

jbuszkie
-
Posts
693 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by jbuszkie
-
-
*Sigh* Everyone may know this but I didn't... When using user scripts if you click outside the script window in the main window that will also kill the script. So not just hitting the "X".. I was about a 1/4 into zeroing out a drive when I accidentally click outside the script window and killed it! *sigh*
-
Nice! I missed the 0000:04:00.0 being able to be mapped back to a PCI device!
From the LSPCI I also could have seen that 04:00.0 mapped to the ASMedia device!
Thanks,
Jim
-
Quote
At least that one is, it's using one of the two Asmedia ports.
Ok.. I give up.. How were you able to tell that ata7 and ata8 where the Asmedia ports from the syslog? Because I know my motherboard.. I could figure it out.. But I can't find anywhere which ports are mapped to which controller in the syslog... There is no mention of asmedia in the syslog.
-
Quote
At least that one is, it's using one of the two Asmedia ports.
I keep forgetting how to piece everything together in the syslog! I haven't had to look at the syslog in a long time LOL. I have to re-learn each time 😄
-
Has anyone ever had issues with a slot going bad in the Norco drive cages? Two different slots in two different cages are, potentially, giving me issues. One is causing the drive to disappear and the other is give sporadic CRC errors. I'm going to look into if it's the cables or the slot. But I was curious to know if anyone ever had a slot go bad on them?
-
On 2/23/2020 at 11:31 PM, ramblinreck47 said:
Also, search for the BPN-DE3500HD, it's the newer version of the same thing.
Hehe.. You have an extra 0 in the part number! No wonder the search came up with nothing! 🙂
BPN-DE350HD
-
Crap! Those are two different Norco drive cages. One with the dropped disk and one with the CRC errors. And it's not like I bumped the machine or anything.. I guess it's time to open her up and check for loose cables to the cages! So the drive might be good??? hmm..
Anyone seen years of vibrations knocking a sata cable loose on a drive cage?
I *think* both of those slots in question are connected to the MB not the LSI card...
Has anyone seen norco slots go bad?
Thanks @johnnie.black
-
Look at the 800K one.. The errors start around 8:16ish
-
Yeah this after the reboots during the rebuild So the disabled disk info is not there...
... I actually found the syslogs..
-
I'll give the diags.. But I'm not sure what help it will be. They don't contain any historical data about failed disks, right? You would be able to see the CRC errors in the SMART report.. What else is useful in there?
-
1 minute ago, landS said:
Howdy folks
An odd behaviour has cropped up recently. After some period of time when I go to the WebUI, CP requires me to log in.
Is this just a change by CP to access the application from the (docker'ed) desktop --- or should I be concerned that backups are being impacted?
Thanks!
I'm seeing this too.. I remember something sent to me about them requiring more log in
This what I found on in my e-mail
QuoteSecurity of your organization’s data is paramount at Code42. With the recent increases in ransomware attacks on the internet, we have implemented product changes to help you better protect your data.
Effective March 3, 2020, Code42 will require all CrashPlan® for Small Business customers to enter their password to access the CrashPlan for Small Business desktop app. This change will help to further ensure the security of your CrashPlan data.
-
Yeah.. I know the CRC are connection issues.. usually.. But these cables haven't been touched in years... I'm worried about the drive red-balling in slot A...
Is it the drive or the slot...
-
Some history...
I had a 8T drive fail (red ball) recently in slot will call it A. I had a spare 8T unassigned device so I swapped it in and rebuilt fine.
I ran pre-clear on the "failed" drive in slot A and it failed in the zeroing phase.. Ok maybe it was a bad drive.
So I bought another 8T drive to keep as a spare. I shucked it and threw it into slot B. Slot B had an old 4T drive that I took out of service for some reason.
I ran pre-clear on the new 8T drive in slot B and it ran fine. No issues other than a couple UDMA CRC errors. It was only like 4 or 5.. So I scratched my head and continued. I want to remove 3 2T disks so I put my "spare" in slot B in the array. I took all the stuff on one of the 2T disks and put it on the 8T drive in slot B.
That ran fine an came up maybe with one or two more CRC errors. I zeroed out the 2T drive and emptied the 2nd 2T drive on the 8T in slot B. That went fine... but a couple more CRC errors. So I'm thinking maybe slot B has some issues with the cable?
The first 2T was ready to be removed from the system So I removed it and created a new config and trusted parity. That went fine. I started a parity check and that was working fine so I stopped it. I shutdown the array and was going to try the new disk in a different slot. I moved the new 8T into slot A and removed the "failed" 8T
I started the system and copied more files from the 2nd 2T disk that I wanted to empty. After that was done I noticed that the new disk in Slot A red balled!!! It had a bunch of errors (like 6k) Shoot! WTF! So now I put the new 8T back in Slot B. And it's currently being re-built! It's moving along at 7% with no disk errors.
It's up to 14 CRC errors. but I think that's what it started with at the start of the re-build.
So do I have a bad drive or bad slot(s). The slots are in 2 different 5 bay norco drive cages.
Trying to figure out how to proceed.. Look to the experts here..
-
Is there a way to just backup the flash drive? The appdata is (supposedly) getting backed up by crash plan. But The flash drive can no longer via crash plan.
So I'd like to use this to just back up the flash drive (then crash plan will backup the backup). I don't really want to stop all the dockers every time I want to back up the flash drive?
-
This Stackoverflow post was helpful. I was able to kill the process this way. We'll see if I can stop/restart the array gracefully. I need to wait for a disk zeroing to finish first before I can try...
QuoteAll the docker: start | restart | stop | rm --force | kill commands may not work if the container is stuck. You can always restart the docker daemon. However, if you have other containers running, that may not be the option. What you can do is:
ps aux | grep <<container id>> | awk '{print $1 $2}'
The output contains:
<<user>><<process id>>
Then kill the process associated with the container like so:
sudo kill -9 <<process id from above command>>
That will kill the container and you can start a new container with the right image.
-
I have a docker that won't stop. I've tried manually killing it (docker kill containername) and I can't.
I tried to kill the process in the container that was still running, but I got an error....
My guess is I won't be able to shutdown/restart the array until the whole docker subsystem is happy.
How can I kill/restart the whole docker processes?
Thanks,
Jim
-
Possibly a dumb question.... But Am I able to backup the contents of the flash drive through this docker? When I go into the flash folder
under root in the manage files part.. Nothing comes up. My guess is this changed sometime ago and my flash drive is not really backing up.
And I don't see it under the storage tab...
Thanks,
Jim
-
As I looked back into my old e-mail.. I've been running Unraid for over 10 years now!!! I upgraded to pro back in April of 2009! I can't find the original Purchase.. but it must have been before that! Anyway.. I'm still using the original flash drive I started with. I do have a second key and drive.. (It's probably not up to date - Must add to todo list! And I'm not sure where it is LOL)
When should I think about preemptively replacing the flash drive? It's a 1GB Drive that's about 1/2 full..
And a big Kudos to Tom and Limetech guys for such a great product and kudos for such a super great community!
Jim
-
Yeah.. The Docker safe one only allows you to exclude. I only want to run it on specific shares so I'll use the old one until the FCP report is clean! 🙂
Thanks again to the great community for all the help
-
2 minutes ago, Squid said:
Don't run that tool against all the drives or all the shares. If it touches the appdata share, funky things may happen with your docker apps. Hence why there's a docker safe new permissions tool right there also. It will not allow you to run against appdata
I didn't see the other one.. I'll have to look when the current one finishes. I'm just running it on specific shares that got flagged. So I should be safe?
Thanks,
Jim
-
Darn... The answer was in once search below where this came up! The fix is in a separate section under tools/ Docker Safe New Perms
-
I'm trying to empty a drive using unbalance and it does warn me about file permissions.. I ran the extended test in FCP and I get a TON of these
The following files / folders may not be accessible to the users allowed via each Share's SMB settings. This is often caused by wrong permissions being used on new downloads / copies by CouchPotato, Sonarr, and the like: /mnt/user/Backup nobody/users (99/100) 0770 /mnt/user/Backup/acer_aspire nobody/users (99/100) 0770 /mnt/user/Backup/acer_aspire/post_factory.tib nobody/users (99/100) 0660 /mnt/user/Backup/acer_aspire/pre_install_image.tib nobody/users (99/100) 0660 /mnt/user/Backup/acer_aspire/Pre_office2.tib nobody/users (99/100) 0660 /mnt/user/Backup/acer_aspire/Pre_office.tib nobody/users (99/100) 0660 /mnt/user/Backup/Browser_bookmarks nobody/users (99/100) 0770Wasn't there an "FIX" button for this? What does it want me to change the permissions to?
-
Ok.. I'll reply to my own message! 🙂
I guess if I just click on the error thing I can acknowledge the error. But I'm still guessing it will live in the smart report forever...
Maybe I should open up the case and replace the cables in a couple of slots....
Jim
-
I have 4 drives that have low UDMA CRC error counts. They are not really increasing. Do I have to live with
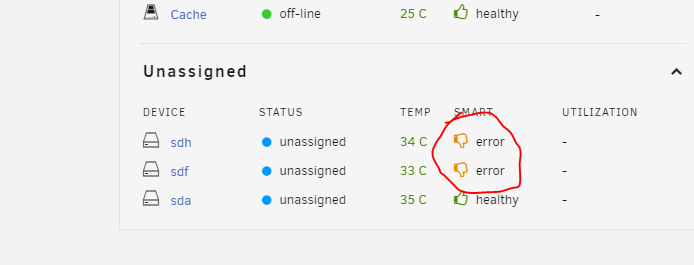
these errors forever? Unfortunately, one of these drives is brand new. It's installed from a drive cage so the connections inside haven't been touched in years.
Is there no way to clear them out? My guess is no...
Jim

Dual Parity question....
in General Support
Posted · Edited by jbuszkie
This is probably another dumb question... But I want to add a second parity disk (10TB). I'll assign it to the parity 2 slot. Now if for some reason I need the disk space and I want to go back to one parity disk... Can I get rid of the Parity 1 (8TB) disk and just have single parity on the parity 2 slot? Or do I have to re-assign the 10TB to Parity 1 and have to rebuild parity completely?
Jim
Edit: I will eventually make both parity 10TB.. But for now I'll stick with a 8TB array limit..