v3) was 4 physical cores and a total of 8 threads, while the new CPU is E-2224 which is only 4 physical cores and doesn't support hyperthreading... but am not sure how to correct the fact the VMs are (maybe) trying to use cores which no longer exist?!? If anyone can assist in how to diagnose and fix this I would be very grateful Thanks
-
Hi all Just wondered if anyone can explain this... I have got a new Proliant ML30 G10 server and wanted to replace my aging ML310e G8 server which I have been using at home for many years. So swapped everything over and spent 2 hours trying to get it to boot into UnRAID. Out of desperation I made a new USB key with the UnRAID USB Creation app and tried that and the new server booted immediately into UnRAID. So I knew it had to be something about the key. I spotted on the original key the EFI directory was called "EFI-" on the new demo UnRAID key it was called "EFI"... so as I have a backup of my key (thanks UnRAID Connect*)... I just renamed the directory from "EFI-" to "EFI"... immediately it worked fine I was just wondering what the significance of the "-" in the directory name is? My understanding is that Legacy to UEFI is controlled with a "~" prefix? Also thought I would post this in case anyone else has a similar problem and this might help them. Thanks
-
Thanks @JorgeB - I have only just got round to doing this and mover has completed, but when I look at the shares, some of the data is still showing as being stored on array disks. So, I ran mover again and it finished straight away - but moved nothing more... When I drill down in my Plex-Media-Server share, it shows several folders which are still holding data on the array; Is this normal... if not, what do I need to do to correct this? Thanks
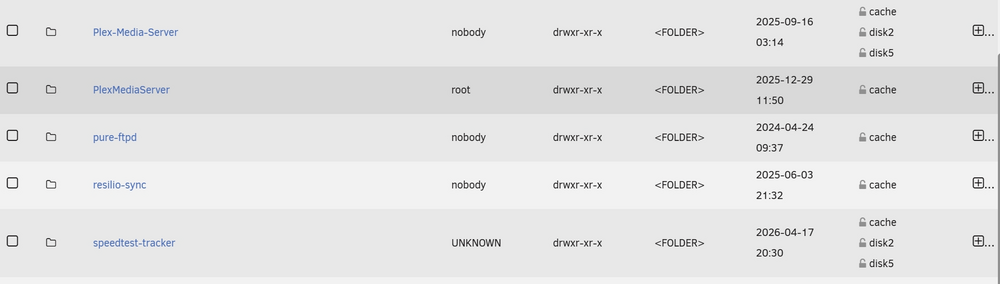
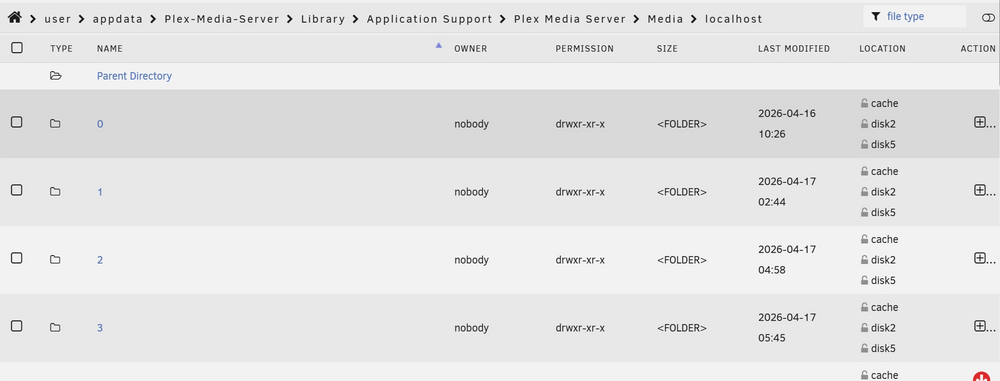
-
Thanks - I followed the SpaceInvaderOne Setup video and got him up and running with Tailscale
-
I tried both the tut's above and still its not working... so, will take a look at tailscale as never used this either... I think there is a tut by SpaceInvaderOne... so will try to find this. Thanks
-
This was just as a test to see if the issue was the routing... but it didnt work even when in the DMZ... once tested I brought it back behind the firewall
-
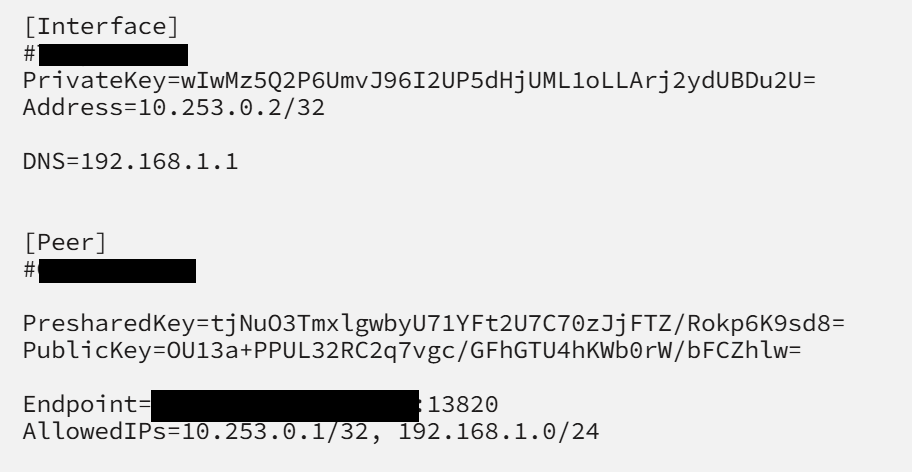
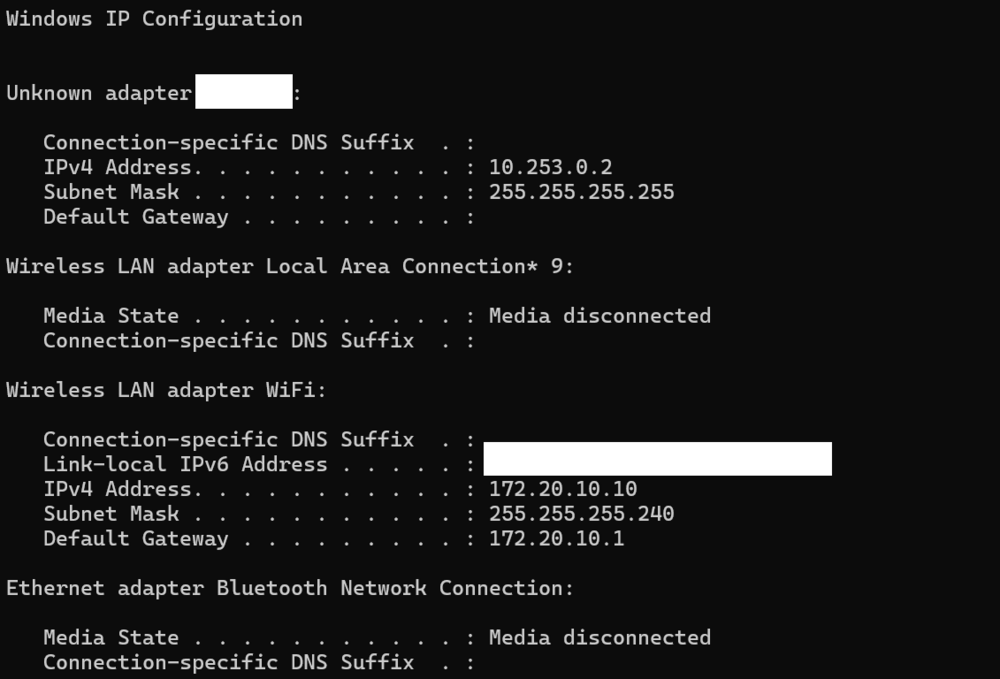
Hi All I am trying to configure the inbuilt Wireguard on a friends server so he can remotely access his LAN... but have spent ages and cant get it to work... I have created a tunnel from settings>vpn manager Added a peer: Then I have tried on a PC and mobile using the QR Code and creating my own tunnel: Forwarded port 13820 to 51820 on the Zyxel Router: But I have not been able to get this to work - can anyone shed any light on this? I am at a loss why this wont work. I have tried putting the server in the DMZ and also using port 51820 as public port - but nothing seem to work. When I am connected IPCONFIG shows; I have travelled 300 miles to visit and set this up, so would really appreciate it if anyone can help. Thanks
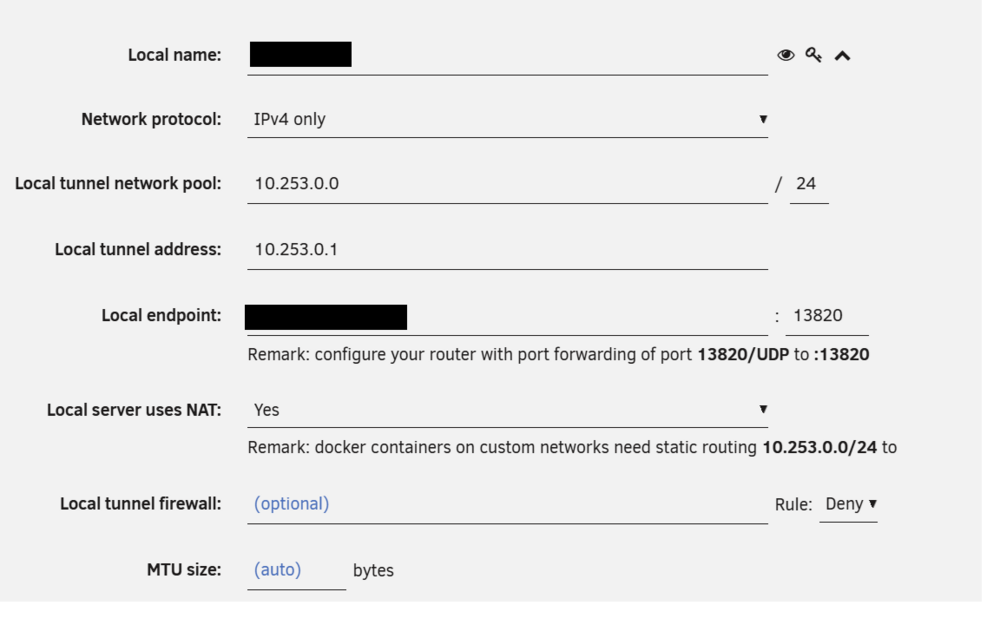
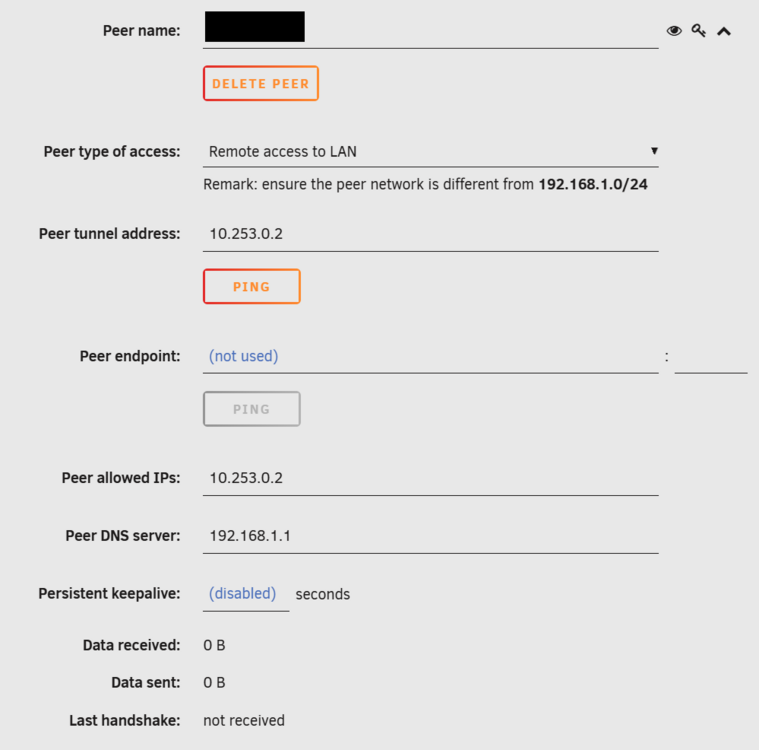

-
Thanks I will try this at the weekend when I can take it offline for a while.
-
I'm bumping this as I still have not moved appdata, domains & system onto the new 2Tb disk, so they are still on the array and the 2Tb SSD is empty. Is there a tut, or a post which outlines the correct way to move these back onto the cache disk? I am wary having lost data when I tried to move them off the original SSD and dont want to end up with more downtime Any advice / instructions greatly received. Thanks
-
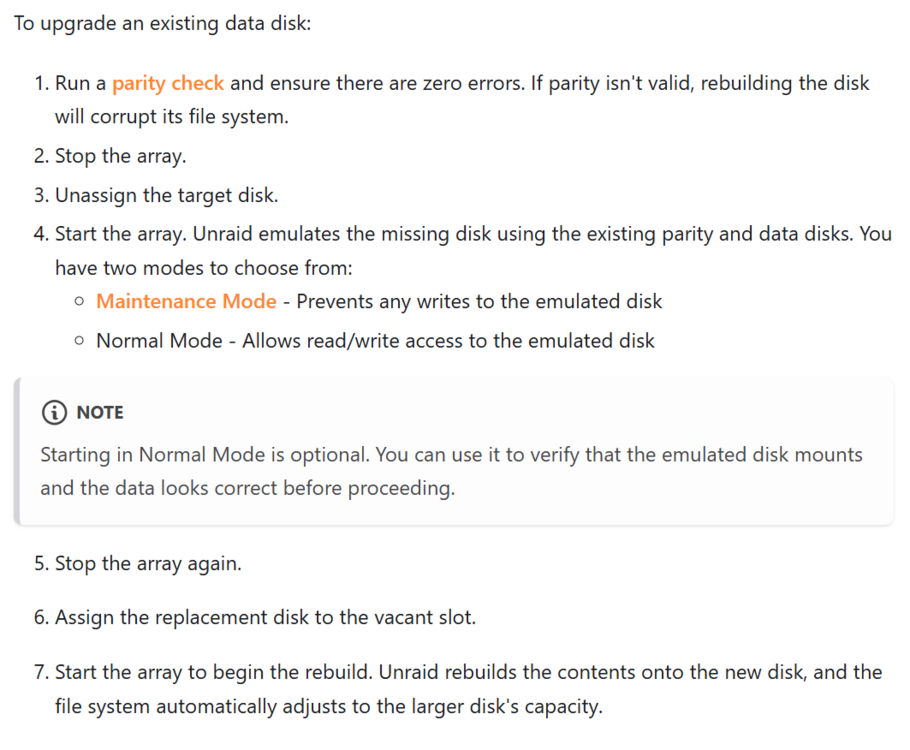
Thanks @itimpi @JorgeB I have already prepared a new disk, so will just replace it. I would rather just dispose of the disk with warnings as I dont want to be in the position where I lose data by trying to save a few £'s :) As I cant physically remove the old disk as the machine is in a data centre - can I check the correct steps to replace it? I was going to stop the array, unassign disk 4 from the Main page, assign the new disk as disk 4 on the Main page and restart the array... is this correct and I think it should warn that the new disk 4 will be overwritten and then start the data rebuild once I accept the warning. Is this correct - or is there anything I need to do differently? Thanks
-
I think this is the correct process to follow, but just want to make sure before starting...
-
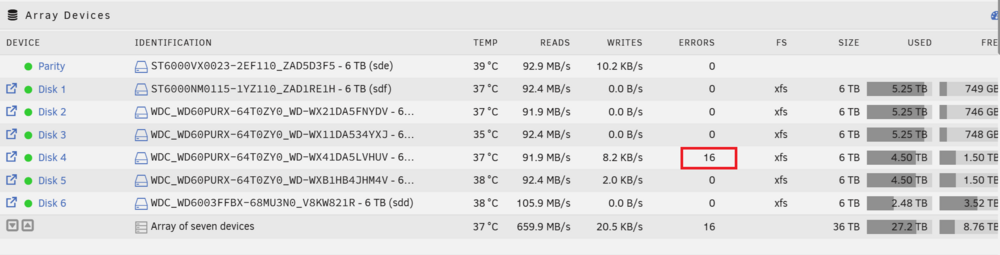
Hi all, I am re-opening this as the same disk has started reporting read errors again... so I am pretty sure its on its way out; This machine is remote, so after the first time I was getting these errors I installed a new disk and ran Preclear on it. So, this disk is already in the machine ready to be added to the array. Is the correct process to just re-assign disk 4 to the new one, or do I need to unassign the existing disk 4 - reboot and then assign the new disk to start the rebuild? Its a while since I have had a disk fail, so just need to make sure I am following the correct process. Current diags attached :-) Thanks phoenix-diagnostics-20260301-0936.zip
-
Not sure why UnRAID reported read errors and then shows "completed without error"... unless I am missing something? I have attached the SMART report too. phoenix-smart-20260117-2032.zip

-
Apologies - I just realised I was logged on to the wrong server, so the above readings are wrong... this is the server with this problem... The minimum space is set to 390.5Gb and the share has 850Gb space... so should be OK, I think! Incidentally, I checked the size of the backups and the folders are about 15Gb in size.

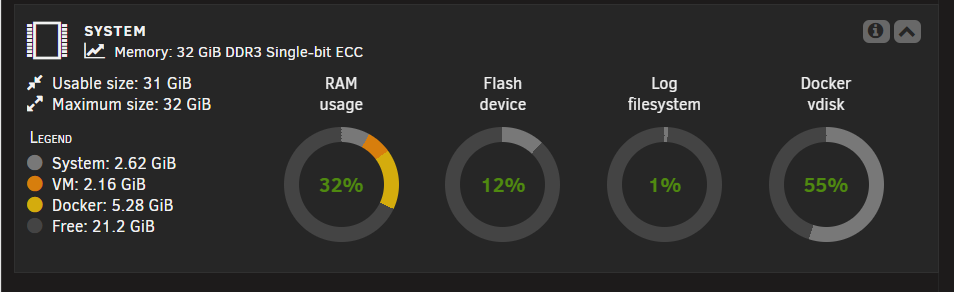
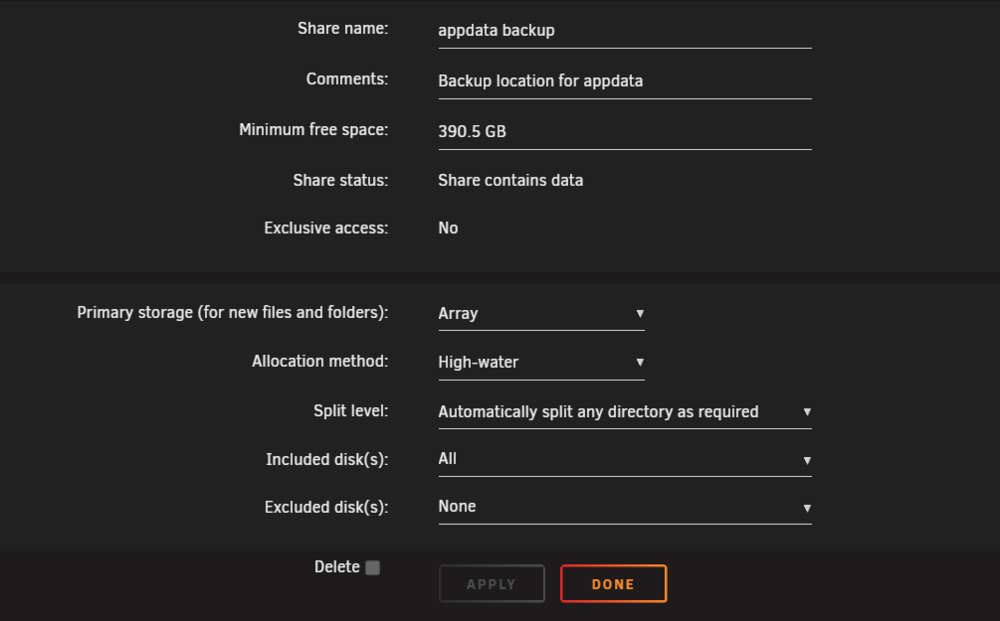 Thanks @Kilrah I spotted that, but was unsure which share this relates to... I have a "/mnt/user/appdata backup" share which I created to store these backups, but it has plenty of space...
Thanks @Kilrah I spotted that, but was unsure which share this relates to... I have a "/mnt/user/appdata backup" share which I created to store these backups, but it has plenty of space...
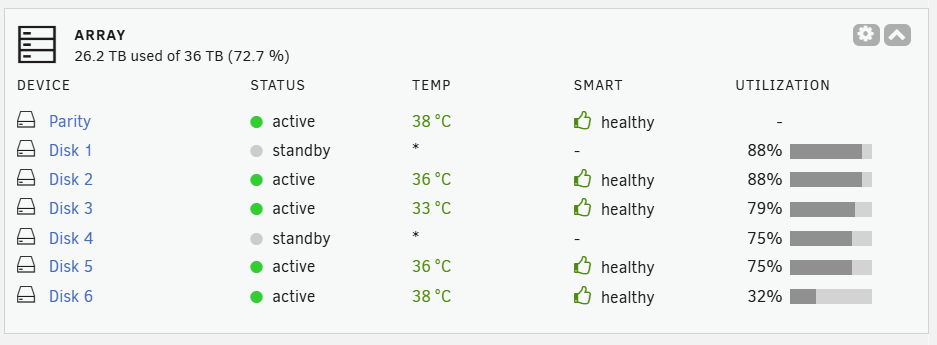
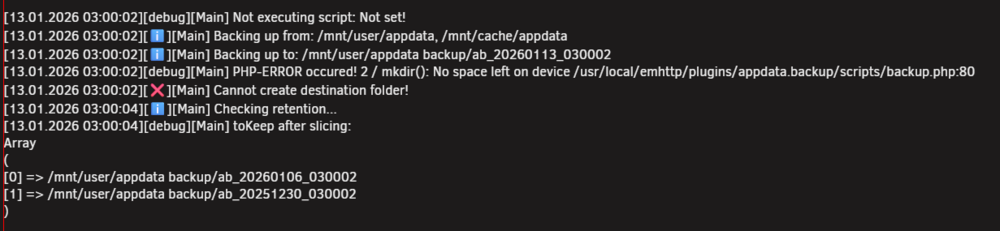
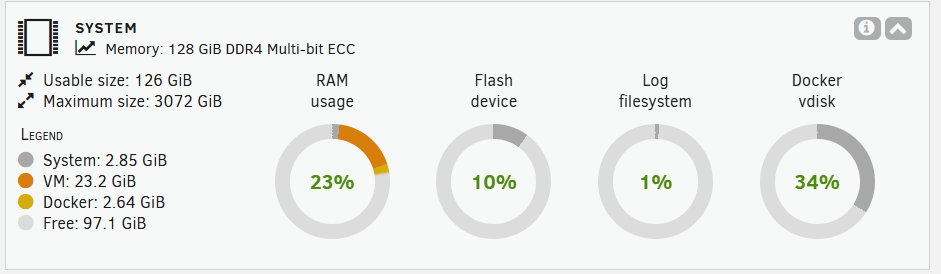 Sorry - my oversight... now attached :) phoenix-diagnostics-20260114-1913.zipHi all One of my servers has just reported an error when Appdata Backup ran overnight. The error says "Cannot create destination folder"; Any thoughts on why this is erroring and where to start looking to fix it? Thanks
Sorry - my oversight... now attached :) phoenix-diagnostics-20260114-1913.zipHi all One of my servers has just reported an error when Appdata Backup ran overnight. The error says "Cannot create destination folder"; Any thoughts on why this is erroring and where to start looking to fix it? Thanks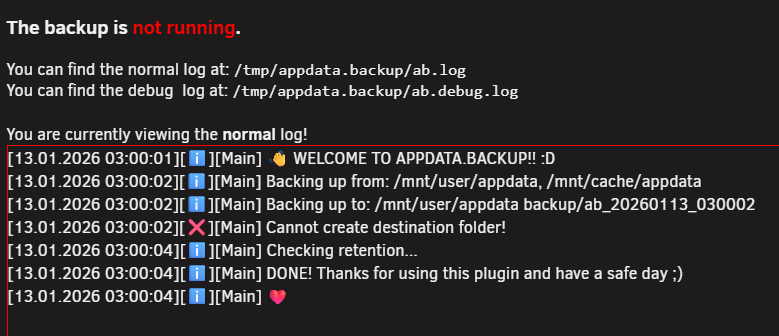
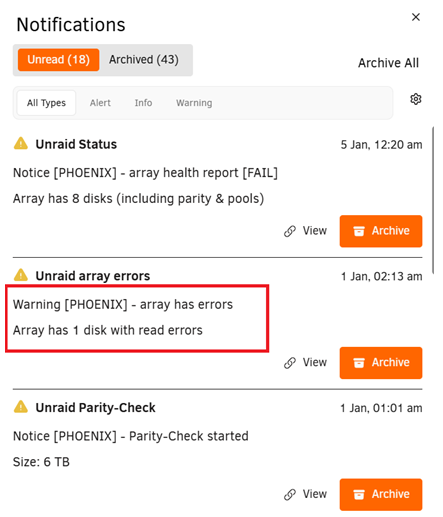
 Hi All I received a warning that one of my array disks had 76 read errors; So I powered the server off, fitted a new 6Tb disk in a spare slot and successfully precleared it ready to replace this one with errors. But, now the disk which had read errors is showing no errors... I am guessing its reset because the machine has been rebooted... is it not showing these read errors now because it hasnt tried to read from the 'failed' sectors, or has the reboot cleared the fault so the disk doesnt need replacing? If the recommendation is to replace it... what is the correct method? I am guessing; Replace the failed disk with the new one When the machine complains that the original disk is missing, assign the new one and confirm rebuild from parity disk Is that correct? Thanks
Hi All I received a warning that one of my array disks had 76 read errors; So I powered the server off, fitted a new 6Tb disk in a spare slot and successfully precleared it ready to replace this one with errors. But, now the disk which had read errors is showing no errors... I am guessing its reset because the machine has been rebooted... is it not showing these read errors now because it hasnt tried to read from the 'failed' sectors, or has the reboot cleared the fault so the disk doesnt need replacing? If the recommendation is to replace it... what is the correct method? I am guessing; Replace the failed disk with the new one When the machine complains that the original disk is missing, assign the new one and confirm rebuild from parity disk Is that correct? Thanks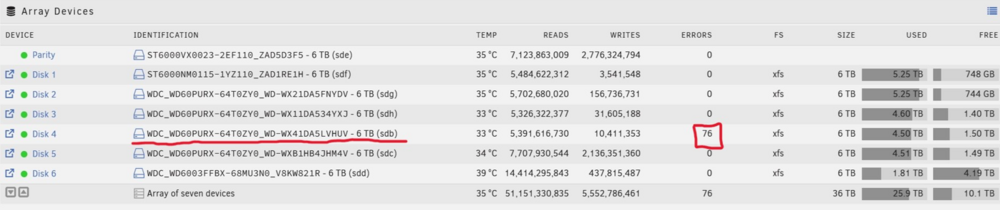
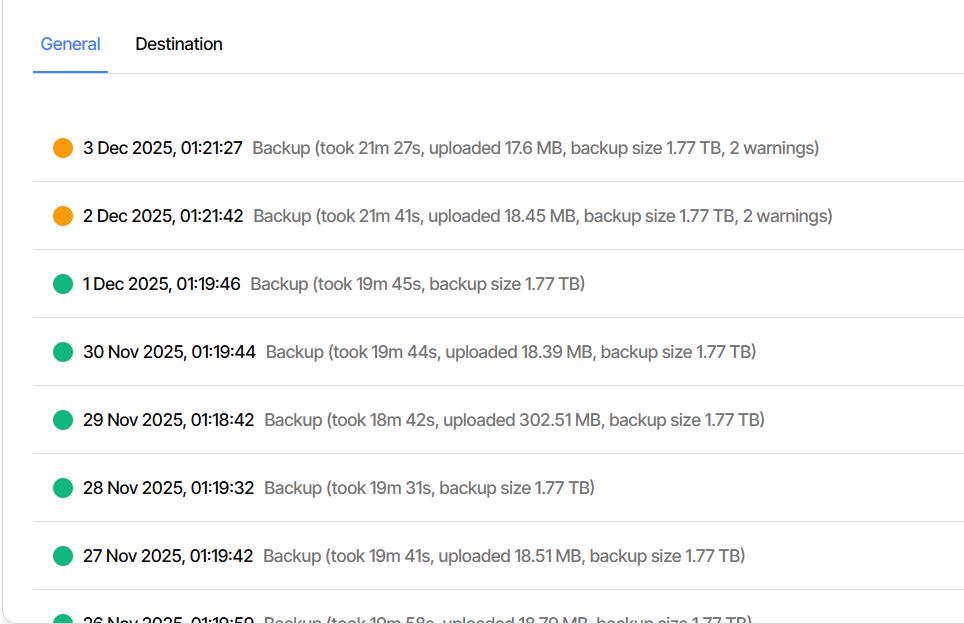
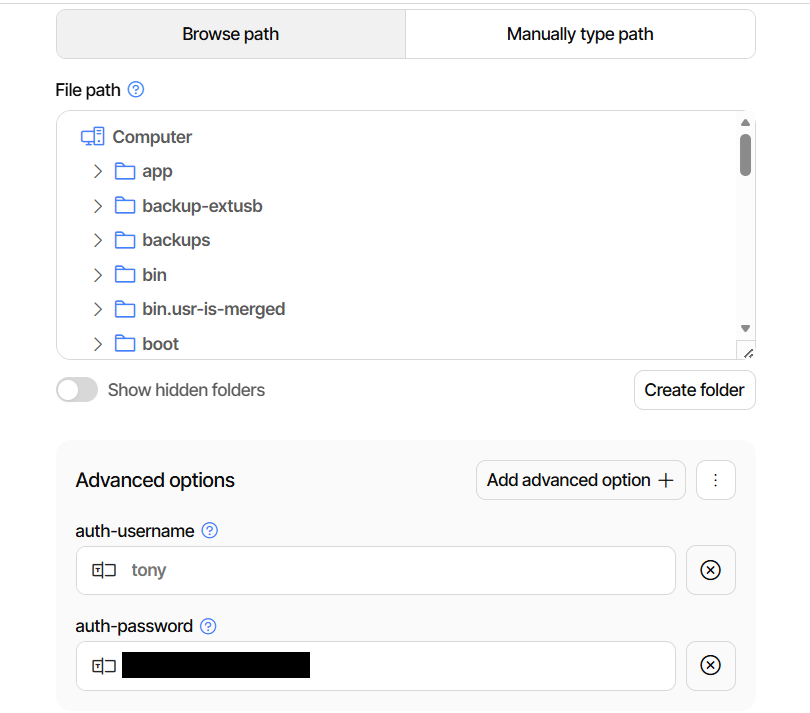
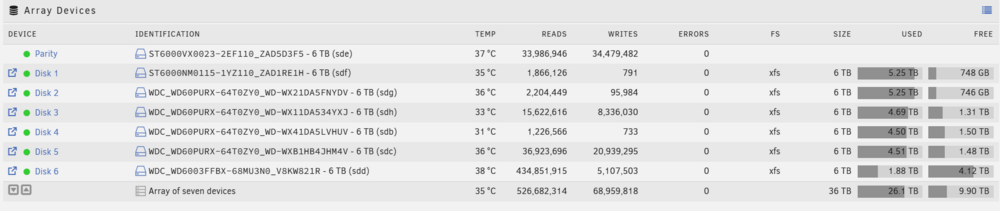 Hi all I recently had a massive issue when I tried to replace my cache disk, which stored appdata, domains & system, with a larger SSD. When I moved the files to the array it all went very wrong and most of my appdata was lost and as a result most dockers failed and needed to be rebuilt completely. I replaced the 500Gb SSD with a 2Tb SSD and recreated the lost data. This is currently stored at /mnt/user/appdata, /mnt/user/domains & /mnt/user/system. After having to recreate most dockers and set them up again, the system has been working for a few months now - so I currently have a working system with an empty 2Tb cache disk. I have a number of VMs and dockers which are running 24x7 and because they are currently on the main array, it keeps all the array disks (which have any docker/vm data on) spinning all the time. This was the main reason that I originally installed a cache disk - to allow the array disks to spin down when not in use. Because of the issue I had before, I have now installed 'Appdata Backup' and it is currently running - creating a backup on the main array. My question is this... what is common practice for storing appdata, domains & system? Or can someone recommend what I should move to cache? In my setup is it best to move them back on to the cache disk? If so, what is the correct way to do this, so I don't lose data again?? Also, as Appdata Backup is currently creating a backup of /mnt/user/appdata... if/when I move appdata to /mnt/cache/appdata should I just manually delete the /mnt/user/appdata backup from the backup location and create a new backup for /mnt/cache/appdata? Or, is there a way to notify Appdata Backup that the location has changed? I want to do this over the New Year break as there will be no users accessing the server... so any help to avoid more massive downtime would be very much appreciated. ThanksOK, as there was no reply to my above query, i removed the username and password from the settings above and tonight got this error... 2025-12-09 01:00:44 +00 - [Error-Duplicati.Library.Main.Controller-FailedOperation]: The operation Backup has failed RemoteListVerificationException: Found 68780 files that are missing from the remote storage, please run repair Can anyone offer any advice why this has broken in the latest release?? Is there a way to roll back to the previous version of Dullicati to get things working again if this option has been removed in the latest version? Thanks
Hi all I recently had a massive issue when I tried to replace my cache disk, which stored appdata, domains & system, with a larger SSD. When I moved the files to the array it all went very wrong and most of my appdata was lost and as a result most dockers failed and needed to be rebuilt completely. I replaced the 500Gb SSD with a 2Tb SSD and recreated the lost data. This is currently stored at /mnt/user/appdata, /mnt/user/domains & /mnt/user/system. After having to recreate most dockers and set them up again, the system has been working for a few months now - so I currently have a working system with an empty 2Tb cache disk. I have a number of VMs and dockers which are running 24x7 and because they are currently on the main array, it keeps all the array disks (which have any docker/vm data on) spinning all the time. This was the main reason that I originally installed a cache disk - to allow the array disks to spin down when not in use. Because of the issue I had before, I have now installed 'Appdata Backup' and it is currently running - creating a backup on the main array. My question is this... what is common practice for storing appdata, domains & system? Or can someone recommend what I should move to cache? In my setup is it best to move them back on to the cache disk? If so, what is the correct way to do this, so I don't lose data again?? Also, as Appdata Backup is currently creating a backup of /mnt/user/appdata... if/when I move appdata to /mnt/cache/appdata should I just manually delete the /mnt/user/appdata backup from the backup location and create a new backup for /mnt/cache/appdata? Or, is there a way to notify Appdata Backup that the location has changed? I want to do this over the New Year break as there will be no users accessing the server... so any help to avoid more massive downtime would be very much appreciated. ThanksOK, as there was no reply to my above query, i removed the username and password from the settings above and tonight got this error... 2025-12-09 01:00:44 +00 - [Error-Duplicati.Library.Main.Controller-FailedOperation]: The operation Backup has failed RemoteListVerificationException: Found 68780 files that are missing from the remote storage, please run repair Can anyone offer any advice why this has broken in the latest release?? Is there a way to roll back to the previous version of Dullicati to get things working again if this option has been removed in the latest version? Thanks