




loz678
Members
-
Joined
-
Last visited
Everything posted by loz678
-
disabling fast boot solved inconsistent boot problems on my asus prime h510m-k
-
the hardware problem appears to be an m.2 drive i'd added as a cache drive. Now that it's removed the machine is stable again
-
I'm still getting crashes every couple of days. So far I've replaced the motherboard, cpu and RAM so it doesn't seem related to that. Googling for "rcu: INFO: rcu_preempt self-detected stall on CPU" suggests there might be a problem with a docker container or a hardware problem with one of my cache drives. Does that sound likely? unraid.log
-
ok thanks, i've removed the connect plug in, some other errors now: ec 21 13:12:20 Tower kernel: unraid-api[9542]: segfault at 8 ip 00001543e6b7980c sp 00007fff870e60c0 error 4 in ld-2.37.so[1543e6b5c000+27000] likely on CPU 4 (core 4, socket 0) Dec 21 13:12:20 Tower kernel: Code: 84 7a 06 00 00 48 85 c0 75 e4 48 83 3d 14 67 01 00 00 0f 85 8b 06 00 00 48 8b bd 98 fd ff ff 48 8b 57 68 48 8b 87 80 02 00 00 <48> 8b 5a 08 f6 87 36 03 00 00 20 0f 84 2f 06 00 00 48 03 1f 48 85 Dec 21 13:12:20 Tower kernel: unraid-api[9545]: segfault at 8 ip 0000145c72f2780c sp 00007ffdd1b1f940 error 4 in ld-2.37.so[145c72f0a000+27000] likely on CPU 8 (core 2, socket 0) Dec 21 13:12:20 Tower kernel: Code: 84 7a 06 00 00 48 85 c0 75 e4 48 83 3d 14 67 01 00 00 0f 85 8b 06 00 00 48 8b bd 98 fd ff ff 48 8b 57 68 48 8b 87 80 02 00 00 <48> 8b 5a 08 f6 87 36 03 00 00 20 0f 84 2f 06 00 00 48 03 1f 48 85 Dec 21 13:12:21 Tower root: plugin: running: anonymous Dec 21 13:12:21 Tower root: plugin: dynamix.unraid.net.plg removed Dec 21 13:12:22 Tower nginx: 2024/12/21 13:12:22 [error] 9416#9416: *342981 FastCGI sent in stderr: "Unable to open primary script: /usr/local/emhttp/plugins/dynamix.my.servers/include/unraid-api.php (No such file or directory)" while reading response header from upstream, client: 192.168.2.12, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "tower", referrer: "http://tower/Plugins" Dec 21 13:12:27 Tower nginx: 2024/12/21 13:12:27 [error] 9416#9416: *342986 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.2.12, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "tower", referrer: "http://tower/Plugins" Dec 21 13:12:33 Tower nginx: 2024/12/21 13:12:33 [error] 9416#9416: *342986 FastCGI sent in stderr: "Unable to open primary script: /usr/local/emhttp/plugins/dynamix.my.servers/include/unraid-api.php (No such file or directory)" while reading response header from upstream, client: 192.168.2.12, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "tower", referrer: "http://tower/Plugins" Dec 21 13:12:38 Tower nginx: 2024/12/21 13:12:38 [error] 9416#9416: *342986 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.2.12, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "tower", referrer: "http://tower/Plugins" Dec 21 13:12:43 Tower nginx: 2024/12/21 13:12:43 [error] 9416#9416: *342986 FastCGI sent in stderr: "Unable to open primary script: /usr/local/emhttp/plugins/dynamix.my.servers/include/unraid-api.php (No such file or directory)" while reading response header from upstream, client: 192.168.2.12, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "tower", referrer: "http://tower/Plugins" Dec 21 13:12:48 Tower nginx: 2024/12/21 13:12:48 [error] 9416#9416: *342986 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.2.12, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "tower", referrer: "http://tower/Plugins" Dec 21 13:12:53 Tower nginx: 2024/12/21 13:12:53 [error] 9416#9416: *342986 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.2.12, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "tower", referrer: "http://tower/Plugins" Dec 21 13:12:58 Tower nginx: 2024/12/21 13:12:58 [error] 9416#9416: *342986 FastCGI sent in stderr: "Unable to open primary script: /usr/local/emhttp/plugins/dynamix.my.servers/include/unraid-api.php (No such file or directory)" while reading response header from upstream, client: 192.168.2.12, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "tower", referrer: "http://tower/Plugins" Dec 21 13:13:04 Tower nginx: 2024/12/21 13:13:04 [error] 9416#9416: *342986 FastCGI sent in stderr: "Unable to open primary script: /usr/local/emhttp/plugins/dynamix.my.servers/include/unraid-api.php (No such file or directory)" while reading response header from upstream, client: 192.168.2.12, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "tower", referrer: "http://tower/Plugins" Dec 21 13:13:09 Tower nginx: 2024/12/21 13:13:09 [error] 9416#9416: *342986 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.2.12, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "tower", referrer: "http://tower/Plugins" Dec 21 13:13:15 Tower nginx: 2024/12/21 13:13:15 [error] 9416#9416: *342986 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.2.12, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "tower", referrer: "http://tower/Plugins" Dec 21 13:13:21 Tower nginx: 2024/12/21 13:13:21 [error] 9416#9416: *342986 FastCGI sent in stderr: "Unable to open primary script: /usr/local/emhttp/plugins/dynamix.my.servers/include/unraid-api.php (No such file or directory)" while reading response header from upstream, client: 192.168.2.12, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "tower", referrer: "http://tower/Plugins" Dec 21 13:13:27 Tower nginx: 2024/12/21 13:13:27 [error] 9416#9416: *342986 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.2.12, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "tower", referrer: "http://tower/Plugins" Dec 21 13:13:33 Tower nginx: 2024/12/21 13:13:33 [error] 9416#9416: *342986 FastCGI sent in stderr: "Unable to open primary script: /usr/local/emhttp/plugins/dynamix.my.servers/include/unraid-api.php (No such file or directory)" while reading response header from upstream, client: 192.168.2.12, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "tower", referrer: "http://tower/Plugins" Dec 21 13:13:39 Tower nginx: 2024/12/21 13:13:39 [error] 9416#9416: *342986 FastCGI sent in stderr: "Unable to open primary script: /usr/local/emhttp/plugins/dynamix.my.servers/include/unraid-api.php (No such file or directory)" while reading response header from upstream, client: 192.168.2.12, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "tower", referrer: "http://tower/Plugins" Dec 21 13:13:45 Tower nginx: 2024/12/21 13:13:45 [error] 9416#9416: *342986 FastCGI sent in stderr: "Unable to open primary script: /usr/local/emhttp/plugins/dynamix.my.servers/include/unraid-api.php (No such file or directory)" while reading response header from upstream, client: 192.168.2.12, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "tower", referrer: "http://tower/Plugins"
-
I'm now getting some read errors and a lot of segfaults. Any ideas? tower-diagnostics-20241221-1017.zip
-
it's just happened again, just after 18:00. "syslog-previous" doesn't seem very useful, is there some other log that might suggest what is happening? tower-diagnostics-20241219-1914.zip syslog-previous syslog
-
no I only realised there was a problem at 04:26 on Dec 19 when I cycled the power. It's possible I ran a docker update at 23:09 on Dec 18 , could be a red herring though
-
Not that I recall
-
For the last month or so my unraid machine has become responsive every few days which I've only been able to resolve via powering off. Looking at "syslog-previous" it looks like an issue occurred at around 23:09 on Dec 18 but my google fu has failed me. Can anyone see what the problem is? syslog tower-diagnostics-20241219-1155.zip syslog-previous
-
version 6.12.6 3 times in the last week I've had unraid become completely unresponsive. The first 2 times I connected a monitor but there was no output. The most recent time it happened the monitor recieved an output , the keyboard didn't work though so I couldn't capture the diagnostics. I took a photo of the messages on the monitor, can anyone make any sense of them? pic attached as well as a diagnostic from after restart. Recently I made 2 hardware changes to the machine 1) replaced an nvme drive that is used as a cache drive 2) replaced 2 sticks of 8gb ddr4 with 2 16gb sticks tower-diagnostics-20241118-0111.zip
.thumb.jpg.ec9022b33573342d334344e91c01e856.jpg)
-
Moments after starting a rebuild of Drive4 (moving from a 4tb drive to 8tb) and Drive1 entered an error state. Would like to understand the cause. diagnostics attached. Hopefuly unrelated but I recently (a few weeks ago) changed from using an LSI controller to an Adaptec ASR-71605 thanks tower-diagnostics-20221027-1423.zip
-
when i start the container: Starting loop.... Checking for new Videos Traceback (most recent call last): File "main.py", line 8, in <module> pytubDef.loop() File "/app/pytubDef/__init__.py", line 202, in loop channelArray = returnMonitoredChannels() File "/app/pytubDef/__init__.py", line 256, in returnMonitoredChannels channelURLs = monitoredChannelsFile.readlines() io.UnsupportedOperation: not readable
-
on my gigabyte z590 board only one stick of RAM was being detected, the tape trick on the H310 solved it
-
as per the screenshots, i've changed the "Destination share" field under backup and the change isn't reflected in the restore tab. Maybe I'm misunderstanding the UI somehow, how exactly is it supposed to be used?
-
indeed, the "Default appdata storage location" is /mnt/user/appdata/ Would it be a good idea to change this for all , or just plex radarr etc?
-
why would this happen? As I said, my appdata isn't on the array and i'm on unraid 6.8.3
-
in the "Restore" tab, how do I change the Source Directory field? I've tried changing it in the "Backup / Settings" tab but it appears to make no difference. What am I doing wrong? Here I've selected a directory called "2019-12-11-apps" yet under restore the source is showing a different directory
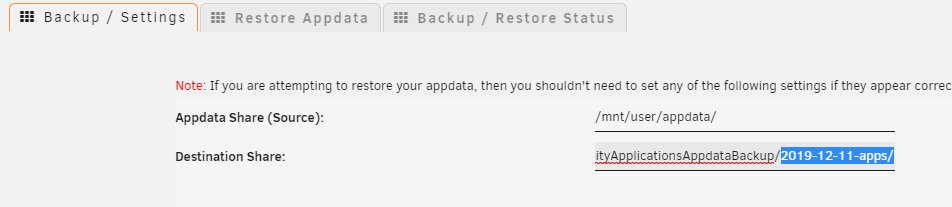
-
Apr 21, 2020 12:09:23.828 [0x7efd06ffd700] ERROR - SQLITE3:(nil), 11, database corruption at line 79051 of [bf8c1b2b7a] Apr 21, 2020 12:09:23.828 [0x7efd06ffd700] ERROR - SQLITE3:(nil), 11, statement aborts at 11: [select media_parts.id from media_parts join media_items on media_items.id=media_parts.media_item_id join metadata_items on metadata_items.id=media_items.metadata_item_id where metadata Apr 21, 2020 12:09:23.828 [0x7efd06ffd700] ERROR - Error cleaning media bundles: sqlite3_statement_backend::loadOne: database disk image is malformed the above is taken from my Plex Media Server.log From googling i've found a vast number of threads on this issue, can someone summarise what I can do to fix it? My plex docker is not stored on the array and i've never encountered any SQLITE corruption in the past. I'm currently running unraid 6.8.3 I have a backup of the plex docker, will restoring this help or is the problem else where?
-
also getting the "Preclear signature FAILED" on a WD My Book 8 TB via usb
-
not OP, but I've deleted the "admin" account using another account with admin privileges but admin remains and I'm able to log into the web ui using admin/"password". What am I doing wrong?
-
I noticed that medusa is using 11GB of my ram, after re-starting medusa it reports 230MB. Why might this be?
-
All of mine disappeared after the move to V2. I had to drop back to the previous version and restore a backup to restore (most) of my torrents. Lesson learned for me, backup more often and switch off auto update!
-
thanks. For anyone else who wants to move back to pre-V2, it's "binhex/arch-delugevpn:1.3.15_18_ge050905b2-1-04"
-
I'm also trying to restore my Deluge docker (binhex-delugevpn) , fortunately I have deluge in a different location to the rest of my docker apps so I have a restore file that contains just Deluge. Could someone tell me the steps? What does "Recreate your docker.img file if necessary (ideally, this should be performed regardless)" mean?
-
I've just inadvertently moved to 2.0, is there any way to move back to the previous version? My 1.5k-ish torrents have all vanished! Also , 2.0 isn't whitelisted all all private sites
.jpg.b58a195ce16fbfcaf35dd30342265cde.jpg)


