




fiore00713
Members
-
Joined
-
Last visited
Everything posted by fiore00713
-
Hey all, I'm trying to sort out an issue I've gone in circles trying to remediate. I'm attempting to put a docker container onto a VPN network type. The container works as expected, however, I'm not able to access it from my desktop which is on a different VLAN. Changing the container back to a bridge network restores my connectivity. I'm able to place my PC onto the same VLAN and access the container while it's on VPN. Frankly, I worked myself in circles and it very well may be something stupid that I'm just neglecting at this point but I'm seeing anybody's insight that can tell me where I've goofed. Diagnostics attached unraid-diagnostics-20260305-1813.zip
-
Hey all, I had a reoccurrence of an issue from a little over a month ago that I thought had been addressed I had suddenly several drives start reporting read errors which ultimately resulted in a couple of disks being disabled. I addressed what I thought had been the issue, some not in use SSDs having still been attached to the HBA (from some previous issues I was chasing) I now had this happen again overnight. Now as I'm trying to re-trace my steps from last time it looks like this may have been an issue on drives between different controllers as the dev IDs were for different disks. From the looks of it, when this happened before it was on the SCSI devices starting with "36" whereas this time it's affecting SCSI devices starting with "1" Originally this morning I thought "ok, maybe the HBA is itself is the problem" but now seeing, at least how I'm interpreting it, that this is happening across different HBAs I'm a little lost -- Unless of course I'm not interpreting something correctly at all I, unfortunately, can't seem to find the diagnostic export from the first occurrence, so I don't have that to attach for comparison. I'm going off of system notifications I have. I do however, have the diagnostics attached from earlier today unraid-diagnostics-20251114-1109.zip

-
I was hoping I could save myself having to run multiple re-syncs, I just wasn't sure if that was the "safe" avenue or not Appreciate it!
-
Hey All, I'm circling back to try and correct an issue that originated a couple weeks ago. I've been stuck traveling for work and am finally getting a breather to be able to attack things. One of my HBA's had itself a moment and offline'd a bunch of drives. In the course of recovering I was able to get my array back online but I'm in a state where one of my two Parity disks is marked as "Device is Disabled" as well as one of my Data disks in the array. I originally had some XFS errors (on the offline data disk, coincidentally) that I was just able to run a repair on and it reports everything has been corrected and no subsequent issues on an additional scan after the fact My question is now, is there anything more I should do as a pre-check I believe both disks to be in good working order, their current status related to my HBA issue From some other reading it sounds like I'd want to set the device as "No Device" start the array, stop the array, Re-add the device and allow a Parity sync to occur If that were to be the case, I would SUSPECT my first course of action would be to get back to a dual-parity state and I don't think the right thing to do would be trying to tackle both disks in one pass So my questions are 1) Would the steps above be the correct to do to get the disks out of the "Device is Disabled" state 2) Should I perform these steps first for my disabled Parity drive and allow the rebuild to occur 3) Once that rebuild process occurs, I would stop the array and perform the same steps for the disabled data drive Are there any other oversights I may be not realizing? Diagnostics attached for good measure unraid-diagnostics-20251029-0912.zip
-
I'm testing this out Out of curiosity, is there any rhyme/reason as to why the SSDs usually don't work as well through the HBAs? Is this some make/model particularity. I ask because for as long as I've been running unraid I've had my SSD drives going through an HBA. Though, on all my previous configurations I believe were utilizing port multipliers. Could there be something in that that may have prevented things from working appropriately?
-
Hello I'm hoping someone smarter can me can point out something obvious I haven't been able to track down. I have 'recently' been trying to get my rig migrated to a new chassis and update some hardware and it has NOT been going well I moved from a Chenbro chassis that had a port multiplier on it's backplanes to a new Hako-Core chassis which utilizes 4-disk backplanes (similar to a Storinator) and I have yet to have the system running in a stable fashion. The current setup is a ASRock Rack ROMED8-2T with a AMD EPYC 7282 I'm utilizing 2x Broadcom branded LSI 9305-24i to wire into the backplanes (System Devices list them as: Serial Attached SCSI controller: Broadcom / LSI SAS3224 PCI-Express Fusion-MPT SAS-3 (rev 01)) All drives are visible in the system, I'm able to start the array without issue Where I begin to see problems is a short time after starting up my docker containers I have 2x Samsung drives in a BTRFS pool for my main cache, this is where my appdata lives After some period of time, usually within 5-10 minutes my syslog begins being bombarded with various errors such as: sd 34:0:15:0: No reference found at driver, assuming scmd(0x000000009270a119) might have completed BTRFS error (device sdah1): error writing primary super block to device 2 There are others but my log did not scroll back far enough, one is related to a "Power-on or device reset occurred" Admittedly, I had a previous forum post regarding this same error, but not the others I have since then replaced both SSD drives that are a part of this cache pool, one at a time, allowing the pool to rebuild in-between I have also replaced the HBA's I was using with new cards from Amazon in the event the original eBay cards were the culprit I have tried moving the drives to different backplanes, which use different SAS cables to different ports on the HBAs The issue persists It seems to be isolated to the SSDs, I do have other SSD pools but they (at least so far) have not gotten enough I/O on them (due to docker containers failing/locking up during these occurrences) I am frankly running out of ideas at this point and I can't keep throwing money at it hoping "maybe this will be the fix" I'm curious if, at this point I could have possibly gotten a bad replacement for one (or more?) of the SSDs despite running preclear testing on the both Also, I'm wondering if in my ignorance if there's something specific with the HBAs that may need to be configured? I've never had an experience where I'd had to do that so I'm not sure where to start. As best I can tell, these cards should be in IT mode as I received them? I'm attaching diagnostics from today's latest foray into trying to make things work If anyone can shed some light on my situation I will be eternally grateful unraid-diagnostics-20250816-1750.zip
-
Hey All, I'm looking for a sanity check around some issues I've been struggling with. I'm wondering if I've got a dying SSD that is then causing the HBA to re-scan the connected drives. This is pretty speculative at this point but I'm not sure if that could be a valid issue or not. Logs are showing I/O error on SDV (12:0:5:0 if I'm reading this correctly), which is one of the drives in my cache pool and then after some time I see a bunch of "Power-on or device reset occurred" for different devices which look to be on the same HBA I've been chasing this down for a couple weeks, thinking it was an HBA issue but now I managed to catch some more data and I'm hoping someone can finally help me put these issues to rest Diagnostics attached unraid-diagnostics-20250723-2101.zip
-
Hey there! I'm having I think the same issue, is there any way you could provide some more details on the "different plugin" portion of your comment?
-
Not sure if I should be revitalizing this thread or starting a new one. I'm still having intermittent issues with this even after completing a rebuild of the system. I DID manage to catch an error in the log window coinciding with a lockup this morning. It would appear that it may be a configuration issue, but I'm not 100% sure how to interpret this. If anyone can make heads or tails of this and at least get me down the right path As an aside, I have VMs currently disabled (disk failure, waiting on RMA) I also have a replacement 10g NIC I was going to work on replacing when I had the chance, should it be a hardware issue on the NIC (one of the only things I haven't yet replaced) Excerpt from the log window attached unraid_error_capture.txt
-
I ran for 19 days before experiencing the issue again. I thought for a moment that it may have been oddly related to a Win11 VM I had but the lockup proved that wrong. In reviewing the syslog it appears that there may be some info captures but I'm not entirely certain how to interpret it if anyone is able to assist in my efforts unraid-diagnostics-20221207-1743.zip
-
Nothing there from the time when the system would have encountered an issue. I was first tipped off by a ping monitor on my NGINX and there was no corresponding logs that were mirrored to the flash drive from that time. I had logs from overnight when backups and docker updates ran, and then subsequently after I had to hard-reset the system but nothing in-between to help me track down anything.
-
Hey All, I've been trying to track down an issue that's plagued me since updating my system to 6.11 I'm running into instances where my serer is becoming completely locked up and unresponsive Dockers appear to crash as my NGINX ping test is the first to report a problem if I'm not around Web interface, SSH, IPMI console and local console are all a no go. The only way that I've found to recover is by a hard reset. I've turned on syslog mirroring to the flash drive but this appears to be happening in such a way that that's not even writing I've got a few dockers that are running with a eth0 interface and I had previously disabled all but my PiHole instance, following this most recent occurrence I've disabled that one for good measure too Looking to see where I may have something jacked up at. One addition oddity is that I've got some old network interfaces that get listed as "do not exist" during boot I had looked at the network config file but did not find the references there, if that may be causing an issue somewhere? unraid-diagnostics-20221104-1611.zip
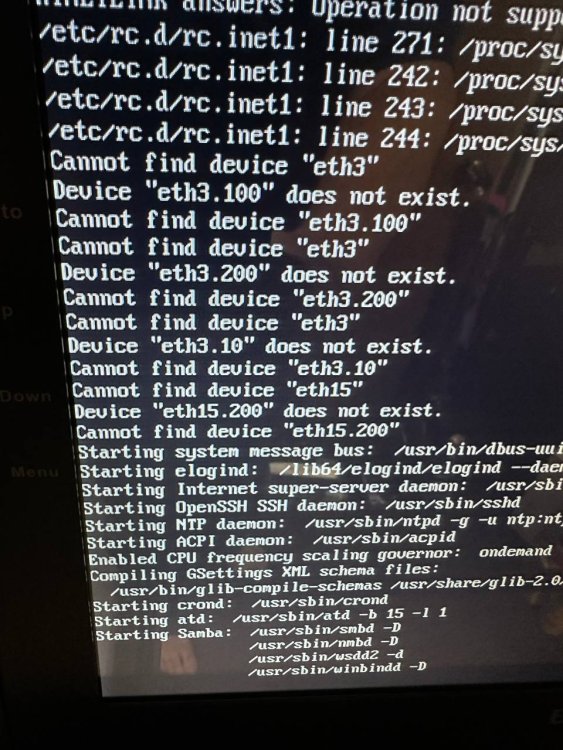
-
I'm seeing a very similar set of issues as @jafi and @capt.shitface when trying to update from 21.0.5 to 21.0.7 (at this time) and something caught my eye... I'm curious if you're seeing the same thing, if it matters or if I'm going down the wrong path I've noticed that my /data path permissions are not set for 'abc' 'abc' but rather 'nobody' 'users' I was trying to compare with a friend of mine but we're a bit at a loss. I'm not sure if the permissions are screwing me up or if it's just something else I'm not catching For reference; I first tried running the update via the gui but it failed for... honestly I cannot remember but it was on the step for "Move new files in place" I've tried subsequently to run updater.phar and am running into similar difficulties Part of me is curious if it's permissions based but I'm not certain If anyone can assist or point me in a different direction it'd be appreciated
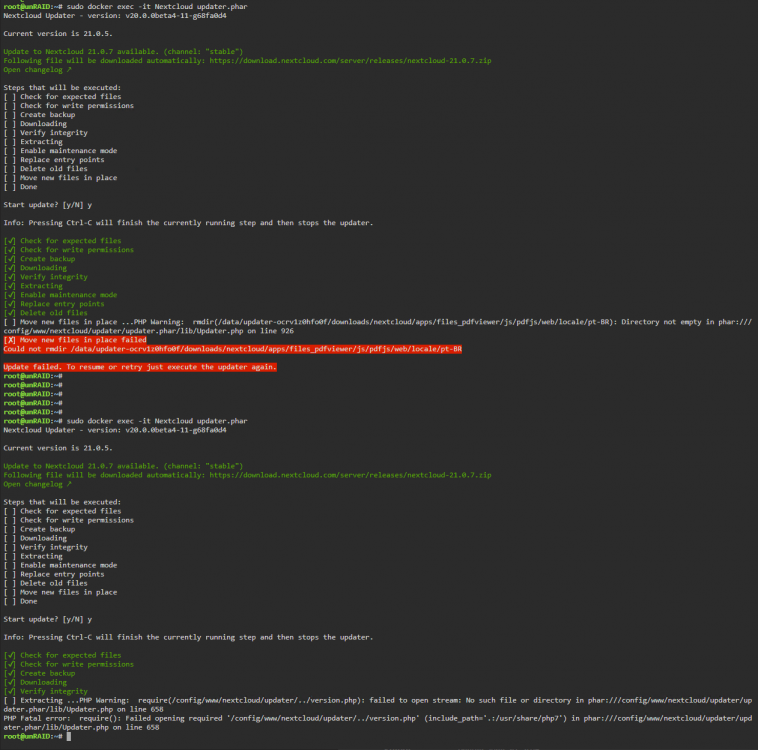
-
@ich777 thanks for the response I am currently running in Legacy mode, not UEFI I checked the BIOS but (unless I'm seriously not digging hard enough) couldn't find anything related to BAR support
-
Trying to sort out getting my P2000 to fire up with the latest update. Trying to determine if it's some setting in unRAID I've managed to get bunked up, BIOS or something else? Running on an ASRockRack X470D4U, I just updated to the latest BIOS and IPMI firmware Updated to 6.9.0 and installed the NVIDIA Driver plugin Seeing the "NVIDIA-SMI" failed message below; I confirmed the card works by hooking up a monitor to the system and was receiving output. I'm seeing the device recognized within System Devices and it's not assigned currently I'm ultimately looking to assign this to my Plex container as I had before upgrading my hardware (I've got it so I'd like to utilize it) Any assistance appreciated unraid-diagnostics-20210302-2253.zip


-
I've managed to roll back to 136 and everything is back in working order now I'll hold at this version for a while see what happens Also, I've had the same issue prior like other users stating where their torrents go missing. Best method I've found is what's been described. Adding in paused stated and forcing a re-check. It'll take a bit of time depending on number and size of files but it beats re-adding and mapping them all manually.
-
I am also seeing this issue since updating last night. I've tried removing and re-adding the container but still no love. Adding a Ubuntu iso getting the same error as well. Tracker Status: Error: Address not available




