





Can0n
Members
-
Joined
-
Last visited
Everything posted by Can0n
-
everything but the chmod has been in my go file for 2 years since i built my first unraid server ill update it and run the command to avoid the need to reboot thanks
-
well hot damn thank you that worked guess i should pay more attention to release notes !
-
@SpaceInvaderOne I was just trying to run a docker command using the old docker-shell script @ljm42 created and the video on it you did back in 2017 here getting Permission denied. im not sure if its the kernel update or docker revision but wondering if there is an updated script for this?
-
now we just need Wireguard to update and get working on Fedora, cannot get Device wg0 added to my fedora 30 workstation laptop
-
ok a wee bit of a pain to fix....booted to safe mode and removed the plugin and its folder dynamix.wireguard and dynamix.wireguard.plg and reboot and my server still wasnt pingable. i went to etc/ and saw a wireguard@ file that i removed. stil no fix. ifconfig still showed my br0 and wg0 configs. as soon as i typed "ip link delete wg0" i could ping the server again so far everything is back up with new VPN setup and not pushing the IoT Vlan subnet to wireguard anymore
-
i curious if what i truncated might be the cause this is mine with 3 days current uptime for the docker Created by... ___. .__ .__ \_ |__ |__| ____ | |__ ____ ___ ___ | __ \| |/ \| | \_/ __ \\ \/ / | \_\ \ | | \ Y \ ___/ > < |___ /__|___| /___| /\___ >__/\_ \ \/ \/ \/ \/ \/ https://hub.docker.com/u/binhex/ 2019-10-09 15:48:13.265883 [info] System information Linux 91e90886702f 4.19.56-Unraid #1 SMP Tue Jun 25 10:19:34 PDT 2019 x86_64 GNU/Linux 2019-10-09 15:48:13.298586 [info] PUID defined as '99' 2019-10-09 15:48:14.873230 [info] PGID defined as '100' 2019-10-09 15:48:16.164085 [info] UMASK defined as '000' 2019-10-09 15:48:16.183256 [info] Permissions already set for volume mappings 2019-10-09 15:48:16.202514 [info] TRANS_DIR defined as '/config/transcode' 2019-10-09 15:48:16.287199 [info] Starting Supervisor... 2019-10-09 15:48:17,512 INFO Included extra file "/etc/supervisor/conf.d/plexmediaserver.conf" during parsing 2019-10-09 15:48:17,512 INFO Set uid to user 0 succeeded 2019-10-09 15:48:17,514 INFO supervisord started with pid 6 2019-10-09 15:48:18,516 INFO spawned: 'plexmediaserver' with pid 57 2019-10-09 15:48:18,517 INFO reaped unknown pid 7 2019-10-09 15:48:19,518 INFO success: plexmediaserver entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2019-10-09 15:48:24,495 DEBG 'plexmediaserver' stdout output: Dolby, Dolby Digital, Dolby Digital Plus, Dolby TrueHD and the double D symbol are trademarks of Dolby Laboratories.
-
i will try booting to safe mode when i get home to remove the wireguard plugin to reboot normally hopefully then ill re-install it. @ljm42 is there anywhere in the USB boot drive the wireguard config file resides after its plugin is removed that i should remove so my system will start up normally?
-
yeah i think the auto start of wireguard with that config is breaking my unraid now, when i pop the power off via a smart plug and power it back up i get one ping then it dies any way to remove wireguard from the USB to reboot without it and set up wireguard from scratch?
-
you may have that sqlite DB corruption everyone is talking about what does your plex docker logs show? (click on dockers then click the log on the far right in line with Plex)
-
well i was able to crash unraid 6.8 (not able to ping or access gui through my socks proxy at work) i use the command line on another unraid server to try and ping the 6.8 one and it wont respond. here is what i did I have Remote to Lan set up with two peers (iphone and a laptop with fedora 30 workstation) for allowed IP's it had the default for the tunnel 10.253.0.1 and my home LAN 10.0.0.0/24 I added my IoT VLAN subnet to the iPhone peer 10.0.107.0/24 and hit apply its crashed hard lol...im going to remotely power cycle it and hope it recovers if i can see diagnostics on the flash drive or can recreate it from home ill post diagnostics I would also like to ask if there is a way to disable wireguard from auto starting up if my config is the problem and preventing my gui and IP from being pingable on my LAN
-
wow this VPN is so much faster and better than my ubiquiti one on my USG 4 P
-
check your setting to see if remote access is working. but for local issue this could be the SQ lite DB corruption the unraid team is looking into per chance are you dockers installed on the array or a cache drive/pool?
-
HI @binhex sorry to be a pest but an important update that fixes a Live TV issue (I only have Over the Air for my local news for my mother in law and our family) it has been glitching the last few updates to Plex and i thought it was my HD Homerun or ATSC antenna but the issue is only happening with Plex not with the HD Homerun App. hoping the latest update can be pushed to your container in the next day or so cheers
-
thanks for the explanation that works for me! I see the update now thanks again for all your hard work
-
Hi @binhex my binhex/plexpass been bugging me for the latest beta update for over 24hours (Version 1.18.0.1906), your automation usually has it compiled and pushed by now whats happening?
-
Congrats everyone I have the logos now trying to source a manufacture to produce them for me but looks so far to only allow orders of 100-250 at a time i want 3 for my servers if I do 100 anyone willing to Paypal some money for them ? Pricing isn’t set yet but would appear to be $2-5CAD for each one if I go that route i understand that I should get permission as well to do this so asking @limetech now if this would be ok?
-
I have 3 Licenses, 2 Pro and 1 Plus I love the easy expansion, the reliability and the community the devs are top notch and easy to work with. the upgrades have been flawless and better and better with every release
-
thanks for your looking into it im at a loss im ok with not having the gui option as i tend to just type in the URL to bring it
-
i dunno its still not working i went to host, defined both container and host applied it then edited back to custom br0 and webgui option went wondering if unraid is blocking those ports from a defined linux firewall ill check into it tonight when i get home
-
yeah my unraid 6.7.2 isnt giving me the same options you have host and bridge show the same window man im blind today sorry about that
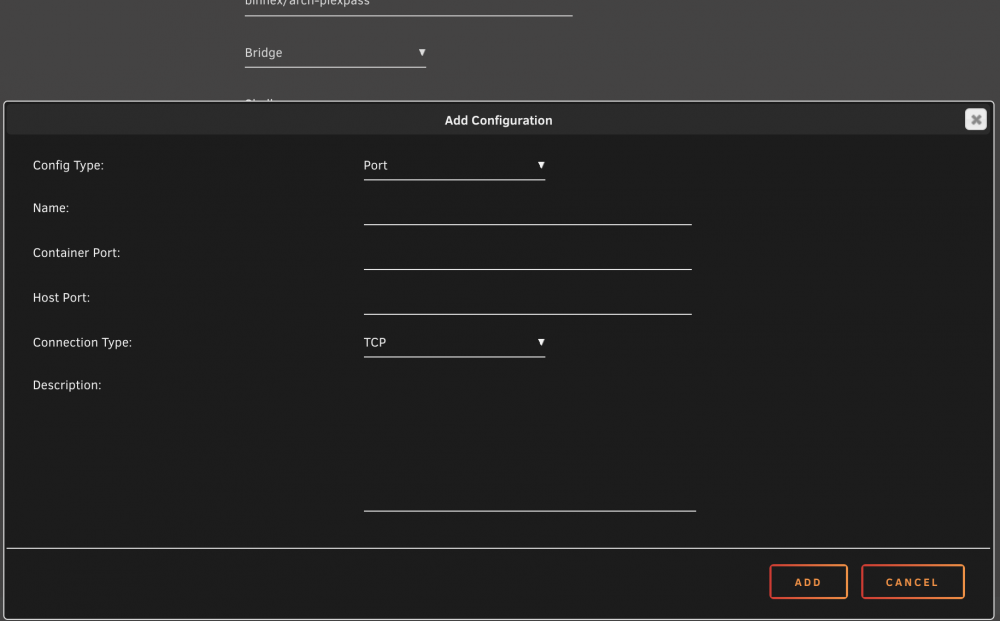
-
ahh ok that makes sense ill do that and report back thanks. got to get ready for work
-
ok not sure if im really doing this correctly... still no gui option
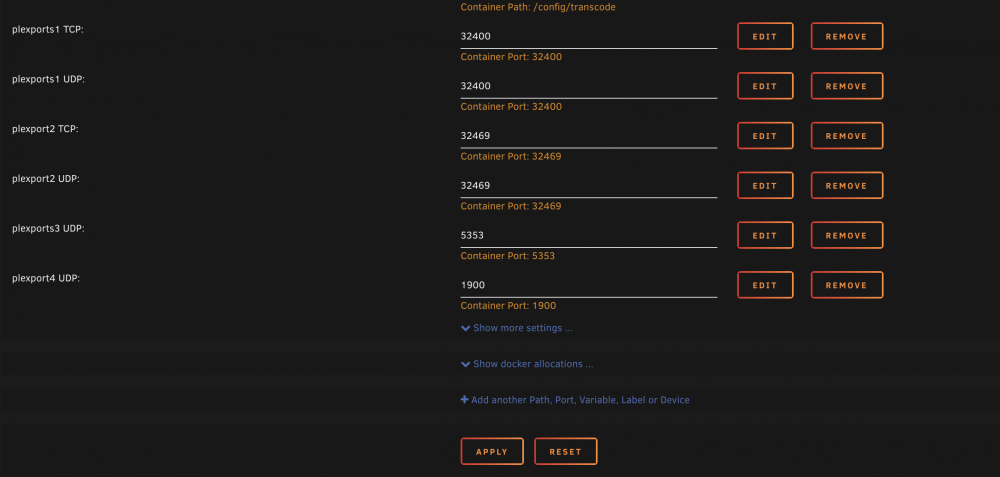
-
hmmm i went to add port and container port is the only option, host is not ***doh my bad add to description
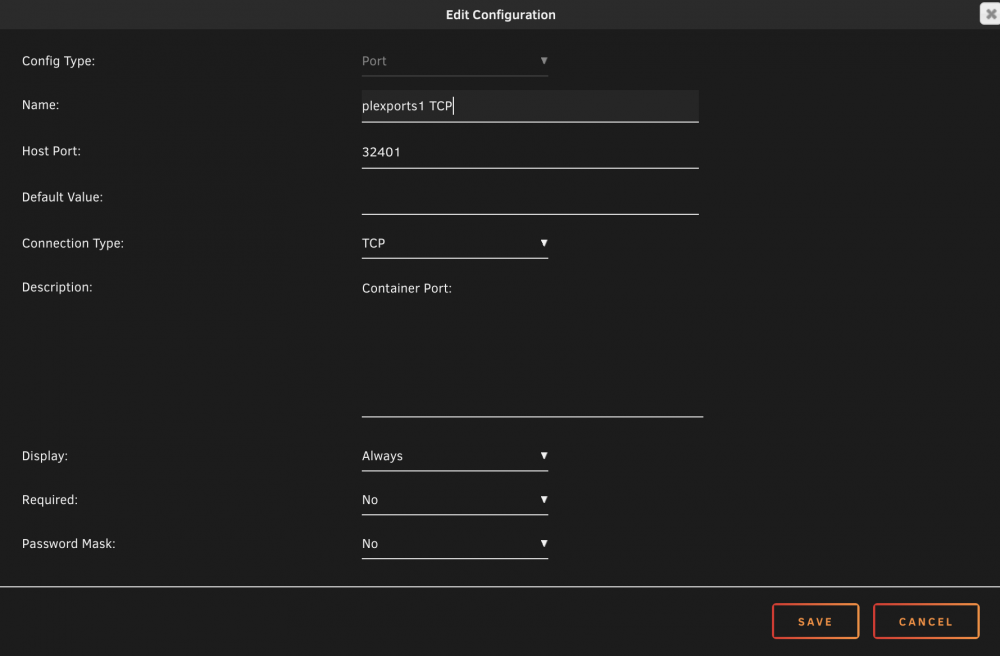
-
hmmm i added them and still a no go unless i did something wrong here is the docker config, i see the docker config section doesnt understand what ports displaying "???"
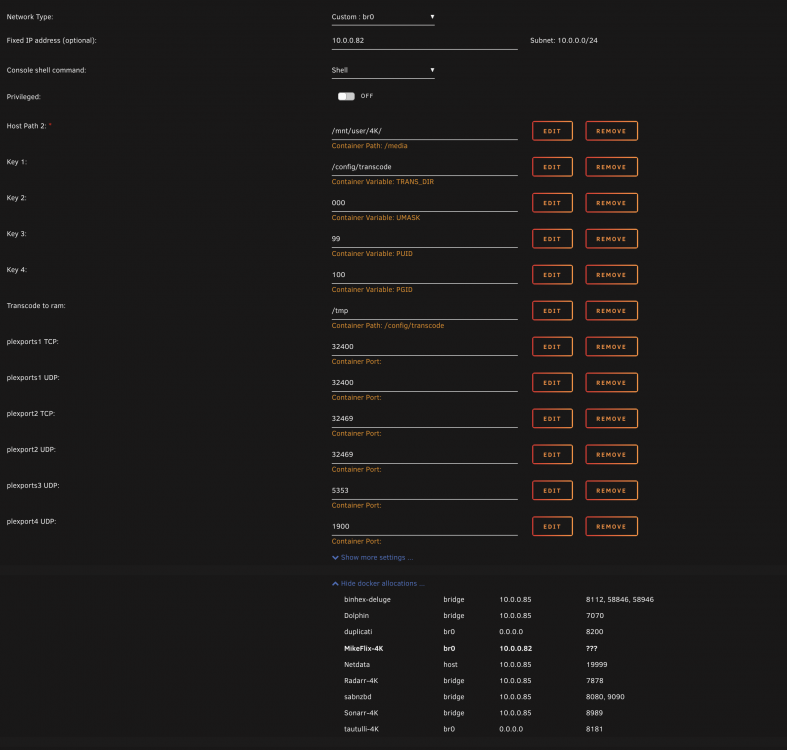
-
thats what i thought. safe to assume -p 32400:3400 is TCP unless specified to be UDP?





