




jcreynoldsii
Community Developer
-
Joined
-
Last visited
Everything posted by jcreynoldsii
-
Thanks, this helped me out too.
-
I've been running a tail on log, just saw these weird messages.
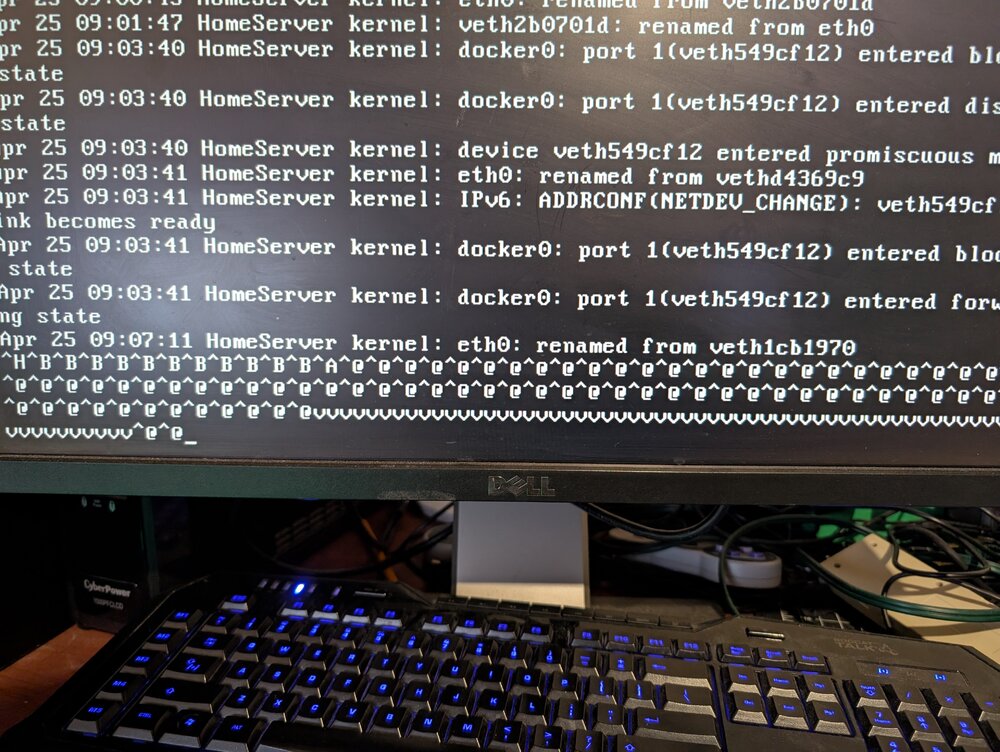
-
Upgrade to 6.12.15. This issue only seems to happen last evening/night. Could it be related to a task that's happening?
-
No I have not, upgrading always tends to introduce new issues. What version is the most stable that you recommend to upgrade to based upon my current version? Those particular files are in the boot/packages dir. To my knowledge I did not place them there.
-
memtest passed with no failures. I noticed a few interesting errors on startup of unraid from my console. sh: line 1: ./apcupsd-3.14.10-x86_64-1_rlw.txz.auto_install: Permission denied sh: line 1: ./powerdown-2.06-noarch-unRAID.tgz.auto_install: Permission denied sh: line 1: ./screen-4.03-x86_64-4.txz.auto_install: Permission denied Attached most recent syslog. syslog.log
-
I have had a crash which resulted in an un-clean shutdown. They first occurrence was yesterday and the second was today. There is nothing new from a configuration standpoint. So I am suspecting something hardware related. What do my logs tell someone that knows what to look for? homeserver-diagnostics-20250421-2125.zip syslog.log
-
Dm'd Sent from my Pixel 6 Pro using Tapatalk
-
PM sent
-
I'll buy. Dm sent.
-
Not that I could tell, issue has resolved itself for now. Thanks.
-
unraid os: 6.8.3 Apps: 2020.07.13 My community apps section is no longer loading, get this message instead: Something really wrong went on during get_content Post the ENTIRE contents of this message in the Community Applications Support Thread No data was returned. It is probable that another browser session has rebooted your server. Reloading this browser tab will probably fix this error What can I do to determine cause? Jay
-
I was afraid you would say that, the setup for this guy isn't the most intuitive. I'll have to remember all the different steps and screens I went to in order to make this work. Where is the config file located so I can replicate settings?
-
Ran the command here are the results: root@BennySRV:/mnt/user/Config/openvpn-as/scripts# ls -la total 140 drwxrwxrwx 1 nobody users 4096 Oct 7 17:24 ./ drwxrwxrwx 1 nobody users 201 Oct 10 15:15 ../ -rwxrwxr-x 1 nobody users 406 Oct 7 17:24 authcli* -rwxrwxr-x 1 nobody users 403 Oct 7 17:24 bridge* -rwxrwxr-x 1 nobody users 406 Oct 7 17:24 certool* -rwxrwxr-x 1 nobody users 406 Oct 7 17:24 confdba* -rwxrwxr-x 1 nobody users 2737 Oct 7 17:24 db-update-1.8* -rwxrwxr-x 1 nobody users 400 Oct 7 17:24 dbcvt* -rwxrwxr-x 1 nobody users 403 Oct 7 17:24 dnscli* -rwxrwxr-x 1 nobody users 421 Oct 7 17:24 dnsfo_active* -rwxrwxr-x 1 nobody users 424 Oct 7 17:24 dnsfo_standby* -rwxrwxr-x 1 nobody users 403 Oct 7 17:24 iosvod* -rwxrwxr-x 1 nobody users 400 Oct 7 17:24 liman* -rwxrwxr-x 1 nobody users 403 Oct 7 17:24 logdba* -rwxrwxr-x 1 nobody users 403 Oct 7 17:24 mandep* -rwxrwxr-x 1 nobody users 406 Oct 7 17:24 netinfo* -rwxrwxr-x 1 nobody users 412 Oct 7 17:24 openvpnas* -rwxrwxr-x 1 nobody users 454 Oct 7 17:24 openvpnas_deferred_init* -rwxrwxr-x 1 nobody users 439 Oct 7 17:24 openvpnas_gen_init* -rwxrwxr-x 1 nobody users 466 Oct 7 17:24 openvpnas_gen_init_deferred* -rwxrwxr-x 1 nobody users 436 Oct 7 17:24 openvpnas_gen_pam* -rwxrwxr-x 1 nobody users 415 Oct 7 17:24 openvpncc* -rwxrwxr-x 1 nobody users 421 Oct 7 17:24 openvpncdisp* -rwxrwxr-x 1 nobody users 427 Oct 7 17:24 openvpncnode* -rwxrwxr-x 1 nobody users 415 Oct 7 17:24 ovpnpasswd* -rwxrwxr-x 1 nobody users 391 Oct 7 17:24 sa* -rwxrwxr-x 1 nobody users 400 Oct 7 17:24 sacli* -rwxrwxr-x 1 nobody users 409 Oct 7 17:24 signtool* -rwxrwxr-x 1 nobody users 281 Oct 7 17:24 sqlite3* -rwxrwxr-x 1 nobody users 421 Oct 7 17:24 sshrpc_agent* -rwxrwxr-x 1 nobody users 421 Oct 7 17:24 ucarp_active* -rwxrwxr-x 1 nobody users 424 Oct 7 17:24 ucarp_standby* -rwxrwxr-x 1 nobody users 427 Oct 7 17:24 update_as_conf* -rwxrwxr-x 1 nobody users 424 Oct 7 17:24 update_va_ver* -rwxrwxr-x 1 nobody users 406 Oct 7 17:24 userdba* -rwxrwxr-x 1 nobody users 394 Oct 7 17:24 web* Somewhat different error in log: /config/scripts/openvpnas: line 11: /config/bin/python: Permission denied
-
Well I think it's safe to say there's a permissions issue. Can you do a ls -la on the directory and post the results here? In general new permissions isn't a good idea on appdata. root@BennySRV:/mnt/user/Config/openvpn-as/scripts# ls -la total 140 drwxrwxrwx 1 nobody users 4096 Oct 7 17:24 ./ drwxrwxrwx 1 nobody users 201 Oct 10 15:15 ../ -rw-rw-rw- 1 nobody users 406 Oct 7 17:24 authcli -rw-rw-rw- 1 nobody users 403 Oct 7 17:24 bridge -rw-rw-rw- 1 nobody users 406 Oct 7 17:24 certool -rw-rw-rw- 1 nobody users 406 Oct 7 17:24 confdba -rw-rw-rw- 1 nobody users 2737 Oct 7 17:24 db-update-1.8 -rw-rw-rw- 1 nobody users 400 Oct 7 17:24 dbcvt -rw-rw-rw- 1 nobody users 403 Oct 7 17:24 dnscli -rw-rw-rw- 1 nobody users 421 Oct 7 17:24 dnsfo_active -rw-rw-rw- 1 nobody users 424 Oct 7 17:24 dnsfo_standby -rw-rw-rw- 1 nobody users 403 Oct 7 17:24 iosvod -rw-rw-rw- 1 nobody users 400 Oct 7 17:24 liman -rw-rw-rw- 1 nobody users 403 Oct 7 17:24 logdba -rw-rw-rw- 1 nobody users 403 Oct 7 17:24 mandep -rw-rw-rw- 1 nobody users 406 Oct 7 17:24 netinfo -rw-rw-rw- 1 nobody users 412 Oct 7 17:24 openvpnas -rw-rw-rw- 1 nobody users 454 Oct 7 17:24 openvpnas_deferred_init -rw-rw-rw- 1 nobody users 439 Oct 7 17:24 openvpnas_gen_init -rw-rw-rw- 1 nobody users 466 Oct 7 17:24 openvpnas_gen_init_deferred -rw-rw-rw- 1 nobody users 436 Oct 7 17:24 openvpnas_gen_pam -rw-rw-rw- 1 nobody users 415 Oct 7 17:24 openvpncc -rw-rw-rw- 1 nobody users 421 Oct 7 17:24 openvpncdisp -rw-rw-rw- 1 nobody users 427 Oct 7 17:24 openvpncnode -rw-rw-rw- 1 nobody users 415 Oct 7 17:24 ovpnpasswd -rw-rw-rw- 1 nobody users 391 Oct 7 17:24 sa -rw-rw-rw- 1 nobody users 400 Oct 7 17:24 sacli -rw-rw-rw- 1 nobody users 409 Oct 7 17:24 signtool -rw-rw-rw- 1 nobody users 281 Oct 7 17:24 sqlite3 -rw-rw-rw- 1 nobody users 421 Oct 7 17:24 sshrpc_agent -rw-rw-rw- 1 nobody users 421 Oct 7 17:24 ucarp_active -rw-rw-rw- 1 nobody users 424 Oct 7 17:24 ucarp_standby -rw-rw-rw- 1 nobody users 427 Oct 7 17:24 update_as_conf -rw-rw-rw- 1 nobody users 424 Oct 7 17:24 update_va_ver -rw-rw-rw- 1 nobody users 406 Oct 7 17:24 userdba -rw-rw-rw- 1 nobody users 394 Oct 7 17:24 web
-
I went from having this setup and working to not, and this is the only thing that I can find in the docker log. I ran new permissions this didnt work. Any ideas? ./run: line 3: /config/scripts/openvpnas: Permission denied ./run: line 3: /config/scripts/openvpnas: Permission denied ./run: line 3: /config/scripts/openvpnas: Permission denied ./run: line 3: /config/scripts/openvpnas: Permission denied ./run: line 3: /config/scripts/openvpnas: Permission denied ./run: line 3: /config/scripts/openvpnas: Permission denied
