

hawihoney
-
Posts
3497 -
Joined
-
Last visited
-
Days Won
7
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by hawihoney
-
-
Tunable back to default - same problem.
Need to add something. See these small reads even when reading/streaming from a single disk. This means, whenever all disks are spun down and I do read from a single disk, all other disks, that are part of the same User Share, where this file belongs to, will spin up to.
Didn't recognize that til today.
Problem is XFS and/or MD related.
-
@Tom: I changed these values back and forth several times during the RCs. But not with RC4. Will do tomorrow.
Sine some weeks I can't stop. That's why I try to avoid to stop the array. It's always hanging on Stopping Services. I need to power cycle with IPMI. The reason are the mount points to external machines. Every morning they are gone and ls on a mount point, or other commands, stall the machines. I changed from Unassigned Devices to own scripts - same result. I couldn't find the reason in these weeks ...
-
I've read that several times now. I can't remember that an application writing to the array did report "Ok" and the array was still writing for minutes. When was that enormous caching introduced?
What happens if that write fails? My application said "Ok" already and I do have no clue that the array created a mess?
Where can I switch that off?
-
Exactly. My first thought was "Give these machines more RAM" and I went from 8GB to 16GB. The only effect was that these read requests start later.
And now think about my other report here. At some point, with really fat files, the systems hang completely.
IMHO, we found a memory leak.
-
Just a follow up. Please see attached picture.
I copy a file to disk20. This copy leads to write activity on disk20 and two parity disks (red color). This is correct.
disk20 is part of a User share. This User share includes all but disk17 (blue color). The copy to disk20 does not touch disk17 - no read, no write. That's correct.
All other disks, that are part of this user share (green color), show these small read requests. That's wrong.
In a previous test I switched off User Shares completely. Then all disks (including disk17) show these wrong read requests.
I can't explain it better. My knowledge of the english language ends here.
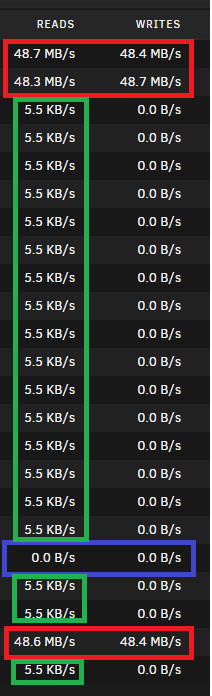
-
I can confirm that with 6.7.0-RC4 no disks spin down here.
-
Update:
Happening on RC4 as well.
Don't know if this is related or just coincidence (both source and target unRAID server on 6.7.0-Rc4):
The target unRAID server has 16GB RAM. During a copy of a 15GB file from the source unRAID server to the target unRAID server the read requests, I'm complaining about, started right before copy ended. And these read requests ended together with the write request.
BTW, RC4 writes noticable faster to my unencrypted XFS array. Something between 10 and 15%.
-
Still true for 6.7.0-rc4. If VM Manager reports non-VM-capable hardware, the VMS tab is shown.
-
That's not the same I think. You do use encryption. My original post is without encryption. In fact I don't even see much difference between your two posts. One shows faster results, but the pattern of the read and write requests, is nearly the same between 6.6.6 and 6.7.0.
I'm not talking about transfer speeds. I'm talking about these small read requests shown in the screenshot of my original post. This is not true for 6.6.6.
-
No encryption. Everything's XFS. A target unRAID test server had no cache, no plugins, no Dockers, no VMs, no User Shares. Just SMB connection to the disk shares.
-
As I wrote several times: I write to a single disk. And during that write activity all other disks show that read activity. The read activities stop immediately if write activity to the single disk ends. The disk LEDs reflect these read activities as well.
So: All disks are working when I write to a single disk.
-
I can confirm that this is happening on RC3 as well.
To the previous poster. What's special with the disks that don't show any read activity? If it happens here, all disks show these tiny read requests.
***EDIT*** Please have a look at the screenshot. The top two drives are parity. I'm writing to disk20. Interestingly disk17 has no read request - all other drives show these read reqests.
I'm writing to disk20 to a folder. On this server this folder is part of a User Share. This User Share does not exist on disk17. Seems that the read requests are only happening to drives that are part of the same User Share.
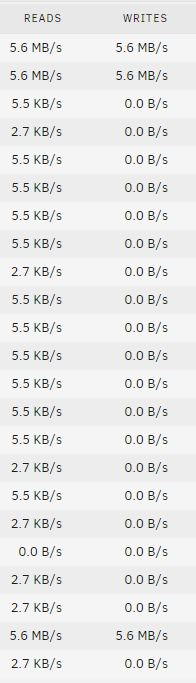
-
May I ask back a question?
Are you sure that the meaning of "Tunable (md_write_method): Auto" did not change with 6.7.0? Perhaps the read requests are the result of a different handling now (from "read/modify/write" to "reconstruct write").
Just an idea.
-
Arg, just replyed in a lengthy post, did hit submit, that page greyed out and did not return. Everythings gone.Let's try again.
I did a different test that comes close to your idea. I took two Unraid servers.
On server1 (6.6.6) I added disk21 from server2 (6.7.0-rc2) via Unassigned Devices. Resulting SMB share was 192.168.178.34_disk21. Now I copied from different software/tools on server1 to that share. The result was identical to the Windows Explorer experience. I took MakeMKV docker, MKVToolNix docker, MC on root console. The result was always the same: The other disks on server2 spin up too and show small read requests.
Two IMHO very important things I need to add:
1.) I can confirm the user above and his post. Spin up of disk21 and the two parity disks on server2 came with a delay of 30 to 90 seconds. The tools are writing but the disks remain sleeping. I don't have any caching running, no Turbo Write.
2.) When the tools report "writing complete" the disks are still writing. Again, it's for around 30 to 90 seconds. I'm curious if there's a write cache somewhere in the system since 6.7.0-rcx.
My hardware:
Server1: 1x Supermicro X9Dri-F, 2x Intel 2609 v2, 64GB RAM, LSI 9300-8i connected to Supermicro BPN-SAS2-EL1 backplane (both ports = 8 lanes), 2x PCIe x4 adapter cards holding 1x Samsung 970 EVO M.2 each. Both M.2 building the cache pool. Several dockers, 2x Unraid VMs to test my upcoming new builds. I try to work around the single array (28+2 drive) limit.
Server2: 1x Supermicro X9Dri-F, 1x Intel 2609 v2, 32GB RAM, LSI 9300-8i connected to Supermicro BPN-SAS2-EL1 backplane (both ports = 8 lanes). No plugings, no docker, no User Shares, no VMs.
-
@Tom: To make it faster I took an existing 6.6.6 machine.
I stopped the array, switched User Shares to Off, started the array and after a minute or so I clicked Spin Down.
Then, I thought, it would be better to test with 6.6.6 first before testing with 6.7.0-rc2. I opened Explorer on Windows and wrote \\tower2\disk21\test followed by Enter.
On Tower2 all disks started to spin up. Then I copied a big file from my Windows machine to that particular disk. The small reads, I'm complaining about in my first post, did not happen.
Upgrade to 6.70-rc2 and reboot:
I opened Explorer on Windows and wrote \\tower2\disk21\test followed by Enter.
On Tower2 only disk21 started to spin up. Then I copied a big file from my Windows machine to that particular disk. The small reads, I'm complaining about in my first post, did not happen.
So, no additional reads with User Shares switched off. I will have a look at it a little bit.
Don't know why all disks spun up on 6.6.6 when accessing disk21. I've never seen that before. I'm using this combo Windows, Total Commander, individual Disk Shares all day and night. I would ignore that for now.
***Edit***. 10 seconds after sending this post, all disks spin up. Read requests on all disks while that copy is still on it's way. That's the difference between 6.6.6 and 6.7.0-rc2. And before someone asks. No plugins, no User Shares, no Cache Dirs, whatever...
-
Oh, I went back to 6.6.6. This weekend I will build a new machine - did buy an additional license today. I will set it up with 6.7.0-rc2 and report then.
-
As I wrote in my first post it's what you see in a unRAID VM running on unRAID. It's nothing important, just a small GUI correction.
-
Hm, I doubt you did get the point.
I don't have virtualization support in a machine and part of the unRAID thinks I have.
The part that's correct is the VM Manager.
The part that's wrong IMHO is the VMS tab and the VMS page.
-
Great. Good job.
-
Please have a look at my Screenshots above. The 44 MB/s represent the activity I started. The xx KB/s are the activities I'm complaining about. If my job stops, the xx KB/s read requests stop immediately as well.
Can't explain it better.
-
1 hour ago, limetech said:
Since you are not using User Shares, then turn this off.
...
But maybe something about this kernel 4.19 and your i/o pattern is conspiring together to cause those idodes to get ejected.
Thanks, will do.
***Edit*** Wait, it can't be that easy. The small read request to the other disks always end with the read or write request to the single disk.
-
2 hours ago, jonathanm said:
Do you have cache dirs plugin installed?
No. Only User scripts and Common problems.
-
Argh, it's happening again. I'm reading disk17 and all disks spin up and have low read activity. There's no hint in lsof or syslog. When looking at the server case I can see very minimal blinks of the activity LEDs. While disk17 ist constantly lit, the activity LEDs on all other disks circulate very fast (disk1, disk2, ...). That happens every 5-10 seconds.
Sorry, was to fast with my previous post. Never seen that behaviour an 6.6.6
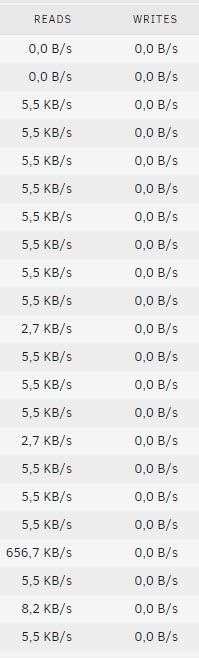
-
For me, OP, I can no longer reproduce that unusual behaviour on 6.7.0-rc2.
I went back to 6.6.6 and did re-test the complete scenario. Here, everything was as expected.
Then I did install 6.7.0-rc2 as before and did re-test that whole scenario again. And this time Unraids behaviour was as expected.
As this machine is mainly a backup and read-only machine with no dockers, no VMs and just two plugins I can't say what's the reason for this. I will stay with 6.7.0-rc2 on that machine and test a little bit further.
Thanks for listening.



[6.7.0-rc2] Reading all disks when writing to a single one
-
-
-
-
-
in Prereleases
Posted
Last post from me on that.
I've set up a test. Two parity drives, a User Share spreading disk1 and disk2. Writing to disk1:
Blue: User Share (disk1, disk2)
Green: Writing to disk1 --> ok.
Red: Small reads on disk2 --> wrong.
If I switch off User Shares completely, all remaining disks show small reads as well.