




Alex.vision
Members
-
Joined
-
Last visited
-
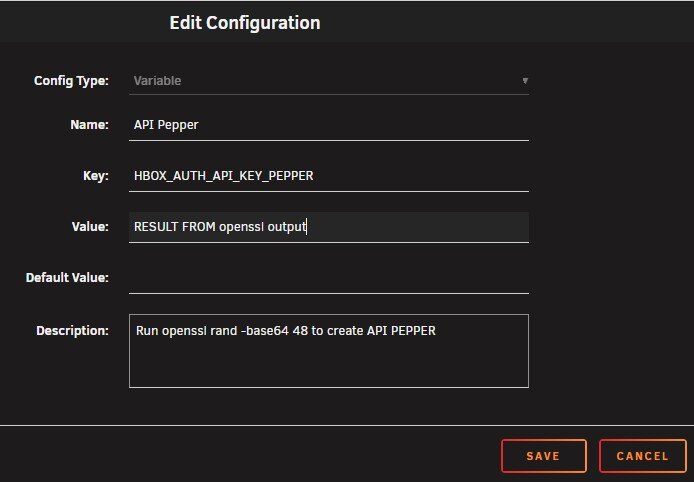
Hi everyone, An update is required for the Homebox Docker template to run after the recent update to v0.26. According to the Homebox Quick Start Guide new environment variable, HBOX_AUTH_API_KEY_PEPPER, must be added to your template. Without this variable, the container will fail to start. How to Update Your Template:Go to the Docker tab in your Unraid WebUI. Click on the Homebox icon and select Edit. Scroll to the bottom and click Add another Path, Port, Variable, Label or Device. Fill out the form with the following details: Config Type: Variable Name: API Pepper Key: HBOX_AUTH_API_KEY_PEPPER Value: Result from openssl output Run openssl rand -base64 48from the Unraid console and paste the output in the Key. Hope this helps anyone trying to start the container after the update.
-
I think they were referencing keeping their inventory up to date and accurate work take the effort of everyone at their house using it
-
I stopped the array and started it in maintenance mode. Then I went and ran xfs_repair sequentially on each disk, dm-13 was disk 14. Output of xfs_repair with no argument: Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 Metadata corruption detected at 0x438a03, xfs_inode block 0x4fb750c0/0x4000 Metadata corruption detected at 0x438a03, xfs_inode block 0x4fb750e0/0x4000 bad CRC for inode 1337413824 bad magic number 0xd42e on inode 1337413824 bad version number 0xffffff8a on inode 1337413824 inode identifier 17922074875601206692 mismatch on inode 1337413824 bad CRC for inode 1337413825 bad magic number 0x8842 on inode 1337413825 bad version number 0xffffffe5 on inode 1337413825 inode identifier 6368462513510018182 mismatch on inode 1337413825 bad CRC for inode 1337413826 bad magic number 0x770d on inode 1337413826 bad version number 0x0 on inode 1337413826 bad next_unlinked 0x886c2f30 on inode 1337413826 inode identifier 17121336769163774748 mismatch on inode 1337413826 bad CRC for inode 1337413827 bad magic number 0xc93 on inode 1337413827 bad version number 0xffffffd3 on inode 1337413827 inode identifier 12464974540121167281 mismatch on inode 1337413827 bad CRC for inode 1337413828 bad magic number 0xfbb8 on inode 1337413828 bad version number 0x5e on inode 1337413828 bad next_unlinked 0xb5123911 on inode 1337413828 inode identifier 986718105180063639 mismatch on inode 1337413828 bad CRC for inode 1337413829 bad magic number 0x9f70 on inode 1337413829 bad version number 0xffffffd1 on inode 1337413829 inode identifier 9197436450205331708 mismatch on inode 1337413829 bad CRC for inode 1337413830 bad magic number 0x6b46 on inode 1337413830 bad version number 0xffffff99 on inode 1337413830 inode identifier 10780288519564079452 mismatch on inode 1337413830 bad CRC for inode 1337413831 bad magic number 0x8643 on inode 1337413831 bad version number 0xfffffff9 on inode 1337413831 bad next_unlinked 0xa7f795d2 on inode 1337413831 inode identifier 9301951815726310928 mismatch on inode 1337413831 bad CRC for inode 1337413832 bad magic number 0xc862 on inode 1337413832 bad version number 0x72 on inode 1337413832 bad next_unlinked 0xdca10f8c on inode 1337413832 inode identifier 10771444236848622832 mismatch on inode 1337413832 bad CRC for inode 1337413833 bad magic number 0x58dc on inode 1337413833 bad version number 0xffffffa5 on inode 1337413833 inode identifier 4184536241355261363 mismatch on inode 1337413833 bad CRC for inode 1337413834 bad magic number 0x6724 on inode 1337413834 bad version number 0xffffffd0 on inode 1337413834 inode identifier 6209372824773348707 mismatch on inode 1337413834 bad CRC for inode 1337413835 bad magic number 0x2dc on inode 1337413835 bad version number 0xffffffb9 on inode 1337413835 bad next_unlinked 0xc058bc35 on inode 1337413835 inode identifier 1922686418770547128 mismatch on inode 1337413835 bad CRC for inode 1337413836 bad magic number 0xddef on inode 1337413836 bad version number 0xffffff92 on inode 1337413836 bad next_unlinked 0xd1c0a2a3 on inode 1337413836 inode identifier 7560397607761111723 mismatch on inode 1337413836 bad CRC for inode 1337413837 bad magic number 0x6f6c on inode 1337413837 bad version number 0x1 on inode 1337413837 bad next_unlinked 0xd1c18aa4 on inode 1337413837 inode identifier 6718994736492193078 mismatch on inode 1337413837 bad CRC for inode 1337413838 bad magic number 0xf3db on inode 1337413838 bad version number 0x38 on inode 1337413838 bad next_unlinked 0xdfdae737 on inode 1337413838 inode identifier 15373977038794471499 mismatch on inode 1337413838 bad CRC for inode 1337413839 bad magic number 0x32be on inode 1337413839 bad version number 0xffffffe7 on inode 1337413839 inode identifier 3850874889388372863 mismatch on inode 1337413839 bad CRC for inode 1337413840 bad magic number 0xf9f8 on inode 1337413840 bad version number 0xffffffea on inode 1337413840 inode identifier 11957124023933224744 mismatch on inode 1337413840 bad CRC for inode 1337413841 bad magic number 0x3da1 on inode 1337413841 bad version number 0xffffff8f on inode 1337413841 inode identifier 9943156008262056140 mismatch on inode 1337413841 bad CRC for inode 1337413842 bad magic number 0x78bc on inode 1337413842 bad version number 0x6c on inode 1337413842 bad next_unlinked 0xb6d2583d on inode 1337413842 inode identifier 16425185457010603707 mismatch on inode 1337413842 bad CRC for inode 1337413843 bad magic number 0xcad7 on inode 1337413843 bad version number 0xffffffff on inode 1337413843 bad next_unlinked 0xf540ff58 on inode 1337413843 inode identifier 8301798493074156569 mismatch on inode 1337413843 bad CRC for inode 1337413844 bad magic number 0x2201 on inode 1337413844 bad version number 0xffffffe3 on inode 1337413844 inode identifier 14193680956722667239 mismatch on inode 1337413844 bad CRC for inode 1337413845 bad magic number 0x728f on inode 1337413845 bad version number 0xffffffd4 on inode 1337413845 bad next_unlinked 0x80a56139 on inode 1337413845 inode identifier 6423524210835257071 mismatch on inode 1337413845 bad CRC for inode 1337413846 bad magic number 0xef78 on inode 1337413846 bad version number 0x3a on inode 1337413846 inode identifier 13961399463325097183 mismatch on inode 1337413846 bad CRC for inode 1337413847 bad magic number 0x2c3c on inode 1337413847 bad version number 0xffffffb9 on inode 1337413847 bad next_unlinked 0xc10a86e4 on inode 1337413847 inode identifier 16338827983165331358 mismatch on inode 1337413847 bad CRC for inode 1337413848 bad magic number 0xc785 on inode 1337413848 bad version number 0x74 on inode 1337413848 bad next_unlinked 0xd1ca6649 on inode 1337413848 inode identifier 17609023455849890315 mismatch on inode 1337413848 bad CRC for inode 1337413849 bad magic number 0x311 on inode 1337413849 bad version number 0x5f on inode 1337413849 inode identifier 5306338147324273232 mismatch on inode 1337413849 bad CRC for inode 1337413850 bad magic number 0x2130 on inode 1337413850 bad version number 0x19 on inode 1337413850 bad next_unlinked 0x8fbbebdd on inode 1337413850 inode identifier 9222025504578170684 mismatch on inode 1337413850 bad CRC for inode 1337413851 bad magic number 0xff9f on inode 1337413851 bad version number 0xffffffe6 on inode 1337413851 inode identifier 2157175030203333371 mismatch on inode 1337413851 bad CRC for inode 1337413852 bad magic number 0x8e2b on inode 1337413852 bad version number 0xc on inode 1337413852 inode identifier 3804752428210338703 mismatch on inode 1337413852 bad CRC for inode 1337413853 bad magic number 0x274b on inode 1337413853 bad version number 0x2b on inode 1337413853 bad next_unlinked 0xb59bc808 on inode 1337413853 inode identifier 14958434368370502431 mismatch on inode 1337413853 bad CRC for inode 1337413854 bad magic number 0xb18 on inode 1337413854 bad version number 0xa on inode 1337413854 inode identifier 3365263010041343481 mismatch on inode 1337413854 bad CRC for inode 1337413855 bad magic number 0x9bd7 on inode 1337413855 bad version number 0x64 on inode 1337413855 bad next_unlinked 0xa050b6e0 on inode 1337413855 inode identifier 13344901019836513918 mismatch on inode 1337413855 bad CRC for inode 1337413856 bad magic number 0x5c40 on inode 1337413856 bad version number 0xfffffff0 on inode 1337413856 inode identifier 16408388291873163339 mismatch on inode 1337413856 bad CRC for inode 1337413857 bad magic number 0xa1bf on inode 1337413857 bad version number 0xffffffef on inode 1337413857 inode identifier 2753195317298073746 mismatch on inode 1337413857 bad CRC for inode 1337413858 bad magic number 0xf7a9 on inode 1337413858 bad version number 0x70 on inode 1337413858 bad next_unlinked 0x9e3d19f8 on inode 1337413858 inode identifier 9083403555133701639 mismatch on inode 1337413858 bad CRC for inode 1337413859 bad magic number 0x2f4c on inode 1337413859 bad version number 0xffffffdf on inode 1337413859 bad next_unlinked 0xcdb4bcc8 on inode 1337413859 inode identifier 13030379633202358370 mismatch on inode 1337413859 bad CRC for inode 1337413860 bad magic number 0x957d on inode 1337413860 bad version number 0x36 on inode 1337413860 bad next_unlinked 0xfde52092 on inode 1337413860 inode identifier 16325000655104360023 mismatch on inode 1337413860 bad CRC for inode 1337413861 bad magic number 0x27b5 on inode 1337413861 bad version number 0xffffffbb on inode 1337413861 bad next_unlinked 0xbd2a2bd0 on inode 1337413861 inode identifier 17267916023967423496 mismatch on inode 1337413861 bad CRC for inode 1337413862 bad magic number 0xfaf3 on inode 1337413862 bad version number 0xffffff89 on inode 1337413862 inode identifier 7845603842249960932 mismatch on inode 1337413862 bad CRC for inode 1337413863 bad magic number 0x9169 on inode 1337413863 bad version number 0x69 on inode 1337413863 inode identifier 10404274597415308852 mismatch on inode 1337413863 bad CRC for inode 1337413864 bad magic number 0x6ff2 on inode 1337413864 bad version number 0xffffff92 on inode 1337413864 bad next_unlinked 0xc1d7a558 on inode 1337413864 inode identifier 8416659992483045786 mismatch on inode 1337413864 bad CRC for inode 1337413865 bad magic number 0xdf70 on inode 1337413865 bad version number 0xffffffa3 on inode 1337413865 inode identifier 8075877313302690646 mismatch on inode 1337413865 bad CRC for inode 1337413866 bad magic number 0xa78a on inode 1337413866 bad version number 0xffffffd1 on inode 1337413866 inode identifier 503808664493179231 mismatch on inode 1337413866 bad CRC for inode 1337413867 bad magic number 0x6aee on inode 1337413867 bad version number 0xfffffffd on inode 1337413867 inode identifier 14760091798483041551 mismatch on inode 1337413867 bad CRC for inode 1337413868 bad magic number 0x49e2 on inode 1337413868 bad version number 0xffffffd3 on inode 1337413868 bad next_unlinked 0xa6b00107 on inode 1337413868 inode identifier 9759543784720780610 mismatch on inode 1337413868 bad CRC for inode 1337413869 bad magic number 0xa3ac on inode 1337413869 bad version number 0x39 on inode 1337413869 bad next_unlinked 0xfe7ff71d on inode 1337413869 inode identifier 8192981107676173907 mismatch on inode 1337413869 bad CRC for inode 1337413870 bad magic number 0x6ea4 on inode 1337413870 bad version number 0x79 on inode 1337413870 inode identifier 11372386283751230817 mismatch on inode 1337413870 bad CRC for inode 1337413871 bad magic number 0x5169 on inode 1337413871 bad version number 0xffffffc3 on inode 1337413871 bad next_unlinked 0xdfc36b2e on inode 1337413871 inode identifier 14038056170548045996 mismatch on inode 1337413871 bad CRC for inode 1337413872 bad magic number 0xc2d7 on inode 1337413872 bad version number 0x2c on inode 1337413872 inode identifier 11159598621810948527 mismatch on inode 1337413872 bad CRC for inode 1337413873 bad magic number 0x77e3 on inode 1337413873 bad version number 0x42 on inode 1337413873 bad next_unlinked 0xb246fc40 on inode 1337413873 inode identifier 14334579915808098849 mismatch on inode 1337413873 bad CRC for inode 1337413874 bad magic number 0x271a on inode 1337413874 bad version number 0xffffff98 on inode 1337413874 inode identifier 9176291537863552833 mismatch on inode 1337413874 bad CRC for inode 1337413875 bad magic number 0xb536 on inode 1337413875 bad version number 0x28 on inode 1337413875 bad next_unlinked 0xa0e5c576 on inode 1337413875 inode identifier 4843254420958294146 mismatch on inode 1337413875 bad CRC for inode 1337413876 bad magic number 0x1397 on inode 1337413876 bad version number 0x77 on inode 1337413876 bad next_unlinked 0xd5dac173 on inode 1337413876 inode identifier 12248959041243266356 mismatch on inode 1337413876 bad CRC for inode 1337413877 bad magic number 0xd3fa on inode 1337413877 bad version number 0xffffffd0 on inode 1337413877 inode identifier 14813339448178687684 mismatch on inode 1337413877 bad CRC for inode 1337413878 bad magic number 0x4efb on inode 1337413878 bad version number 0xffffffff on inode 1337413878 bad next_unlinked 0xe9eca67d on inode 1337413878 inode identifier 9560660240498580168 mismatch on inode 1337413878 bad CRC for inode 1337413879 bad magic number 0xc9ab on inode 1337413879 bad version number 0x69 on inode 1337413879 inode identifier 6870943572697468751 mismatch on inode 1337413879 bad CRC for inode 1337413880 bad magic number 0xaeb6 on inode 1337413880 bad version number 0xffffff9e on inode 1337413880 bad next_unlinked 0xc40e06b6 on inode 1337413880 inode identifier 10305720418651753316 mismatch on inode 1337413880 bad CRC for inode 1337413881 bad magic number 0xbd20 on inode 1337413881 bad version number 0x6c on inode 1337413881 inode identifier 11634100825141329677 mismatch on inode 1337413881 bad CRC for inode 1337413882 bad magic number 0xd812 on inode 1337413882 bad version number 0xffffffa0 on inode 1337413882 bad next_unlinked 0x9f01ab21 on inode 1337413882 inode identifier 2050986944037637798 mismatch on inode 1337413882 bad CRC for inode 1337413883 bad magic number 0x1892 on inode 1337413883 bad version number 0xffffffcb on inode 1337413883 bad next_unlinked 0x9b7879cf on inode 1337413883 inode identifier 11647272854504042307 mismatch on inode 1337413883 bad CRC for inode 1337413884 bad magic number 0x803d on inode 1337413884 bad version number 0xffffff9a on inode 1337413884 bad next_unlinked 0xfdcd13af on inode 1337413884 inode identifier 3341531756162138365 mismatch on inode 1337413884 bad CRC for inode 1337413885 bad magic number 0x47f9 on inode 1337413885 bad version number 0xffffffc4 on inode 1337413885 bad next_unlinked 0xe4ed7a1f on inode 1337413885 inode identifier 15243022173953876915 mismatch on inode 1337413885 bad CRC for inode 1337413886 bad magic number 0xfec0 on inode 1337413886 bad version number 0xfffffff6 on inode 1337413886 bad next_unlinked 0xa52fb285 on inode 1337413886 inode identifier 16448132619544346858 mismatch on inode 1337413886 bad CRC for inode 1337413887 bad magic number 0xe9c on inode 1337413887 bad version number 0x40 on inode 1337413887 inode identifier 12503458612845411036 mismatch on inode 1337413887 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - process newly discovered inodes... 151d82dff680: Badness in key lookup (length) bp=(bno 0x4fb750c0, len 16384 bytes) key=(bno 0x4fb750c0, len 4096 bytes) 151d82dff680: Badness in key lookup (length) bp=(bno 0x4fb750e0, len 16384 bytes) key=(bno 0x4fb750e0, len 4096 bytes) Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 2 - agno = 5 - agno = 3 - agno = 6 - agno = 1 - agno = 7 - agno = 4 entry "UCUK0HBIBWgM2c4vsPhkYY4w" at block 1 offset 464 in directory inode 169 references non-existent inode 1337413824 clearing inode number in entry at offset 464... entry "UCU-ljC8EvKZFhJ-pct_5rMQ" at block 1 offset 784 in directory inode 169 references non-existent inode 1337413830 clearing inode number in entry at offset 784... entry "Tr8-ofSpyxU.jpg" at block 0 offset 96 in directory inode 172 references non-existent inode 1337413835 clearing inode number in entry at offset 96... entry "tQN6o4jbJiM.jpg" at block 0 offset 128 in directory inode 172 references non-existent inode 1337413839 clearing inode number in entry at offset 128... entry "TlcCJ1iMw4c.jpg" at block 0 offset 312 in directory inode 172 references non-existent inode 1337413834 clearing inode number in entry at offset 312... entry "tW-PSwxyNuA.jpg" at block 0 offset 344 in directory inode 172 references non-existent inode 1337413840 clearing inode number in entry at offset 344... entry "t3jNFcH4G8I.jpg" at block 0 offset 744 in directory inode 172 references non-existent inode 1337413836 clearing inode number in entry at offset 744... entry "tXWebwlfqfc.jpg" at block 0 offset 776 in directory inode 172 references non-existent inode 1337413841 clearing inode number in entry at offset 776... entry "t4wPbumPXYo.jpg" at block 0 offset 1896 in directory inode 172 references non-existent inode 1337413837 clearing inode number in entry at offset 1896... entry "tYHdi3eXCrQ.jpg" at block 0 offset 1928 in directory inode 172 references non-existent inode 1337413842 clearing inode number in entry at offset 1928... entry "t6QyS7TJ0yc.jpg" at block 0 offset 2616 in directory inode 172 references non-existent inode 1337413838 clearing inode number in entry at offset 2616... entry "teDHr8IDGTU.jpg" at block 0 offset 2648 in directory inode 172 references non-existent inode 1337413843 clearing inode number in entry at offset 2648... entry "TGunTxeoRQo.jpg" at block 0 offset 3448 in directory inode 172 references non-existent inode 1337413826 clearing inode number in entry at offset 3448... entry "TTZI9-aEh-M.jpg" at block 0 offset 3520 in directory inode 172 references non-existent inode 1337413831 clearing inode number in entry at offset 3520... entry "TbdNZuCvEh4.jpg" at block 0 offset 3592 in directory inode 172 references non-existent inode 1337413833 clearing inode number in entry at offset 3592... entry "H4RWJMiGikc.jpg" at block 0 offset 2656 in directory inode 34371802 references non-existent inode 1337413847 clearing inode number in entry at offset 2656... entry "HFd_pEUgcoQ.jpg" at block 0 offset 2728 in directory inode 34371802 references non-existent inode 1337413848 clearing inode number in entry at offset 2728... entry "HHSKl8ocC4Y.jpg" at block 0 offset 2800 in directory inode 34371802 references non-existent inode 1337413849 clearing inode number in entry at offset 2800... entry "HdWniqLRL9k.jpg" at block 0 offset 2872 in directory inode 34371802 references non-existent inode 1337413850 clearing inode number in entry at offset 2872... entry "h1hRldbgyaw.jpg" at block 0 offset 2944 in directory inode 34371802 references non-existent inode 1337413851 clearing inode number in entry at offset 2944... entry "hJi8cIsIwWA.jpg" at block 0 offset 3016 in directory inode 34371802 references non-existent inode 1337413852 clearing inode number in entry at offset 3016... entry "hUeeMbW3kp8.jpg" at block 0 offset 3160 in directory inode 34371802 references non-existent inode 1337413854 clearing inode number in entry at offset 3160... entry "hjky05iupFY.jpg" at block 0 offset 3304 in directory inode 34371802 references non-existent inode 1337413856 clearing inode number in entry at offset 3304... entry "htgATpqCYYc.jpg" at block 0 offset 3376 in directory inode 34371802 references non-existent inode 1337413857 clearing inode number in entry at offset 3376... entry "hv5tgjGPkLk.jpg" at block 0 offset 3448 in directory inode 34371802 references non-existent inode 1337413858 clearing inode number in entry at offset 3448... entry "wuCtm8JcT5c.jpg" at block 0 offset 96 in directory inode 45903436 references non-existent inode 1337413875 clearing inode number in entry at offset 96... entry "wcof-Noho9Q.jpg" at block 0 offset 312 in directory inode 45903436 references non-existent inode 1337413872 clearing inode number in entry at offset 312... entry "W9IzDL9xzjQ.jpg" at block 0 offset 2728 in directory inode 45903436 references non-existent inode 1337413860 clearing inode number in entry at offset 2728... entry "WIwn-sy7N5U.jpg" at block 0 offset 2800 in directory inode 45903436 references non-existent inode 1337413861 clearing inode number in entry at offset 2800... entry "WOpCDHRiElw.jpg" at block 0 offset 2872 in directory inode 45903436 references non-existent inode 1337413862 clearing inode number in entry at offset 2872... entry "WYMRKZ4HWbE.jpg" at block 0 offset 2944 in directory inode 45903436 references non-existent inode 1337413863 clearing inode number in entry at offset 2944... entry "WhEZ11xFQEU.jpg" at block 0 offset 3016 in directory inode 45903436 references non-existent inode 1337413864 clearing inode number in entry at offset 3016... entry "WhYRg_oCQeE.jpg" at block 0 offset 3088 in directory inode 45903436 references non-existent inode 1337413865 clearing inode number in entry at offset 3088... entry "WzN5IEIZ3Ew.jpg" at block 0 offset 3160 in directory inode 45903436 references non-existent inode 1337413866 clearing inode number in entry at offset 3160... entry "w6AKyVlNQ9Q.jpg" at block 0 offset 3232 in directory inode 45903436 references non-existent inode 1337413867 clearing inode number in entry at offset 3232... entry "w9nUcpvQ-zI.jpg" at block 0 offset 3304 in directory inode 45903436 references non-existent inode 1337413868 clearing inode number in entry at offset 3304... entry "wNSwFWNLDvA.jpg" at block 0 offset 3376 in directory inode 45903436 references non-existent inode 1337413869 clearing inode number in entry at offset 3376... entry "wOwUZqlfmqI.jpg" at block 0 offset 3448 in directory inode 45903436 references non-existent inode 1337413870 clearing inode number in entry at offset 3448... entry "wUOiNtcV15E.jpg" at block 0 offset 3520 in directory inode 45903436 references non-existent inode 1337413871 clearing inode number in entry at offset 3520... entry "wkFR0cdmCf4.jpg" at block 0 offset 3592 in directory inode 45903436 references non-existent inode 1337413873 clearing inode number in entry at offset 3592... entry "wltEkq1BjTc.jpg" at block 0 offset 3624 in directory inode 45903436 references non-existent inode 1337413874 clearing inode number in entry at offset 3624... entry "wzG5obJntEk.jpg" at block 0 offset 3656 in directory inode 45903436 references non-existent inode 1337413887 clearing inode number in entry at offset 3656... entry "n2YVkF3ZNZU.en.vtt" at block 1 offset 992 in directory inode 45903457 references non-existent inode 1337413828 clearing inode number in entry at offset 992... entry "Berlin Calling (2008)" at block 0 offset 232 in directory inode 5434559503 references non-existent inode 1337413883 clearing inode number in entry at offset 232... entry "Body and Soul (1947)" at block 0 offset 272 in directory inode 5434559503 references non-existent inode 1337413885 clearing inode number in entry at offset 272... entry "rt21DJz7yZg.en.vtt" at block 0 offset 280 in directory inode 279924638 references non-existent inode 1337413829 clearing inode number in entry at offset 280... entry "SD" in shortform directory 2853095751 references non-existent inode 1337413876 junking entry "SD" in directory inode 2853095751 entry "system.xml" at block 0 offset 120 in directory inode 1242596405 references non-existent inode 1337413844 clearing inode number in entry at offset 120... entry "mb.lic" at block 0 offset 144 in directory inode 1242596405 references non-existent inode 1337413845 clearing inode number in entry at offset 144... entry "cinemamode.xml" at block 0 offset 168 in directory inode 1242596405 references non-existent inode 1337413846 clearing inode number in entry at offset 168... entry "branding.xml" at block 0 offset 200 in directory inode 1242596405 references non-existent inode 1337413853 clearing inode number in entry at offset 200... entry "encoding.xml" at block 0 offset 224 in directory inode 1242596405 references non-existent inode 1337413855 clearing inode number in entry at offset 224... entry "metadata.xml" at block 0 offset 248 in directory inode 1242596405 references non-existent inode 1337413859 clearing inode number in entry at offset 248... Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... bad hash table for directory inode 169 (no data entry): rebuilding rebuilding directory inode 169 bad hash table for directory inode 172 (no data entry): rebuilding rebuilding directory inode 172 bad hash table for directory inode 34371802 (no data entry): rebuilding rebuilding directory inode 34371802 bad hash table for directory inode 45903436 (no data entry): rebuilding rebuilding directory inode 45903436 bad hash table for directory inode 45903457 (no data entry): rebuilding rebuilding directory inode 45903457 bad hash table for directory inode 279924638 (no data entry): rebuilding rebuilding directory inode 279924638 bad hash table for directory inode 1242596405 (no data entry): rebuilding rebuilding directory inode 1242596405 bad hash table for directory inode 5434559503 (no data entry): rebuilding rebuilding directory inode 5434559503 - traversal finished ... - moving disconnected inodes to lost+found ... disconnected inode 34068247, moving to lost+found disconnected inode 40248873, moving to lost+found disconnected inode 127970674, moving to lost+found disconnected inode 1755570736, moving to lost+found disconnected inode 1755570741, moving to lost+found disconnected dir inode 2980512120, moving to lost+found disconnected dir inode 2980512122, moving to lost+found disconnected dir inode 5434559500, moving to lost+found disconnected dir inode 7501876191, moving to lost+found disconnected dir inode 9317232958, moving to lost+found disconnected dir inode 11738005425, moving to lost+found disconnected dir inode 13804049261, moving to lost+found Phase 7 - verify and correct link counts... resetting inode 169 nlinks from 159 to 157 resetting inode 5434559503 nlinks from 11 to 9 resetting inode 127970675 nlinks from 2 to 9 resetting inode 2853095751 nlinks from 9 to 8 done Then I ran another xfx_repair -n and this was the output: Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 3 - agno = 6 - agno = 1 - agno = 5 - agno = 2 - agno = 4 - agno = 7 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... No modify flag set, skipping filesystem flush and exiting. Next I restarted the array without maintenance mode selected. The files I was missing now show in the windows file explorer, and my docker container starts with out issue.
-
Hey all, Today I was trying to figure out why one of my docker containers seems to be stuck in a boot loop. While reading through its logs I came across the line OSError: [Errno 117] Structure needs cleaning: '/youtube/UCUK0HBIBWgM2c4vsPhkYY4w' So I tried opening the 'youtube' share from my windows pc, this share should contain 30+TB of YouTube videos. When I opened it, it showed as completely empty. Logging into the web UI I navigated to the shares page and clicked compute to see if quickly calculate if any files were on the disks. It then populated the shares size across all my disks, so the data is still showing as taking up space. I opened the syslog and was greeted with many errors like the following. ar 26 09:48:15 Media kernel: XFS (dm-13): Metadata corruption detected at xfs_buf_ioend+0xac/0x384 [xfs], xfs_inode block 0x4fb750c0 xfs_inode_buf_verify Mar 26 09:48:15 Media kernel: XFS (dm-13): Unmount and run xfs_repair Mar 26 09:48:15 Media kernel: XFS (dm-13): First 128 bytes of corrupted metadata buffer: Mar 26 09:48:15 Media kernel: 00000000: d4 2e 23 99 8a 07 ea dc ed a1 3d 66 4d 29 4b c6 ..#.......=fM)K. Mar 26 09:48:15 Media kernel: 00000010: 10 06 d2 3d bb 0f 97 c9 fd c2 7f 39 ef f0 66 19 ...=.......9..f. Mar 26 09:48:15 Media kernel: 00000020: e4 29 db f8 e3 4c 8d f6 ab 77 39 44 97 c7 32 31 .)...L...w9D..21 Mar 26 09:48:15 Media kernel: 00000030: 6c a3 da 9d 1b 22 7d b9 ef 23 a3 2e e7 44 f6 1e l...."}..#...D.. Mar 26 09:48:15 Media kernel: 00000040: 8e 0c a9 28 aa ab f3 fa 46 f0 83 28 a0 e6 52 74 ...(....F..(..Rt Mar 26 09:48:15 Media kernel: 00000050: d6 28 ab 0d b5 68 e9 bc ed d0 ef 19 6f 69 e0 ed .(...h......oi.. Mar 26 09:48:15 Media kernel: 00000060: 55 83 a6 9a 6f 84 21 3f 0b 59 0e 11 93 5c 76 09 U...o.!?.Y...\v. Mar 26 09:48:15 Media kernel: 00000070: dc 22 35 40 7f f1 cf 35 12 33 18 08 2e f5 21 25 ."[email protected]....!% Mar 26 09:48:15 Media kernel: XFS (dm-13): metadata I/O error in "xfs_imap_to_bp+0x50/0x70 [xfs]" at daddr 0x4fb750c0 len 32 error 117 Mar 26 09:48:15 Media kernel: XFS (dm-13): Metadata corruption detected at xfs_buf_ioend+0xac/0x384 [xfs], xfs_inode block 0x4fb750c0 xfs_inode_buf_verify Mar 26 09:48:15 Media kernel: XFS (dm-13): Unmount and run xfs_repair Mar 26 09:48:15 Media kernel: XFS (dm-13): First 128 bytes of corrupted metadata buffer: Mar 26 09:48:15 Media kernel: 00000000: d4 2e 23 99 8a 07 ea dc ed a1 3d 66 4d 29 4b c6 ..#.......=fM)K. Mar 26 09:48:15 Media kernel: 00000010: 10 06 d2 3d bb 0f 97 c9 fd c2 7f 39 ef f0 66 19 ...=.......9..f. Mar 26 09:48:15 Media kernel: 00000020: e4 29 db f8 e3 4c 8d f6 ab 77 39 44 97 c7 32 31 .)...L...w9D..21 Mar 26 09:48:15 Media kernel: 00000030: 6c a3 da 9d 1b 22 7d b9 ef 23 a3 2e e7 44 f6 1e l...."}..#...D.. Mar 26 09:48:15 Media kernel: 00000040: 8e 0c a9 28 aa ab f3 fa 46 f0 83 28 a0 e6 52 74 ...(....F..(..Rt Mar 26 09:48:15 Media kernel: 00000050: d6 28 ab 0d b5 68 e9 bc ed d0 ef 19 6f 69 e0 ed .(...h......oi.. Mar 26 09:48:15 Media kernel: 00000060: 55 83 a6 9a 6f 84 21 3f 0b 59 0e 11 93 5c 76 09 U...o.!?.Y...\v. Mar 26 09:48:15 Media kernel: 00000070: dc 22 35 40 7f f1 cf 35 12 33 18 08 2e f5 21 25 ."[email protected]....!% Mar 26 09:48:15 Media kernel: XFS (dm-13): metadata I/O error in "xfs_imap_to_bp+0x50/0x70 [xfs]" at daddr 0x4fb750c0 len 32 error 117 I am attaching my diagnostic file, for further help. I see the recommendation in the log is to run xfs_repair on dm-13 but I don't know for certain which disk that is. Is there a good chance at recovering the data that isn't showing in explorer. This data is split across several drives, do I need to run xfs_repair on all of them? Thanks for any help. -Alex media-diagnostics-20240330-0930.zip
-
Update This command has been changed in the quick start guide to HBOX_OPTIONS_ALLOW_REGISTRATION
-
If you want to shut down your server, you are more than welcome to. It won’t hurt anything. Pressing the power button will initiate a clean shutdown of the system just like any other computer.
-
Never mind I figured it out. I am an idiot, my flash drive was full. I saw another post about memory and it made me look at my flash utilization. Nvidia driver update filled my tiny flash drive up and I forgot to clear out the older version. Thanks for the help. Sometimes its just the simplest things.
-
OK, I tried again and got the same error. I was able to manually download the .tgz from your github page, so Im assuming its something on my end. When I get home and can stop my containers, I will remove the plugin reboot and reinstall.
-
Trying to install the latest update, getting an error. plugin: updating: unassigned.devices.plg plugin: downloading: unassigned.devices-2022.11.11.tgz ... 8% plugin: unassigned.devices-2022.11.11.tgz download failure: File I/O error Executing hook script: post_plugin_checks Is this something wrong on my end, or the file host? Edit: on UnRaid 6.11.3
-
I was able to pull the following information. 221107 13:44:41 mysqld_safe Starting mysqld daemon with databases from /config/databases 221109 14:34:01 mysqld_safe Logging to '/config/databases/mysql_safe.log'. 221109 14:34:01 mysqld_safe Starting mysqld daemon with databases from /config/databases 221111 14:01:59 mysqld_safe Logging to '/config/databases/189c729a4305.err'. 221111 14:01:59 mysqld_safe Starting mysqld daemon with databases from /config/databases 221111 14:12:19 mysqld_safe Logging to '/config/databases/189c729a4305.err'. 221111 14:12:19 mysqld_safe Starting mysqld daemon with databases from /config/databases 221111 14:14:13 mysqld_safe Logging to '/config/databases/189c729a4305.err'. 221111 14:14:13 mysqld_safe Starting mysqld daemon with databases from /config/databases 221111 15:01:04 mysqld_safe Logging to '/config/databases/c721f46dfcab.err'. 221111 15:01:04 mysqld_safe Starting mysqld daemon with databases from /config/databases 221111 15:31:31 mysqld_safe Logging to '/config/databases/c721f46dfcab.err'. 221111 15:31:31 mysqld_safe Starting mysqld daemon with databases from /config/databases When I looked at 189c729a4305.err I found: 221111 14:12:21 mysqld_safe mysqld from pid file /var/run/mysqld/mysqld.pid ended 221111 14:14:13 mysqld_safe Starting mysqld daemon with databases from /config/databases 2022-11-11 14:14:13 0 [Note] /usr/sbin/mysqld (mysqld 10.3.37-MariaDB-1:10.3.37+maria~deb10-log) starting as process 297 ... /usr/sbin/mysqld: One can only use the --user switch if running as root 2022-11-11 14:14:13 0 [Note] InnoDB: Using Linux native AIO 2022-11-11 14:14:13 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins 2022-11-11 14:14:13 0 [Note] InnoDB: Uses event mutexes 2022-11-11 14:14:13 0 [Note] InnoDB: Compressed tables use zlib 1.2.11 2022-11-11 14:14:13 0 [Note] InnoDB: Number of pools: 1 2022-11-11 14:14:13 0 [Note] InnoDB: Using SSE2 crc32 instructions 2022-11-11 14:14:13 0 [Note] InnoDB: Initializing buffer pool, total size = 256M, instances = 1, chunk size = 128M 2022-11-11 14:14:13 0 [Note] InnoDB: Completed initialization of buffer pool 2022-11-11 14:14:13 0 [Note] InnoDB: If the mysqld execution user is authorized, page cleaner thread priority can be changed. See the man page of setpriority(). 2022-11-11 14:14:13 0 [Note] InnoDB: Transaction 6976 was in the XA prepared state. 2022-11-11 14:14:13 0 [Note] InnoDB: 1 transaction(s) which must be rolled back or cleaned up in total 0 row operations to undo 2022-11-11 14:14:13 0 [Note] InnoDB: Trx id counter is 6977 2022-11-11 14:14:13 0 [Note] InnoDB: 128 out of 128 rollback segments are active. 2022-11-11 14:14:13 0 [Note] InnoDB: Starting in background the rollback of recovered transactions 2022-11-11 14:14:13 0 [Note] InnoDB: Rollback of non-prepared transactions completed 2022-11-11 14:14:13 0 [Note] InnoDB: Creating shared tablespace for temporary tables 2022-11-11 14:14:13 0 [Note] InnoDB: Setting file './ibtmp1' size to 12 MB. Physically writing the file full; Please wait ... 2022-11-11 14:14:13 0 [Note] InnoDB: File './ibtmp1' size is now 12 MB. 2022-11-11 14:14:13 0 [Note] InnoDB: 10.3.37 started; log sequence number 4990257; transaction id 6978 2022-11-11 14:14:13 0 [Note] InnoDB: Loading buffer pool(s) from /config/databases/ib_buffer_pool 2022-11-11 14:14:13 0 [Note] Plugin 'FEEDBACK' is disabled. 2022-11-11 14:14:13 0 [Note] InnoDB: Starting recovery for XA transactions... 2022-11-11 14:14:13 0 [Note] InnoDB: Transaction 6976 in prepared state after recovery 2022-11-11 14:14:13 0 [Note] InnoDB: Transaction contains changes to 1 rows 2022-11-11 14:14:13 0 [Note] InnoDB: 1 transactions in prepared state after recovery 2022-11-11 14:14:13 0 [Note] Found 1 prepared transaction(s) in InnoDB 2022-11-11 14:14:13 0 [ERROR] Found 1 prepared transactions! It means that mysqld was not shut down properly last time and critical recovery information (last binlog or tc.log file) was manually deleted after a crash. You have to start mysqld with --tc-heuristic-recover switch to commit or rollback pending transactions. 2022-11-11 14:14:13 0 [ERROR] Aborting 221111 14:14:15 mysqld_safe mysqld from pid file /var/run/mysqld/mysqld.pid ended I do have another location running this docker, it updated with no issues. So I don't know that its the update that caused the issue. I did try to run jasonbean/guacamole:1.4.0 already but it still had the same error, so perhaps what ever is borked mysql stayed with it. I didn't want to have to set up all my RDP sessions and 2FA, so I tried it on a backup config folder. I can restore from my last docker backup, or if it doesn't work I can just delete the container and reinstall. I just wanted to skip the hassle.
-
It looks like your DB is corrupted. Not sure what your next steps need to be, perhaps use DB corruption in a search with Radarr. Do you have a backup of Radarr, you could just try to spin up a new container and import a backup
-
My container just updated while I was connected, when it came back up I received an error when connecting. ERROR An error has occurred and this action cannot be completed. If the problem persists, please notify your system administrator or check your system logs. I looked in the docker log, but found no obvious error. ---------------------- User UID: 99 User GID: 100 ---------------------- Using existing properties file. Using existing MySQL extension. Using existing TOTP extension. No permissions changes needed. Database exists. Database upgrade not needed. 2022-11-11 14:14:12,375 INFO Included extra file "/etc/supervisor/conf.d/supervisord.conf" during parsing 2022-11-11 14:14:12,375 INFO Set uid to user 0 succeeded 2022-11-11 14:14:12,376 INFO supervisord started with pid 27 2022-11-11 14:14:13,378 INFO spawned: 'guacd' with pid 30 2022-11-11 14:14:13,378 INFO spawned: 'mariadb' with pid 31 2022-11-11 14:14:13,379 INFO spawned: 'tomcat' with pid 32 guacd[30]: INFO: Guacamole proxy daemon (guacd) version 1.4.0 started guacd[30]: INFO: Listening on host 0.0.0.0, port 4822 2022-11-11 14:14:14,473 INFO success: guacd entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2022-11-11 14:14:14,473 INFO success: mariadb entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2022-11-11 14:14:14,473 INFO success: tomcat entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2022-11-11 14:14:15,569 INFO exited: mariadb (exit status 0; expected) At this point I do not know where to look for a more advanced log.
-
I thought this might be the case, figured I would ask. Yes I can upgrade to a newer larger flash drive, I have three other Unraid servers that have bigger drives, this one has just been old faithful. I think it was my first thumb drive back when I first started with Unraid in January of 2011. Thanks for the info @ich777 I appreciate it. I will look at grabbing one of those flash drives soon.
-
Is it possible to change the download directory for the driver file? Currently my server is running off a 1GB Flash drive. When there is an update it almost completely fills my OS drive. I'm guessing it cannot be on the array as it would need to load before before that starts. Could it be loaded to a different flash drive?
-
I have been having this exact issue. Thanks for posting your solution, I deleted the folder in Booksonic and re-added it, boom all my authors and books showed up immediately. Thanks



