




RedXon
Members
-
Joined
-
Last visited
Everything posted by RedXon
-
Bump with new diagnostics, now with Unraid 6.10 RC-1 which, sadly hasn't resolved the issues. azeroth-diagnostics-20210820-0941.zip
-
Hello So I've followed some threads on here and on reddit and tried out the various solutions that were recommended to solve this problem, none of which really have done anything for me. For some reason for some time now my array just wont spin down. It never does. Even when I tell it to spin down manually, it just immediately spins back up as if something constantly would need the disk. This is weird as on every setting I see, all the system and docker files are on the cache. Also, in the plugins for active streams and file activity nothing shows up. In open files all the files that are open and on the disks are from the process SHFS, and afaik that shouldn't affect anything I think. What am I missing? I tried it with and without the cached directories plugin, both to no avail. Attached is the diagnostics log so I hope someone can find something as it get's really annoying (especially in summer). And yes, I know one of my drives is failing, I'll replace that shortly. azeroth-diagnostics-20210810-1259.zip
-
For a few days now I can't connect to my owncloud via my reverse proxy anymore as I get a 400 bad request anytime I try to do it. I have not changed anything in my proxy conf and have already contacted the dev of the owncloud docker container. He said that nothing has changed in the container since the issue came up for me, leading me to believe the error has to lie somewhere with the proxy. Does anyone know what it could be? It's now been a few weeks and I've tried to solve it on my own, without success. It worked until the 7th of may but has not worked since. I can not connect from either the browser, my phone, the owncloud windows or owncloud android client. Nothing works unfortunately. Does anyone have an idea? Here is my proxy conf that has, at least until the 7th of may, worked wonderfully. server { listen 443 ssl; listen [::]:443 ssl; server_name owncloud.*; include /config/nginx/ssl.conf; client_max_body_size 0; # enable for ldap auth, fill in ldap details in ldap.conf #include /config/nginx/ldap.conf; location / { # enable the next two lines for http auth #auth_basic "Restricted"; #auth_basic_user_file /config/nginx/.htpasswd; # enable the next two lines for ldap auth #auth_request /auth; #error_page 401 =200 /login; include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_owncloud owncloud; proxy_pass https://192.168.0.2:8000; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $remote_addr; proxy_set_header X-Forwarded-Port $server_port; proxy_set_header X-Forwarded-Proto $scheme; } }
-
Thanks for your answer. Unfortunately not really. I get this in my logs at startup, which doesn't seem that strange to me. After this it's conly the cron repeated with nothing else. May 12 02:20:24 1c9933409ffc cron[592]: (CRON) INFO (pidfile fd = 3) May 12 02:20:24 1c9933409ffc cron[592]: (CRON) INFO (Running @reboot jobs) 210512 02:20:24 mysqld_safe Logging to '/config/database/1c9933409ffc.err'. 210512 02:20:24 mysqld_safe Starting mysqld daemon with databases from /config/database May 12 02:25:24 1c9933409ffc mariadb: Upgrading databases... May 12 02:25:24 1c9933409ffc mariadb: This installation of MySQL is already upgraded to 10.3.29-MariaDB, use --force if you still need to run mysql_upgrade May 12 02:30:01 1c9933409ffc CRON[994]: (root) CMD (/sbin/setuser abc php /config/www/owncloud/occ system:cron &>/dev/null) May 12 02:39:01 1c9933409ffc CRON[1005]: (root) CMD ( [ -x /usr/lib/php/sessionclean ] && if [ ! -d /run/systemd/system ]; then /usr/lib/php/sessionclean; fi) Only thing I can think of is that it's some issue with my SWAG/Letsencrypt reverse proxy configuration, but I haven't changed anything in there, and all my other proxies still work. It still worked a few days ago, in fact the last sync action I had successfully was on the 7th of may. Because yes, also on my owncloud destkop app I get 400: Bad request (which is to be expected, as it also uses HTTP as a protocol I think). So unfortunately I have no idea what might have broken it. I have only my domain through the proxy as trusted domains, so I can't connect via local connection. I think I'll add the local IP to my trusted domains and try to access directly via the local IP and report back... Edit: in fact, yes. The issue lies with my reverse proxy it seems. All other sites still work but I get 400 with owncloud. Local connection to the IP works. Was there any change which needs a change in the reverse proxy conf?
-
Since some last update I have an error when I want to connect to the owncloud. I get Error 400 - Bad Request, regardless of what PHP Version I select. I tried version 7.2, 7.3 or 7.4. Does anyone know what the issue could be here?
-
I actually found out what the problem was, by trying something completely different, thanks for all your help. The file was encoded in UTF-8-BOM, which somehow was not compatible. I changed it to UTF-8 and tada, it works.
-
Thank you, I did exactly that But unfortunately it does nothing, not when I hit Force Scan not on adding it, nothing. Anything else that could be wrong here? The file works in VLC and other apps. It also works if I enter the m3u url from where I got it, but it has over 10000 entries, so I edited it with only the ones I want. There should be about 200 in there... For further clarification, I don't think there's a fault in the list, just in the way I put it in. I can for example load the list in Kodi with the Simple plugin included. It works fine but I unfortunately have no EPG there, that's what I try to do with Tvheadend. I hope that this can do that there.
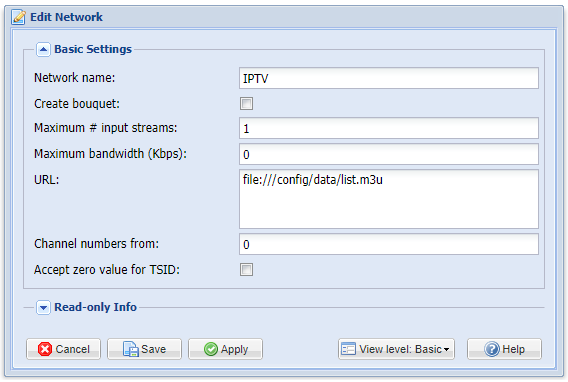
-
How can I add a local m3u file to TVheadend? If I try every combination with file:// it doesn't work, if I try absolute path, if I try mapped path, no matter what I try, it doesn't work unfortunately.
-
Does this work with an USB 3.0 Bluray drive?

