leeknight1981
Members
-
Joined
-
Last visited
Everything posted by leeknight1981
-
i had a update today (2021.03.17) to nvidia and the server was rebooted but the screen GUI still doesn't work. Ill head over to them guys its not major but its useful TIA L33
-
6.9.1 i am now unable to use the GUI on Screen! Server's are up and running but screen is totally black, Signal is being received but nothing. I am able to log into the 2 but the other 2 i am trying to set up its going to be a pain in the arse or i have to set ip on flash. Is there a reason for it? Prior to 6.9.1 i was running the final beta and it worked ok so its since Stable iv noticed. We have the screens on most of the time its not a must but easier for the lads to monitor Any ideas TIA L33
-
Hi Guys i cant seem to find a definitive answer will the Dell 165T0 Broadcom 57800S Quad Port Network Card work with UnRAID? OR would the Mellanox MNPA19-XTR be a better choice? Ideally id like an on board card TIA L33
-
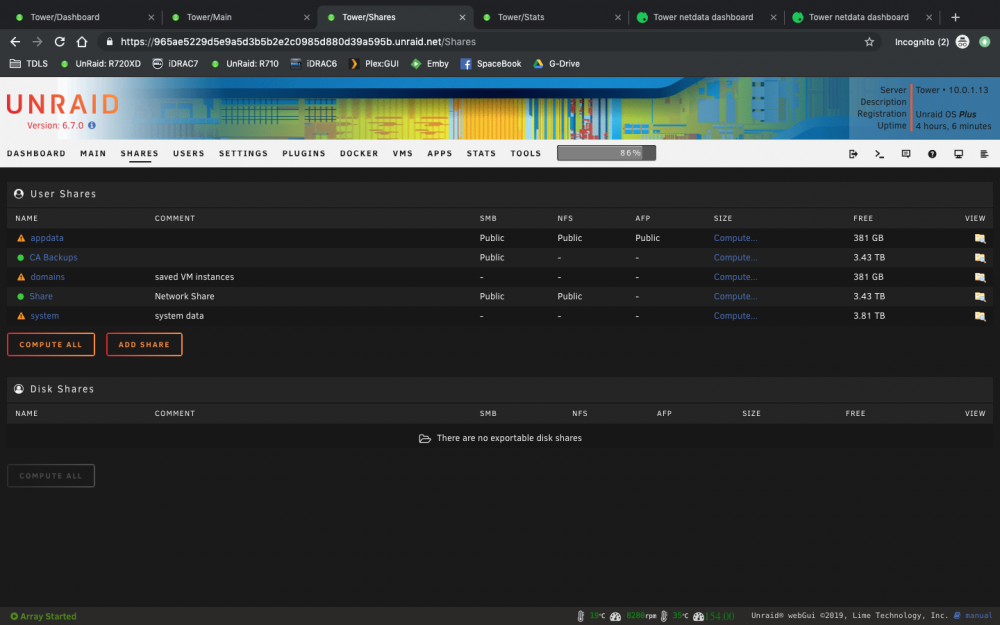
Hi Guy's Can someone have a look at the screen dump iv added!? CA Backup Share Size 3.43 TB and the other share's Do they need to be that size? can they be made smaller. Do they need to be that size? Have had UnRaid for some time but my mate set it up for me a few years back! iv Since Upgraded to a Dell R720 XD with 2 x CPU E5-2667 v2 @ 3.30GHz, 64GB DDR3 1.3v 1333Mhz, and 2 x 8TB parity with 6 x 4TB data. I got it for next to Nothing Anyways iv set everything else up and am just unsure if the Share's / CA Backup should be that size and or if it can be changed. PS i do weekly CA Backup i then Zip them and upload them to G-Drive after 4 weeks i delete the previous 4 backups TIA L33
-
Hi Guy's after having a few issues I just need some clarification, All my docker containers are stored on an SSD / the cache drive like this /mnt/user/appdata/letsencrypt/ /mnt/user/appdata/organizr/ CA Backups is set to /mnt/user/CA Backups/appdatabackup /mnt/user/CA Backups/flashdrivevbackup/ /mnt/user/CA Backups/libvirt backup/ So unless I am wrong the backup is backed up to the SSD / Cache? So if said SSD / cache was to fail / die id be FUBAR and lose all my dockers etc so do I manually move the backups or do I set them to a folder on the share / array TIA please forgive my terminology its been a really long 2 days and I haven't the time to investigate Regards L33
-
Out of curiosity i created another Music library and called it Music - MP3 i pointed it to an empty folder in Plex folder, I then tried to delete said library but it will not delete the same as the normal one. Nothing in the folder at all was a brand new folder. So i now have Music and Music - MP3 library's that i am unable to remove from the sidebar! The Plex dev's can be arrogant bastards at times so i don't wanna go to them unless i Really have to. Anyone have any ideas on this before i F&CK Plex off for Emby. TIA L33
-
Awesome I am away for the bank holiday weekend so I’ll check when I get back, I know the last folder I dropped before the issue was Genesis and the time before it was Genesis so I’ll have to go threw all of them! If left it would plex sort it or will it just keep stalling many thanks who do I buy a burgundy XD
-
Haha indeed I am basically moving my iTunes library 1 artist at a time to Plex, it goes fine but then just stops. Going to leave it scanning for a day and see what happens if anything. PS its a 1.3TB music library hence doing it 1 artist at a time TIA L33
-
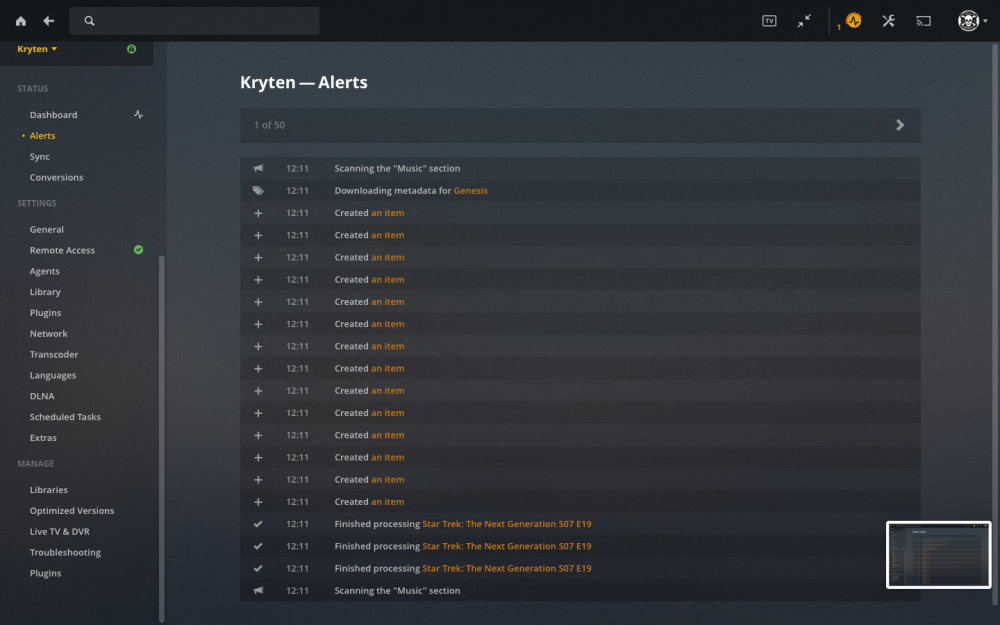
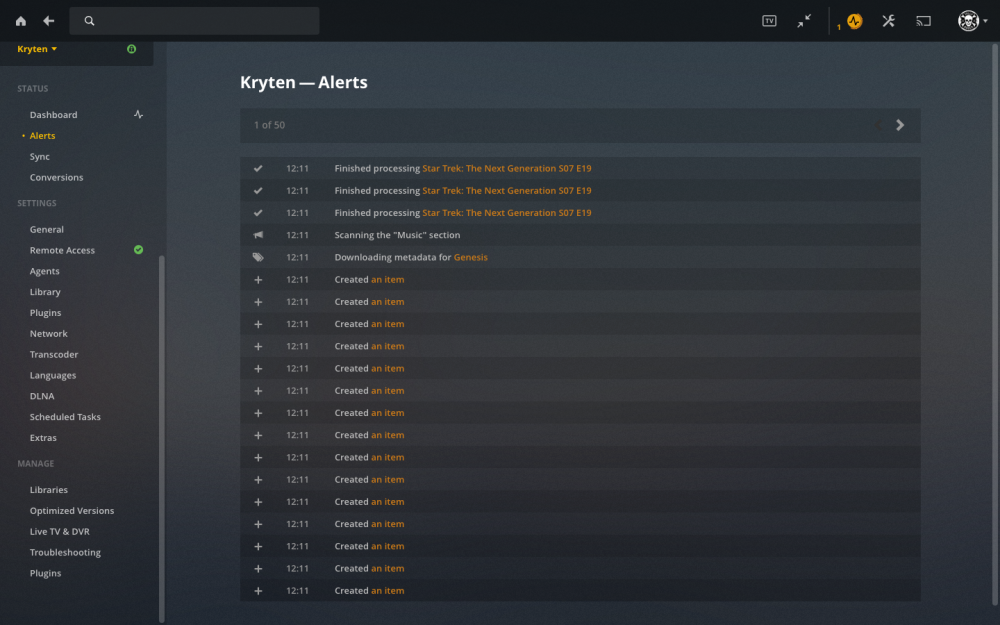
OK the problem has started again the library is u and running and the media has been scanned and plays ok, The mover has completed moving the media to the array. I have just added another folder but it has not picked it up So i added another and the same its only scanning the media thats already in the library Nothing New. I know these two albums work as i had them in the previous library. i have stopped the container and Scanned library files, Optimised the database and cleaned the bundles. Stopped and Started the docker and then dropped another album into the music folder but it doesn't put the Artis nor Album in the library. Says added item. from docker log if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:13:26,008 DEBG 'plexmediaserver' stderr output: GUI: Requesting metadata for '...And Then There Were Three...' 2019-05-03 04:13:28,060 DEBG 'plexmediaserver' stderr output: GUI: Requesting metadata for 'A Trick Of The Tail' 2019-05-03 04:13:28,161 DEBG 'plexmediaserver' stderr output: GUI: Requesting metadata for 'Abacab' 2019-05-03 04:13:28,221 DEBG 'plexmediaserver' stderr output: GUI: Requesting metadata for 'Calling All Stations' 2019-05-03 04:13:28,290 DEBG 'plexmediaserver' stderr output: GUI: Requesting metadata for 'Duke' 2019-05-03 04:13:28,313 DEBG 'plexmediaserver' stderr output: GUI: Requesting metadata for 'Foxtrot' 2019-05-03 04:13:28,364 DEBG 'plexmediaserver' stderr output: GUI: Requesting metadata for 'From Genesis To Revelation' 2019-05-03 04:13:28,373 DEBG 'plexmediaserver' stderr output: GUI: Requesting metadata for 'Genesis' 2019-05-03 04:13:28,384 DEBG 'plexmediaserver' stderr output: GUI: Requesting metadata for 'Genesis Live' 2019-05-03 04:13:28,398 DEBG 'plexmediaserver' stderr output: GUI: Requesting metadata for 'Seconds Out' 2019-05-03 04:13:36,289 DEBG 'plexmediaserver' stderr output: __code__:487: FutureWarning: The behavior of this method will change in future versions. Use specific 'len(elem)' or 'elem is not None' test instead. 2019-05-03 04:13:36,670 DEBG 'plexmediaserver' stderr output: __code__:500: FutureWarning: The behavior of this method will change in future versions. Use specific 'len(elem)' or 'elem is not None' test instead. 2019-05-03 04:13:44,057 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit 2019-05-03 04:13:44,057 DEBG 'plexmediaserver' stderr output: if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format 2019-05-03 04:13:44,057 DEBG 'plexmediaserver' stderr output: return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format 2019-05-03 04:13:44,057 DEBG 'plexmediaserver' stderr output: record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:13:44,060 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit 2019-05-03 04:13:44,060 DEBG 'plexmediaserver' stderr output: if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:13:44,063 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit if self.shouldRollover(record): 2019-05-03 04:13:44,063 DEBG 'plexmediaserver' stderr output: File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:13:44,067 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit 2019-05-03 04:13:44,067 DEBG 'plexmediaserver' stderr output: if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:13:44,070 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit 2019-05-03 04:13:44,070 DEBG 'plexmediaserver' stderr output: if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:13:44,073 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit 2019-05-03 04:13:44,073 DEBG 'plexmediaserver' stderr output: if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:13:44,077 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit 2019-05-03 04:13:44,077 DEBG 'plexmediaserver' stderr output: if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:13:44,079 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit if self.shouldRollover(record): 2019-05-03 04:13:44,080 DEBG 'plexmediaserver' stderr output: File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:13:44,082 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit 2019-05-03 04:13:44,082 DEBG 'plexmediaserver' stderr output: if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:13:44,084 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit 2019-05-03 04:13:44,085 DEBG 'plexmediaserver' stderr output: if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:13:44,088 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit 2019-05-03 04:13:44,088 DEBG 'plexmediaserver' stderr output: if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:14:02,161 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover 2019-05-03 04:14:02,161 DEBG 'plexmediaserver' stderr output: msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:14:02,164 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit if self.shouldRollover(record): 2019-05-03 04:14:02,164 DEBG 'plexmediaserver' stderr output: File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:14:02,167 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit 2019-05-03 04:14:02,167 DEBG 'plexmediaserver' stderr output: if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:14:02,170 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit 2019-05-03 04:14:02,170 DEBG 'plexmediaserver' stderr output: if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:14:02,173 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit 2019-05-03 04:14:02,173 DEBG 'plexmediaserver' stderr output: if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:14:02,176 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit 2019-05-03 04:14:02,176 DEBG 'plexmediaserver' stderr output: if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:14:02,179 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit 2019-05-03 04:14:02,179 DEBG 'plexmediaserver' stderr output: if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:14:02,181 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit 2019-05-03 04:14:02,181 DEBG 'plexmediaserver' stderr output: if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 2019-05-03 04:14:02,184 DEBG 'plexmediaserver' stderr output: Traceback (most recent call last): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 76, in emit 2019-05-03 04:14:02,184 DEBG 'plexmediaserver' stderr output: if self.shouldRollover(record): File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/handlers.py", line 156, in shouldRollover msg = "%s\n" % self.format(record) File "/usr/lib/plexmediaserver/Resources/Python/lib/python2.7/logging/__init__.py", line 734, in format return fmt.format(record) File "/usr/lib/plexmediaserver/Resources/Plug-ins-4610c6e8d/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/core.py", line 77, in format record.__dict__[key] = uni(record.__dict__[key]) UnicodeDecodeError: 'utf8' codec can't decode byte 0xa9 in position 18: invalid start byte Logged from file audiohelpers.py, line 248 It was working fine its added some media ok but now its just stopped adding newly added albums Can anyone shed any light on this PLEASE for my Sanity Regards L33 Plex Media Server Logs_2019-04-30_13-34-33.zip
-
OK I have restored my CA backup all is ok, I have now Added Music and pointed it to the folder Music in Plex and it is now scanning. This is the exact process I did but I added the artists one at a time instead of all at once. I have taken logs as soon as Plex loaded and ill take them again if it does the same again. I shall keep you Posted
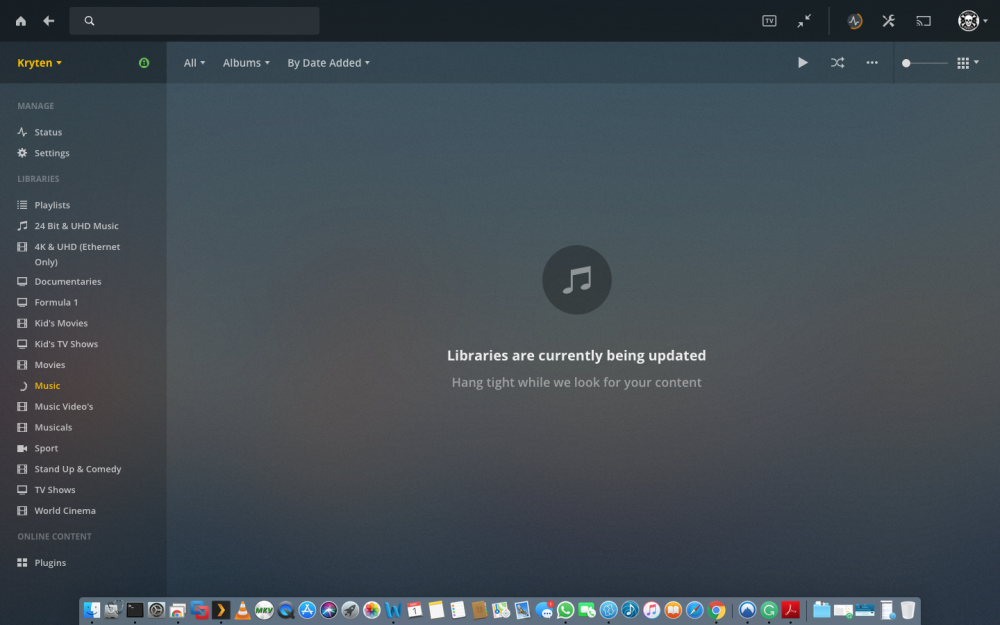
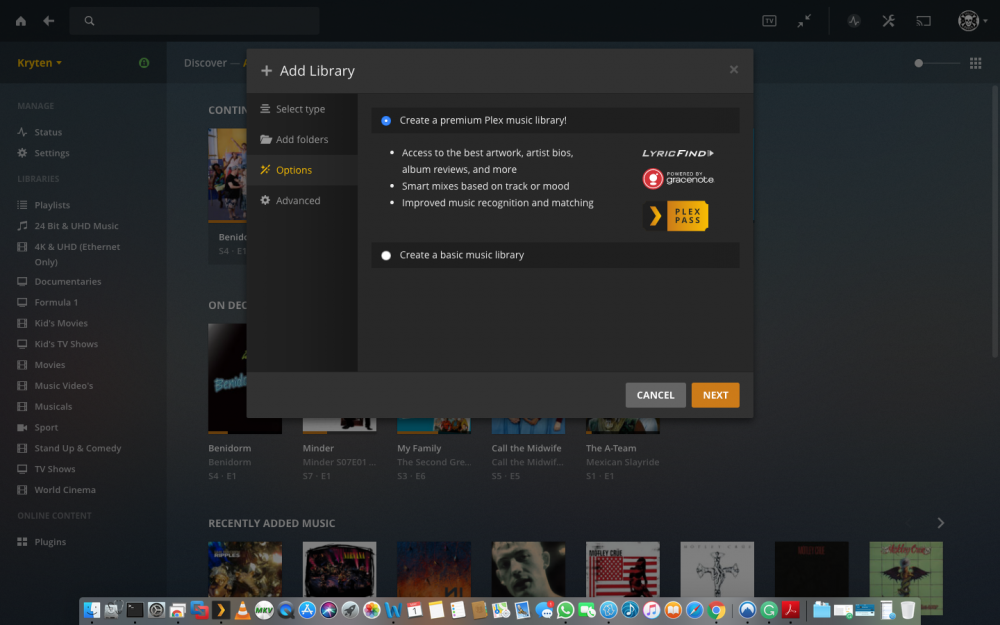
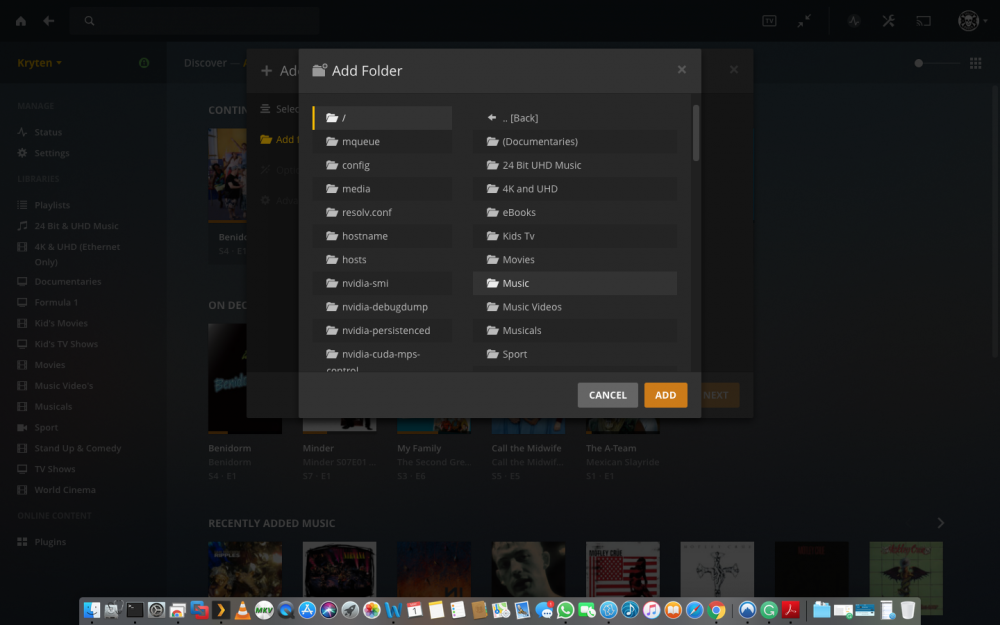
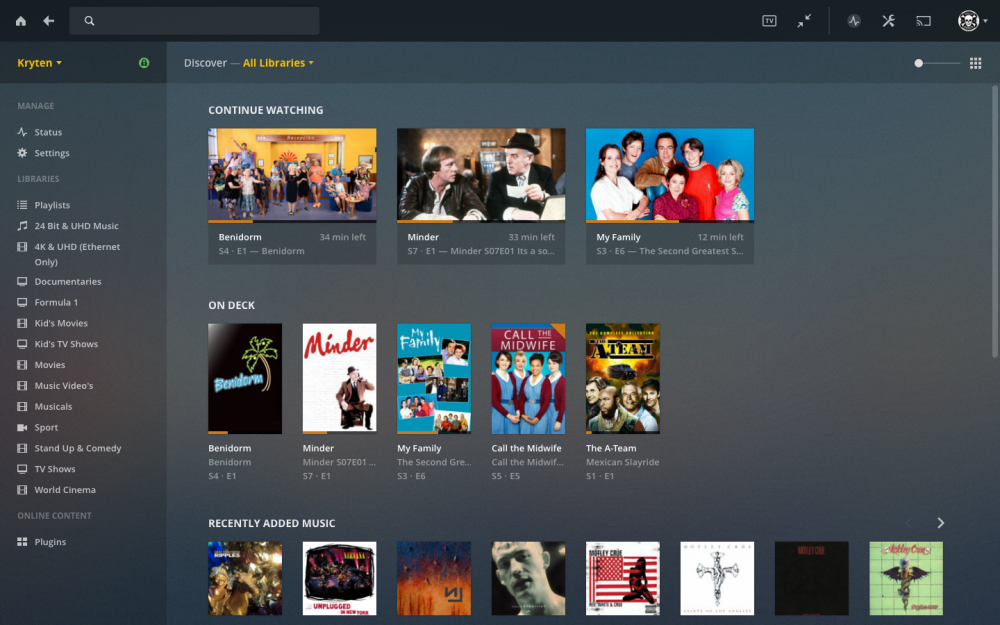 Is it possible that this is an issue with RC7? i have a CA backup that i am currently restoring it was created Sunday before i added the Music library. Once restored and all up and running i am going to Create a New library in plex Music, and point it to /mnt/user/Share/Array Share/Plex/ in there i have all my plex folders Ill pop a screen dump below TIA L33
Is it possible that this is an issue with RC7? i have a CA backup that i am currently restoring it was created Sunday before i added the Music library. Once restored and all up and running i am going to Create a New library in plex Music, and point it to /mnt/user/Share/Array Share/Plex/ in there i have all my plex folders Ill pop a screen dump below TIA L33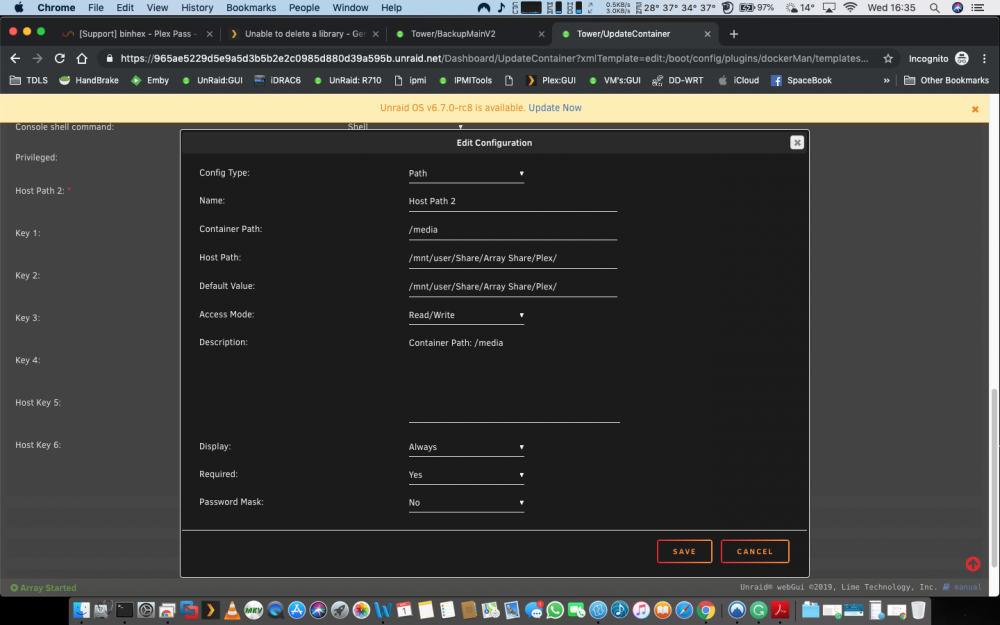
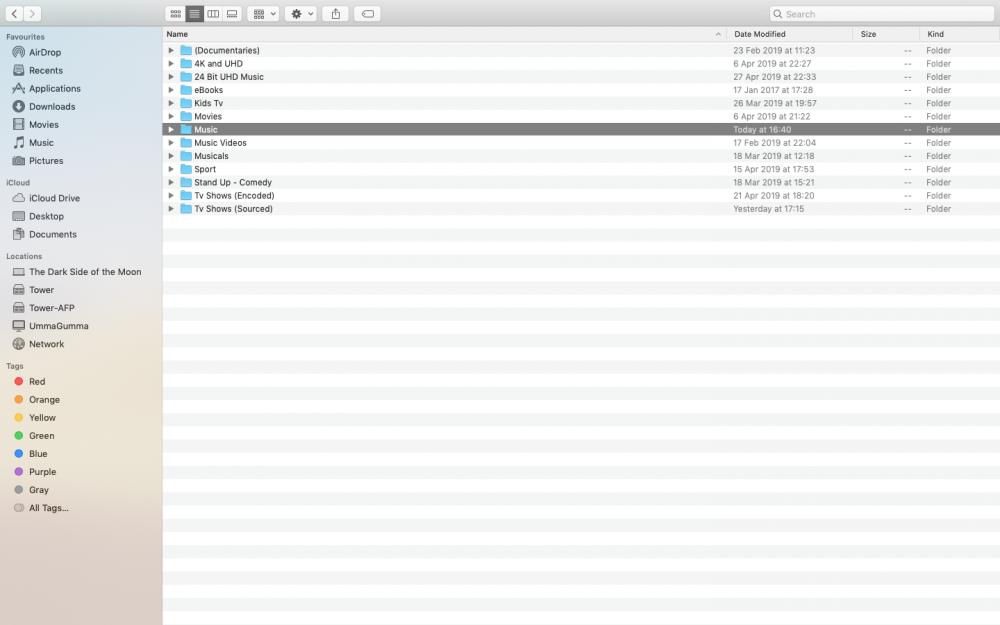 Hi of course there attached, Only had this issue since adding Music many thanks L33
Hi of course there attached, Only had this issue since adding Music many thanks L33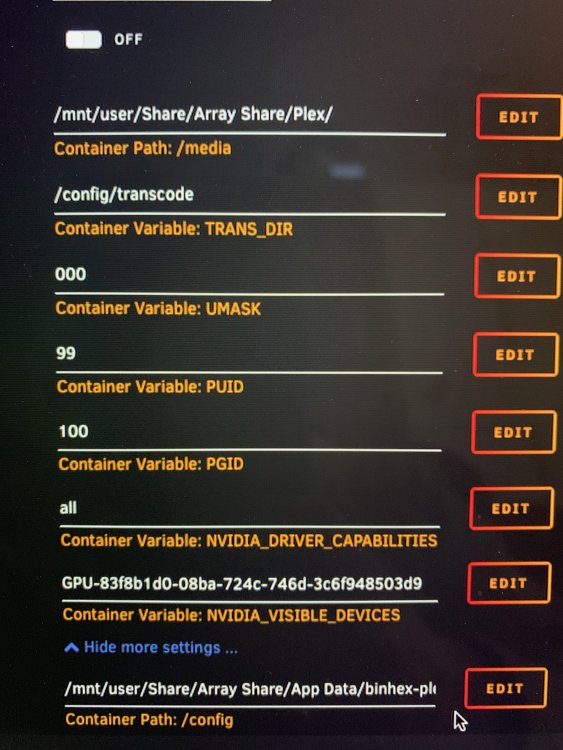
 Hi Bud Yeah i copied the media from my iMac so if it goes it goes but i have many backups, Like i say i have moved the Music folder out of plex folder iv refreshed the library etc But the albums remain but with no files. I have tried to delete the Library Music but it just wont go. have a look at the screen dumps ... Delete Library, Tick box clicked delete All still there after refreshing I hate not understanding whats going wrong and the web has been no help So i thought i would try your expertise Many Thanks . Lee
Hi Bud Yeah i copied the media from my iMac so if it goes it goes but i have many backups, Like i say i have moved the Music folder out of plex folder iv refreshed the library etc But the albums remain but with no files. I have tried to delete the Library Music but it just wont go. have a look at the screen dumps ... Delete Library, Tick box clicked delete All still there after refreshing I hate not understanding whats going wrong and the web has been no help So i thought i would try your expertise Many Thanks . Lee
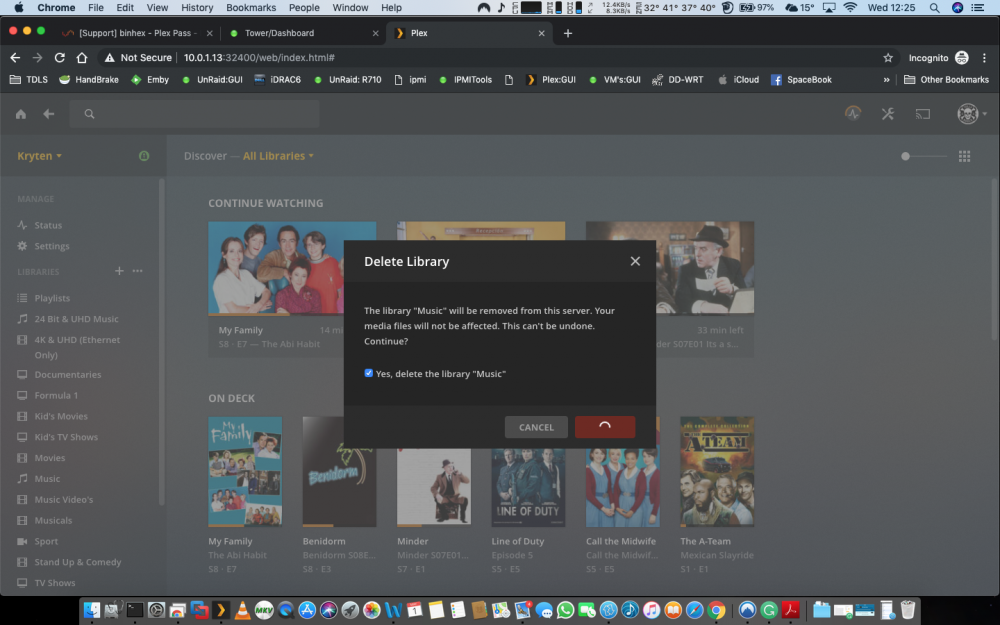
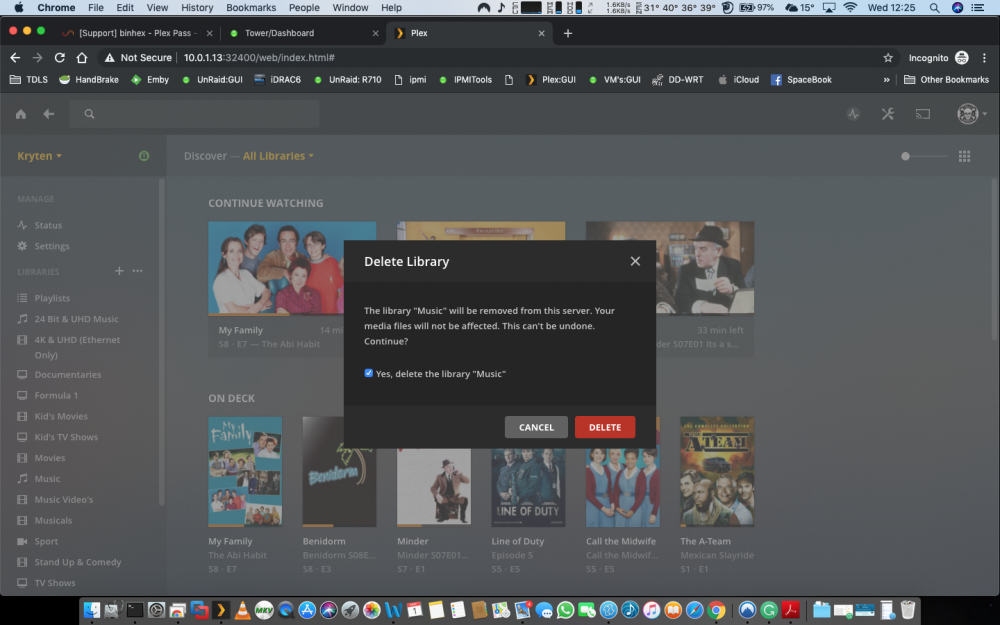
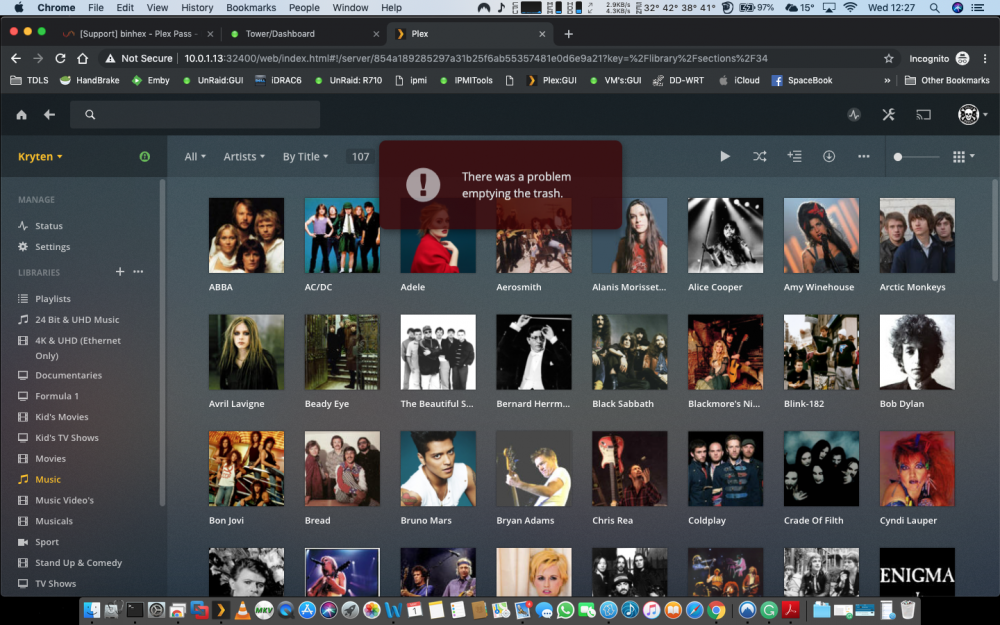 I have moved the folder Music out of the Plex folder and re scanned all the albums are still there but says files are missing, i click delete library Music i get the check box i tick it and click delete but nothing happens. Iv re started the plex docker and re started the array Regards LeeHI i really need some Help! I recently added a new library Music! i have been adding music from my iTunes. Most items have scanned and work ok but iv added Liam Gallagher its the same as all my other files .mp3 and works fine elsewhere iv added all of led zep also but when i click scan library files it circle spins for about 5 seconds and stops. I have tried to delete the library but it remains, i am unable to empty the trash also. i have attached log's etc. It just randomly stopped scanning newly added folders. I know these files are all ok as used them on Plex previously Please any help would be much appreciated. Plex Media Server Logs_2019-04-30_14-26-56.zipHi really need some help I have the latest docker plex-pass I added a new library Music, No problems slowly started adding media and it works amazingly but as I add more it doesn't pick up the new files. I have deleted said Music library but it's still there So I moved the entire folder out of the Plex folder deleted again But still there. Iv shut the array down rebooted the Server Still there Optimised database, Cleared bundles but now it won't empty trash... I have attached logs. why won't the deleted library Go? this is the 3rd time iv tried adding a music library all the Music is OK as its from iTunes and all is correct iv checked. Is this an Unraid issue, Plex issue or Docker Regards Lee Plex Media Server Logs_2019-04-30_10-58-20.zipHi just updated the docker but i still have 0mbps as Bandwidth, Local & Remote in Plex desktop and Web GUI, I know there maybe far more important things to fix but this would be helpful. TIA L33
I have moved the folder Music out of the Plex folder and re scanned all the albums are still there but says files are missing, i click delete library Music i get the check box i tick it and click delete but nothing happens. Iv re started the plex docker and re started the array Regards LeeHI i really need some Help! I recently added a new library Music! i have been adding music from my iTunes. Most items have scanned and work ok but iv added Liam Gallagher its the same as all my other files .mp3 and works fine elsewhere iv added all of led zep also but when i click scan library files it circle spins for about 5 seconds and stops. I have tried to delete the library but it remains, i am unable to empty the trash also. i have attached log's etc. It just randomly stopped scanning newly added folders. I know these files are all ok as used them on Plex previously Please any help would be much appreciated. Plex Media Server Logs_2019-04-30_14-26-56.zipHi really need some help I have the latest docker plex-pass I added a new library Music, No problems slowly started adding media and it works amazingly but as I add more it doesn't pick up the new files. I have deleted said Music library but it's still there So I moved the entire folder out of the Plex folder deleted again But still there. Iv shut the array down rebooted the Server Still there Optimised database, Cleared bundles but now it won't empty trash... I have attached logs. why won't the deleted library Go? this is the 3rd time iv tried adding a music library all the Music is OK as its from iTunes and all is correct iv checked. Is this an Unraid issue, Plex issue or Docker Regards Lee Plex Media Server Logs_2019-04-30_10-58-20.zipHi just updated the docker but i still have 0mbps as Bandwidth, Local & Remote in Plex desktop and Web GUI, I know there maybe far more important things to fix but this would be helpful. TIA L33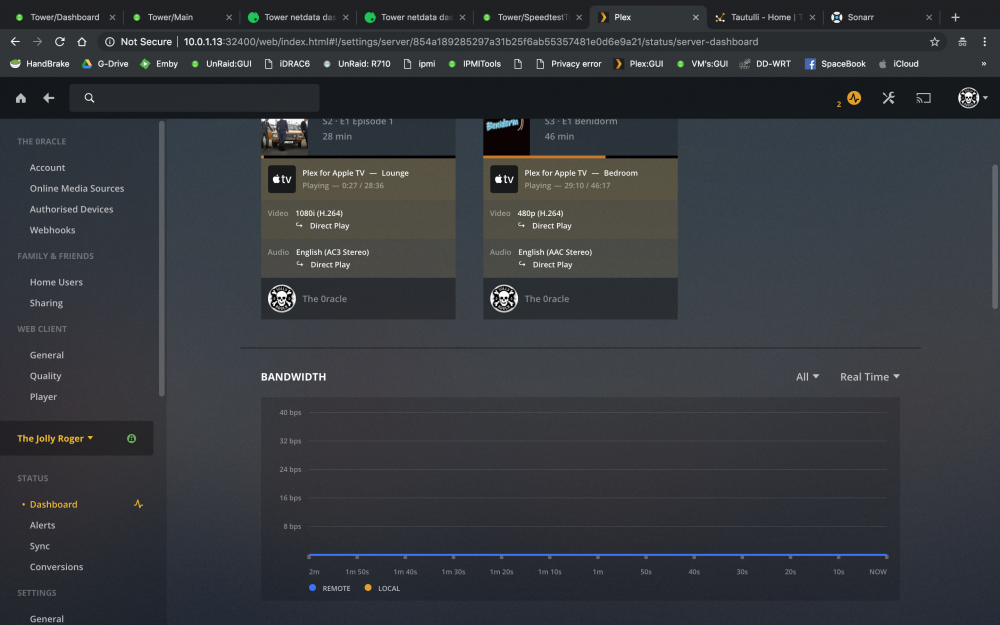
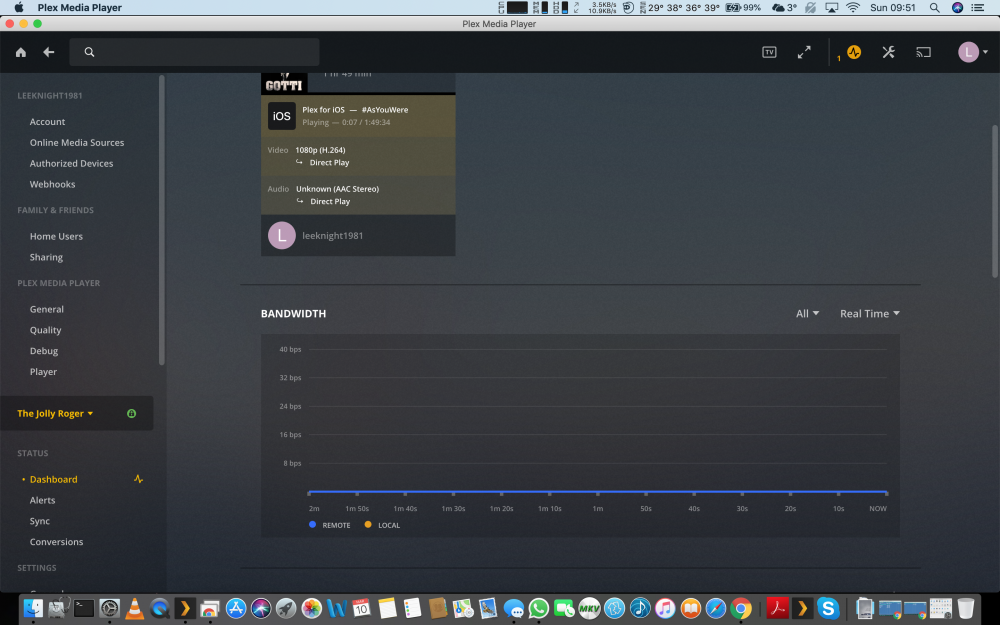
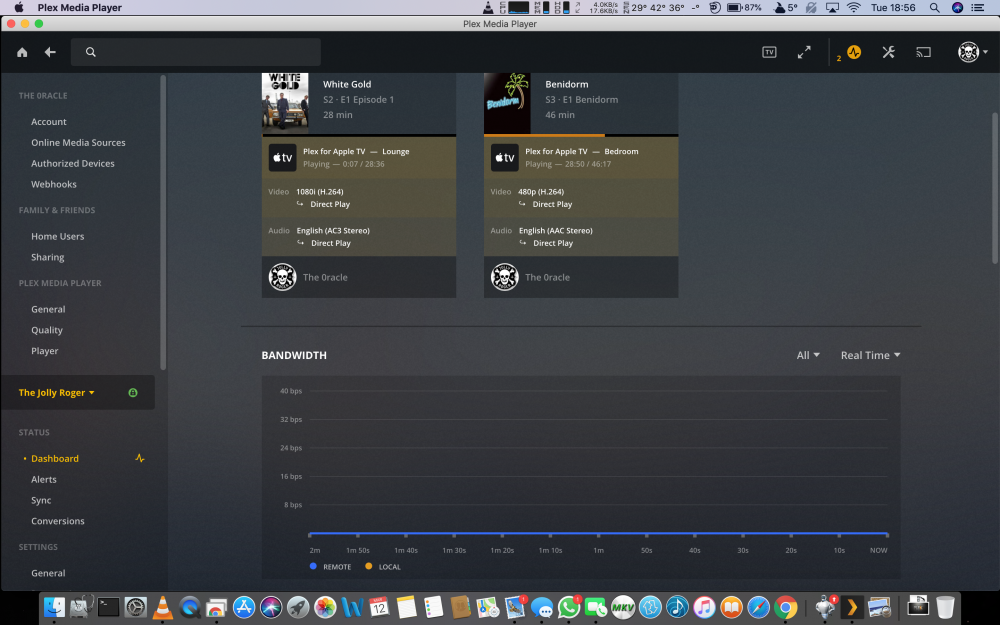 Hi Running the latest binhex/arch-plexpass but i am unable to see bandwidth usage local and remote says 0 Is there a fault? TIA L33
Hi Running the latest binhex/arch-plexpass but i am unable to see bandwidth usage local and remote says 0 Is there a fault? TIA L33