




guitarlp
Members
-
Joined
Everything posted by guitarlp
-
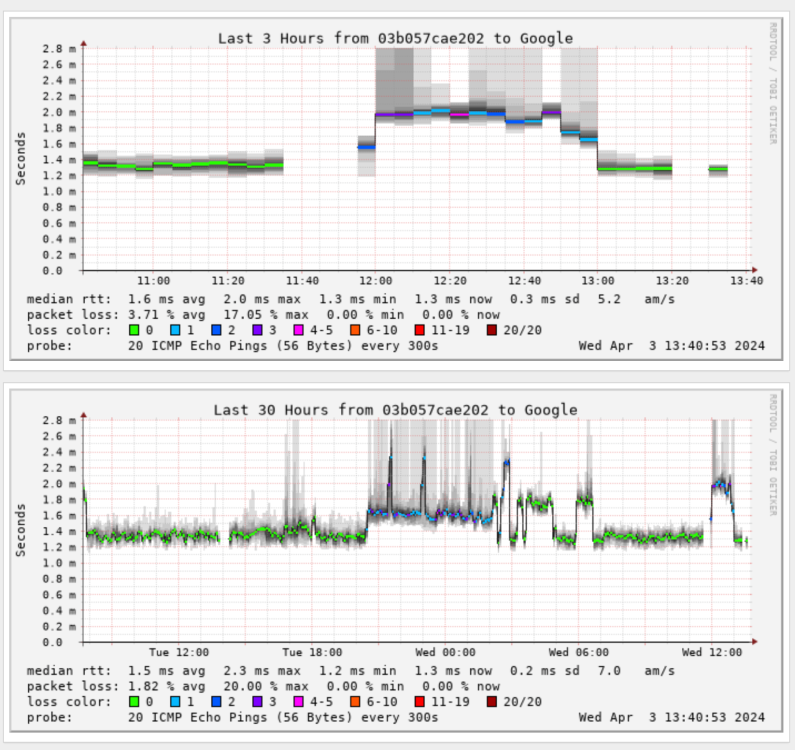
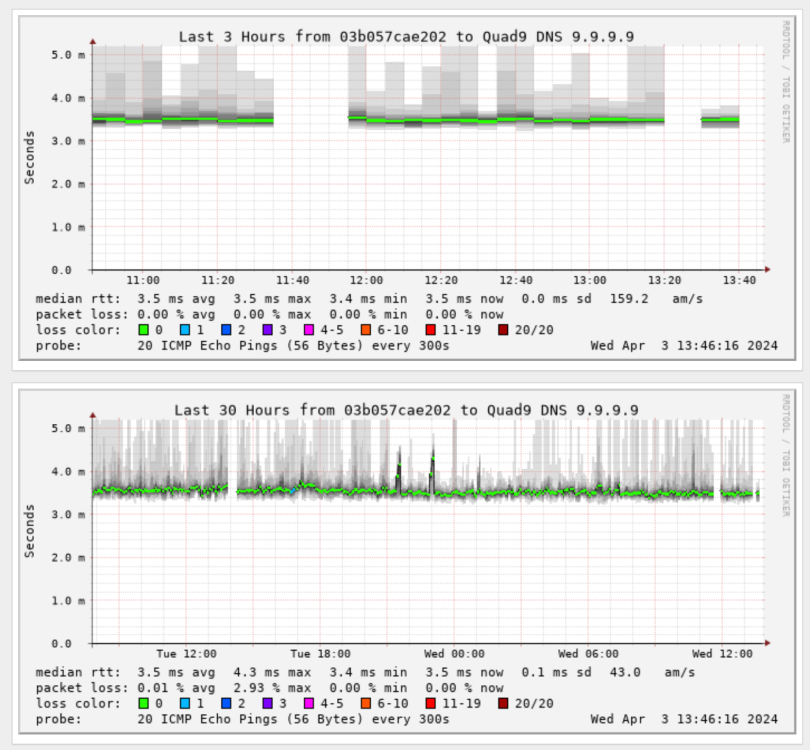
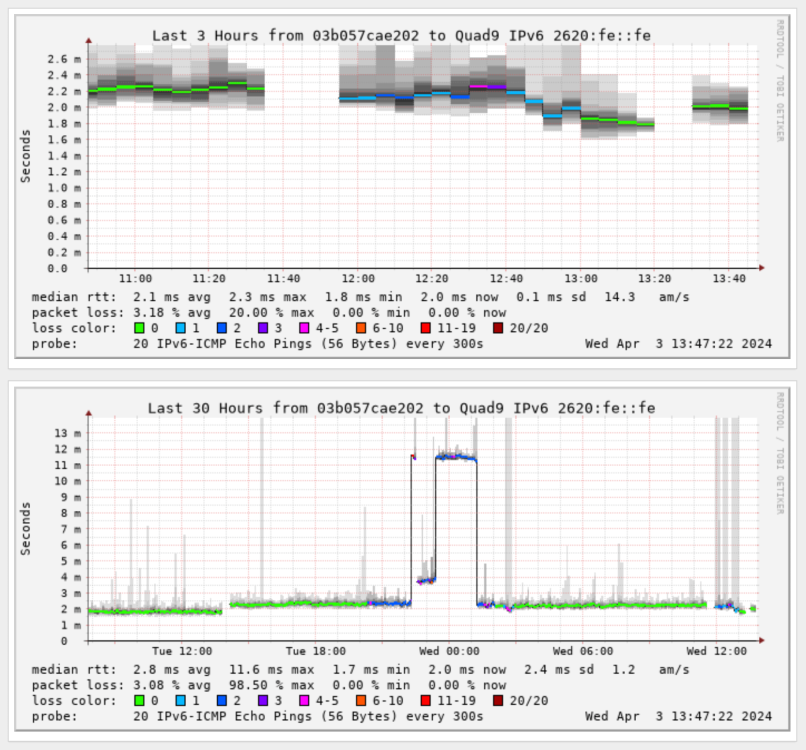
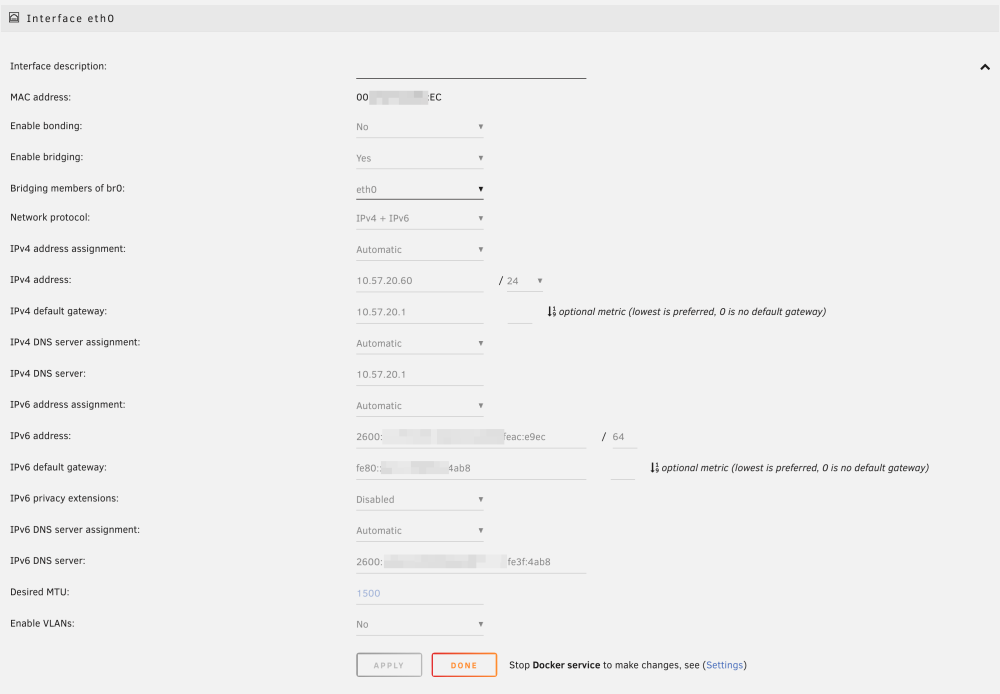
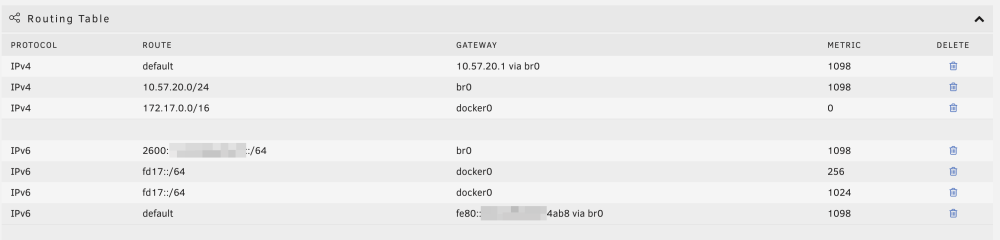
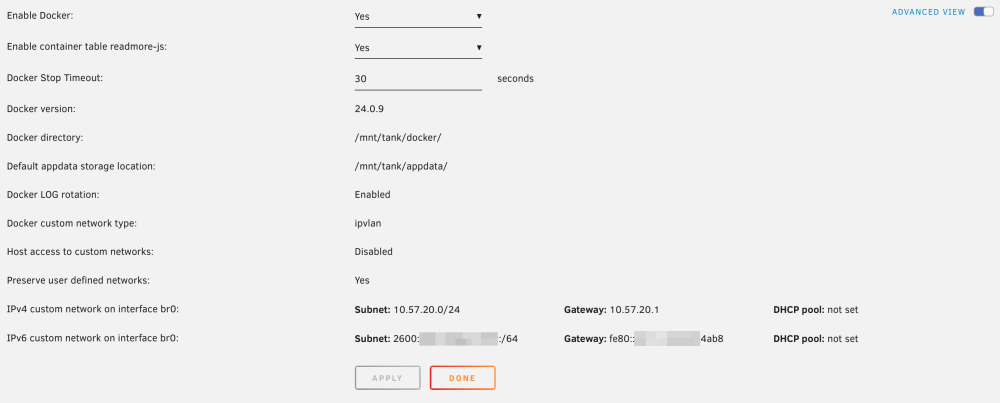
I moved my smokeping docker container from my bridge network to my custom br0 network. However, once I did that, all my targets connecting via IPv6 are getting packet loss. Here's an example (anything that isn't green is when I get packet loss and the container is on the br0 network): When I run a ping from within that container, I'm always getting packet loss when I run the command forcing IPv6. I don't get any packet loss on IPv4: 80c35650254d:/config# ping -4 -c 5 google.com PING google.com (142.251.40.46): 56 data bytes 64 bytes from 142.251.40.46: seq=0 ttl=118 time=1.429 ms 64 bytes from 142.251.40.46: seq=1 ttl=118 time=1.337 ms 64 bytes from 142.251.40.46: seq=2 ttl=118 time=1.262 ms 64 bytes from 142.251.40.46: seq=3 ttl=118 time=1.401 ms 64 bytes from 142.251.40.46: seq=4 ttl=118 time=1.400 ms --- google.com ping statistics --- 5 packets transmitted, 5 packets received, 0% packet loss round-trip min/avg/max = 1.262/1.365/1.429 ms 80c35650254d:/config# ping -6 -c 5 google.com PING google.com (2607:f8b0:4007:819::200e): 56 data bytes 64 bytes from 2607:f8b0:4007:819::200e: seq=0 ttl=117 time=1.918 ms 64 bytes from 2607:f8b0:4007:819::200e: seq=2 ttl=117 time=1.812 ms 64 bytes from 2607:f8b0:4007:819::200e: seq=3 ttl=117 time=1.952 ms 64 bytes from 2607:f8b0:4007:819::200e: seq=4 ttl=117 time=1.884 ms --- google.com ping statistics --- 5 packets transmitted, 4 packets received, 20% packet loss round-trip min/avg/max = 1.812/1.891/1.952 ms I monitor sites like google.com using smokeping, but I also monitor IP addresses like Quad9's DNS servers. With IP addresses, I'm not seeing any packet loss when testing the IPv4 9.9.9.9: But I am seeing packet loss when I test Quad 9's IPv6 DNS servers: So my issue is that any outbound connection to an IPv6 address is always getting some packet loss when in my custom br0 mode. Any ideas on what I should look into? I'm on the latest unRAID 6.12.9. I'm using pfSense are my gateway, and IPv6 is handled via SLAAC. Here are my interface settings: Here is my routing table: Here are my docker settings:
-
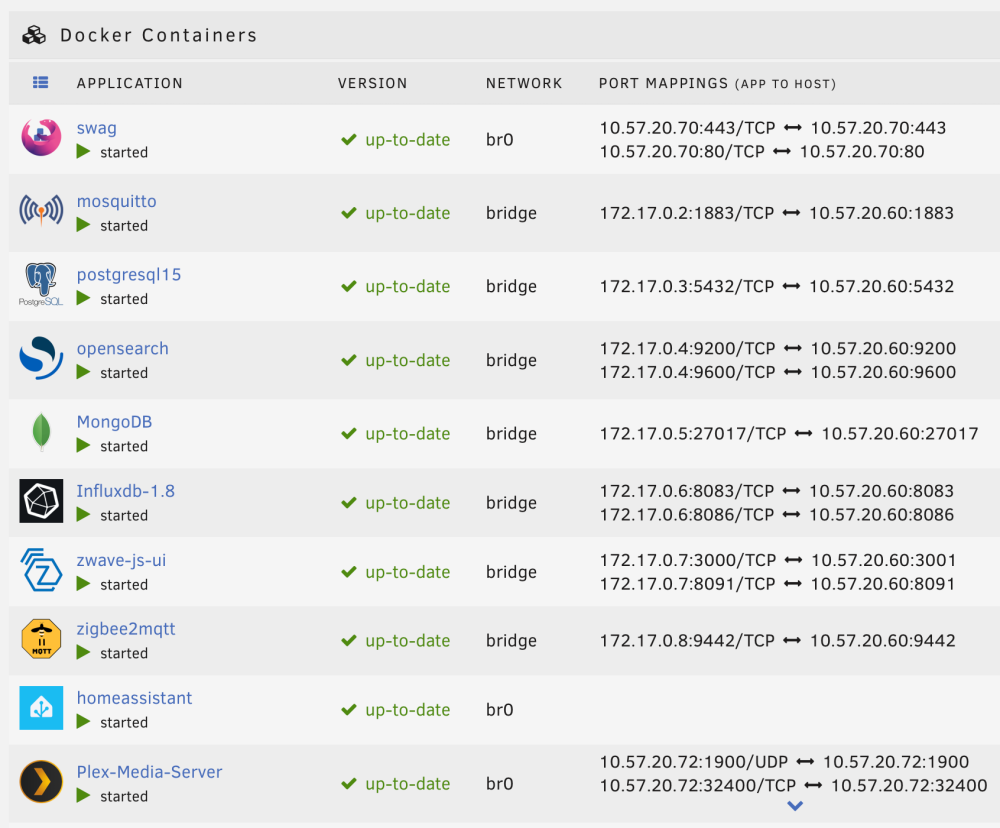
Why do some containers using a custom br0 network show port mappings, and others do not? I understand that when you use a custom network, the port mappings no longer matter. But I'm confused on why some containers in the unRAID GUI are showing port mappings, and others are not, for the same br0 network. For those containers that don't list them, is there a way for me to get them showing up, so that things are consistent in the GUI? See the attached screenshot. The `swag` and `Plex-Media-Server` docker containers use my br0 network and have port mappings defined. But `homeasistant` has no port mappings showing.
-
This post for example.
-
Thank you for the response. I understand that part though. I default to encrypt everything, but I'm wondering if doing an encrypted XFS drive is going to fix this, or if I need to ultimately do an unencrypted XFS disk. Normally encryption doesn't impact perceived performance... but normally raid1 doesn't cause huge iowaits with freezing docker containers :).
-
This is an old thread (apologies), but this still doesn't appear to be fixed on the latest `6.11.5`? When I switch from btrfs raid 1 to XFS non raid, can I do that encrypted, or does it have be be an unencrypted XFS disk? I read something in this thread about encryption possibly attributing to this issue.
-
Is the Dynamix SSD Trim plugin still required on pools that use BTRFS with encryption? The plugin mentions: But I have read that the `discard=async` BTRFS option included as of unRAID 6.9 doesn't work on encrypted drives.
-
Would it be possible to exclude docker updates creating warnings? I run the CA Auto Update Applications app to update Docker apps every day. However, if Fix Common Problems runs before an update is installed, warnings get created which give me small heart attack when I receive those via Pushover notifications. I can ignore each notification, but that's per docker app (and only after a warning fires). I have 27 dockers right now, and today I was able to ignore 4 of them, but that means I have 23 apps that may cause warnings in the future and every time I add a new docker that adds another chance for a warning to appear.
-
Is this container still up to date and okay for use? It failed to install a couple of times, but now that it did install unRAID is showing the version as "not available".

-
No problem. I had the same issue and banged my head around it for about an hour. Then I re-read the instructions (carefully this time) and once I removed that folder things worked for me as well.
-
Remove the new syslinux folder from 5.0.4. You should only be copying over the bzimage and bzroot files (along with the readme if you want).
-
What did the pre-clear report show at the end of this pre-clear? I've never noticed this (don't usually watch the pre-clear until it's done) ... but now that you noted it, I undoubtedly will on my next pre-clear And of course I'll wonder the same thing if the "+" number is anything but zero !! I'm surprised Joe L didn't provide some feedback on this. Joe L ?? I did the pre-clear on two drives and both of them had increasing "+" values as the pre-clear continued. The reports at the end showed no issues on either drive. I checked the Smart reports before and after and didn't see anything concerning. So for those that see this, I don't believe it's anything to worry about. I'd still like to know what it means though because it did concern me to see a number increasing during a pre-clear like that. I assumed it was bad sectors getting replaced or something of the sort. Trying to google for what it means didn't return anything relevant.
-
What does it mean if the records in and records out values contain a positive + value? For example, I'm current preclearing a 3TB WD Red drive that shows the following: 624648+4 records in 624648+4 records out What's the +4 value? Is that a bad sign? Edit: Now they're at +6: 660271+6 records in 660271+6 records out
-
Doing the calculations from this thread with my setup: 14 green/red drives (14*2) = 28a 10 7200 drives (10*3) = 30a 2 SSD's = 2a? This might be on the 5v rail though. 8 120mm fans and 3 140mm fans = 1.5a System = 5a 3 PCI-E cards = 3a 2 USB devices = 2 a Adding that all up I'm at 71.5a. A Seasonic 1000 watt PSU has 83a on the 12v rail. The 860 watt PSU is 71a. The 1000 watt would be the safe bet, but wouldn't be as effecient. The 860 watt would be cutting it close. Although, I believe the 2a green and 3a 72000 estimations are already a bit inflated. It seems the greens are usually 1.6-1.8. I've also heard the Seasonic's can provide short bursts of power over their stated specs. If both of those are true, the 860 watt PSU would be my best bet.
-
You'll want to put some splitters on your molex cables to increase the total number of connections. Monoprice is a great place to get those: http://www.monoprice.com/products/subdepartment.asp?c_id=102&cp_id=10245&cs_id=1024501 If you need more SATA connectors: http://www.monoprice.com/products/subdepartment.asp?c_id=102&cp_id=10226&cs_id=1022604 For example, if you wanted to change 1 molex into 2, you could get this for less then $1: http://www.monoprice.com/products/product.asp?c_id=102&cp_id=10245&cs_id=1024501&p_id=1313&seq=1&format=2 Just be careful on connecting a bunch of these to one cable from your PSU. You should try to use all the Molex/SATA cables evenly so that the power is distributed across your cables. I don't feel comfortable with more then 7 hard drives on a single cable from my PSU. Too many devices on a single cable could cause issues as the cable wire itself may not be able to supply enough current for all the devices on that chain.
-
It's been mentioned in this thread and else ware around the web that Seasonic will provide extra cables if requested. I wanted to give an update that if that was true in the past it no longer is true today. I contacted their customer service department and requested a couple more molex cables for my 26 drive build using their SS-760XP2 PSU. They asked for me to send them my proof of purchase, and after I did they told me I would have to buy any extra cables from a third party. Why they needed my proof of purchase To tell me that I'll never know. I really like their PSU's and have never had any failures or issues with them, but I wanted to let everyone know they shouldn't expect free cables from Seasonic going forward and to factor the $7 or so per additional cable (plus shipping) into the price of the PSU. Not a big deal, but something to be aware of.
-
I agree... everyone enjoys pics... something you did in yours (that you may not even realize) may give one of us an idea to do in our own unRAID server.
-
I've re-wired it (SATA cables) completely 4 times now if that makes a difference. Every time I opened the case there was something about the wiring I didn't like. I figured that I'll have this running for years without needing to open the case... I might as well take an hour or two and organize everything as best as possible. Not only can organized wiring make replacing things in a case easier... but it also helps keep case temps down. It took a couple different tries for me to finally settle on how I wanted the SATA cables organized, but I'm pretty content with how I have it now. The obsessive compulsive side in me still wants to clean up some of the builk cables bunched on the open side of the case... but... I... must... resist.
-
I really like what you guys have done. bjp... that thing is massive . I love the custom work that you did. Mine is fairly simple... Case: Lian-Li PC-A16B (same one Tom uses on some builds) PSU: PC Power & Cooling 750 watt (60A on the 12v rail!) CPU: Intel E660 CPU Cooler: Scyth Ninja Mini Memory: XMS2 2GB (2 x 1GB) DDR2 800 (PC2 6400) Dual Channel Kit Motherboard: DFI Lanparty UT-P35-TSR (8 on board SATA ports) PROMISE SATA300 TX4 PCI SATA II Controller Card (2 of them) Intel Pro 1000 Gigabit NIC Chenbro SK33502BK Blackplane (3 of them) 3 80mm replacement fans for the Chenbro backplanes (stock ones were VERY loud) Current hard drives: 2 1TB drives 2 750 gig drives 2 640 gig drives 1 320 gig drive 1 250 gig drive (as cache) I like the case because it's just small enough to house 15 drives. The only problem I had was figuring out what to do with all the cables. The bottom 2 backplanes were pretty easy... but working on the top backplane with the PSU up there as well proved to be a challenge. The PSU doesn't have modular cables which is a pretty big drawback for a case of this size. I was able to route all the unused ones to the back side of the case... out of site and out of the way. It took some time connecting SATA, power, and fan cables on the top backplane. If I need to get up there again I'll have to push the backplane out of the case a bit and remove most of the PSU in order to get my hands in there. Then I need a flashlight, needle nose plyers, and a lot of patience . All the SATA cable connections to the top backplane where made outside of the case because there's no way I could get everything routed smoothly once the backplane was in the case.








