Alex.vision
Members
-
Joined
-
Last visited
Everything posted by Alex.vision
-
Hmm, I seem to be getting the same error on the old disk4 Aug 17 10:43:51 Media unassigned.devices: Adding disk '/dev/mapper/ST8000AS0002-1NA17Z_Z840XT2C'... Aug 17 10:43:51 Media emhttpd: shcmd (69098): /usr/sbin/cryptsetup luksOpen /dev/sdk1 ST8000AS0002-1NA17Z_Z840XT2C Aug 17 10:43:52 Media unassigned.devices: Mount drive command: /sbin/mount -o rw,noatime,nodiratime '/dev/mapper/ST8000AS0002-1NA17Z_Z840XT2C' '/mnt/disks/ST8000AS0002-1NA17Z_Z840XT2C' Aug 17 10:43:52 Media kernel: XFS (dm-28): Filesystem has duplicate UUID 55c3e94c-c28a-4132-adb2-43d2ff58c702 - can't mount Aug 17 10:43:52 Media unassigned.devices: Mount of '/dev/mapper/ST8000AS0002-1NA17Z_Z840XT2C' failed: 'mount: /mnt/disks/ST8000AS0002-1NA17Z_Z840XT2C: wrong fs type, bad option, bad superblock on /dev/mapper/ST8000AS0002-1NA17Z_Z840XT2C, missing codepage or helper program, or other error. ' Aug 17 10:43:52 Media unassigned.devices: Partition 'ST8000AS0002-1NA17Z_Z840XT2C' cannot be mounted. I will run an extended test on disk1 now.
-
I ran into problems trying to mount the new Disk 4. This was in my syslog. Aug 17 10:18:18 Media unassigned.devices: Adding disk '/dev/mapper/WDC_WD80EFZX-68UW8N0_VKGW28LX'... Aug 17 10:18:18 Media emhttpd: shcmd (69093): /usr/sbin/cryptsetup luksOpen /dev/sdab1 WDC_WD80EFZX-68UW8N0_VKGW28LX Aug 17 10:18:18 Media unassigned.devices: Mount drive command: /sbin/mount -o rw,noatime,nodiratime '/dev/mapper/WDC_WD80EFZX-68UW8N0_VKGW28LX' '/mnt/disks/WDC_WD80EFZX-68UW8N0_VKGW28LX' Aug 17 10:18:18 Media kernel: XFS (dm-28): Filesystem has duplicate UUID 55c3e94c-c28a-4132-adb2-43d2ff58c702 - can't mount Aug 17 10:18:18 Media unassigned.devices: Mount of '/dev/mapper/WDC_WD80EFZX-68UW8N0_VKGW28LX' failed: 'mount: /mnt/disks/WDC_WD80EFZX-68UW8N0_VKGW28LX: wrong fs type, bad option, bad superblock on /dev/mapper/WDC_WD80EFZX-68UW8N0_VKGW28LX, missing codepage or helper program, or other error. ' Aug 17 10:18:18 Media unassigned.devices: Partition 'WDC_WD80EFZX-68UW8N0_VKGW28LX' cannot be mounted. Looks like it can't be mounted.
-
OK, I will mount both drives in unassigned devices and look into their contents and try to see if it looks good.. Are you thinking I should compare the drives with something like Krusader, or should a quick look at the folder structure and layout with Midnight Commander be sufficient? I disabled SMB, Docker and VM's before starting the array as I wanted to minimize anything writing to the array. If I should use Krusader, I will need to stop the array and re-enable Docker. Thanks for all the help!!
-
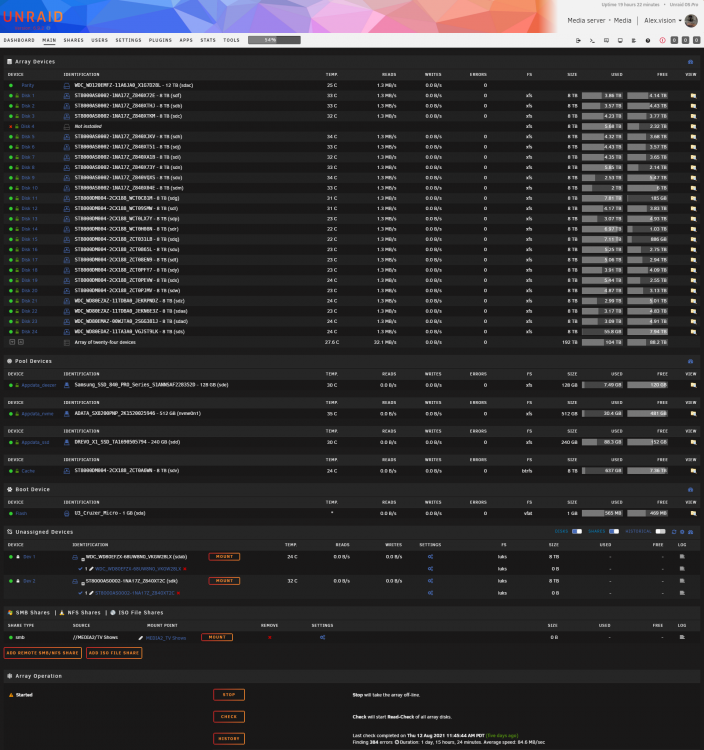
Trurl I understand what your are saying about the parity. That makes sense. I was able to unassign disk4 and start the array. Attached in the diagnostic file and a screenshot of the array. media-diagnostics-20210817-0907.zip
-
No problems with the flash drive during any of this time. I think the syslog server was not running all the time that the Unraid server was, so the log is incomplete. From the timeline, I know the New Disk 4 was being built on Aug 12, but within the last say 2 hours of it being complete is when it started showing errors for Drive 1. I was monitoring the end of the rebuild closer than any other time. I want to say it had completed 98.2+ % of the rebuild before any notices about issues with Disk1 happened. So moving forward, should I tell Unraid to rebuild Disk 4 on to the new one again, hope that Disk 1 holds out, then replace Disk 1, with the new one I just ordered? or Replace Disk 1 and hope the old disk 4 holds out, then replace it? Since starting this whole thing, I have left the mover script off, I don't think I have written anything to the array but I'm not 100% sure. If I have written anything it was just some media that can be lost. Id like to minimize loosing an entire drive, but a few media files hopefully wont be missed.
-
Normally I have the syslog mirroring to another computer, but I don't see information in it about the rebuild during that time. I am attaching it anyways, I don't really know what Im looking for. I know this is a lot of drives for 1 parity, I was running dual parity a long time ago, but I had a backplane fry the controller on 3 data drives and one of the parity drives a while ago and I have been working on building a complete backup system for my entire array. I have offloaded about half the array onto 2 new servers that will act as a pair. I still want to make a backup of the data on this system, but with just having shelled out $2500 for my other pair I just cant afford to buy another 100TB of drives during this chia mining thing. I was hoping to make it just a little longer till prices came down. Timeline 07-03-21 Last scheduled parity check (Completed with no errors) 07-15-21 Read Errors on Disk 4 Rebuild disk 4 Pending Sector Errors Disk 4 08-08-21 Replace Disk 4 with new disk Rebuild New Disk 4 Parity Finished rebuild with 384 errors Read Errors Disk 1 Shutdown array to replace Disk 1 08-16 New Disk 1 arrives, start server to begin replacement for Disk 1 Array list places old Disk 4 in array instead of New Disk 4. Yeah I can understand not wanting to look through all those smart reports, there are a bunch of them , I don't have any other smart warnings, on the main page. Though I may have marked them as "Acknowledge" so they are not showing. I also am attaching a text file of my archive notifications that were from that time period. I do get emails as soon as a problem is detected. I don't have a complete backup of this server, it is mostly media, so I could get it all back, eventually. Though I really don't want to re-rip 100TB worth of data, ouch. (Media) - Archived Notifications.txt alex.vision syslog Aug 10-12.txt
-
Hey all, Recently my array had some errors with one of my disks. I had been in the process of consolidating my array using the Unbalance plugin to free up space. Though for me this was taking forever as I have a lot of SMR drives in my array. Anyways as I was moving data around I got an alert that said: Alert [MEDIA] - Disk 4 in error state (disk dsbl) ST8000AS0002-1NA17Z_Z840XT2C (sdk) This lead me down a long road of trying to rebuild parity, then deciding that I should swap the disk with a spare from another system. I replaced that drive with WDC_WD80EFZX-68UW8N0_VKGW28LX, and rebuilt the array. While rebuilding I received another error that Disk 1 a ST8000AS0002-1NA17Z_Z840X72E was also experiencing errors. The array finished the rebuild/replace for the Disk 4 failure, but we had a heat wave roll through, so before I could look into everything I shutdown the system so it wouldn't overheat. I also bought a new drive to replace Disk 1 with and it just came in. I started up the server, getting ready to replace Disk 1, when I saw that the system had tried to use my old Disk 4 ST8000AS0002-1NA17Z_Z840XT2C instead of the new Disk 4 WDC_WD80EFZX-68UW8N0_VKGW28LX. When I tried to put the correct drive that the array had rebuilt upon, Unraid said it was wrong. I didn't want to start anything with out finding out what I should do. Smart Data shows (Old Disk 4) Current pending sector 2392 Offline uncorrectable 2392 (New Disk 4) no errors (Disk 1) Reported uncorrect 7 Current pending sector 24 Offline uncorrectable 24 I have the array offline while I try to figure out what has happened. Any advise would be greatly appreciated. media-diagnostics-20210816-1407.zip
-
Oh, ok. Ouch, these 8TB take a while, but I guess that's the cost of doing business with large drives. Thanks for the help, it is greatly appreciated. Now I have to figure out why the thing crashed in the first place. On to the next mission....
-
I guess I missed the part about it being a different log. My wife set down my dinner right as I was typing this up, so steak and potatoes made me read a bit faster than usual. I knew I was going to miss something, I so rarely have issues, that when one comes around I lose basic sense and become "that guy who can't rtfm". I've attached the log you requested. MEDIA-preclear.disk-20181009-0749.zip
-
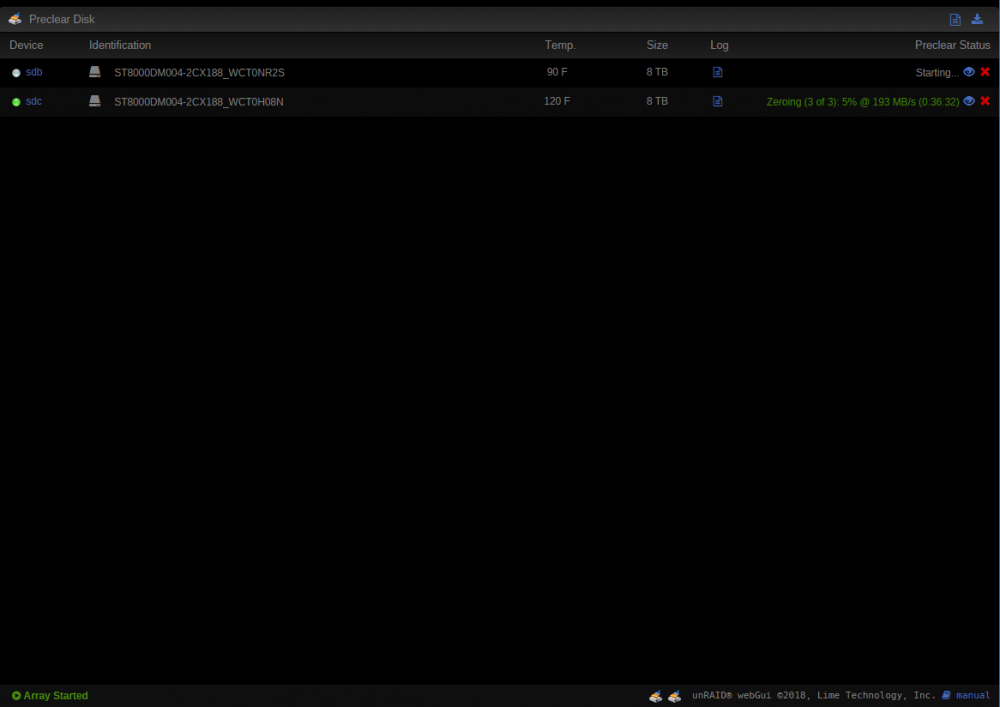
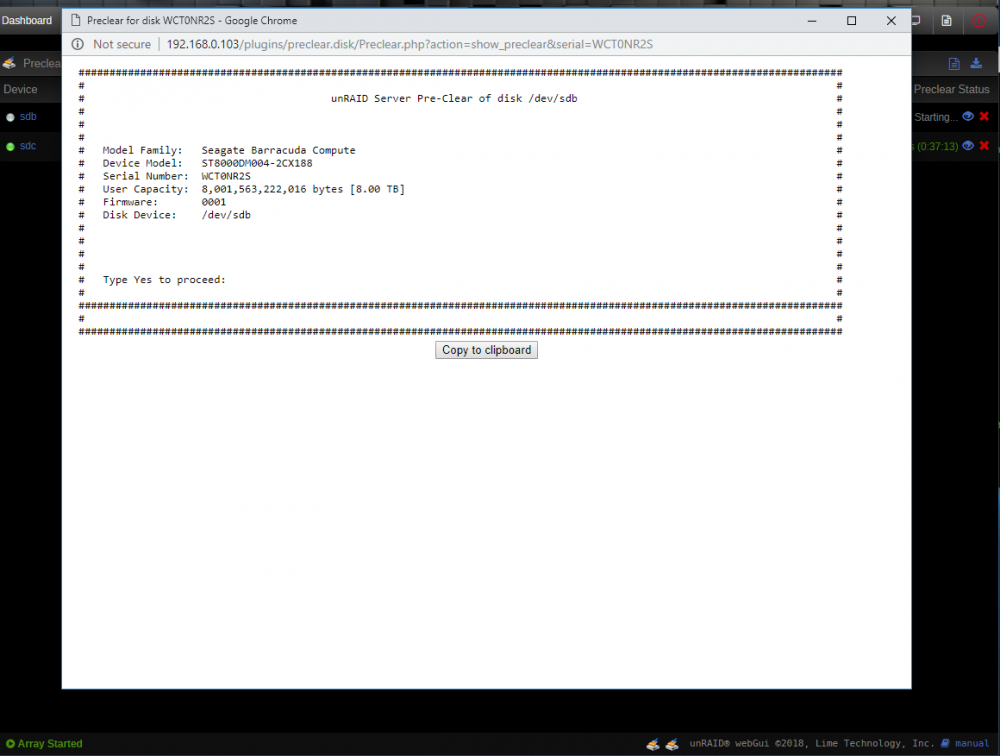
I'm experiencing a slight problem with gfjardim's preclear plugin. I was right in the middle of a 3 cycle run of preclears on 2x 8TB drives when my server locked up and the webUI and the local GUI were completely frozen. I was forced to hard reset the server. After coming on line and restarting my array, I was able to resume both preclear runs. One of them began running right from where it left off. The second drive seems to be stuck at "starting", but nothing is happening. That was over 12 hours ago. I left it overnight and while I was at work just in case. The preclear log for that run seems to be stuck at " Type Yes to proceed:" I'm running unRaid 6.5.2 Preclear Ver 2018.09.20 I know there are updates to both, I was right in the middle of clearing these drives, so I didn't want to change anything and have to start the process over. Any thoughts on what I can do to get this preclear to resume from where it left off, or do I need to start over? Can I update the preclear plugin while running a preclear on a drive? My first reaction was that I better not. Thanks for any help. syslog.txt