

jbuszkie
-
Posts
693 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by jbuszkie
-
-
The new test is saying my unraid_notify is corrupted.

I can download it and it looks just fine?
I'd post it here, but there is soo much I'd have to take out! (e-mails, passwords..)
How do you want to debug?
-
On 1/23/2022 at 9:15 AM, sirkuz said:
I am on 6.10.0-rc2 and while running parity rebuilds I am noticing that I still get these errors when leaving the UI open under the latest Edge browser. Waiting for 6.10 final to hopefully resolve this one
")
Damn! I was hoping that 6.10 would fix/address this like @Squid alluded to... Fingers crossed that whatever change they going to do wasn't put in yet...
-
3 hours ago, Squid said:
This issue will hopefully disappear once 6.10 is released. After a certain amount of time, Main / Dashboard will reload themselves
7 minutes ago, Squid said:Most reports do not get replied to. That doesn't mean nothing is being looked at. As I said
Which should solve at least some it is (the running out of shared memory) was one of the symptoms that resulted in the above.
I, Normally, don't have main or dashboard open. For me, it's the docker window and a couple of the docker web interfaces.
And in the past it was open web terminals (I only use putty now!). So I don't know if the 6.10 release will fix for all..
Fingers crossed that it will though!!! And I do hope that they are looking into this as it's slightly annoying... Not bad enough to bug them constantly... but always hoping for a post here from them saying that they found the issue! 🙂
-
39 minutes ago, Squid said:
This issue will hopefully disappear once 6.10 is released. After a certain amount of time, Main / Dashboard will reload themselves
Is @limetech even looking at this? He chimed in a while ago and then crickets... There really a lot of us that have this issue. Now I don't know if this "a Lot" is still in the noise for the amount total unraid users so it's not a big enough issue...
I've just had this happen twice last week... And then sometimes it goes for months without hitting this.. *sigh*
-
Thanks!
I just found this in the FAQ
It mentions that I SHOULD see "no balance found on /mnt/cache"
What was weird is I didn't see anything on the main page that said that a balance was in progress like I do when I add/replace a regular drive to the array...
So I was a little worried...
Glad all is good!
-
I added a second drive to my cache pool as per the manual. I can't tell if it's automatically in RAID1?

I got a warning when I first added the disk
Event: Unraid Cache disk message Subject: Warning [TOWER] - pool BTRFS too many profiles (You can ignore this warning when a pool balance operation is in progress) Description: Samsung_SSD_980_1TB_S64ANJ0R676360X (nvme0n1) Importance: warningDo I have to do a manual balance?
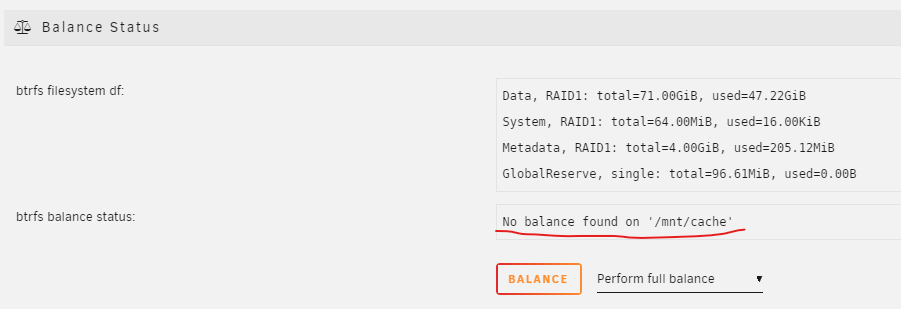
Am I protected? or do I need to do that full balance?
Thanks,
Jim
-
So I wanted to upgrade my cache and eventually make it raid 1. I have two nvme slots but if I used the other slot on the MB I'd have to give up two sata connectors. I didn't want to do that. So I bought a PCIe 3.0 x4 card to NVME.
My MB has 3.0 PCIe so great I thought.
So I plug it into one of my non x16 slots and powered up.
I ran the disk speed benchmark and I was unimpressed. Less than 1G/s I ran the onboard existing NVME drive and it was 3x faster! I'm like crap! Are my slots not really 3.0? Was there some limitation in the slot I used? So I pull up the MB manual and it looks like I have 3x x16 slots (of which only one can be x16 other wise 2x 8x) the last x16 is only x4. And I have 3x PCIe 1x slots. Guess what I plugged my 4x card into... Yes a 1x slot!!
So I opened up the case again and move the card over to the real x4 slot... And BOOM! 3x-ish. the speed!
I have no idea why I though the little 1x slots were 4x???
I'm an idiot sometimes!! 🙂
-
Has anyone moved away from crash plan to something else? I heard versioning is on 90 days now! CP is getting worse and worse about what they back up and now how long they keep revisions!
Is there something better/ cheaper out there now?
-
1 hour ago, Squid said:
Q. Are you guys perchance leaving the dashboard open on a browser tab and never closing it?
I am not.. I'm more diligent now about closing any web terminals I try to keep the browser on the setting page.
I did notice I got this once when I had a grafana webpage auto refreshing. Not sure if that was related at all..
Even if we do have the dash board open all the time, it shouldn't matter??
-
4 minutes ago, trurl said:
"manual" link at lower right of the webUI takes you to the current version of the documentation. Also linked at top and bottom of forum.
The manual never used to be useful for stuff like this. I've always relied on the knowledge here!
It seems like the manual has improved!
-
This is what I did from Squid's post I found
On 11/21/2020 at 12:00 AM, Squid said:Anytime a disk is redballed (as yours is), you must rebuild the contents of the drive. You don't need to clear it again.
Stop the array, unassign the disk. Start the array, stop the array, re-assign the disk and restart the array. A rebuild will happen.
It seems to be rebuilding. I'm getting more memory tomorrow so I'll try to replace that sata cable tomorrow or switch the cable to my last free slot and mark that slot as bad! 😞
-
2 minutes ago, JorgeB said:
Not quite clear what you want to do, there are two options:
1) rebuild on top of the old disk, this is usually the recommended option unless the emulated disk is not mounting.
2) do a new config to re-enable the disk but you'll need to re-sync parity.
1) I want to rebuild on top of the old disk
How do I do that? Unraid has it redballed
-
Ugh... I hate to bring up an old thread... But I'm having issues again. It looks like it's the same slot as above.
I just rebooted my server and upon restart drive 8 became red balled!
Nov 12 09:46:52 Tower kernel: ata8.00: exception Emask 0x10 SAct 0x0 SErr 0x400000 action 0x6 frozen Nov 12 09:46:52 Tower kernel: ata8.00: irq_stat 0x08000000, interface fatal error Nov 12 09:46:52 Tower kernel: ata8: SError: { Handshk } Nov 12 09:46:52 Tower kernel: ata8.00: failed command: WRITE DMA EXT Nov 12 09:46:52 Tower kernel: ata8.00: cmd 35/00:08:30:14:01/00:01:00:02:00/e0 tag 19 dma 135168 out Nov 12 09:46:52 Tower kernel: res 50/00:00:37:15:01/00:00:00:02:00/e0 Emask 0x10 (ATA bus error) Nov 12 09:46:52 Tower kernel: ata8.00: status: { DRDY } Nov 12 09:46:52 Tower kernel: ata8: hard resetting link Nov 12 09:47:02 Tower kernel: ata8: softreset failed (1st FIS failed) Nov 12 09:47:02 Tower kernel: ata8: hard resetting link Nov 12 09:47:12 Tower kernel: ata8: softreset failed (1st FIS failed) Nov 12 09:47:12 Tower kernel: ata8: hard resetting link Nov 12 09:47:47 Tower kernel: ata8: softreset failed (1st FIS failed) Nov 12 09:47:47 Tower kernel: ata8: limiting SATA link speed to 1.5 Gbps Nov 12 09:47:47 Tower kernel: ata8: hard resetting link Nov 12 09:47:52 Tower kernel: ata8: softreset failed (1st FIS failed) Nov 12 09:47:52 Tower kernel: ata8: reset failed, giving up Nov 12 09:47:52 Tower kernel: ata8.00: disabled Nov 12 09:47:52 Tower kernel: ata8: EH complete Nov 12 09:47:52 Tower kernel: sd 8:0:0:0: [sdg] tag#20 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=0x00 cmd_age=60s Nov 12 09:47:52 Tower kernel: sd 8:0:0:0: [sdg] tag#20 CDB: opcode=0x8a 8a 00 00 00 00 02 00 01 14 30 00 00 01 08 00 00 Nov 12 09:47:52 Tower kernel: blk_update_request: I/O error, dev sdg, sector 8590005296 op 0x1:(WRITE) flags 0x800 phys_seg 33 prio class 0 Nov 12 09:47:52 Tower kernel: md: disk8 write error, sector=8590005232 Nov 12 09:47:52 Tower kernel: md: disk8 write error, sector=8590005240 Nov 12 09:47:52 Tower kernel: md: disk8 write error, sector=8590005248Now I really believe that the disk is still good. How do I get unraid to try to rebuild onto that disk? As in how do I get it to believe that the disk is not redballed and try to rebuild to that disk?
The other drive from the above post that had "errors" in this slot has been behaving fine in a different slot for over a year now. So I really think it's an issue with that slot.
grr... I can't remember if I replaced that ata8 cable or not last time.
Thanks,
Jim
-
1 hour ago, jcato said:
Sep 30 08:41:23 unRaid5 nginx: 2021/09/30 08:41:23 [alert] 12576#12576: worker process 18277 exited on signal 6How to stop this error message? Reboot?
When I had this (I believe) I stopped my dockers one by one until it stopped coming.. And for me it was just the first one... Reboot will work as well...
-
Sorry.. But then It's beyond my help.. I'm nowhere near the expert here!
-
I don't remember the details of the problem or the fix... And might be useless.. But might you try a full reboot? Not just restarting the dockers?
-
19 minutes ago, optiman said:
Please - any idea how I can fix the docker update issue? I thought this was supposed to be fixed in the latest version, but clearly it is not. I can force an update and then it will say it's Up to Date. But the auto run check (daily) and hitting the Check For Updates do not work.
Is this the wrong place to ask for help for this issue?
Did you undo any "fixes" you implemented before the upgrade?
-
@limetech Is there any way you guys can start looking at this? There are more and more folks that are seeing this.
For the rest of us... Maybe we should start listing our active dockers to see if one of them is triggering the bug. Maybe there is one common to us that's the cause. If we can give limetech a place to start so to more frequently trigger this condition, it would probably help them..
For me I have
Home_assist bunch
ESPHome
stuckless-sagetv-server-java16
CrashPlanPRO
crazifuzzy-opendct
Gafana
Influxdb
MQTT
I have no running VMs
My last two fails did not have any web terms open at all. I may have had a putty terminal, but I don't think that would cause it?
I do have the dashboard open on several machines (randomly powered on) at the same time..
Jim
-
6 hours ago, xthursdayx said:
Any ideas? For some reason, I'm currently unable to download my diagnostics, but any advice or ideas would be much appreciated. Cheers!
You posted the space available for your cache and others.. But how much space do you have left in /var? Was it full?
The first thing I do is delete the syslog.1 to make some space so it can write the log, then I restart nginx. Then I tail the syslog to see if the writes stop. My syslog.1 is usually huge and frees up a lot of space so it can write to the syslog
The time before last time, I still had some of those errors in the syslog after the restart.. So I was going to stop my dockers one by one and see if it stopped. And well it did with my first one.
Two days ago when then happened to me.. I didn't have to do that. the restart was all I needed...
-
2 hours ago, Flemming said:
I have the same problem and /etc/rc.d/rc.nginx don't fix anything, not even temporarily
strange that /etc/rc.d/rc.nginx restart didn't fix it.
I assume you made room in /var/log for more messages to come through?
After the restart did you still have stuff spewing in the log file?
I do recall a time where I had to do a restart to fix it completely.
Jim
-
No.. I never did...
-
This happened again to me last night. I've been really good about not leaving web terminal windows open. Well.. I didn't have any last night open or for a while.
What I did have different was I had set my grafana window to auto refresh every 10s. I wonder if that had anything to do with this problem?
Also.. The restart command didn't completely fix it this time. I was still getting a bunch of these...
Aug 23 09:09:49 Tower nginx: 2021/08/23 09:09:49 [alert] 25382#25382: worker process 1014 exited on signal 6 Aug 23 09:09:50 Tower nginx: 2021/08/23 09:09:50 [alert] 25382#25382: worker process 1044 exited on signal 6 Aug 23 09:09:51 Tower nginx: 2021/08/23 09:09:51 [alert] 25382#25382: worker process 1202 exited on signal 6 Aug 23 09:09:53 Tower nginx: 2021/08/23 09:09:53 [alert] 25382#25382: worker process 1243 exited on signal 6 Aug 23 09:09:54 Tower nginx: 2021/08/23 09:09:54 [alert] 25382#25382: worker process 1275 exited on signal 6 Aug 23 09:09:55 Tower nginx: 2021/08/23 09:09:55 [alert] 25382#25382: worker process 1311 exited on signal 6 Aug 23 09:09:56 Tower nginx: 2021/08/23 09:09:56 [alert] 25382#25382: worker process 1342 exited on signal 6 Aug 23 09:09:57 Tower nginx: 2021/08/23 09:09:57 [alert] 25382#25382: worker process 1390 exited on signal 6 Aug 23 09:09:58 Tower nginx: 2021/08/23 09:09:58 [alert] 25382#25382: worker process 1424 exited on signal 6 Aug 23 09:09:59 Tower nginx: 2021/08/23 09:09:59 [alert] 25382#25382: worker process 1455 exited on signal 6
I started to kill my dockers and after I stopped the HASSIO group, That message stopped. I restarted the docker group and it hasn't comeback.
I really wish we could get to the bottom of this!!
FYI.. I'm now on 6.9.2
-
On 8/11/2021 at 7:38 PM, ljm42 said:
Would you please try this again? It should work now.
This form updates DDNS for your server and we recently made a server-side change to the DDNS script that caused problems here. Sorry about that
")
Yeah.. It works fine now!
Can't wait for it to be able to send encrypted flash images!
I have to upgrade my flash drive though! It's only one Gig.... And maybe 11 years old! Might be time anyway!! lol
-
 1
1
-
-
15 hours ago, ljm42 said:
The ping will fail but what we are checking is whether it is able to resolve the IP address. If you see this then DNS rebinding is properly disabled:
Pinging rebindtest.unraid.net [192.168.42.42] with 32 bytes of data:Yup.. That works fine.






[Plugin] CA Fix Common Problems
in Plugin Support
Posted
PM sent