





ThatDude
Members
-
Joined
-
Last visited
Everything posted by ThatDude
-
Update, just add a variable to the docker config and you're good to go. Lots of other variable on the github page.
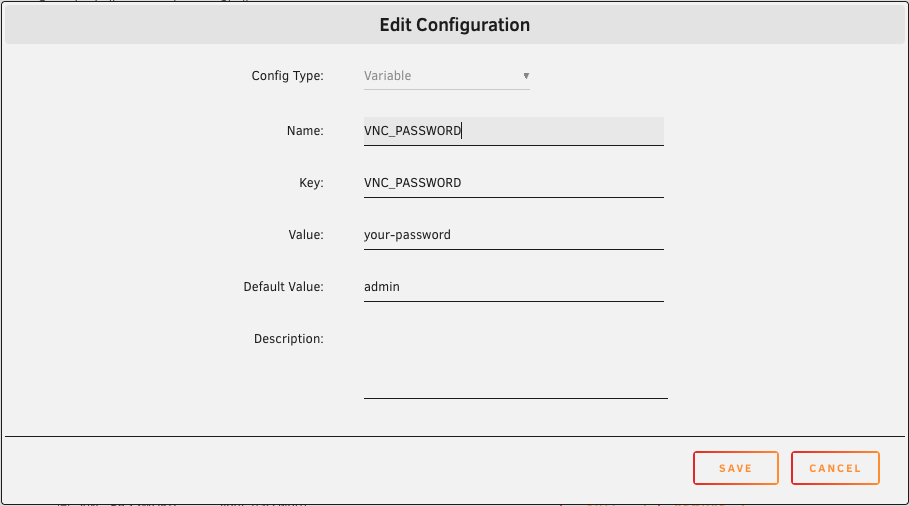
-
Hey this is just what I was looking for, however, how are you protecting the Vorta docker webui from unauthorised access? As-is anyone with the IP and port can manipulate the backups
-
Hi don Open the terminal and type: echo "blacklist r8169" > /boot/config/modprobe.d/r8169.conf Then reboot. Please be aware that this was a old problem and may have been fixed natively in recent unraid builds. PS If for some reason your network doesn't work after the reboot you can login directly on the server and remove that file: rm /boot/config/modprobe.d/r8169.conf And reboot
-
Thanks @JorgeB Could you comment on what the formal security policy is for unRAID? It looks like a version point update is released every 4-12 weeks, is that the baseline for security patches too? I'm genuinely surprised by the responses in this thread, I think we should fully expect level 8 CVEs to be patched in a timely manner, if end users don't install those patches then sure, that's on them. Even if the devs don't want to patch anything until the next release cycle that's fine, just be upfront about it. Apologies in advance if this has already been formally answered by the devs, I didn't see it anywhere.
-
Are you being serious? Have you met 'people' ? I think a better question might be where is the formal policy on patching CVEs? unRAID is a mature paid for product relied upon by X thousands of users around the world. I'm not sure if unRAID enables SSH on a default install (it used to), but if it does what steps are taken to secure the SSH service? Such as disabling root logins by default, key based auth ONLY, enabling the 'deny hosts' plugin etc etc. Offering general advice to not expose unRAID's SSH to the internet is not a formal security policy, and does nothing to protect the unRAID box from lateral movements of hackers that have gained access to the LAN.
-
Is there a formal policy on patching critical CVE's in unRAID? It's been >3 days and you have to assume a percentage of the user base have SSH exposed either deliberately or accidentally.
-
Sorry to resurrect this old thread, I rebuilt my unRAID and forgot to backup my compsize binary, is there any chance one of you could link to yours? I recall building it being a PITA to compile
-
Man I NEVER would have found that on my own 🙂 Thank you very much indeed.
-
Would it be possible to include a list of excluded folders? My main culprit is Plex, the media folder is 58GB and I don't need to back it up as that data will re-generate in a DR scenario. Full path to exclude: "/mnt/user/appdata/plex/Library/Application Support/Plex Media Server/Media" I could work around this using your pre-run script to stop the plex docker, mv the Media folder outside of the 'appdata' path, allow the backup to happen, then move it back in the post-run-script, but I feel dirty just writing this paragraph 🙂 I'm using the compressed archive option so I end up with a series of tar files, maybe could be done with the built in tar exclude options: tar --exclude='./folder' --exclude='./upload/folder2' -zcvf /backup/filename.tgz . On a separate note, thanks for maintaining this plugin, it's brilliant.
-
That correlates - thanks for the clarification.
-
Thanks so much @bonienl I totally missed that post. If Tailscale is running as a plugin presumably I just need to run /usr/local/emhttp/webGui/scripts/reload_services from the go script to get the web interface working. I'm specifically interested in getting the Tailscale plugin operational before the array is brought online as I need to type in my encryption key before the array can start.
-
It looks like recent builds of unRAID lockdown services, which is a good thing! To enable SSH I had to edit /etc/ssh/sshd_config and add my tailscale IP in the listen section: Port 22 AddressFamily any ListenAddress 192.168.1.250 ListenAddress 100.94.227.51 <-------- here ListenAddress fd7a:115c:a1e0:ab12:4843:cd96:625e:e333 Then restart SSH with /etc/rc.d/rc.sshd restart This seems to have updated /boot/config/ssh/sshd_config which I guess means it will work across reboots (I can't test this right now) I guess there will be a similar process for the other services on unRAID
-
First of all thanks for this plugin, it's much needed IMO as running TailScale or ZeroTier in a docker doesn't work unless the array is mounted. I've installed the plugin and 'tailscale up' to add to my tailscale network. I can ping the unraid server from my remote machine but no other services work, SSH, HTTP, SMB etc. Can anyone point me in the right direction? unRAID v6.12.0
-
Thank you. SIGINT was the missing part of the puzzle, I've never come across that before. #!/bin/bash exit_script() { trap - SIGINT SIGTERM # clear the trap kill -- -$$ # Sends SIGTERM to child/sub processes } trap exit_script SIGINT SIGTERM while true; do echo "Do some task" done
-
Hi I have a bash script that starts with the array and continues running in a while loop. This script is preventing my server from shutting down (if I kill the script manually shutdown works as expected). What's the most efficient way to detect a shutdown state from within the bash script so I can have it self terminate? Something like: if exists /tmp/shutdown.txt; then exit 1; fi Many thanks
-
I also need rdiff-backup to be installed on the unRAID base. This is almost certainly not the optimal way to do it, but it works for me. Maybe @EUGENI_CAT would consider making this part of NerdTools? Install the userscripts plugin, add a new script, paste this in: #!/bin/bash # Script to install rdiff-backup on unRAID # Tested against unRAID 6.11.5 - this will need updating in future versions of unRAID when the slackware kernel changes # no erorr checking what-so-ever :-) extra_location="/boot/extra" checkfile="python3-3.9.15-x86_64-1.txz" if [ ! -f ${extra_location}/${checkfile} ] then wget https://slackware.uk/slackware/slackware64-current/slackware64/d/${checkfile} -P ${extra_location} fi checkfile="python-pip-22.2.2-x86_64-1.txz" if [ ! -f ${extra_location}/${checkfile} ] then wget https://slackware.uk/slackware/slackware64-current/slackware64/d/${checkfile} -P ${extra_location} fi checkfile="binutils-2.39-x86_64-1.txz" if [ ! -f ${extra_location}/${checkfile} ] then wget https://slackware.uk/slackware/slackware64-current/slackware64/d/${checkfile} -P ${extra_location} fi checkfile="gcc-12.2.0-x86_64-1.txz" if [ ! -f ${extra_location}/${checkfile} ] then wget https://slackware.uk/slackware/slackware64-current/slackware64/d/${checkfile} -P ${extra_location} fi checkfile="glibc-2.36-x86_64-3.txz" if [ ! -f ${extra_location}/${checkfile} ] then wget https://slackware.uk/slackware/slackware64-current/slackware64/l/${checkfile} -P ${extra_location} fi checkfile="kernel-headers-5.19.17-x86-1.txz" if [ ! -f ${extra_location}/${checkfile} ] then wget https://slackware.uk/slackware/slackware64-current/slackware64/d/${checkfile} -P ${extra_location} fi checkfile="librsync-0.9.7-x86_64-1_SBo.tgz" if [ ! -f ${extra_location}/${checkfile} ] then wget https://github.com/That-Dude/rdiff-bacup-unraid/raw/main/${checkfile} -P ${extra_location} fi # install packages upgradepkg --install-new ${extra_location}/python3-3.9.15-x86_64-1.txz upgradepkg --install-new ${extra_location}/python-pip-22.2.2-x86_64-1.txz upgradepkg --install-new ${extra_location}/binutils-2.39-x86_64-1.txz upgradepkg --install-new ${extra_location}/gcc-12.2.0-x86_64-1.txz upgradepkg --install-new ${extra_location}/glibc-2.36-x86_64-3.txz upgradepkg --install-new ${extra_location}/kernel-headers-5.19.17-x86-1.txz upgradepkg --install-new ${extra_location}/librsync-0.9.7-x86_64-1_SBo.tgz pip install rdiff-backup
-
This plugin is super useful but man do I wish someone would make a video describing the ins and outs, benefits and pitfalls.
-
Unfortunately the failed drive (cache drive 1) seems to have a physically failed and has disappeared from the system again. The remaining drive has the 'bad superblock' error and none of the safe (or unsafe) recovery methods mentioned in your (excellent) btrfs thread work. It won't mount at all. I have backups, they are just a few days out of date. I'll create a new 1 drive cache pool and restore to the working drive. I'm disappointed that BTRFS dropped the ball here, a RAID1 configuration should be able to sustain a 1 disk failure without catastrophic results. 🤷♂️
-
A physical power cycle has made the drive visible again on the system but it's now an unassigned device, and not in the 2 disk cache pool. When I add it back to pool, unRAID tells me that the drive will be formatted when I start the array. Is there a way to add it back in correctly?
-
The SSD that went offline? Yes it's physically still installed in the server, I've not disconnected anything. It seems odd that one would physically fail and the other would sustain virtual damage in the same event.
-
Hi @JorgeB please see attached. I've not touched the failed drives but I have restored a backup of a VM onto the main array as it's critical for my work. unga-diagnostics-20220906-1331.zip
-
Hi I had two drives pooled to create a BTRFS (RAID1) cache, but overnight one of them has failed and gone offline. The second drive is still present and has a green ball, but shows an unmountable file system unRIAD wants me to format it. How can I recover from this situation? I assumed that in the case of a drive failure the pool would just keep running and alert me to replace the failed disk.
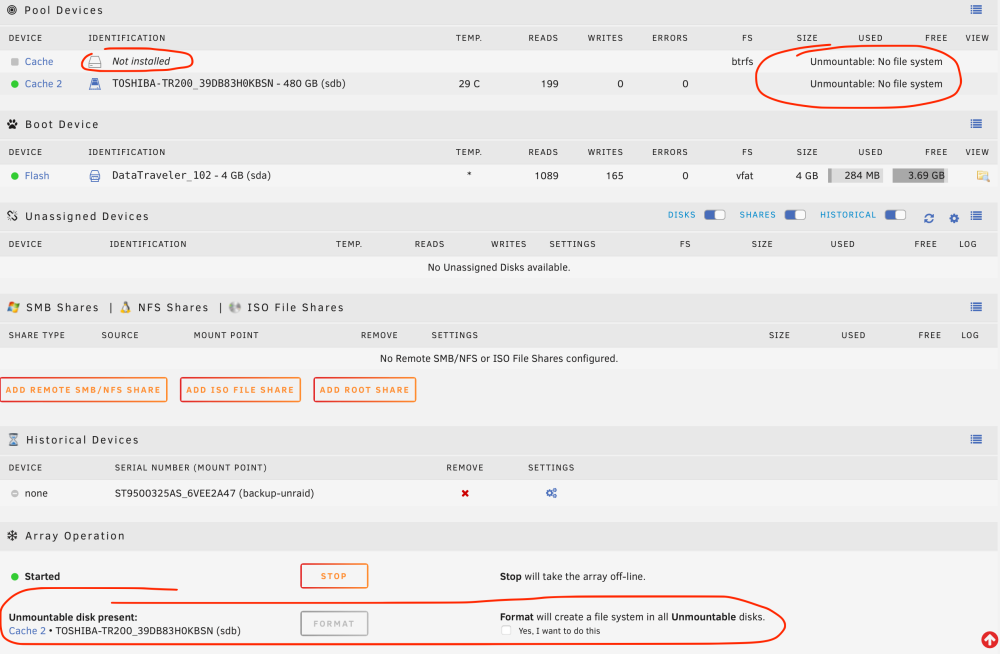
-
OK that's a terrifying procedure 🙂 It's copying the parity to the new drive now. Thank you JorgeB
-
I have an array entirely made up of 6TB drives. A data drive fails. It was with warranty so I had it replaced, BUT WD sent me a larger drive (8TB). I stop my array. Put in the new drive. And I receive the error that "Disk in parity slot is not biggest" - and I am unable to rebuild my array. What's the correct procedure in this scenario?
-
Hopefully it's fixed! I found that mine would work for a couple of days before dropping out, requiring either a physical cable reset on the server or a switch reboot. This only happened on unRIAD, my Windows boxes have been solid for months.





