




harshl
Members
-
Joined
-
Last visited
-
If I'm understanding correctly, you would like to stop accepting key based authentication from the existing keys and then beginning accepting key based authentication again from a set of new keys? If that is the case, just modify your authorized_keys file. Delete the keys that you don't want to be able to authenticate and add the new keys that you do want to be able to authenticate with. Your authorized_keys file should be found here: /boot/config/ssh/root/authorized_keys
-
For what its worth, I ended up going a different direction. I am using an exporter plugin for unraid that Prometheus (separate container) gathers data from and Grafana (speparate container) pulls data from Prometheus. For me this is a much better solution. Particularly since the Grafans version in this container is ancient. It is version 7 while current is 11. I couldn't even export other dashboards from my 11 system into this one, so I moved away from it entirely. Have a look here for more info: https://unraid.net/blog/prometheus
-
@EDACerton Any thoughts on this? I don't know if you were involved in writing this or not, just saw your sticky post and thought I would see if you had any thoughts?
-
Hey all! I have been using Tailscale on my containers with little to no issues at all until this most recent deployment. It is a container with no stateful disk mapped to the container itself. That being the case, I opened up the advanced Tailscale options and used the setting "Tailscale State Directory:" to define a place for it to create the persistent files for Tailscale (/mnt/cache/appdata/container-name/). My question is first of all, am I using that correctly and is that what it is for? I ask this question, because despite having supplied that path, which does exist and is owned by nobody:users with 777 permissions, no files have been written to that directory. Every time I upgrade or make a change to, and restart the container, I have to re-authenticate Tailscale, delete the old node from the Tailscale console and rename the new one to the proper name without a -1 since it was duplicated. Is there a bug in this feature, or am I using it wrong? I imagine it probably isn't used all that much within the Unraid user base. Thanks for any pointers!
-
I'm experiencing a similar issue. Posted this on the GitHub thread: I'm experiencing a similar issue. Unraid 7.0.1 Clean install of UUD from Apps Host Networking with privileged mode enabled Nothing in the dashboard at all. Influx refusing connections.
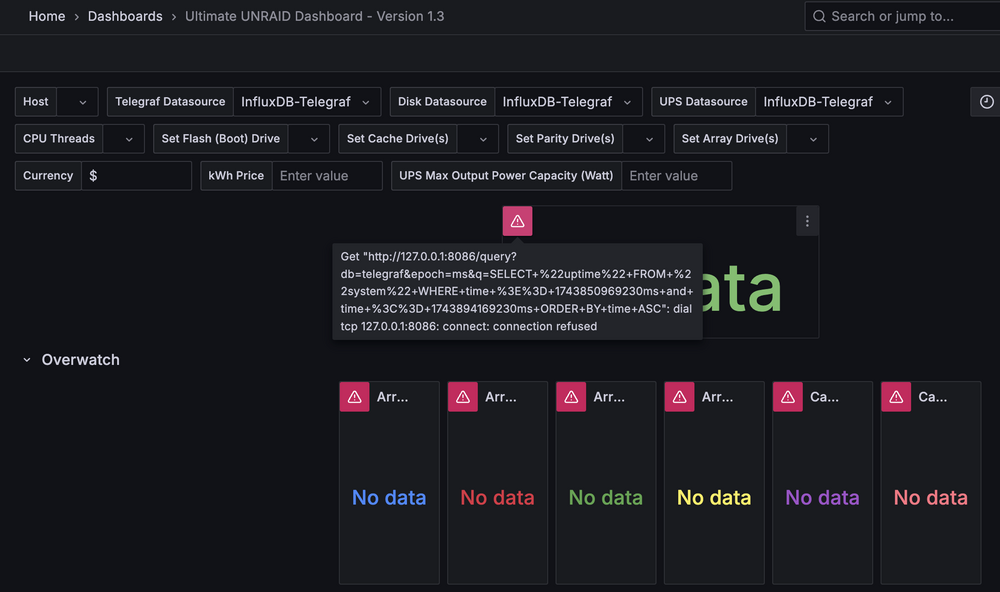
-
Did you ever find an answer to this or find another way to do it? I too am looking to keep metrics longer in Prometheus on Unraid and am curious what you ended up doing long term? Thank you for any guidance you can provide.
-
I am creating snapshots of several of my VMs then copying them to other storage then deleting the snapshot. Seems to be working great other than the snaps I take on the CLI are not reflected in the GUI. I have booted the VM from the copied disk and it seems to boot up just fine. 🤷♂️ Here is how I am taking the snapshot: # 2. Create snapshot echo "Creating snapshot $SNAPSHOT_NAME..." virsh snapshot-create-as --domain "$VM_NAME" "$SNAPSHOT_NAME" --disk-only --atomic --diskspec "hdc,snapshot=external" --diskspec "hdd,snapshot=no" check_status "Snapshot creation" I stumbled onto this post while searching for why my snapshots don't appear in the GUI, which I suppose is mostly answered in the post above.
-
Confirmed. I am seeing now that after rebooting to replace the controller in the server, none of the drives are spinning down anymore, as configured. Thanks!
-
Just to close the loop on this, the issue was either with the cable or the controller, not sure which as I replaced them at the same time. I did not replace the backplane or anything else in the mix. Thanks for the technical and moral support!
-
Thank you so much!
-
Sorry, I stated in the text what I was doing, but the screenshot shows something different. Sorry for the confusion. It is doing exactly what it has been configured to do. As a troubleshooting step, I wanted to disable spin down. I'm pretty convinced now that it has nothing to do with the issue, but regardless, I don't want this pool to spin down. I have set the first disk not to, but the remaining two disks still spin down and don't have a setting in the GUI I can find to set them not to. It is currently behaving exactly as configured from my perspective. Would you like me to submit a bug somewhere about it either not obeying the config of the first drive, or, the setting missing on subsequent drives? Thanks!
-
FYI, the pool is not obeying the setting from the first disk. Is there a way to set it on the other two disks so they are in sync?
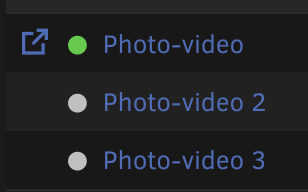
-
As a troubleshooting step, I would like to disable spin down for this zpool. It has the following drives present: If I click on the first drive I see the option to change spin down: However, when I click on the other two disks, they do not have that option: Will the other disks follow the setting of the 1st disk, or is there somewhere else that I need to set this? Thank you!
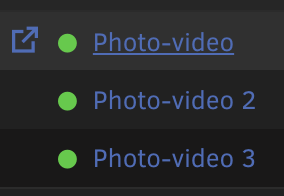
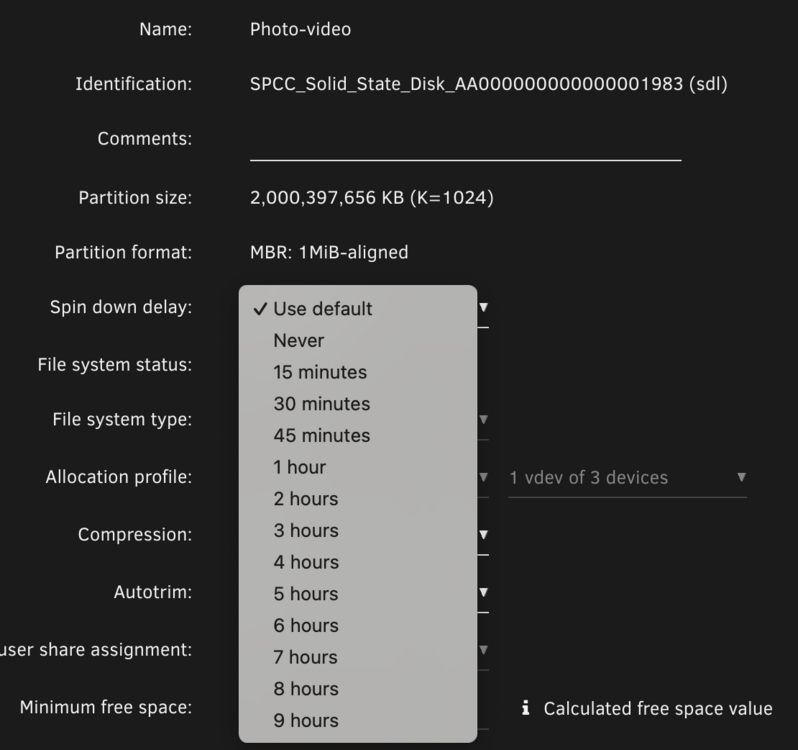
-
JorgeB, thank you for the responses and insight. The server came back up and the zpool mounted fine. I have copied the data off to two other locations and will continue troubleshooting the failure. Nice to have a friendly community to lean on when you get into these situations. Thanks again!
-
I tried rebooting it well over an hour ago and it hasn't gone down. Something has it hung. I guess I'll force power it off and maybe replace the HBA and cables?





