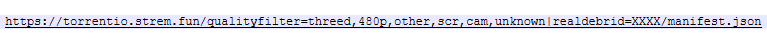hernandito
Community Developer
-
Joined
-
Last visited
Everything posted by hernandito
-
Awesome.... thank you! I have edited the original post to include.
-
Hi, the chmod commands are to enable the scripts and the zurg binaries (in /appdata/zurg) to be executable... nothing to do with the rclone mount folder.
-
Thank you.... the repo is available now. Had to make it public.
-
Apologies.... I forgot to change the repo to public. It is fixed.
-
The repo should be active... https://github.com/hernandito/unRAID-RD-CLI_Debrid-Plex-Zurg. It is literally 4 files that you need to download from there.
-
Reserved
-
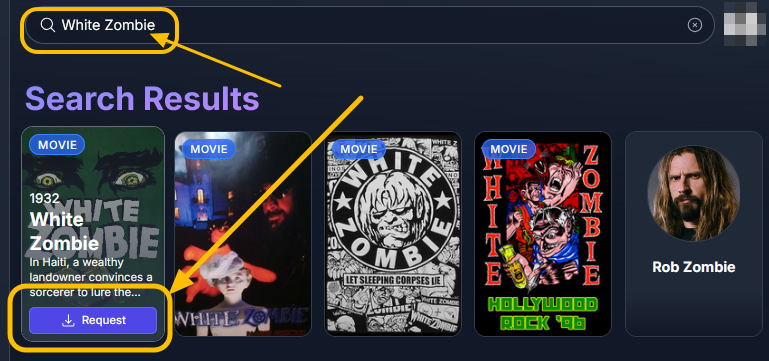
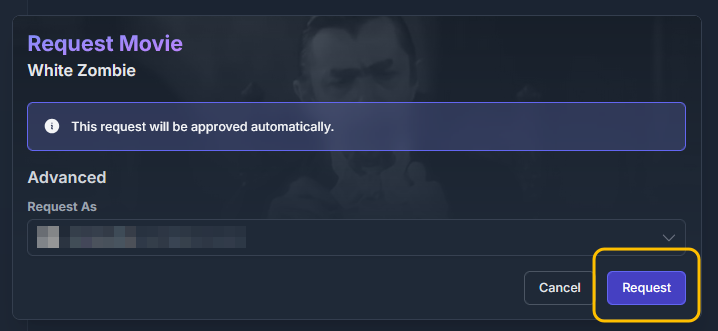
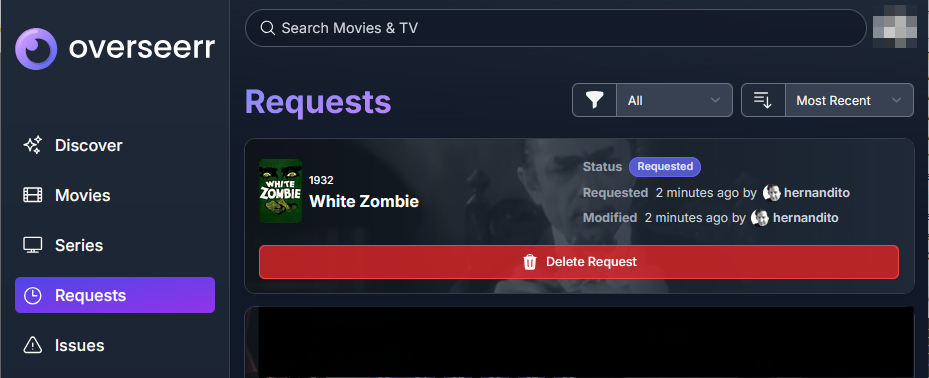
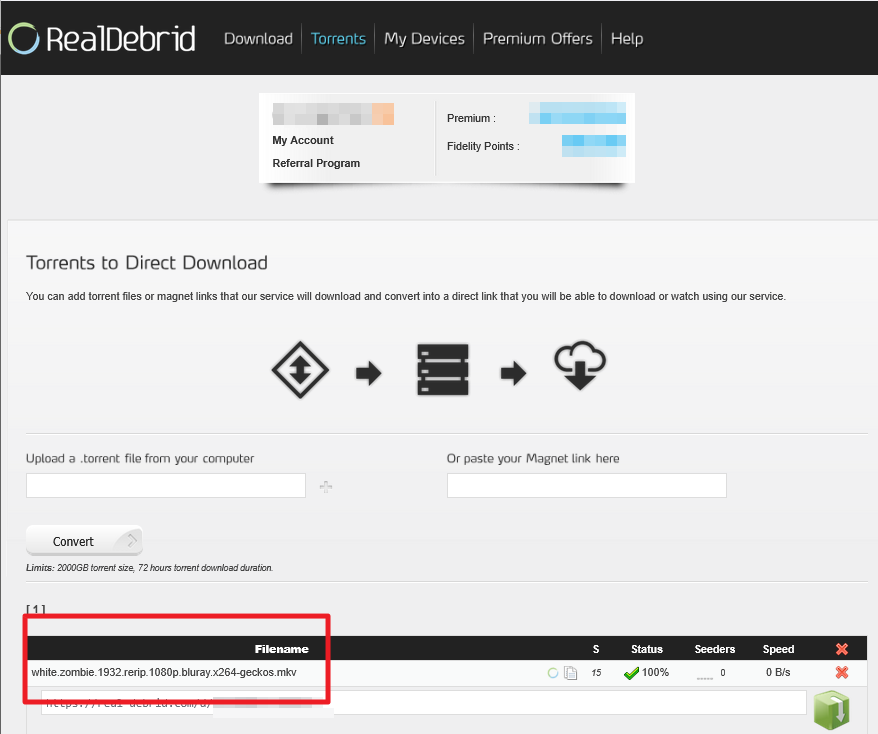
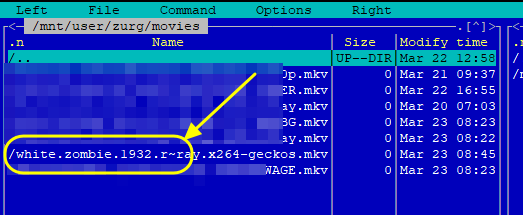
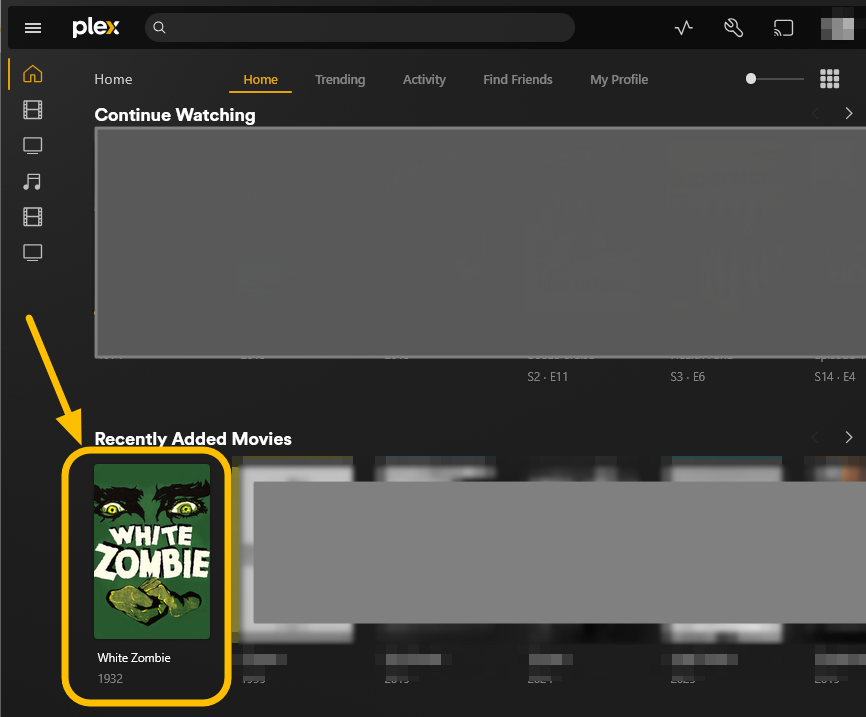
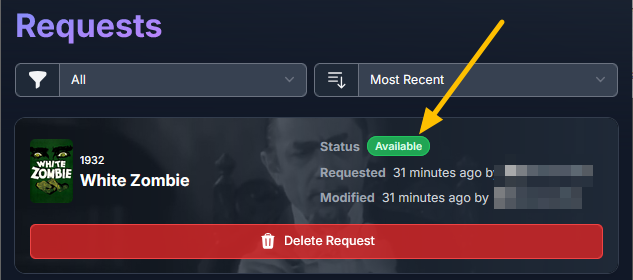
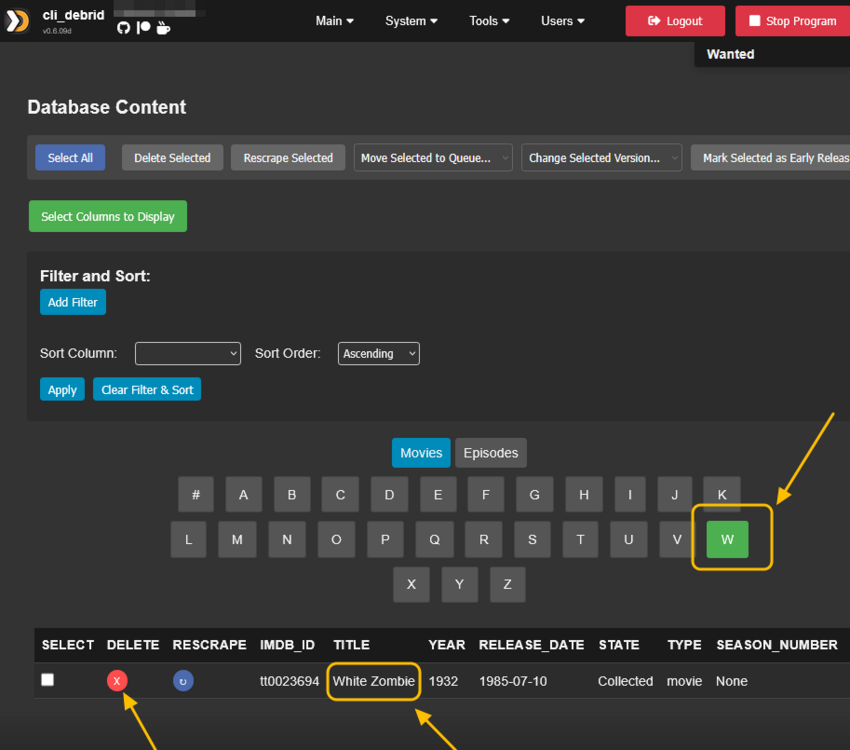
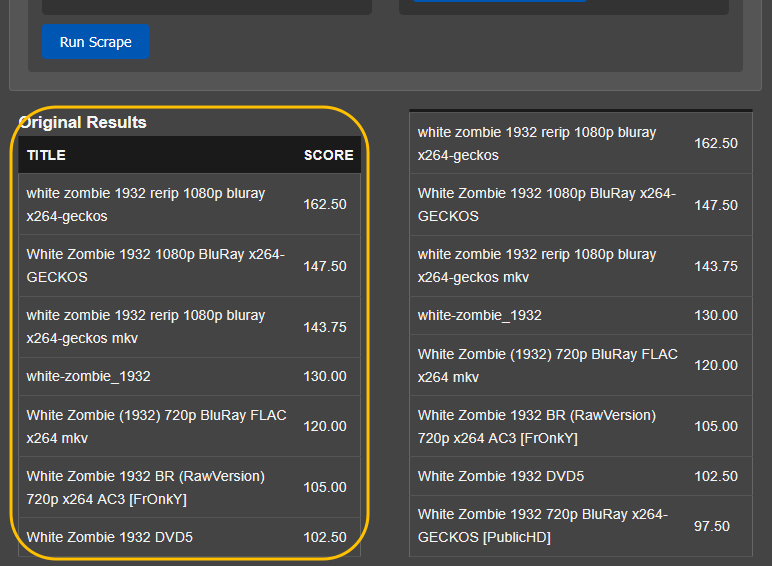
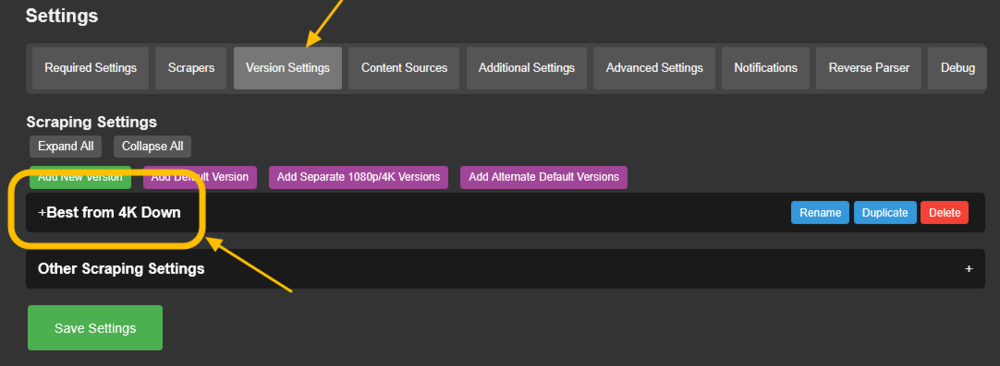
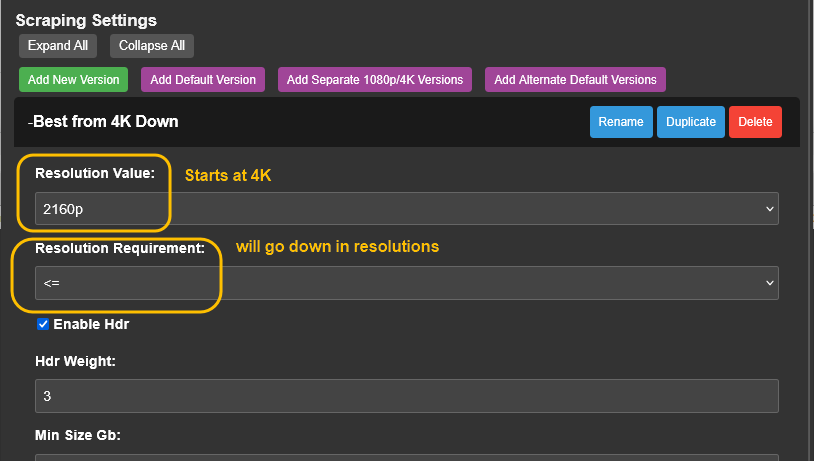
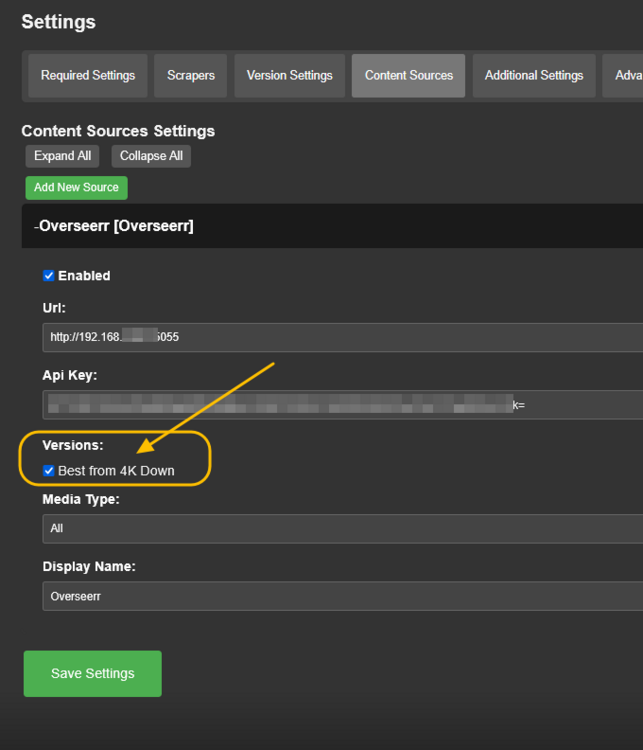
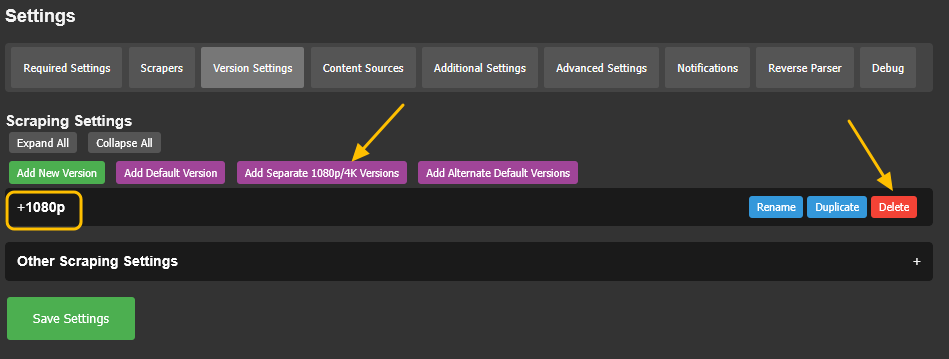
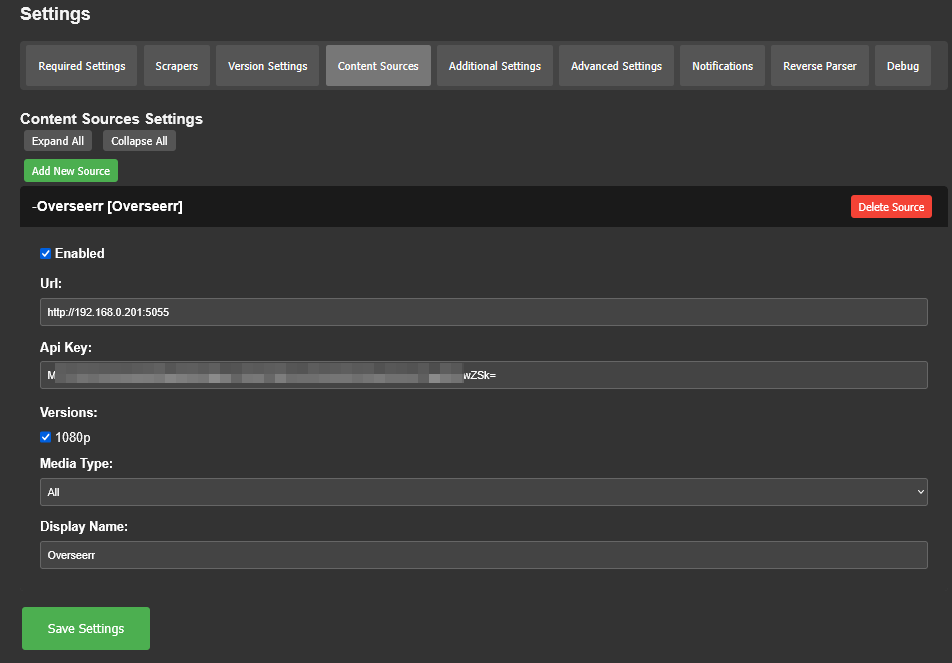
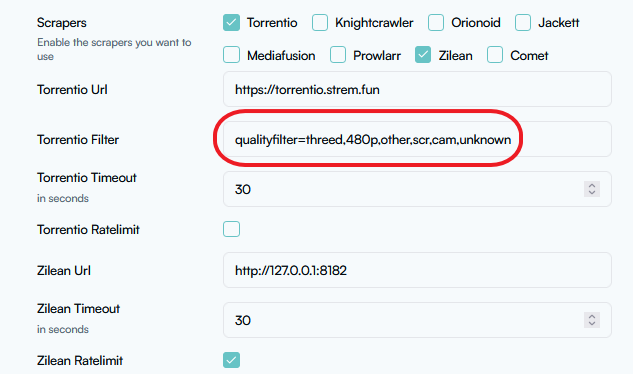
Go to Overseer On the search bar type the name of a Movie you know is not in your collection. Click the Request button: The below screen will pop up. Notice that it tells you (in my case) that the item will be approved automatically. Click the Request button. Go o the Request tab and you will see your movie added. Back in unRAID, open up the Log screen for your CLI_Debrid docker, giving it some time, you will see scrolling messages about adding the new movie. Again, after waiting for a few minutes (2 to 8 min. approx). Go to https://real-debrid.com/torrents. You should see your added movie. Go to your unRAID folders and navigate to /mnt/user/zurg/movies and you should see: Finally, go to the Home screen in Plex, and you will see the movies added to your Recently Added Movies: If you do NOT see the new movie, please go to Plex > Settings > Manage > Libraries and execute a "Scan Library Files" for the Movies-DB library. I had to do this once, and after this, new movies show very quickly. Back in Overseerr Requests Page, you should see that the movie is now shown as Available. You can Delete Request so it doesn't clutter this page. But if you (or a lazy friend) tries to add it again, it will tell you it is Available. TV Shows: Everything described above works the same for TV Series. Please note that if you add a show that has a lot of episodes and seasons, it will take a while to scrape and add everything. It processes one episode at a time. Success....! As mentioned throughout this guide, I am a semi-newbie on this. If you followed the guide precisely, you should be golden. If you run into issues, I may not be the best one to help resolve. I hope others, more experienced users, can help out. Tips, Usage, Recommendations, Advice: 3/25/25 - tips added below Below I will share useful tips that may not be clearly obvious. I will keep adding tips as I discover, so check back often. If you have some tips, please message me, and I will add them here (crediting you). - Library Management. If you want to delete media from your library, the best way to do this is going into CLI_Debrid >System > Database. Type the first letter of the release you want to delete. Select the release, and click delete. This will delete it from the CLI_Database, and your Plex. Make sure it is also not in your Overseer's request list. - Debrid Media Manager, I use this site to mainly check what is in my Real-Debrid library. I mainly check the sizes of each of the files that will stream. Useful to diagnose if something is going to play properly in Plex. This is also available to self-host, but I don't see a Docker template.... yet. I have not discovered if the file size is reported in CLI_Debrid. - CLI_Debrid Tester. This is a very useful tool to see if your Scrapers are properly finding releases. Performing these tests will not add the movie to your list. Go to Tools > Tester. Type the name of a movie and Search. It will present you with a list; make your selection. On the next screen, select your Version resolution. On the left hand column, select options to check (max file size, preferred release type, etc). Then hit the Run Scrape at bottom of left column. You will then be shown ((below bottom-left Run Scrape button) the items and their scores of what it finds. Depending on the movie and release date, you should have a decent size list. - CLI_Debrid's Scraper. You can also add movies / shows within CLI_Debrid. Under Main > Scarpers, type the name of what you want and hit Search. The nice thing is it will give you resolution options based of your selected versions. This is a very nice feature. But Overseer is nicer if you have other users making requests. CL_Debrid allows for User Account. Your preference. - CLI_Debrid's Queues. You can see what is in your download queue, if the item is yet unreleased, or Blacklisted. Blacklisted are items that it has not found, or that you have blocked from any future download. - More on the Debrid Cloud - added 3/25/25 As I mentioned in my edit at the start of the guide, Debrid is a powerful thing. In a nutshell, Real-Debrid (RD) allows you to add releases to media you want. The searching of this media is handled by CLI_Debrid (CLI), with the request coming from either Overseerr or items you add to Plex watchlist. Zurg's job is to ensure this media is properly indexed and cataloged in your Plex. When CLI_Debrid receives a request and it executes a search (scrape), if the exact release is available at RD (this is called a cached release), it will simply add it as a reference* to your RD account and your library gets updated. If the release is NOT available at RD, RD will get the release from torrents being seeded in the wild. This may take some time to download and make available in your library. You can monitor on the RD web site. Remember the download is not stored on your machine. This release will also be available to any other member of RD. In essence, everyone shares the same files. At RD some files expire and will get erased, when this happens, Zurg notices, and takes charge by requesting a new file, which will be downloaded and then cached again. Your Plex will never skip a beat. My one concern was, what if RD goes belly up... your collection and references to each release is gone... poof. Well there is a solution. There are other comparable alternatives to RD that do the same. They are not as cheap as RD and apparently not as complete (say others)... But what about the library you have curated built up? Enter https://debridmediamanager.com (DMM)- which I mentioned somewhere here. I believe you can also self host this (but not sure how it's done) - there is a Docker listed on their Github. In essence, it ties to your RD account and once you log in, it shows you your entire collection. When your are viewing your collection, you can click on a little button, and back up your library as a little 2MB .json for a library on thousands of releases. You store this file locally. This process can be automated (not sure how). So.... it goes belly up; you sign up for an AllDebrid or Torbox account. Tie it to DMM and click on another little button, to import that .json file and you will be golden. More black magic... you can share that little .json file with others, and you basically replicate their collection. *The "reference" to the files I mention above, are basically the hashes of those release files. That is all your collection is, a list of file names and hashes that share between providers and because they reference the actual file. - More on Versions and Quality - added 3/25/25 Per the above tip, we have determined that storage capacity is not really an issue for the Debrid method. Because of this, one would like THE best quality releases possible. The determining factor on what you select would be download speed of your internet connection. The higher the quality, the faster your internet speed needs to be. Also critical is where are you watching your content. If you are ONLY watching on your phone's screen, you may get away with 720p content, but if you have a super-duper 77" OLED 4K TV, you want the highest quality your internet can support. In my case, I have a big TV and really good ethernet. This can support watching 4K Remux content, with files upwards of 100GB. You need to figure out what is the best quality/file size you want to consume. I suggest testing and looking at the files sizes and the quality of your playback. A quick brief on encoding qualities (not an expert). There is a lot on info and discussions out there, but from my understanding, the best possible quality encoding comes from REMUX, releases, followed by BLUERAY, followed by WEB-DL. There are lower like Pre-Release, TS, Telecine, , but I do not care for these... like someone in the movie theater filming the screen with their phone... With the above in mind, and in my case, I want best possible resolution and best encoding within that resolution that is available. I have configure the CLI_Debrid > Settings > Version Settings the following way. I ONLY have one setting. As I described earlier, I started with the "Add Separate 1080p/4K Versions". I have now deleted the 1080p version. And renamed mine to "Best from 4K Down". Drilling into the specifics of this version, please see below. In the screenshots below, I will highlight the items that are important for my situation. Then, in the Settings > Contents Sources > Overseer, make sure your option is ticked: CONCLUSION: Best of luck, and PLEASE sponsor and donate to the CLI_Debrid team. You can do a Patreon subscription or do a one time donation. It is important that these guys are supported to continue their efforts.

-
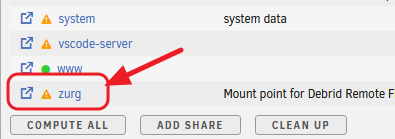
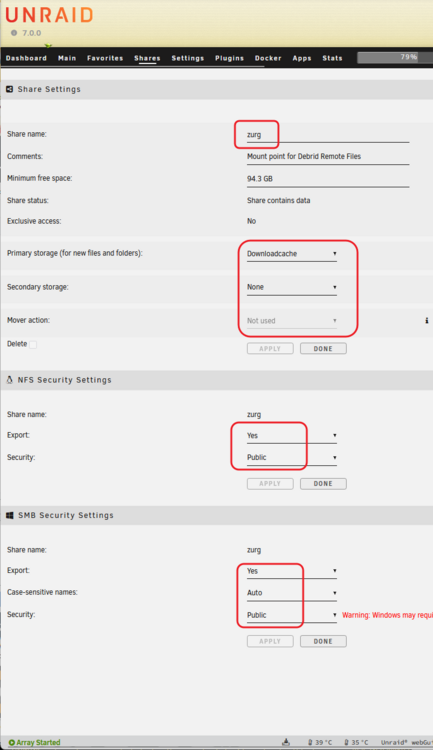
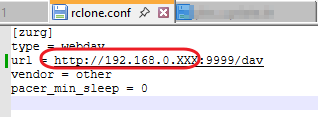
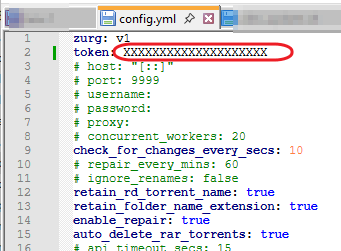
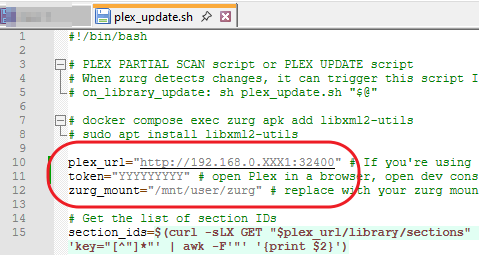
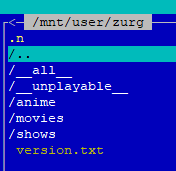
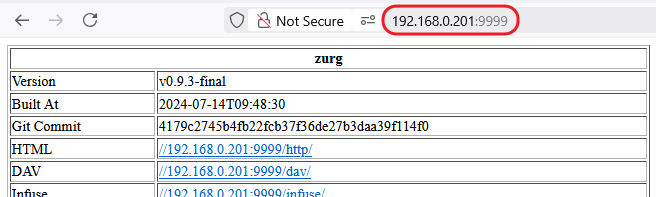
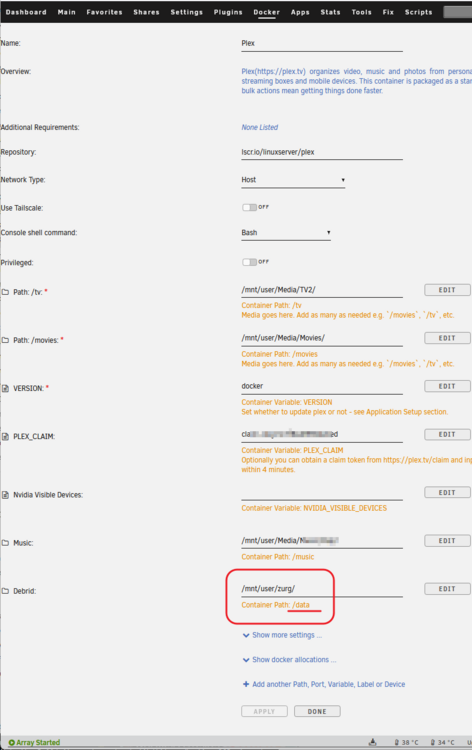
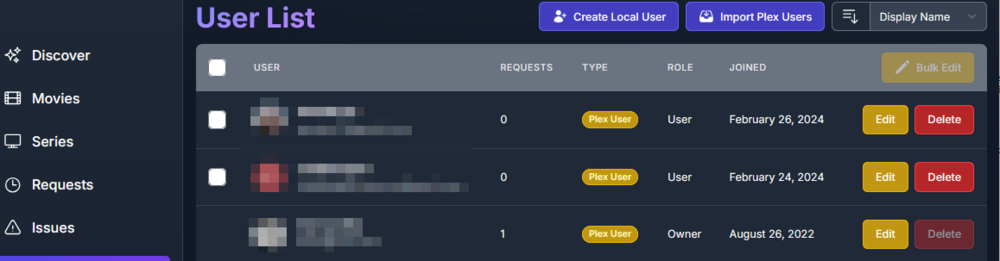
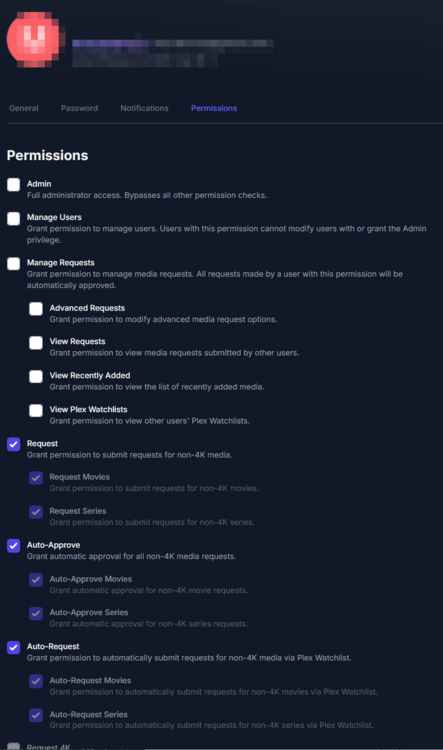
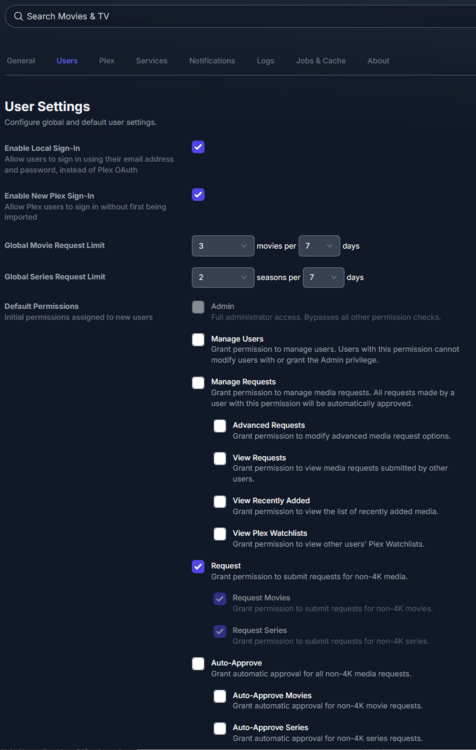
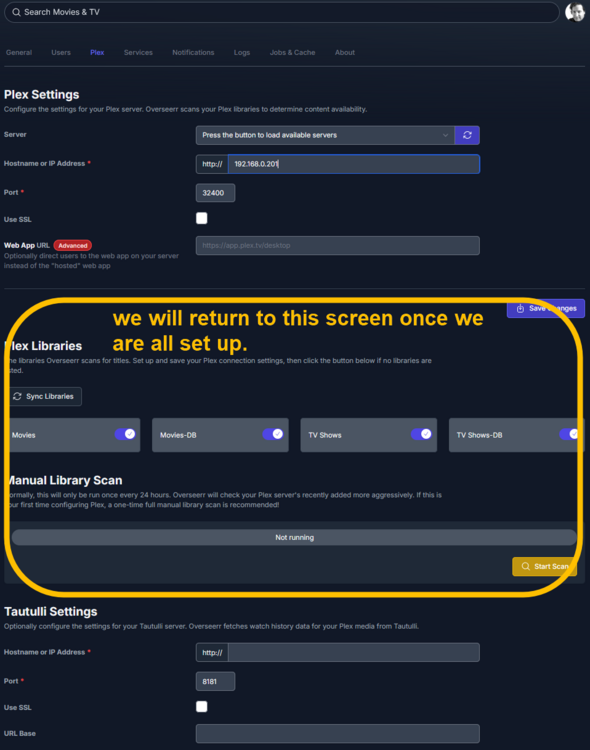
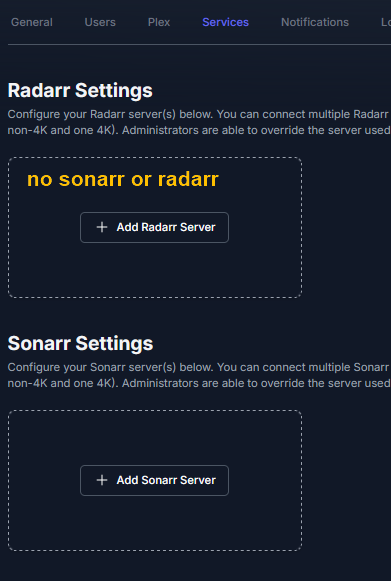
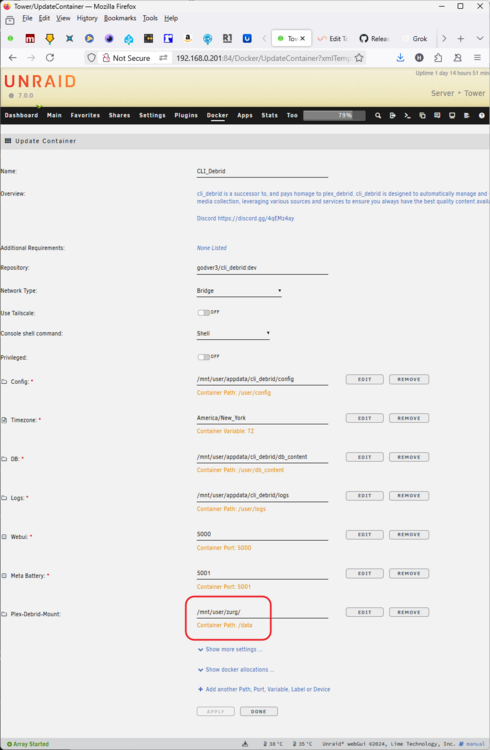
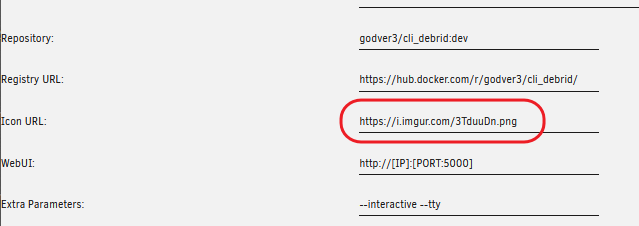
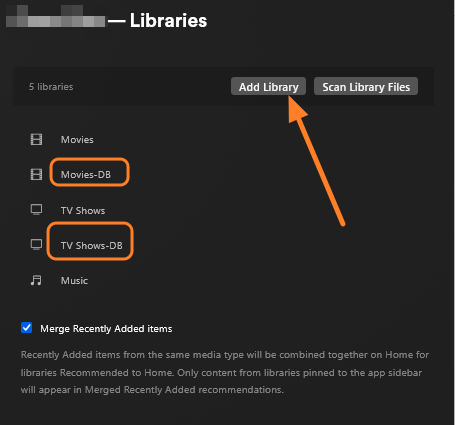
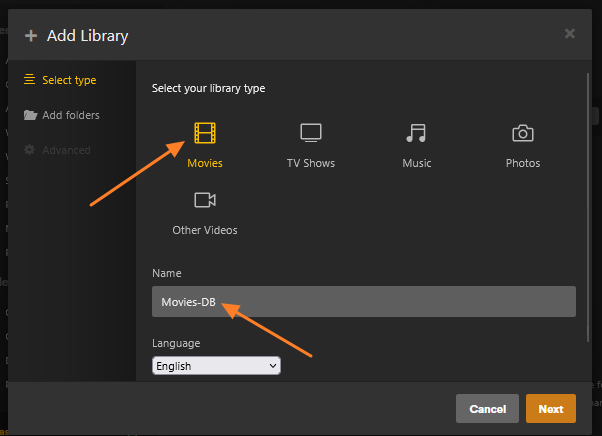
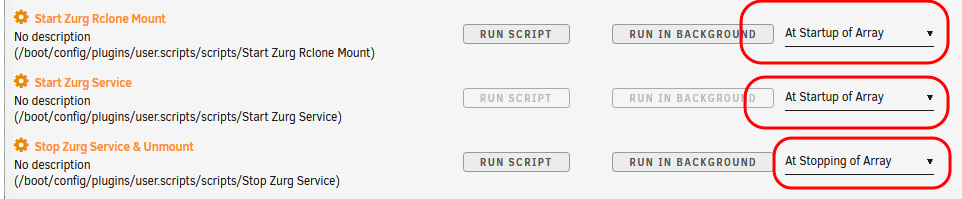
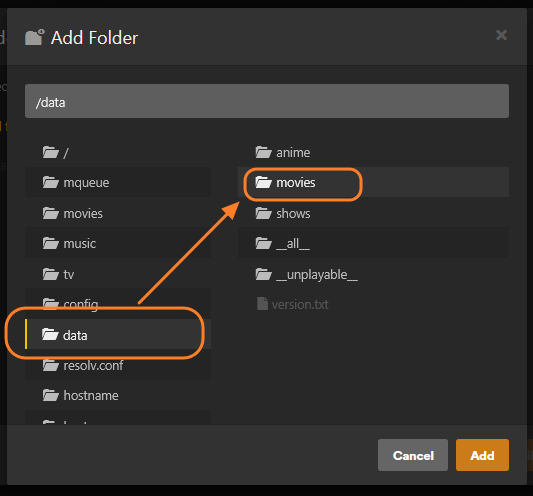
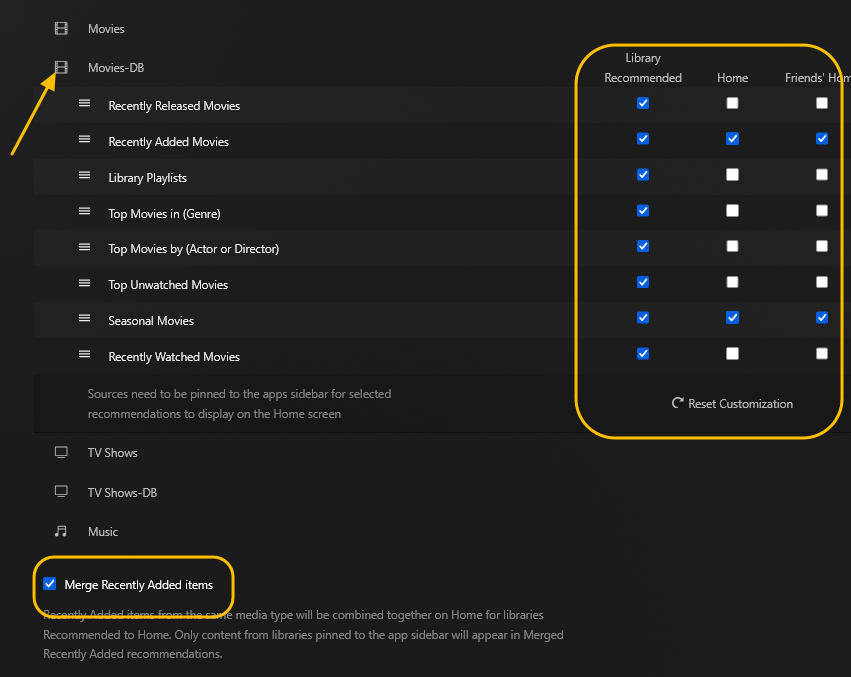
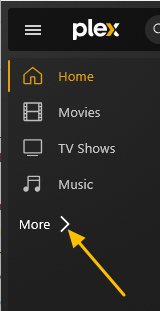
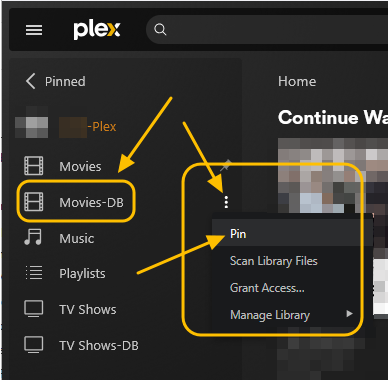
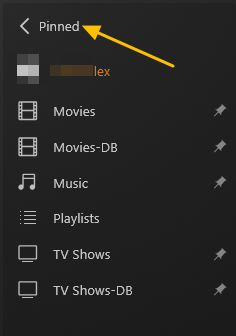
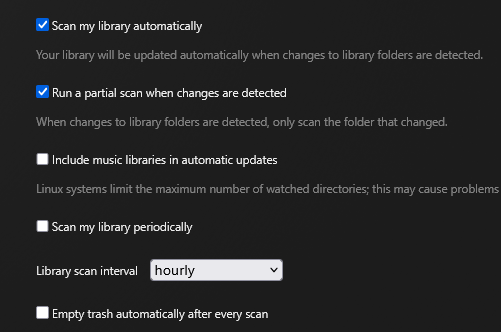
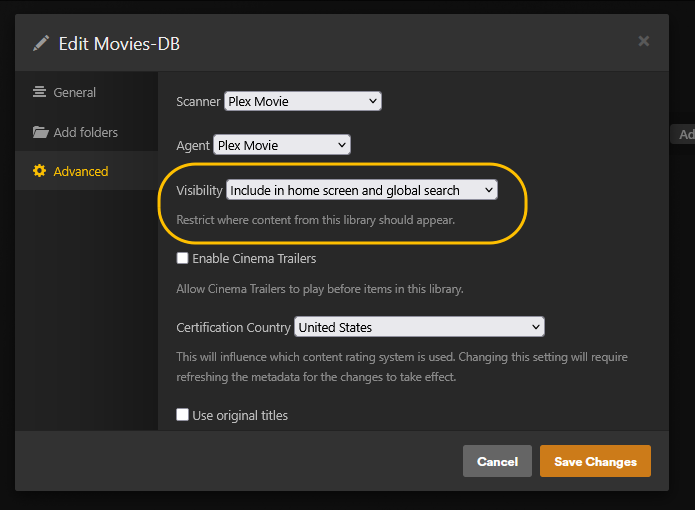
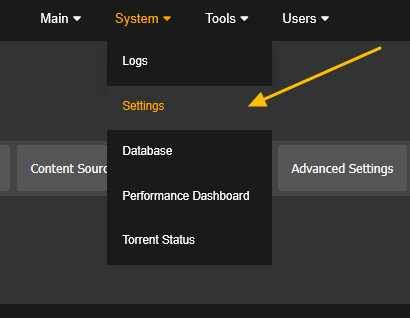
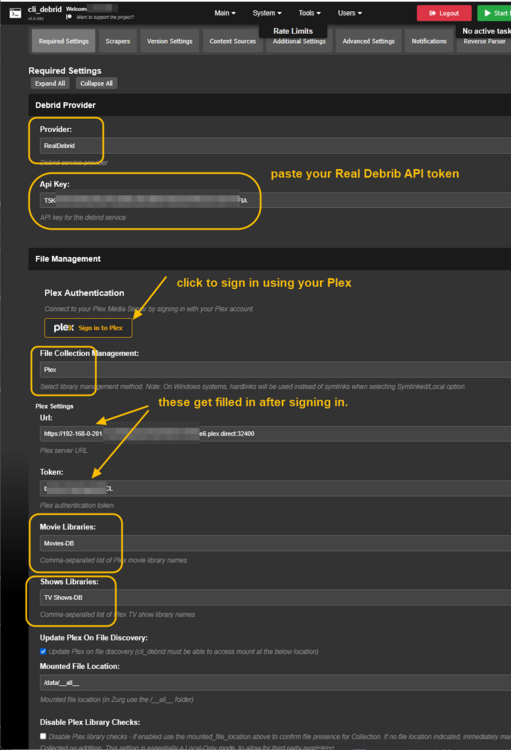
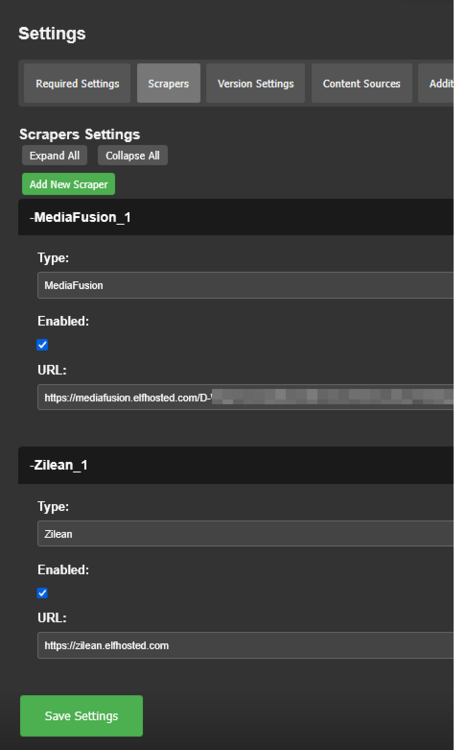
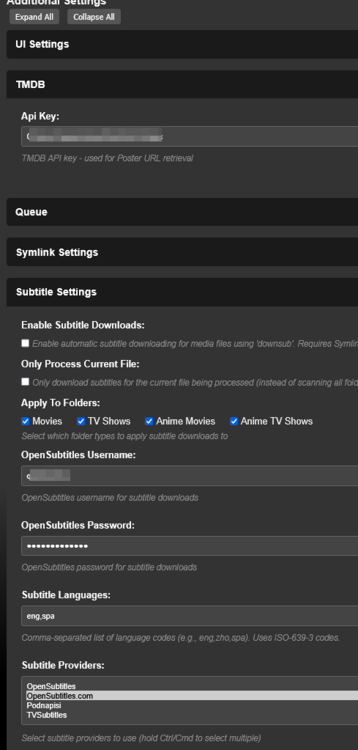
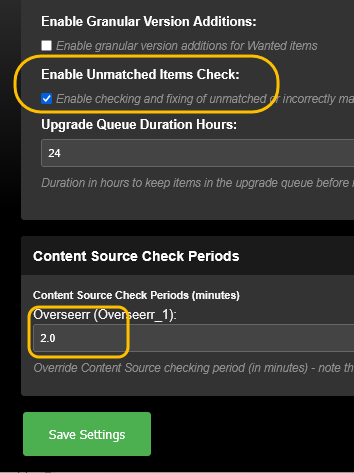
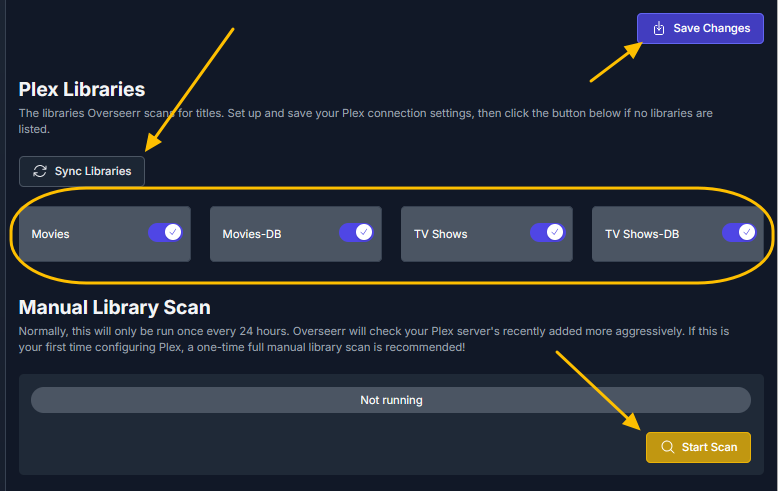
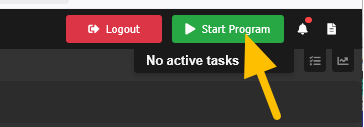
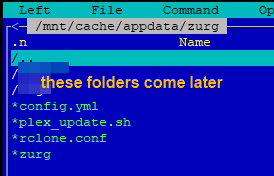
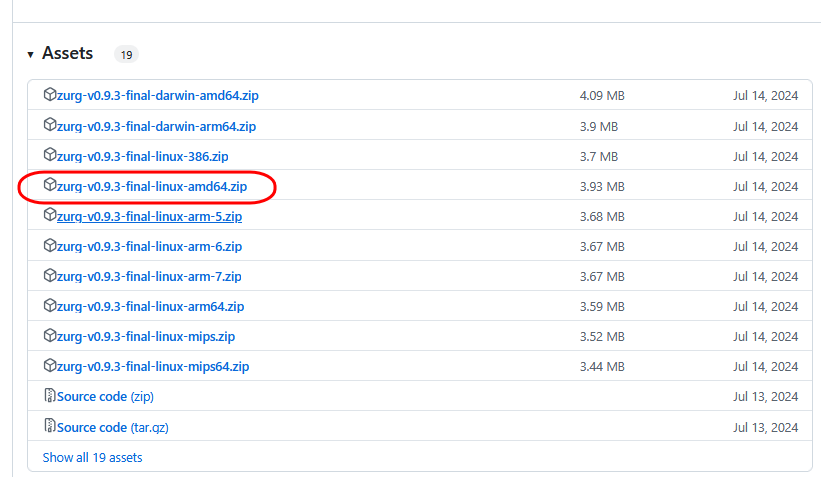
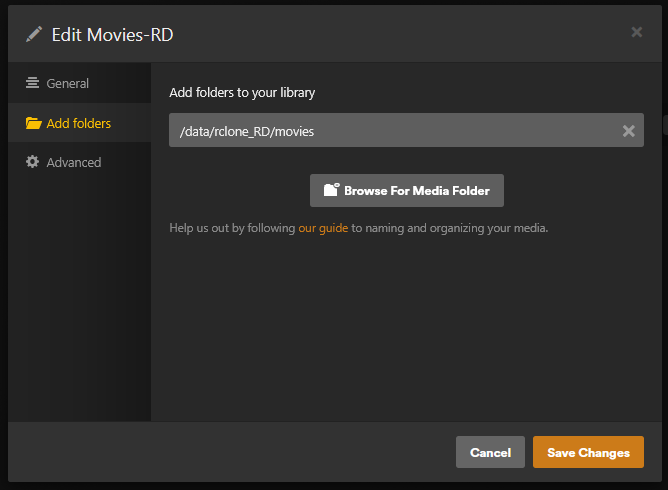
This guide is meant for the typical unRAID user who is somewhat aware what Debrid is. In a nutshell, Debrid allows you to build an unlimited size media library that is stored in a "cloud". It will stream from the cloud - behind the scenes, it uses torrent technology. You can consume this media using your Plex docker. Movies and Shows will show up as expected in the UI as recently added items in your library. I believe people out there have a completely remote libraries - with nothing stored locally. PLEASE CHECK BACK OFTEN FOR CLARIFICATIONS, TIPS, AND UPDATED INFO I will add notes right below when something is added. 🤩 EDIT 3/25/25: I keep having conversations with avid users of this Debrid method and it is a VERY powerful thing. Below you will hear me mentioning about only wanting 1080p content. If you have a good internet connection, and the proper TV, you could be watching media at 4K Blue-ray Remux DV quality where the media files can be anywhere between 60GB and 120GB+. I tested last night and w/ my 1GB internet, and a 60GB file played smoothly. The beauty of this is that no files are stored in your system. It is not uncommon for folks to have libraries with over 10,000 items. See further explanation in the Tips section of this guide. 😁 EDIT 3/31/25: Versions / Quality More on Version and Qualities in Tips section below. ============================================================================================================== Those on Kodi, may be more familiar with the use of Debrid and add-ons like Fen, Seren, The Crew, Umbrella, etc. The best part of this is that you can simply search for what you want to watch, and then you select the quality and away it goes. There are also curated lists, and lists of most recent, popular, trending, award winners, etc. For this method, one has to add the desired media, and it will add it. Much like it's done with Radarr/Sonarr. Unfortunately, Plex does not have something similar.... enter this guide. IMPORTANT: I am NOT an expert on this. It is a very complex system with many parts working together. One small mistake and it will not work. It has taken me about two weeks to put together. My success is all thanks to godver3, who is the author of the amazing package "CLI_Debrid". Thanks also to @mash2k3 for creating the docker template and for his help on the Zurg and Rclone scripts. This guide is meant to be followed to the letter. Currently there is no comprehensive guide out there to implement. I am NOT going to explain what all the pieces are, as I am NOT an expert. I simply managed to get it all done. I am likely not able to help much if you run into issues. Hopefully others can chime in. You can always go to CLI_Debrid's Discord channel for help. I am sure I have have not done things 100% correctly. But it works. Again, I am not an expert. I have created a package in my Github of files needed for this. You need to be able to be comfortable with the command line, and have more than passing knowledge working in unRAID. Things you need: An installed and functioning Plex Media Server docker from lsio. Install the rclone plugin obtained from CA, get the Waseh version. A paid account from Real-Debrid, it's cheap at around $10 for 3 months. Install the CLI_Debrid docker available in CA. Template by "mash2k3". IMPORTANT, when installing, choose the godver3/cli_debrid:dev version. Latest version will NOT work. Download the zip file from my repo here. I'll explain what to do with it later. Download the zurg binary form your the zurg-testing repo here. Download the zip file for the latest version of zurg-v0.9.xxx-final-linux-amd64.zip Install the Overseerr docker from CA by linux server. I will show you settings later on. You are responsible for proxying this Docker if you want it available from outside your network. User Scripts plugin in unRAID. This assumes you know how to use it. IMPORTANT CAVEAT For my Debrid media consumption, I really am interested in Debrid media at 1080p resolution. Some of my configuration below will reflect this. This doesn't mean it is limited to those. After you get going, you can explore CLI_Debrid and the MediaFusion settings to change this. I have not tried getting other resolutions. ANOTHER VERY IMPORTANT CAVEAT: I have my /appdata stored in a drive pool called cahe... this was the norm w/ unRAID for a long time, and stuck to it. With the advent of multiple pools, it may be the case where your appdata is NOT located at /mnt/cache/appdata. If this is the case, you will need to adjust my instructions below to account for this. Step 1 - Create a share and a folder in /mnt/cache/appdata Create User Share In unRAID's Web UI, go to Share and create a new root share. Name this share "zurg". In this new share, we are going to be mounting (via rclone) a folder that your Real Debrid account creates for you out in the cloud somewhere. Not that it matters for our purposes, but I believe this remote folder stores a torrent file that is linked to the actual media file you want. Please configure your share as below. Remember this folder is NOT store in unRAID; it is only mounted. No need to back the folder up, no need to store, or move it to the array. In my example, I am mounting this folder to my "DownloadCache" pool. I strongly advise NOT mounting it on the array. I cannot guarantee it it will work on the array. This folder is NOT meant to be touched. Do not put or manipulate files in there; do not copy or erase files from it. Note that I am sharing it as NFS and SMB: Create and Configure the Zurg Folder in Appdata Go to your appdata folder... and create a new folder called "zurg". So in my case it is in /mnt/cache/appdata/zurg/ Download the latest zurg binary from the Zurge-Testing repo here. Extract the single file named zurg and place it in this folder. I am linking to file directly, but if you land on the repo, this is the file you need: Also, into this folder, copy the zip file you download from my repo above. After extracting the zip file, you should end up with this: Edit the file rclone.conf and change the IP to your unRAID's internal IP: Edit the file config.yml to add your Real Debrid AP Private Token. After you have set up your paid Real Debrid account, the API key can be located at this link: https://real-debrid.com/devices Edit the config.yml : Edit the file plex_update.sh There are three things that need to be changed and verified: Change the Plex IP and port to match your setup Paste your Plex Token... If you don't know how to do this, follow this link. Make sure that the zurg user share you created earlier is properly found in your unraid at /mnt/user/zurg. If it does not, fix it please. Do NOT change the zurg_mount value in the script file. In unRAID, open a terminal window and type the following commands - One line at a time: cd /mnt/cache/appdata/zurg chmod +x zurg chmod +x plex_update.sh Create User Scripts that Launch and Kill Rclone and Zurg Zurg is an application that takes the Real Debrid stuff, and makes it so that Plex can interpret the data and properly shows in Plex. That is the extent of my knowledge. It is required. Rclone mounts the remote Real Debrid cloud folder to a share in your server. In our case, this will be mounted into /mnt/user/zurg. Very important. As of this writing, no unRAID docker template exists for this. The required items to make these two run, is what we stored in /mnt/cache/appdata/zurg. To automatically launch Zurg and the Rclone share, we are going to create User Scripts specifically do this. We will be creating three separate scripts. For the Start Zurg Service script, paste this: #!/bin/bash cd /mnt/user/appdata/zurg chmod 777 zurg /mnt/user/appdata/zurg/./zurg & Please make sure the schedule is set to "At Starting of Array". If you ever want to manually launch this script form the User Scripts page, you MUST click on RUN IN BACKGROUND. For the Start Zurg Rclone Mount script, paste this: #!/bin/bash sleep 10 rclone mount zurg-wd: /mnt/downloadcache/zurg --dir-cache-time 20s --config=/mnt/user/appdata/zurg/rclone.conf --allow-other --allow-non-empty --gid 100 --uid 99 --daemon Please note in the script above, I am actually specifying the actual pool folder and NOT the user share. I did this in case the array has not completed starting when the script is executed. Please change my /mnt/downloadcache/zurg to the actual drive you are using to house this mount. Please make sure the schedule is set to "At Starting of Array". If you ever want to manually launch this script from the User Scripts page, you MUST click on RUN IN BACKGROUND. For the Zurg-UNMOUNT Drive script, paste this: #!/bin/bash pkill zurg sleep 2 fusermount -uz /mnt/downloadcache/zurg Please make sure the schedule is set to "At Stopping of Array". Some explanations here. This is meant to run once you execute an Array Stop. If you were to try to stop the array without this, you would end up in a dreaded "Retry un-mounting disks" situation. This will require an unclean reboot/shutdown of your server and will cause a parity check when you start back up. We also need to stop the zurg process from running. This is running in the background and must be stopped in order to not get the unclean shutdown. Also please note the script needs to reference the actual path of the zurg folder. I have mine at /mnt/downloadcache/zurg. Please change this accordingly. After firing the first two scripts (remember the third kills what we are starting), you can check they are both properly running by going to your /mnt/user/zurg folder, and you should see this: Also in your web browser, navigate to http://192.168.0.XXX:9999 (change your IP). You should see a zurg status page (nothing gets configured here). YOU MUST SEE THE ABOVE BEFORE CONTINUING If you see these, wonderful, consider yourself lucky - I spent about 2 weeks trying to get this to work. However, we still have a long way to go. If you do NOT see these items in the folder, retrace all the steps above. If that does not work, I may need the help of others to figure out why. If you ultimately cannot get this to work, there is no point going forward with this guide. Step 2 - The Setup of Dockers The paths and references, so that all the dockers talk to each other properly, are VERY important. Please follow the below carefully. In some occasions, you will need to add additional paths to some of the existing Docker templates. Plex Media Server: Unfortunately, this is NOT compatible with Jellyfin or Emby. The CLI_Debrid docker is not yet compatible with these. I assume you already have Plex running with locally stored Movie and TV Show libraries. We need to configure Plex with additional libraries to include the rclone mounted Debrid media. This media will appear in your /mnt/user/zurg folder. Movies show up as single .mkv files, all stored in one big folder. They will also show up in the __all__ folder. This is normal, and you should NEVER try to manually organize this. Edit your Plex template and ADD the highlighted path: Start Plex and go to Settings > Manage > Libraries. We are going to add two new libraries. One for the Debrid Movies and one for the Debrid TV Shows. In my screepcap below, I have already added the two libraries. To add libraries, Movies 1) Click Add Library. On the screen that pops up, select Movies and name the library Movies-DB. Click Next... 2) Click on Browse Folders for library, and select /data/movies. Remember this is the mounted rclone folder. On the Advanced tab, make sure you have the below options set. TV Shows Similar to the process above, except: Call the new library TV Shows-DB Select library type as TV Shows Point to the folder /data/shows It will scan those new folders for content; but as a newbie, you probably don't have any media yet. When looking at all your Libraries, click on the little movie icon to the right of Movies-DB to expand the options. Please match all the checks shown below: Repeat this for the TV Shows-DB library OPTIONAL: If you want Debrid Movies and TV Shows in your Recently Added elements of your Plex Home page showing both your local media and you Debrid media, follow the below: Go back to your Plex Home Page, and on the right side menu select More: Click on the Movies-DB library, click on the three dots, and select Pin Repeat for the TV Shows-DB. It should look something like the below. Click on the "< Pinned" item to return to the Home menu. End of OPTIONAL. In Plex > Settings > Settings > Library make sure you have the below items ticked: Overseer: If you already use Overseer, and you use Radarr/Sonarr with it, you may want to create a new Overseerr docker for Debrid only use. I will assume that you are not using Overseerr at the moment or with Sonarr/Radarr or torrents.... There is nothing to change to the default Overseerr docker template. Overseer allows you to have your Plex users request and add media to your collection. You are the Admin, and you can individually allow your Plex friends to request/add. Overseer gives you the following options to you and your users Add TV/Movies directly without your approval Allows user to request, but you have to approve their requests Allows you and your to automatically request what is on their Plex watch list Users log in via their Plex account. You can configure Overseer as you see fit. In my case, I have a two users that can automatically add their requests and what is on their watch list. I will paste my Settings screens below based on this. I will also highlight CRITICAL settings as well. If screen is not included below, you can leave w/ default values. As mentioned above, we will need to return to Overseer once we do some stuff. CLI_Debrid Docker: This makes the magic happen. In unRAID go to Community Apps, search for "CLI_Debrid" and click install. On the Docker setup screen match this: It is possible that the Path I am highlighting above does not exists (I can't recall, and I don't want to bork my installation). If it does not exist, add it. Change your Time Zones per your location. OPTIONAL: This is a very hernandito thing. I am manic compulsive obsessive over icons. I created a new icon for this Docker. If you want, you can use what I use. Enable Advanced Setting in the docker setup page and paste: https://i.imgur.com/3TduuDn.png Click to add the docker. Once the Docker is started, go to its web ui on port :5000. IMPORTANT: You will be presented with a big dialog about using a new Phalanx database option. Please pick to NO. Disable. I could not get things to work with this option enabled. You will be presented with a Wizard to set up... again no screencap... try to muddle through the options. I believe the options is asking are all changeable in the Settings pages, which I will post below. Once you are in the home screen, please make sure the button on the top-right is green like picture below. You will not be able to change settings if this is running: Then please navigate to the Settings screen. On center top menu go to System > Settings. Below are the settings you need to apply. I will highlight special instructions on the screens below. Please make sure you Save Settings before changing tabs.: Required Settings: Scrapers: Add two scrapers. One will be a Zilean scraper, the other one is MediaFusion. For the Zilean configuration, enter https://zilean.elfhosted.com For MediaFusion, go to this web site. https://mediafusion.elfhosted.com/configure. As I mentioned earlier, I only want 1080P content. You can experiment with other choices, but I dont know what will result. Now return to your CLI_Debrid Settings > Scrapers (second from the above screen capture) and click on the URL: field for MediaFusion. Then paste the code that was placed in your clipboard by the MediaFusion web site. Save Settings..... Version Settings: EDIT - 3/31/25: Since I originally wrote this, I have learned and tested more on the Version Quality Settings. Please refer to the Tips section at the end of the guide for more updated information. Sorry, same caveat... I only want 1080p content. When I first strted setting this up, this page caused some confusion. In order to properly set up please follow my instructions, and later you can come back and experiment. In you are only interested in 1080p you should be set. I am sure godver3 and @mash2k3 would laugh at me... but remember I am still a newbie at this Debrid stuff. In this page, you can set your file size limits and change your version priorities. I was getting some pretty huge files (50GB BR Remux) that did not play well in Plex (constantly re-caching). I lowered my size limit and re-scraped. I get better file sizes that should be more playable in Plex. I have 1GB internet... I dont know how others are able to play those huge files. I added 4K as a resolution option, again setting my max file size to 22GB. Here are the steps I followed: If there are any options displayed, click the red Delete button on each one until you get rid of everything. Click on the "Add Separate 180p/4K Versions" button. Then I deleted all the 4K versions, so it looks like the screenshot above. Save Settings.... Content Sources: Click on "Add New Source" and select Overseerr Put your internal URL and port number for your Overseer docker Go to the Overseerr web ui, and click Settings > General. Copy the API Key Return to CLI_Debrid and paste the API key. When you do this copy, make sure you check that against what is in Overseerr. For some reason I ended up w/ two = signs at the end... that made things not work. Save Settings. Additional Settings: I only made two changes. I added my TMDB API Key. You need to go to their web site to generate one. I added my Username and Password to my OpenSubtitles.com account. I have a paid account so I can get subtitles. Advanced Settings: Again, I made only two changes here towards the bottom of the screen. I enabled the Unmatched Items Check (helps with getting realeases that do not match what you wanted). Changed the Overseerr check period. Changed it to 2 minutes to not have to wait too long while testing the whole thing. After you get everything working, you should change it back. This is it for all the Settings I customized in CLI_Debrid. This is a very powerful program that takes time to familiarize. If you run into any issues, I suggest going to their Discord and asking. BUT, please consider supporting them by becoming a Patreon member. The link is right on the header of the web page. Back to the Overseerr Docker: In Overseer, go to Settings > Plex and perform the following steps: Click on the "Sync Libraries Button" and wait until your libraries show up. Check All the Libraries (this will ensure you do not add duplicate media between your local files and your Debrid media). If you search for an item, and it is already in one of your libraries, Overseerr will show it as Available. This is also helpful if you have users that do not bother to check if something is already in your library before requesting. Click "Save Changes" Click the "Start Scan". This will scan all your libraries to know what you already have. This will take time. Just let it run and let's keep on going. Testing it All The moment of truth.... Go to the CLI_Debrid UI and click the green button on upper right to start the program. You may want to open the dockers log window to get a sense of what it is doing. Make sure Plex and CLI_Debrid are running properly. Make sure the Real Debrid folder is mounted at /mnt/user/zurg. (continues next post....)

-
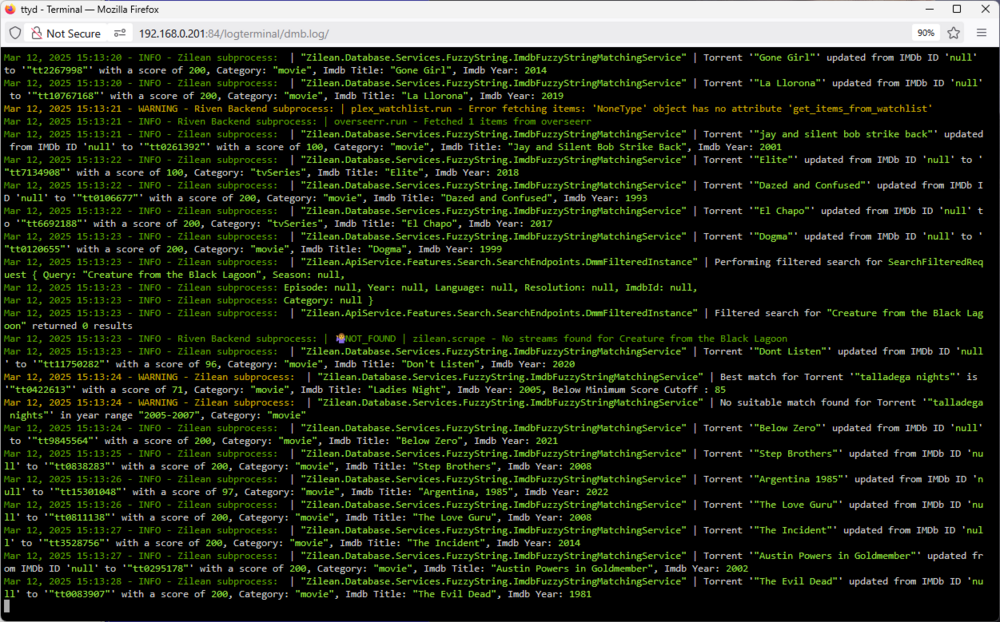
I'm baffled by this: DMB is searching for all these movies I have NOT requested. Earlier, because of the Listrr setting in Riven, It was adding all the movies in the list I found. To remedy, I deleted the DMB docker and all the folders it created. Then I did a clean fresh install of DMB. I did NOT add the Listerr option. I only checked on Overseer as Content source. In Overseer, my request list is empty/clear. I had hoped this captured my requests in Overseer. Why are these files being scanned. They do not land in my Real-Debrid torrent list and are not symlinked/mounted to the rclone folder. It seems like it's scanning movies in Spanish. Thanks. ps.... Riven did capture a movie in my Overseer list...! YAY...! But I still don't know why it is scanning all those files.
-
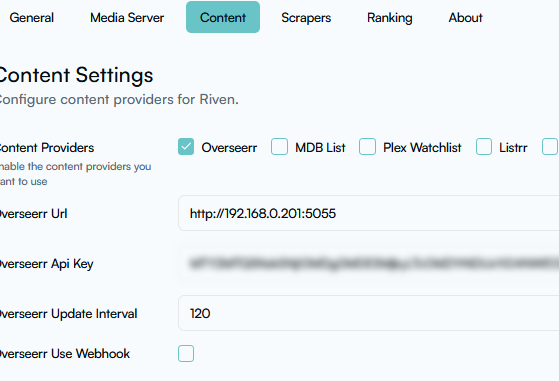
Thank you! I will take your advice on keeping separate libraries in Plex. I am NOT a fan of Trakt. I don’t like that my library contents is floating out there. I can’t figure out how to set up with Overseer…. I have Overseer working with Radarr/Sonarr. But going into settings I don’t see how to connect to Riven or the Debrid stuff. I know I would likely need to set up a separate Overseer container for Debrid… but can’t figure out how to setup the automation. My main thing is being able to look at lists of movies or shows. My usual is to look at what IMDB is featuring and if I find something interesting, I manually switch over to Radarr/Sonarr UI and add it. It used to be that the two would automatically import anything on my IMDB watchlist, but somehow that stopped working…. I think my ideal process to add media would be for a couple of my plex users and myself log in to a reverse proxied Overseer/Petio, they can search and add their movie/show, and it would land in the rclone folder above. For my permanent, ”stored in unRAID” media, only I will use Sonarr/Radarr (Usenet downloads). Personally, 99% of the time, I use Kodi on my TV’s, each with their own HTPC. I do not use Plex. With Kodi, I love Fen Lite, Umbrella, Seren add-ons as I can browse lists and search for anything, and I get to watch it by simply clicking on it. I shortcut certain lists like “Best Sci-Fi movies” or “Your mind will never be the same after watching” or “Mindf**k” movies. I get to do this while laying flat on my couch. I think you can add these lists into Riven, but then again, Riven is not geared for user accounts. I use Plex for my friends and family. I want to implement this so when they ask me for some lame reality show, I don’t take up my precious storage. Not a fan of the Kardashian family; I need to keep all the brain cells I have remaining. one question, in Riven, the Plex scan interval is set to 120. However I think things will only show up if I manually scan the library. It would be nice if stuff shows up in Plex right away. I will investigate further. But any tips? thank you again!
-
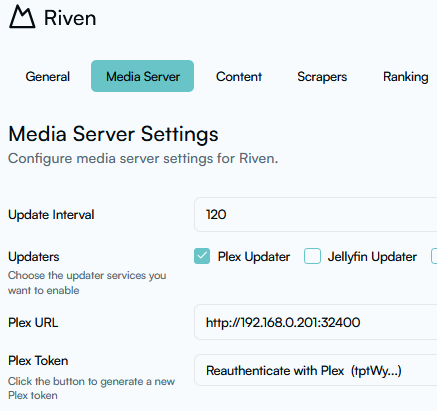
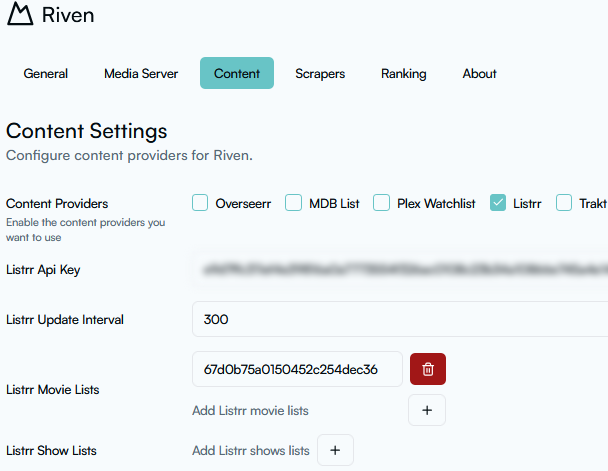
My Progress.... In Plex docker, I added this path: In Riven settings, I added my Plex Media Server: I went to the Listrr web site (https://listrr.pro) and created an account. Once in the account, I created my own list with the following criteria: - Movies between 1970 and 2032 w/ IMDB rating between 5.8 and 9.9. I copied the list ID into Riven along with my Listrr API key Don’t do this…. It will add all these movies to your Riven! I went to Torrentio (https://torrentio.strem.fun/configure) and configured my preferences for language, qualities to omit. I also pasted my RD API key. I clicked on the "Install" button. I then pasted the text that was put in my clipboard into text editor (API changed). Back in Riven > Scraper settings, I did the following (note the pasting on the quality filter section in the URL above. Note; I also clicked on Zilean and left the default values: And finally, in Riven > Ranking settings: I checked these: On Riven's main page, I searched for a specific movie. Then I asked it to Manually Scrape It gave me a "Success" message... I went to my unRAID's folder - /mnt/user/DMB/dmb/zurg/mnt/rclone_RD/movies/ and sure enough the mkv file is in there. In my Plex > Manage Libraries, I added a new "Movies" library which I names "Movies-RD", and pointed it to: When I click on that new library, I see the one movie.... and it plays! I call this progress. Here are some questions and things I want: 1 ) An easy one, I need to figure out how to show this new library in my Plex Home UI... Or perhaps consolidate with my original Movies library. 2 ) Was the MKV I see in the folder above a fully 7 GB downloaded file that was stored there? Or is it a symlink / pointer? 3) Is there any other way to add content outside of Riven... like Overseer, or Petio? I want to allow some family member the ability to add stuff. Riven does not seem geared for user accounts. I also have to look further as I do not recall seeing any options on which version of the one movie I picked to add. I can perhaps continue editing this post and have it be a guide for the newbies like myself. Thank you again for creating this and for your help. H.

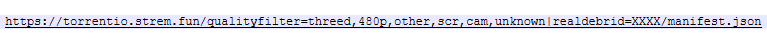

-
Fantastic.... it worked! Thank you. I do have NPM, but this is not proxied in any way ATM. Now on to figure out how the rest works. Thank you again for your help.....!
-
I have reinstalled DMB and I properly get the website… But I can’t save any settings as I get the “Cross posts are forbidden” error. I am set to bridge mode. And Origin is set to http://192.168.0.201:3000, which is my server’s IP. I can get to the Riven ui. i tried changing to host mode, and the log stays stuck at: Any ideas? Thank you.
-
A restart of the server allowed me to delete the folder....
-
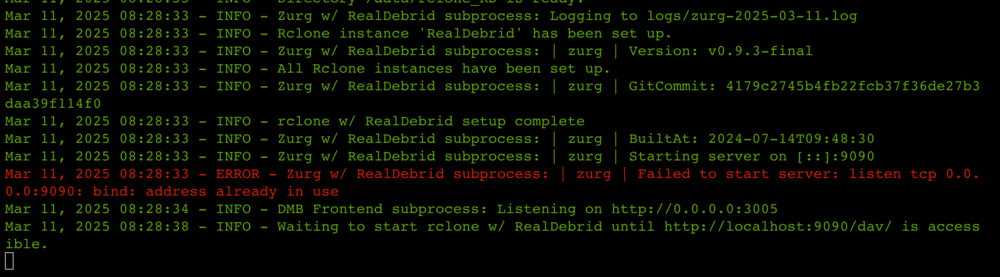
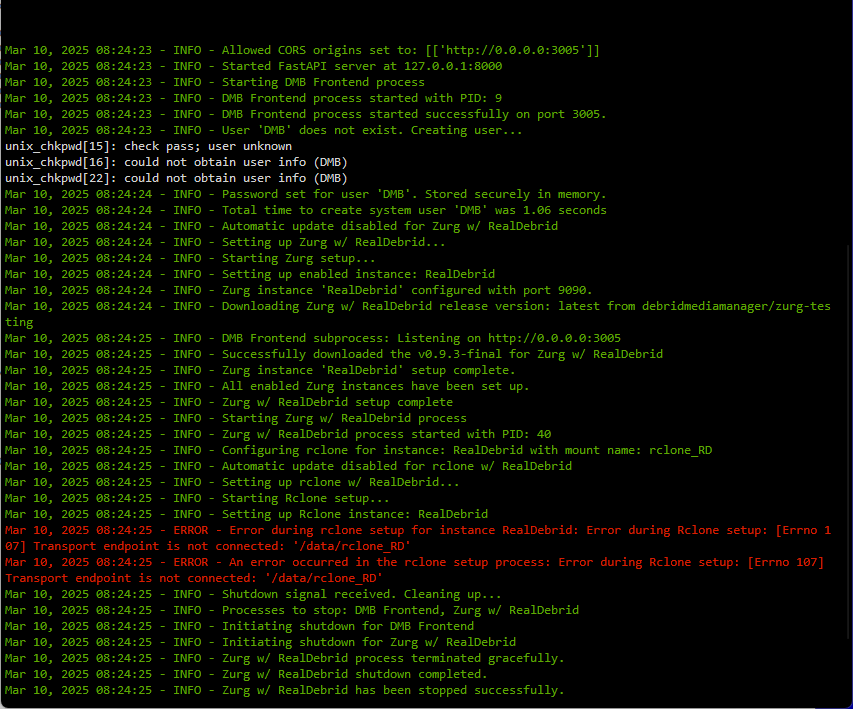
Hi... I ran into an issue. In trying to resolve the "Cross-site POST form submissions are forbidden" error, I removed the Docker to re-install. The docker created a file-folder /mnt/user/DMB/dmb/zurg/mnt. After removing the DMB docker, I cannot erase this folder. At one time it contained a file $rclone_DB that I could not erase via the console or Windows. After several re-installs, the one file is no longer there, but I still cannot erase the folder. I have tried re-installing the DMB container, but it quits right after starting up. This is the log: Version: 6.1.6 Mar 9, 2025 12:25:31 - INFO - Allowed CORS origins set to: [['http://0.0.0.0:3005']] Mar 9, 2025 12:25:31 - INFO - Started FastAPI server at 127.0.0.1:8000 Mar 9, 2025 12:25:31 - INFO - Starting DMB Frontend process Mar 9, 2025 12:25:31 - INFO - DMB Frontend process started with PID: 9 Mar 9, 2025 12:25:31 - INFO - DMB Frontend process started successfully on port 3005. Mar 9, 2025 12:25:31 - INFO - User 'DMB' does not exist. Creating user... Mar 9, 2025 12:25:33 - INFO - Password set for user 'DMB'. Stored securely in memory. Mar 9, 2025 12:25:33 - ERROR - Error changing ownership of '/data/rclone_RD': [Errno 107] Transport endpoint is not connected: '/data/rclone_RD' Mar 9, 2025 12:25:33 - INFO - Total time to create system user 'DMB' was 1.53 seconds Mar 9, 2025 12:25:33 - INFO - Automatic update disabled for Zurg w/ RealDebrid Mar 9, 2025 12:25:33 - INFO - Setting up Zurg w/ RealDebrid... Mar 9, 2025 12:25:33 - INFO - Starting Zurg setup... Mar 9, 2025 12:25:33 - INFO - Setting up enabled instance: RealDebrid Mar 9, 2025 12:25:33 - INFO - Shutdown signal received. Cleaning up... Mar 9, 2025 12:25:33 - INFO - Processes to stop: DMB Frontend Mar 9, 2025 12:25:33 - INFO - Initiating shutdown for DMB Frontend Mar 9, 2025 12:25:33 - INFO - DMB Frontend process terminated gracefully. Mar 9, 2025 12:25:33 - INFO - DMB Frontend shutdown completed. Mar 9, 2025 12:25:33 - INFO - DMB Frontend has been stopped successfully. Mar 9, 2025 12:25:38 - INFO - Shutdown complete. Mar 9, 2025 12:45:44 - INFO - I have tried several times with the same result. I have manually removed the docker and all created files and folders in /appdata and the array. Except I cannot delete the one folder. Being that it is a share, I have tried deleting the share on the unRAID WebUI as well with no luck. I don't know if it new install are failing because that one folder is existing. Here is my docker setup page for DMB. Any help is greatly appreciated. Even if I cant get DMB to work, I would love to be able to delete the folder. Thanks. H. p.s. The latest re-install shows additional errors in red:

-
Thank you! This all sounds like a bug…. Scheduled mover should not activate when data rebuild is in progress; and status of mover is not being reported per my original post. Thanks again… on my way to stop the mover.
-
Thanks @itimpi. Glad to hear it’s not an issue other than performance. Server is not doing a parity check. It’s rebuilding a drive that went bad and was replaced. I assume I can either pause the drive rebuild on Main page. Or I can go to console and issue the “mover stop” command. The second option sounds better as I want the array back to normal asap. thoughts?
-
Hi…. My server is early-on on a drive data rebuild (16%), and mover button was disabled because of this. I woke up and drive data rebuild says it will take like 20 days. Last night it said it was going to take about 28 hours. I see on the Main page that the Move button is available to push. I go to Settings > Schedules and it reports “mover as running”. so two things… One, the mover status is not reporting like my original post. And two, scheduler activated the mover overnight even though unRAID was in the middle of a drive rebuild. This is concerning as mover should be not be running. is this an issue? I have about 1TB in cache that is copying to the array. thanks.
-
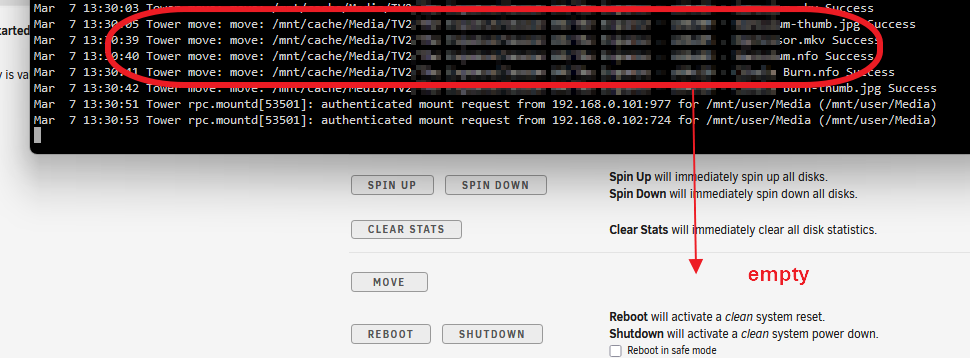
Hello, I am in the middle of a large "Mover" operation. Mover is running properly, but on unRAID's main screen, it does NOT show it as running. I do NOT have the "Mover Tuning" plugin installed. When I had it installed, it was fake-moving files to /user0 folder. I also do NOT have "Automatic Turbo Mode" enabled. Is this a bug, or is something not set up correctly? Please see screencap below: Thank you.
-
The ones with the gradient backgrounds are REALLY hard to modify; takes me about 45 minutes for each icon... I have done the pale blue, blue, and yellow. I will look to see if I can streamline the method. In the meantime, if you have any favorites in the gradient versions, please let me know and I will focus on those first.
-
Another shameless plug to my animated FolderView icons... I have added a lot of icons over the past couple months: https://github.com/hernandito/unRAID-Docker-Folder-Animated-Icons---Alternate-Colors I take requests too....
-
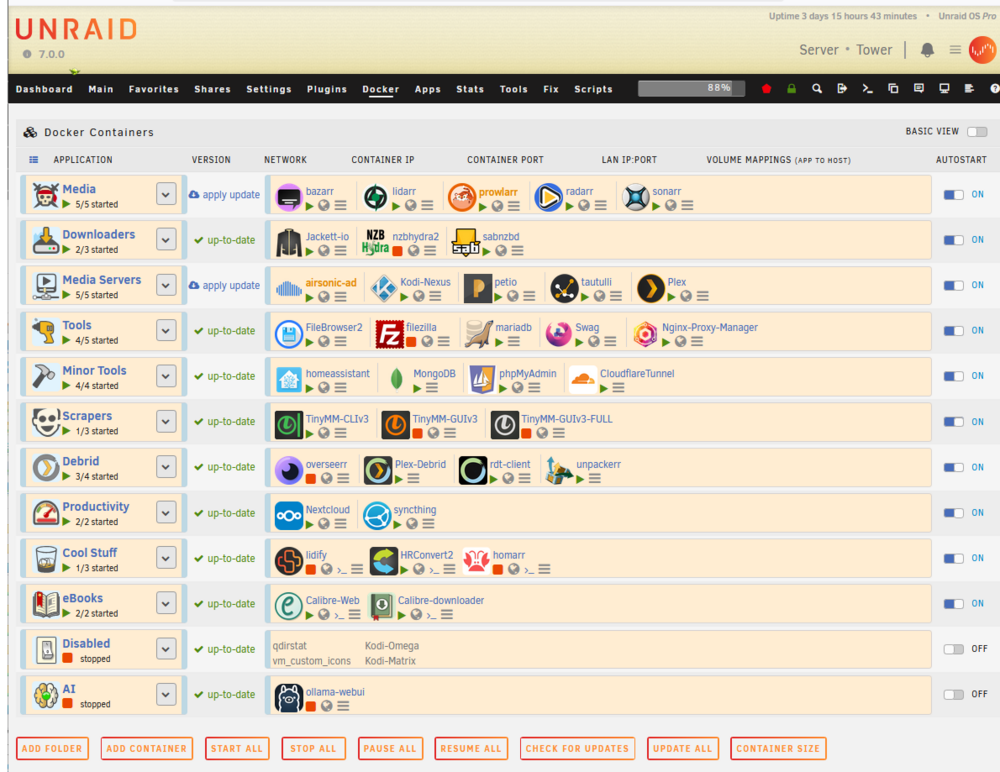
Hear, hear.... This is begging to be included in unRAID. Looking at a long list of of dockers sounds like an ordeal. I use the Dockers page as my main unRAID page; meaning I have a pinned tab in my browser with the Dockers page. I just love looking at all these beautiful Docker apps...
-
THANK YOU!!!!! It worked. An addition(s) to your instructions on the backup procedure. I have created custom .css files that further customize the UI. Prior to doing any of the steps above, users should copy the folder: /boot/config/plugins/folder.view/styles There is also a /scripts folder. I don't have any scripts (nor do I know exactly how to use), but people should copy this as well. In broad terms, what were the changes you made? The history of this plugin... @GuildDarts came up with the original version. I helped him refine the UI into something similar to the current version. That original developer then decided to no longer develop it. There was at some point a significant unRAID upgrade that broke the plugin. One of the unRAID All-Stars (wish I could remember who) did a tweak that un-broke it. He clearly stated it was a fix, but was not planning to keep developing. At some point @scolcipitato created a new version... I helped him as well to refine the UI and allow more customization for it. See my screencap above and compare to the stock UI. I hope someone picks up the development. @VladoPortos I am volunteering you for the job... 😁 Thank you again...!
-
I am deeply saddened to see @scolcipitato leaving us.... this is by far the BEST plugin, and it should be built-in into stock unRAID. @VladoPortos please, how do I get to your fix for this????? My Docker page still works... but I cannot edit the Docker Folders. I am scared I am a breath away from the plugin to fail completely. I will roll back to 6.x version of unRAID when that happens. Holding my breath for this.... 🤢 The setup page
-
Hello. Recently my Usenet download speeds have dropped dramatically. I used to get about 1000Mbps... today I am at 95Mbps. I thought it was my cable modem, so I got a new one from my ISP. No improvement. I did a Speedtest from my Windows machine, and I got 900Mbps. In unRAID, I installed speed-test-cli inside one of my dockers. I consoled into the Docker and ran a test... 93Mbps.... about 1/10th. When I internally copy files to/from the server, they copy very slow... So something is wrong with my unRAID's network speed (both inside the LAN and on the internet). Could I have changed a setting somewhere that is causing this? I am baffled. It's a Supermicro motherboard so NIC should be reliable. I have attached diagnostics. Thank you, H. tower-diagnostics-20250201-1151.zip