



wayner
Members
-
Joined
-
Last visited
Everything posted by wayner
-
I have two licensed Unraid servers tied to the same email address. I think I have a bad USB drive in server1 - it is from 2017. I am trying to replace my key but I am worried that I will blacklist server2, which is good, rather than server1. How does it work when you have multiple servers and you are trying to replace a key. Does it give you an option on which one to replace, and were does that happen?
-
From an old diag file I found that this system is running Unraid version 6.4.1
-
I have an older Unraid server which is running an older version of Unraid. It had a disk that had failed. So I stopped the array, unassigned the old disk, put in a new disk and powered on. The system will not fully boot up. Here is what I get on the monitor. I get the same error when I put the old hard drive back in rather than the new drive. The system is now quite a few years old as is the USB drive. Anyone have a recommendation on how to fix.
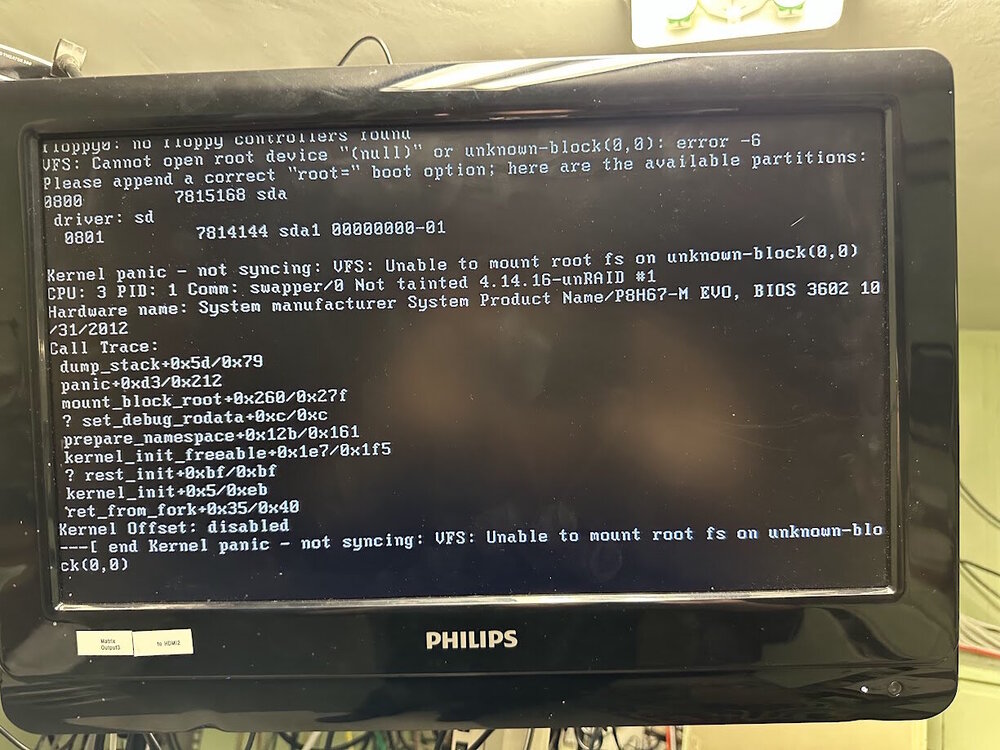
-
Awesome. Thanks.
-
I have a data drive that is throwing errors. I am going to replace it ASAP. When I start the rebuild of the data drive will the array be online at the time, which means that the dockers are alive? Or does the rebuild only happen with the array stopped?
-
@spants I believe one other action is needed - you need to create a lighttpd folder under the logs folder in appdata. I noticed that pihole wasn't running so I checked the logs which showed the text below. I manually created a /appdata/pihole/log/lighttpd folder and now it seems to work ok. When the docker restarted it created files in that lighttpd folder. install: cannot create regular file '/var/log/lighttpd/access-pihole.log': No such file or directory install: cannot create regular file '/var/log/lighttpd/error-pihole.log': No such file or directory chown: cannot access '/var/log/lighttpd': No such file or directory chmod: cannot access '/var/log/lighttpd/access-pihole.log': No such file or directory chmod: cannot access '/var/log/lighttpd/error-pihole.log': No such file or directory 2024-12-30 17:17:53: configfile.c.1290) opening errorlog '/var/log/lighttpd/error-pihole.log' failed: No such file or directory 2024-12-30 17:17:53: server.c.1509) Opening errorlog failed. Going down. Stopping lighttpd lighttpd: no process found
-
FYI, there seems to be another similar issue. The pihole-FTL.db file also gets very large. Currently this file is in /appdata/pihole/pihole on my server. Apparently you can limit the amount of logging that goes to this database in the pihole-FTL.conf file. I have to figure out how to do this.
-
@JorgeB When I received my daily dis report it is still showing errors. How do I reset the read error? Event: Unraid Status Subject: Notice [PORTRUSH] - array health report [FAIL] Description: Array has 5 disks (including parity & pools) Importance: warning Parity - ST8000DM004-2U9188_ZR11R018 (sdb) - active 31 C (disk has read errors) [NOK] Disk 1 - ST4000DM004-2CV104_ZTT2QHX8 (sdc) - active 34 C [OK] Disk 3 - ST8000DM004-2U9188_ZR11SQ9R (sdd) - active 31 C [OK] Cache_nvme - WDC_WDS500G2B0C_21305D807219 (nvme0n1) - active 38 C [OK] Cache_nvme 2 - CT500P3SSD8_2310E6B819BE (nvme1n1) - active 35 C [OK] Parity is valid Last checked on Sun 29 Dec 2024 08:15:15 AM EST (yesterday), finding 0 errors. Duration: 7 hours, 15 minutes, 9 seconds. Average speed: 306.5 MB/s
-
Thanks Jorge, I will keep a close eye on it.
-
Thanks - I just did that and I see that the docker created a pihole folder off of my /appdata/pihole/log folder, as in /appdata/pihole/log/pihole, and it has created two files so far - pihole.log and FTL.log. So it seems to have worked. I will keep an eye on the docker size. Thanks!
-
I agree in that the log max size is not working. My log size got up to 4.6GB. It seems like logs are being written to somewhere in the docker rather than the appdata folder. This sure seems to be a bug to me.
-
Last weekend when my parity check was running a SMB network share died as my old Unraid server (192.168.1.99) went down. At the same time my current Unraid server, named Portrush, started having disk read errors on my parity drive (disk0). These errors only lasted for a second at Dec 21 09:29:42. Since then I don't see any new read errors, and I successfully went through a parity check. Is this indicative of a problem on the parity drive or are these read errors possibly related to the other server going down. This other server is set up as a SMB share on my main server. On my daily notice report I still see the following: "Parity - ST8000DM004-2U9188_ZR11R018 (sdb) - active 32 C (disk has read errors) [NOK]". How do I reset this error? Or should I? See my logs below (logs truncated as there were 169 of these read errors). Dec 21 09:29:39 Portrush kernel: CIFS: VFS: \\192.168.1.99\media BAD_NETWORK_NAME: \\192.168.1.99\media Dec 21 09:29:39 Portrush kernel: CIFS: VFS: reconnect tcon failed rc = -2 Dec 21 09:29:41 Portrush kernel: CIFS: VFS: \\192.168.1.99\media BAD_NETWORK_NAME: \\192.168.1.99\media Dec 21 09:29:41 Portrush kernel: CIFS: VFS: reconnect tcon failed rc = -2 Dec 21 09:29:42 Portrush kernel: ata1.00: exception Emask 0x0 SAct 0x3f80 SErr 0x0 action 0x0 Dec 21 09:29:42 Portrush kernel: ata1.00: irq_stat 0x40000008 Dec 21 09:29:42 Portrush kernel: ata1.00: failed command: READ FPDMA QUEUED Dec 21 09:29:42 Portrush kernel: ata1.00: cmd 60/40:38:d0:98:f8/05:00:0b:02:00/40 tag 7 ncq dma 688128 in Dec 21 09:29:42 Portrush kernel: res 43/40:40:e8:98:f8/00:05:0b:02:00/00 Emask 0x409 (media error) <F> Dec 21 09:29:42 Portrush kernel: ata1.00: status: { DRDY SENSE ERR } Dec 21 09:29:42 Portrush kernel: ata1.00: error: { UNC } Dec 21 09:29:42 Portrush kernel: ata1.00: configured for UDMA/133 Dec 21 09:29:42 Portrush kernel: sd 1:0:0:0: [sdb] tag#7 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Dec 21 09:29:42 Portrush kernel: sd 1:0:0:0: [sdb] tag#7 Sense Key : 0x3 [current] Dec 21 09:29:42 Portrush kernel: sd 1:0:0:0: [sdb] tag#7 ASC=0x11 ASCQ=0x4 Dec 21 09:29:42 Portrush kernel: sd 1:0:0:0: [sdb] tag#7 CDB: opcode=0x88 88 00 00 00 00 02 0b f8 98 d0 00 00 05 40 00 00 Dec 21 09:29:42 Portrush kernel: I/O error, dev sdb, sector 8790776016 op 0x0:(READ) flags 0x0 phys_seg 168 prio class 2 Dec 21 09:29:42 Portrush kernel: md: disk0 read error, sector=8790775952 Dec 21 09:29:42 Portrush kernel: md: disk0 read error, sector=8790775960 Dec 21 09:29:42 Portrush kernel: md: disk0 read error, sector=8790775968 Dec 21 09:29:42 Portrush kernel: md: disk0 read error, sector=8790775976 Dec 21 09:29:42 Portrush kernel: md: disk0 read error, sector=8790775984 Dec 21 09:29:42 Portrush kernel: md: disk0 read error, sector=8790775992 Dec 21 09:29:42 Portrush kernel: md: disk0 read error, sector=8790776000
-
Unless I am missing something here the UXG-Lite and UXG-Max make no sense. Unless you really want 2.5Gb LAN ports. But the UXG-Lite is slightly more expensive than the UCG-Ultra and is inferior in every way.

-
So I am thinking about replacing my USG - it looks like the best device to replace it with is a UCG-Ultra. But that device has the Unifi network application builtin. But this appears better than a UXG-Lite and is cheaper than a UXG-Max despite having similar specs. Is there any downside to switching to this device and now using that as my controller, rather than self-hosting the Unifi controller on a docker on Unraid?
-
Thanks for the feedback folks, and thanks for making this docker!
-
Thanks, is there an issue with upgrading too many versions at once. If I go to 7.5.187 can I then jump up to the stable tag of 8.5.6 or should I stop at 8.1.127 first?
-
Will do. Would you happen to know the minimum controller version for the UXG-Max or UXG-Lite. I still have a USG but will be upgrading it soon to one of these so I think I need to be on a newer version for that as well.
-
I never moved from 7.2.95 as there wasn't a compelling reason and last September you said (in the Unifi Controller thread) that 7.2.95 tags are fine for now. Once we got into last October we got into the linuxserver Unifi controller being deprecated issue and I didn't think it was worth changing anything until that settled down and then I hadn't paid any attention to upgrading to the new docker until now. If I went into the old Unifi Controller and changed the tag to 7.5.187, would that upgrade my old docker to 7.5.187, or is that repository of controller versions no longer existing?
-
Thanks for your response, But this doesn't address the issue of restoring your backup from the same version. My backup will be version 7.2.95 and from what you show in step 3 I will be restoring to a system running 7.5.187. Isn't that a no-no? @PeteAsking says in post 1 of this thread "Make sure old version of unifi controller is the same version you will be migrating to. Unifi is difficult if the versions are different. " Can I ignore that? Or should I upgrade my old docker to 7.5.187 first, assuming that is even possible anymore?
-
I have not touched my unifi controller docker in over a year and not paid attention since there was still debate on whether to use the two docker solution or one docker almost exactly a year ago. It is good to see that there is a stable single docker solution. I am currently running the old linuxserver non-reborn unifi controller docker with version 7.2.95 which was the recommended old old stable version in the past. Given that you are supposed to be on the same Unifi version when switching to reborn, what should I do? Do I upgrade the old linuxserver Unifi controller docker to version 7.5.187 by changing the repository parameter to linuxserver/unifi-controller:version-7.5.187. Then follow the instructions in the first post? Or do I install the reborn docker and use 11notes/unifi:7.2.95-unraid as the version? Or does that version even exist in that repository? Or something else?
-
Thanks
-
I always thought that it was the former, but the website for the product seems to use Unraid.
-
Can this be added to the apps repository?
-
When I search for rclone in apps there are five results - four of them are dockers and one is a plugin. Which one do I use? Can I use the Nacho-Rclone-Native-GUI docker?
-
I use OneDrive to hold all of my personal data files and I have it set to sync on a couple of different PCs in my house. This is separate from all my media files which are stored in unRAID and these data files are relatively modest in size - about 29GB. I want to ensure that these data files are also held elsewhere in case I ever got locked out of my MS account. I know that they should be on my local PCs in the c:\Users\wayner\OneDrive account but I want to back them up outside of the OneDrive world as well, just in case my account got hacked and someone was able to delete or lock my files. What would be the best way to backup this data to unRAID? I know that there are a few OneDrive/Dropbox "clones" that run on unRAID. Which one would make sense for my purposes and can you have it sync on a daily or weekly basis? Or is there a better way of solving this problem?


