



wayner
Members
-
Joined
-
Last visited
Everything posted by wayner
-
I tried a fresh 7.2.2 install on the old USB and a different USB but I still got the same error. I tried the front USB port and still got the error. I removed all other USB devices, except the keyboard and got the error. I tried one of the rear USB ports and it booted. So it looks like there may be an issue with some of the USB ports on my motherboard. I restored my Nov 2025 backup and got up and running. That was in OS 6.12.4. I am now upgrading to 7.0.1. I will try the original USB port again later on to see if I still get the error or whether it was something sporadic. Very strange.
-
How do I backup the current flash drive since I can't boot into the Unraid OS? I have a backup that is from Nov 2025, and I haven't changed much on the system since then. So I am happy to restore this. Should I try to recreate a boot flash drive on the existing USB drive using the USB tool to create a 7.2 boot disk? Then copy over the /config file from the backup zip file? Is that essentially the same as restoring a full backup? Or even just try restoring the Nov 2025 backup? How do I tell what version my backup ZIP drive is? I think it is 7.2.2 but I am not 100% sure. This backup is from Nov 28, 2025 which is one week after 7.2.2 was released. I presume this would be in one of the files in the backup? which one?
-
Overnight I had a power outage. My system has a UPS so this shouldn't cause problems, but I don't know how long the outage lasted. My system was unresponsive. I tried powering off and back on and got error 110. I tried shutting the power for 10 minutes but it still won't boot up. The system keeps trying to find a boot drive but I keep getting this error -110. The system has run fine for several years. The boot drive is a Samsung flash drive that is attached to the USB header on the motherboard. I have not touched anything to do with the boot drive in a long time. I believe the system is running Unraid 7.2.2 I Googled and there doesn't seem to be much on this topic. I am guess that the issue is that my flash drive is not working.
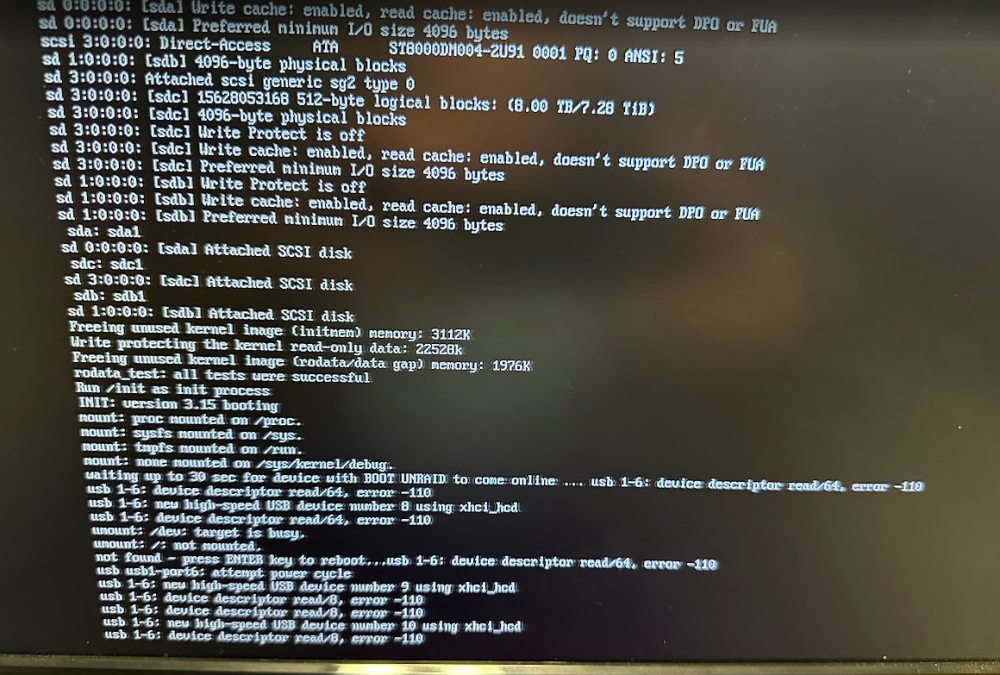
-
I am now very glad that I decided to buy a UCG model as my new gateway rather than a UXG. Thanks for all your hard work @PeteAsking !
-
I am going to be switching to a UCG gateway so I won't be using the Unifi Network Application docker container anymore. Any advice on which version on the docker container that I should be on when I migrate to the UCG device? I am on 9.5.21 right now. Should I try to install 9.5.2 on the UCG so that I am on the same versions before migrating?
-
I am now I went through this path and I am now on 9.5.21. Pretty much up to date. But maybe time to upgrade my USG3P to something newer!
-
So far I have gone from 7.5.187 to 8.0.26 to 8.5.6. You can see that it has to do a database conversion on some of these upgrades. It seems that it leaves behind orphaned images. What do you do to get rid of them?
-
I just upgraded from the old docker container to unifi reborn and all is well. Thanks @PeteAsking for all your work on this! I went from 7.2.95 to 7.5.187 and am now trying to figure out a path to more recent versions. I skimmed through this thread and it seems like a viable upgrade path would be to 8.0.26 to 8.5.6 to 9.0.108 to 9.5.21. This is not being too aggressive and skipping too many upgrades along the way. Does this make sense to those of you with more experience at this? I guess I could always try rolling back if required.
-
I am not sure what you mean by method 1 or 2. I am going by post 1 "To install this docker" where you say to backup, stop the old container, install the new container, start it and restore. Is that method 1? If there were problems could I then just. stop and delete the new container and then start up the old container and it will work as if nothing ever happened.
-
I am finally getting around to moving to this container from the old Unifi container. If things don't go well on my upgrade can I just delete the new Unifi reborn container and go back to my old Unifi Controller container?
-
What's the use case for needing transcoding? When you are remote and have a slower upload speed?
-
Sorry for the delayed response as I missed your post. Back when I installed AirVideo it was available through the Unraid Apps repository. I don't think it is there anymore. But you can manually create a docker, but I don't really know how to do that. The docker files seems to still be available here: https://hub.docker.com/r/dmaxwell/airvideohd/ and can be installed with: docker run -d --net=host -v /mnt/user/appdata/airvideohd:/config -v /mnt/user/Media:/videos -v /mnt/user/appdata/airvideohd/temp:/conversionPath --name airvideohd dmaxwell/airvideohd So if you can figure out how to add the docker manually it should still work. Good luck! If you get it working please post your results to help others.
-
Plex seems to need metadata to pull in shows. My main TV watching is sports and I use a PC based DVR (SageTV) to record content. Plex doesn't like Filenames like NFLFootball-LosAngelesRamsatSeattleSeahawks-29695429-0.mpg There have been some Plex (and/or Jellyfin) plugins to pull in sports but I have had issues getting them to work properly - not that I have tried recently. Another option that I have occasionally used is VLC. With VLC you can browse to your Unraid shares and play files.
-
Can you go into more detail on how you setup the configured vlans? Thanks.
-
But the nice thing about giving each device its own IP address is that you can just use port 80 for the web UI and don't have to futz around with port numbers when typing in URLs.
-
I want to try to install a second version of a docker contianer from the Apps repository. But when you click on Actions it gives you the options for WebUI, Edit or Uninstall. What about installing again to a different appdata folder with different port/Ip settings?
-
Thanks. This works but to me this sure seems like a bug, not a feature.
-
I have several dockers where I have specified that the docker get its own IP address. Is there any reason not to do this for every docker? Why futz around with port numbers where you are using stuff like 8888 and 8080, etc for web ports when you can just use the default port 80 on every docker with its own IP?
-
I recently installed Tailscale on my Unraid server and have it set up to allow local network access and to work as an exit node. When I am connecting remotely from my phone or another PC I am able to access devices on my LAN so I know that Tailscale is Working. But I can't access dockers running in custom br0 network types. I am using IPVLAN and host access to custom networks is disabled. Should this be enabled? Any downsides to enabling this?
-
I have two Unraid servers and on both of them I am having problems moving items around on the dashboard. I click the lock icon to unlock the dashboard, but when I try to move items around they tend to snap back to where they were originally. It seems that I can move them to the middle of the three columns, but I can't move items to the left or right column.
-
How do you customize things like moving the menu from the side to the top. The Azure color theme is different than the White color theme, but what if you want to mix and match? I found a plugin called Custom WebUI CSS but that seems like a lot of low level work. Can you not just select things like colors, menu placement, etc the way that you would for something like the Windows UI?
-
When I change the Dynamix Color Theme from Azure to White it doesn't really change the color that much, but it does change the menu placement from the side to the top, and it adds a bunch of icons along the header. But the color doesn't really change to white, it still seems to be a light gray. Is this misnamed? And how do I edit the theme it so that I can customize colors, menu locations, button links in the header, etc. I don't see a theme editor in the apps.
-
I am having this same issue after having upgraded from 6.4.1 to 7.0.1. I do have xmls for my dockers but I can't edit them. How do I repair this? See the thread I started here: https://forums.unraid.net/topic/195791-issues-with-dockers-after-upgrading-unraid-from-641-to-701/
-
I just did this big upgrade and things seem to be going relatively ok, except that there is an issue with my Dockers. My dockers all say 3rd party and there are a few menu items missing from the dropdown - no Edit and no WebUI. How do I fix this? I looked in /boot/config/plugins/dockerMan/templates-user and there are XML files for all of my dockers. I also have these one my backup. But is the issue one of compatibility? These xml files from 6.4.1 are not compatible with 7.0.1. When I look at previously installed apps it doesn't show the dockers that are currently installed. Diagnostics file is attached. hoylake-diagnostics-20251213-1158.zip
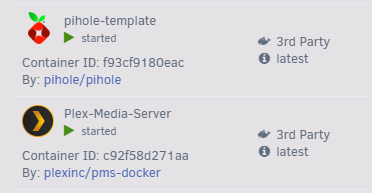
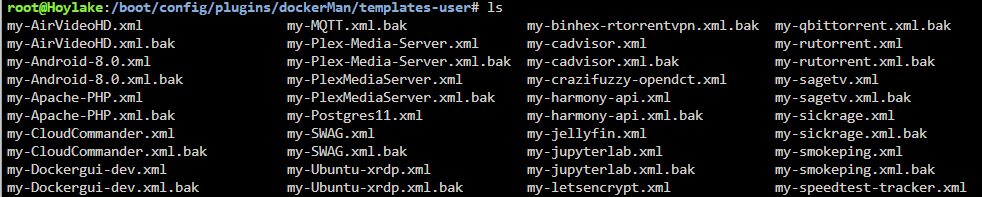
-
I have an older server that I have not upgraded in a LONG time. I want to upgrade it from 6.4.1 and it shows that the update available is 7.0.1. This is quite a few versions. Should I be aware of any issues? I have removed a bunch of older plugins that appear to have been deprecated. Anything else that I should do before upgrading? The Update assistant said to update these but most of them can't be updated so I have got rid of them for now. One of the things I had to get rid of was Fix Common Problems, which had the update assistant and now I am flying blind. And the Apps tab isn't working as it gives me an error as seen below. But I will uninstall that plugin as well, since that is from the days when it was still a plugin. Something really wrong went on during force_update Post the ENTIRE contents of this message in the Community Applications Support Thread <br /> <b>Fatal error</b>: Allowed memory size of 134217728 bytes exhausted (tried to allocate 23072768 bytes) in <b>/usr/local/emhttp/plugins/community.applications/include/helpers.php</b> on line <b>47</b><br /> I have backed up the USB Flash drive. If things go wrong can I just restore it and everything should go back to 6.4.1?





