




vurt
Members
-
Joined
-
Last visited
Everything posted by vurt
-
Can this be updated with a dark mode please? Pretty please! I believe the new version 2.2 might have it.
-
Hi @advplyr. I recently had to recreate my docker img. After reinstalling Audiobookshelf from the old existing template which worked previously, I can't access it via ita LAN ip. But oddly I can access it via URL because I reverse proxied it. Do you know how to resolve this?
-
I did as you suggested and indeed found "lsio" in some of the files. The odd thing is, after I recreated the docker img, Custom:br0 is already there but Custom:lsio wasn't. Anyway I did "docker network create lsio" and recreated the custom network. I've since managed to bring back a few of the containers. This is a different problem now. Sonarr won't start and at the end of the container install log, shows this error: docker: Error response from daemon: error while creating mount source path '/mnt/user/appdata/downloads': mkdir /mnt/user: file exists. Audiobookshelf also shows a similar error: docker: Error response from daemon: error while creating mount source path '/mnt/user/appdata/downloads': mkdir /mnt/user: file exists. Radarr shows this error: unable to open database file I think the Radarr error might be solved if I can find restore a backup of the database. But I'm sure what's going on with Sonarr and Audiobookshelf—would you have any ideas? thank you for your help!
-
Thank you! I think I might have a custom network, i was following a guide. From what I read in your link, custom networks are gone with the deleted docker image. When I'm re-adding the containers, does the template remember the Network Type from previously? Because right now, eg, radarr's network type is None, but when I click on the dropdown, I see an option for Custom: br0. And to complicate matters, I thought I'd created a custom network called "lsio" because I was following a guide for Linux Server's containers. I hope that didn't sound as confusing as I feel.
-
Hi all, can someone help me out please? This happened during the monthly parity check. I was previously on v6.12.14 and then updated to v7.0.1 hoping it'll automagically solve it after a reboot. No dice. I've attached the diagnostic zip. I'm also away and don't have physical access. I've set up a wireguard tunnel for remote access. Thank you in advance, tower-diagnostics-20250503-1837.zip
-
Whew, replaced the data cables and rebuilt Disk 1, seems t o be back to normal now... thank you so much. Attached a new diags just in case... thank you again. tower-diagnostics-20240516-1107.zip
-
text error warn system array login Apr 30 14:59:38 Tower kernel: sd 2:0:0:0: [sdc] 39063650304 512-byte logical blocks: (20.0 TB/18.2 TiB) Apr 30 14:59:38 Tower kernel: sd 2:0:0:0: [sdc] 4096-byte physical blocks Apr 30 14:59:38 Tower kernel: sd 2:0:0:0: [sdc] Write Protect is off Apr 30 14:59:38 Tower kernel: sd 2:0:0:0: [sdc] Mode Sense: 00 3a 00 00 Apr 30 14:59:38 Tower kernel: sd 2:0:0:0: [sdc] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA Apr 30 14:59:38 Tower kernel: sd 2:0:0:0: [sdc] Preferred minimum I/O size 4096 bytes Apr 30 14:59:38 Tower kernel: sdc: sdc1 Apr 30 14:59:38 Tower kernel: sd 2:0:0:0: [sdc] Attached SCSI disk Apr 30 14:59:59 Tower emhttpd: WDC_WD201KFGX-68BKJN0_8LGN4XZF (sdc) 512 39063650304 Apr 30 14:59:59 Tower kernel: mdcmd (2): import 1 sdc 64 19531825100 0 WDC_WD201KFGX-68BKJN0_8LGN4XZF Apr 30 14:59:59 Tower kernel: md: import disk1: (sdc) WDC_WD201KFGX-68BKJN0_8LGN4XZF size: 19531825100 Apr 30 14:59:59 Tower emhttpd: read SMART /dev/sdc Apr 30 15:00:08 Tower emhttpd: shcmd (32): echo 128 > /sys/block/sdc/queue/nr_requests May 1 21:57:00 Tower kernel: I/O error, dev sdc, sector 1953509432 op 0x0:(READ) flags 0x0 phys_seg 4 prio class 2 May 1 21:57:00 Tower kernel: I/O error, dev sdc, sector 1953509432 op 0x1:(WRITE) flags 0x0 phys_seg 4 prio class 2 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#12 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=21s May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#12 Sense Key : 0x5 [current] May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#12 ASC=0x21 ASCQ=0x4 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#12 CDB: opcode=0x88 88 00 00 00 00 04 88 ae 94 68 00 00 05 40 00 00 May 1 21:57:15 Tower kernel: I/O error, dev sdc, sector 19473011816 op 0x0:(READ) flags 0x0 phys_seg 168 prio class 2 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#15 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=21s May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#15 Sense Key : 0x5 [current] May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#15 ASC=0x21 ASCQ=0x4 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#15 CDB: opcode=0x88 88 00 00 00 00 04 88 ae 99 a8 00 00 02 f0 00 00 May 1 21:57:15 Tower kernel: I/O error, dev sdc, sector 19473013160 op 0x0:(READ) flags 0x0 phys_seg 94 prio class 2 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#16 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=21s May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#16 Sense Key : 0x5 [current] May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#16 ASC=0x21 ASCQ=0x4 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#16 CDB: opcode=0x88 88 00 00 00 00 04 88 ae 9c 98 00 00 02 50 00 00 May 1 21:57:15 Tower kernel: I/O error, dev sdc, sector 19473011816 op 0x1:(WRITE) flags 0x4000 phys_seg 168 prio class 2 May 1 21:57:15 Tower kernel: I/O error, dev sdc, sector 19473013912 op 0x0:(READ) flags 0x0 phys_seg 74 prio class 2 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#17 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=21s May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#17 Sense Key : 0x5 [current] May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#17 ASC=0x21 ASCQ=0x4 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#17 CDB: opcode=0x88 88 00 00 00 00 04 88 ae 9e e8 00 00 05 40 00 00 May 1 21:57:15 Tower kernel: I/O error, dev sdc, sector 19473014504 op 0x0:(READ) flags 0x4000 phys_seg 168 prio class 2 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#18 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=21s May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#18 Sense Key : 0x5 [current] May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#18 ASC=0x21 ASCQ=0x4 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#18 CDB: opcode=0x88 88 00 00 00 00 04 88 ae a4 28 00 00 00 80 00 00 May 1 21:57:15 Tower kernel: I/O error, dev sdc, sector 19473015848 op 0x0:(READ) flags 0x0 phys_seg 16 prio class 2 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#19 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=21s May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#19 Sense Key : 0x5 [current] May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#19 ASC=0x21 ASCQ=0x4 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#19 CDB: opcode=0x88 88 00 00 00 00 04 88 ae a4 a8 00 00 05 40 00 00 May 1 21:57:15 Tower kernel: I/O error, dev sdc, sector 19473015976 op 0x0:(READ) flags 0x0 phys_seg 168 prio class 2 May 1 21:57:15 Tower kernel: I/O error, dev sdc, sector 19473013160 op 0x1:(WRITE) flags 0x4000 phys_seg 168 prio class 2 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#20 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=21s May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#20 Sense Key : 0x5 [current] May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#20 ASC=0x21 ASCQ=0x4 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#20 CDB: opcode=0x88 88 00 00 00 00 04 88 ae a9 e8 00 00 05 40 00 00 May 1 21:57:15 Tower kernel: I/O error, dev sdc, sector 19473017320 op 0x0:(READ) flags 0x0 phys_seg 168 prio class 2 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#21 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=21s May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#21 Sense Key : 0x5 [current] May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#21 ASC=0x21 ASCQ=0x4 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] tag#21 CDB: opcode=0x88 88 00 00 00 00 04 88 ae af 28 00 00 05 40 00 00 May 1 21:57:15 Tower kernel: I/O error, dev sdc, sector 19473018664 op 0x0:(READ) flags 0x0 phys_seg 168 prio class 2 May 1 21:57:15 Tower kernel: sd 2:0:0:0: [sdc] Synchronizing SCSI cache May 2 09:58:12 Tower emhttpd: error: hotplug_devices, 1709: No such file or directory (2): tagged device WDC_WD201KFGX-68BKJN0_8LGN4XZF was (sdc) is now (sdg) ** Press ANY KEY to close this window ** Also attached a diagnostic zip. The Dashboard isn't responsive—nothing happens when I try to spin down the disabled drive or spin down the array. The Parity Check remains paused, can't cancel it. tower-diagnostics-20240502-1022.zip
-
Thank you thank you!
-
@JorgeB Sorry, hopefully this is the last question... my dockers are back, but sabnzbd is having difficulty starting up "Execution Error". I removed it, and reinstalled it from the user template, and still getting the error. This is the output from the install: docker run -d --name='sabnzbd' --net='lsio' -e TZ="America/New_York" -e HOST_OS="Unraid" -e HOST_HOSTNAME="Tower" -e HOST_CONTAINERNAME="sabnzbd" -e 'PUID'='99' -e 'PGID'='100' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='http://[IP]:[PORT:8080]/' -l net.unraid.docker.icon='https://raw.githubusercontent.com/linuxserver/docker-templates/master/linuxserver.io/img/sabnzbd-icon.png' -p '8080:8080/tcp' -p '9090:9090/tcp' -v '/mnt/user/appdata/downloads/':'/downloads':'rw' -v '/mnt/user/appdata/downloads/incomplete/':'/incomplete-downloads':'rw' -v '/mnt/user/appdata/sabnzbd':'/config':'rw' 'linuxserver/sabnzbd' 9a17b4e103d196ccd1bc70ca2424698d2fb1ff9bb8309c50a6e039963da7e688 docker: Error response from daemon: driver failed programming external connectivity on endpoint sabnzbd (8314f2297d197ff8245f283a14065cc78112e31c5c4cdfc1a5cd5b418f3eeb89): Error starting userland proxy: listen tcp4 0.0.0.0:9090: bind: address already in use. The command failed. I can see there's a conflict with the bind address but I don't know what that actually means or how to resolve. Thanks so much for your help!
-
Whew, thank you! @JorgeB I also lost my dockers... from what I read, I can go to the Apps tab and look at Previous Apps and reinstall from there... would that be safe to do? [I'm not seeing a lost+found folder unless I'm looking in the wrong places, or maybe there isn't one?]
-
Hi @JorgeB, thanks so much for the quick response. I ran -n, and then had to do -L. This is the output after the repair: Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being destroyed because the -L option was used. - scan filesystem freespace and inode maps... clearing needsrepair flag and regenerating metadata sb_ifree 33068, counted 33075 sb_fdblocks 2448669658, counted 2453742304 - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - agno = 16 - agno = 17 - agno = 18 - agno = 19 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 2 - agno = 1 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - agno = 16 - agno = 17 - agno = 18 - agno = 19 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... Maximum metadata LSN (35:2939140) is ahead of log (1:2). Format log to cycle 38. done
-
Hi all... my setup mysteriously got this error. I've searched the forum and followed the diagnostic advice. This is the output of the filesystem check: Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being ignored because the -n option was used. Expect spurious inconsistencies which may be resolved by first mounting the filesystem to replay the log. - scan filesystem freespace and inode maps... sb_ifree 33068, counted 33075 sb_fdblocks 2448669658, counted 2453742304 - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - agno = 16 - agno = 17 - agno = 18 - agno = 19 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 3 - agno = 2 - agno = 1 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - agno = 16 - agno = 17 - agno = 18 - agno = 19 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... No modify flag set, skipping filesystem flush and exiting. And attached is the log. Can someone please advice? This looks scary catastrophic. tower-diagnostics-20240308-1114.zip
-
Oh does this mean I probably always had this error but the previous version wasn't reporting it? Can I click on /mnt/user/appdata/downloads and it'll be excluded from backup? I think this is the folder that's causing the error. It doesn't require backing up anyway.

-
Thank you, that makes sense but wasn't an error previously. The appdata/downloads folder is used by Sabnzbd, Radarr, Sonarr, and Hydra.
-
-
Yeah still getting 75% warning, is that odd if the CLI says 65% is used? The warning is always 75% though, it's not increasing. I increased the allocation to 30G to see how that goes.
-
Hi there, recently updated to the latest Appdata.Backup so I migrated from the previous one. I'm getting this new error: tar creation failed! Tar said: tar: /mnt/user/appdata/downloads/incomplete: file changed as we read it This is the debug log ID that was sent: 030ae8ae-4efa-40f0-957a-cc7ab4d3e48c hope that works, never sent a debug log like this before!
-
Thanks for helping take a look @trurl 🙏

-
20GB, I think this was the default.
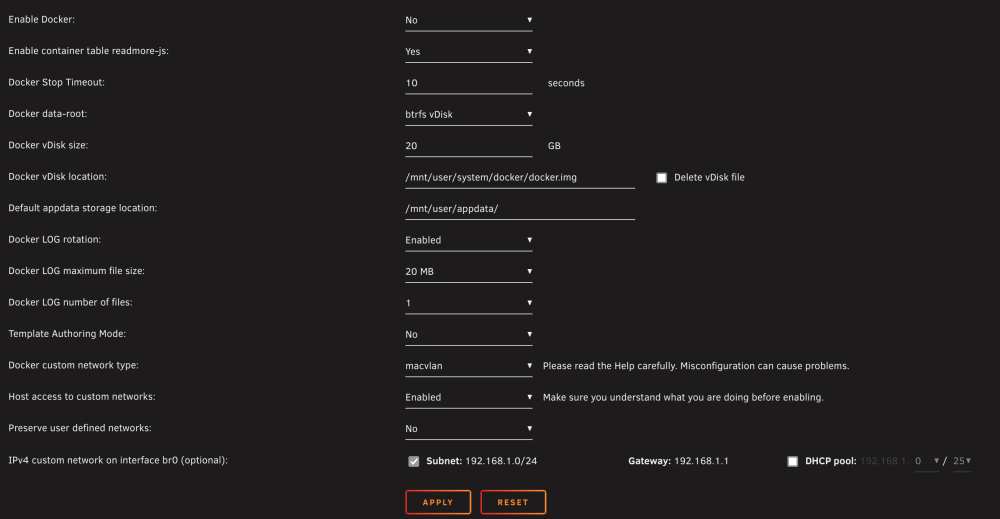
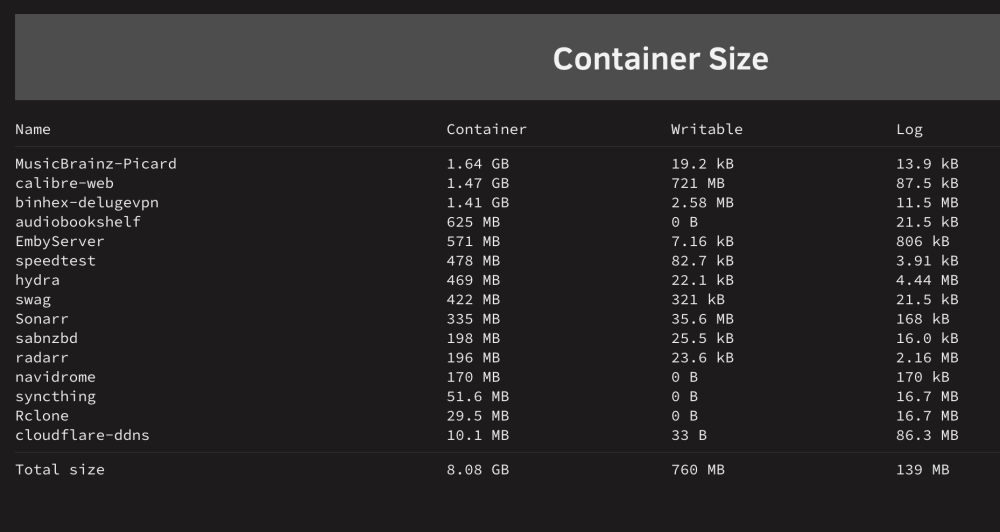
-
Here's the breakdown. I'm asking because I'm receiving warnings: "Docker image disk utilization of 75%." Picard, Calibre, and Deluge are far bigger than I expected.
-
@SmartPhoneLover Thank you for this! I just came across gonic and thought to try it as replacement for navidrome. Are there set up considerations for unraid? Do I just install it from DockerHub? Also, do you know if gonic is capable of writing tags to the music files?
-
Sorry I didn't contact them, I wanted to check in here if other SWAG users have encountered this. I noticed my SSL cert expired and when I went looking, I saw this on ZeroSSL. It looks like they've changed this so it's no longer free and unlimited, and it doesn't look like we can get wildcards at all unless we upgrade to their Premium plan. Looks self-explanatory but I wanted to confirm I'm not ... crazy or other SWAG users have worked around this.

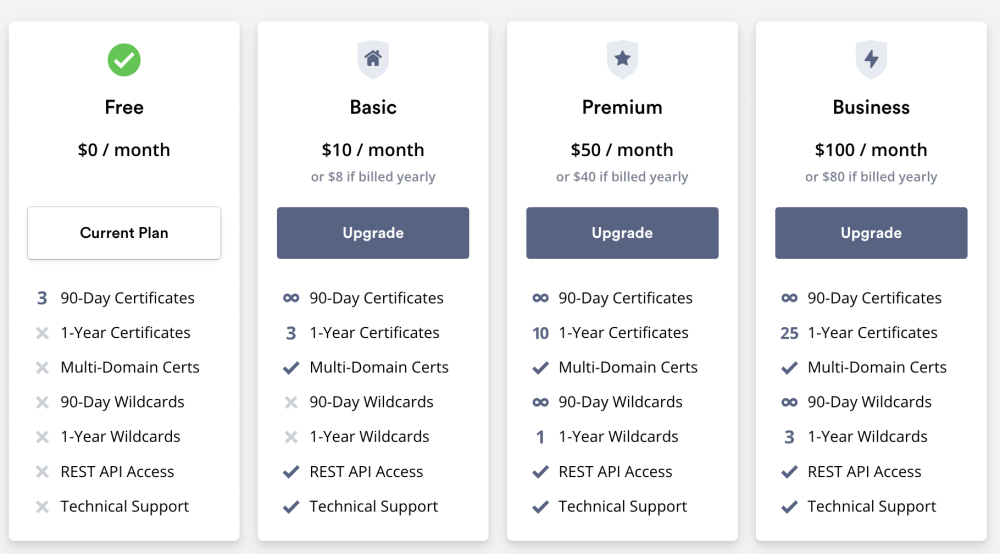
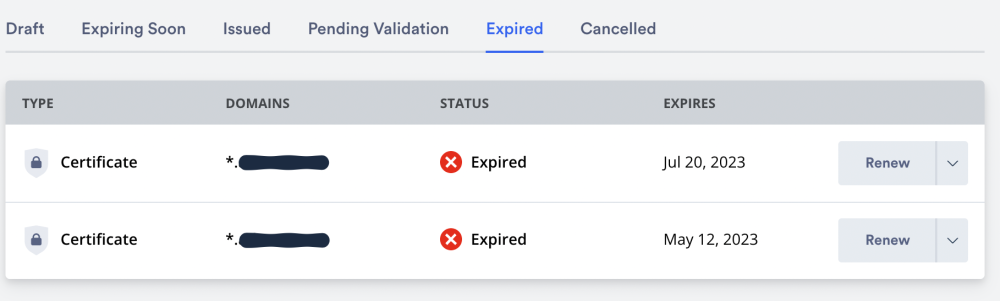
-
Has anyone encountered an issue with ZeroSSL? I didn't know this previously or it might be a change on their end, but I've ran out of "credits" on the free plan to renew my SSL cert.
-
Hi fellow unraiders. I'm getting this error, could it be due to the recent unraid update? EPIC FAIL! NzbDrone.Core.Datastore.CorruptDatabaseException: Database file: /config/sonarr.db is corrupt, restore from backup if available. See: https://wiki.servarr.com/sonarr/faq#i-am-getting-an-error-database-disk-image-is-malformed ---> System.Data.SQLite.SQLiteException: database disk image is malformed database disk image is malformed
-
Hi fellow Unraiders. I recently replaced and rebuilt a data drive. Subsequently, I'm having issues with Emby. The three users I set up are gone, I can't log in with their creds. Instead, I see a new user "bin" that I never created. I found this discussion on the Emby forum which pointed me at users.db, I also posted there for help. Per the Emby discussion, I opened up users.db, and I can see my three users in there. And there's no "bin" user. What could've happened and how do I fix this? In /data: In users.db:











